목차
- Upstage x AWS AI Initiative 신청하기
- Upstage console에서 API 발급 받기
- API 문서 살펴보기
- Google Sheets에서 Solar Pro2 사용하기
안녕하세요. Upstage와 AWS가 교육과 공익 분야에서 API를 무료로 사용할 수 있는 AI Initiative라는 기회를 이번 부산 정보영재 해커톤에 너무 잘 활용해서 유용함을 전파하기 위해 여러분께 소개 드리게 되었습니다.
1. Upstage x AWS AI Initiative 신청하기
먼저, Upstage x AWS AI Initiative를 신청해야하는데요. 신청할 수 있는 대상은 다음과 같습니다.
- 초,중,고 교사나 학생
- 대학교 교직원이나 학생
- 대학병원 소속
- 비영리(NGO/NPO)단체
그럼 신청링크로 들어가서 신청을 해보겠습니다.
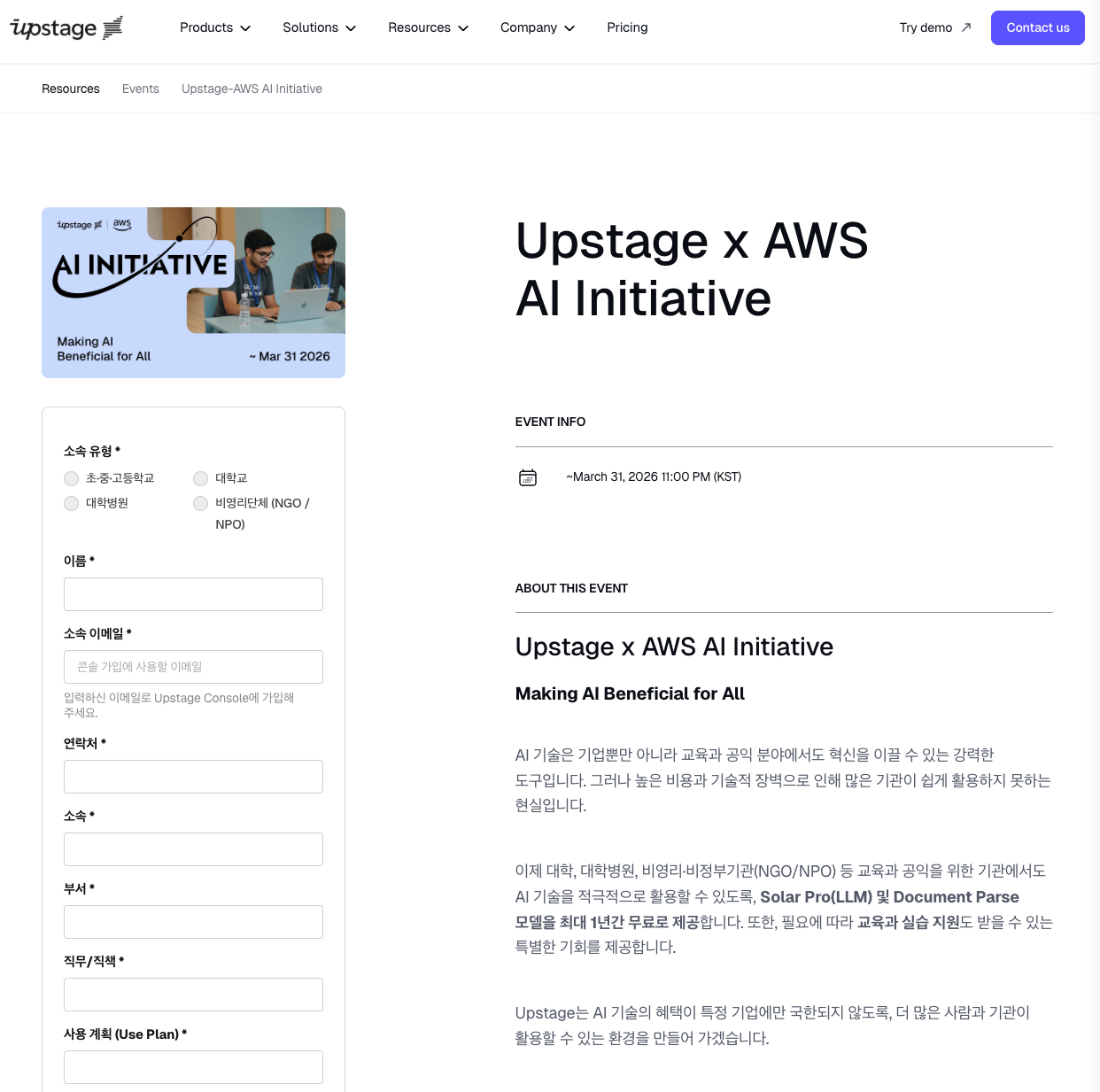
저는 중등 교사라 초,중,고등학교 소속으로 체크를 했습니다. 이름과
소속 이메일을 작성하는데요. 아래 학생증이나, 기관을 인증할 수 있는 공식 서류를 업로드 하게 되면 gmail이어도 상관없는 것 같더라구요.
주의할 점은 만 14세 이상의 대상만 지원이 가능하다는 점입니다.
소속과 부서, 직무 직책을 입력하고 나면 사용 계획을 입력해야하는데요. 저는 '연구용'으로 입력했었습니다.
Submit을 누르고 나면, 승인되는데 약 2일 정도 걸렸던 것 같습니다. 승인이 완료되면 이메일로 승인이 완료되었다는 메일이 오는데, 그때부터 입력한 이메일 계정으로 로그인하여 혜택을 누려볼 수 있습니다.
Upstage가 제공하는 여러 기능이 있겠지만, 사용 가능한 혜택은 Solar Pro모델과 Document Parse 모델의 API사용료를 전액 지원 받을 수 있어요.
2. Upstage console에서 API 발급 받기
승인이 완료되고 나면, 본격적으로 Upstage API를 Upstage console에서 발급받아 사용하실 수가 있습니다. 로그인 하실 때 반드시 AI Initiaitve에 입력하셨던 이메일로 접속하셔야 무료로 사용 가능합니다.
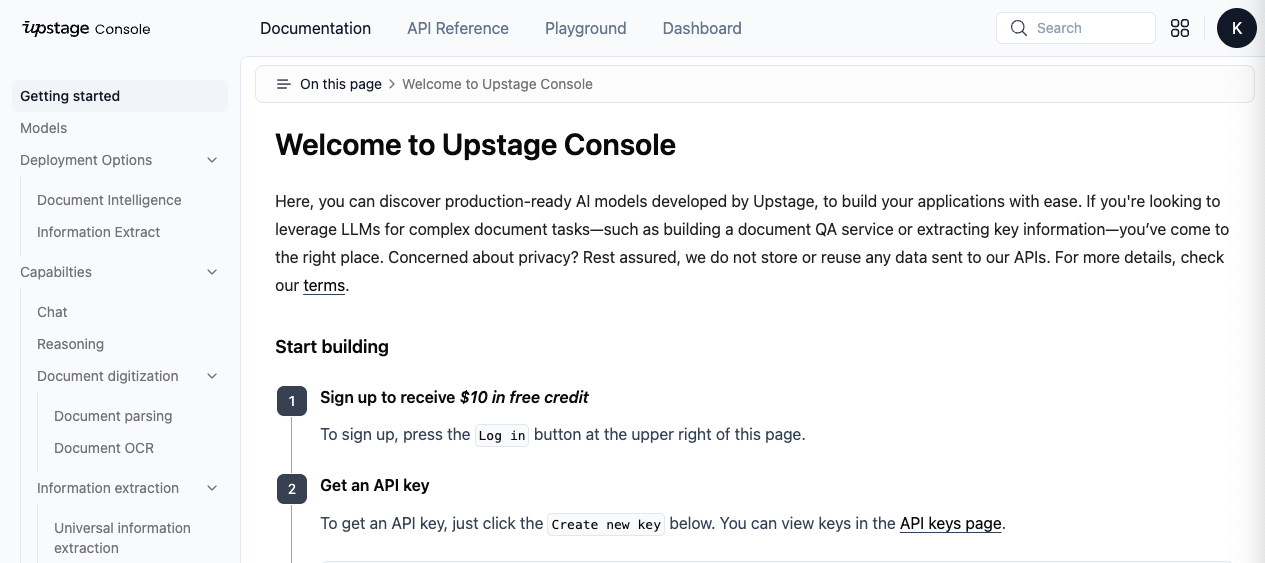
콘솔에 들어가시면 온통 영어라, 어려움을 겪으실 수도 있을텐데 크롬에서 한글 번역을 사용하시면 됩니다.
Start Building에 2. Get an API KEY부터 시작하시면 되는데요. API keys page에 들어가셔서 Create new key를 눌러 만드실 수도 있습니다.
API KEY를 활용하는 Reference 예제 코드가 Python, LangChain, LlamaIndex, cURL, JavaScript까지 다양하게 잘 나와있어서 사용하시는데 어려움이 전혀 없습니다.
3. API 문서 살펴보기
우리가 무료로 사용할 수 있는 모델은 Solar Pro와 Document Parse인데요. 여기에 해당하는 예제 코드들은 3.Make an API request의 Chat, Chat with Reasoning, Document parsing, Document OCR에 해당합니다.
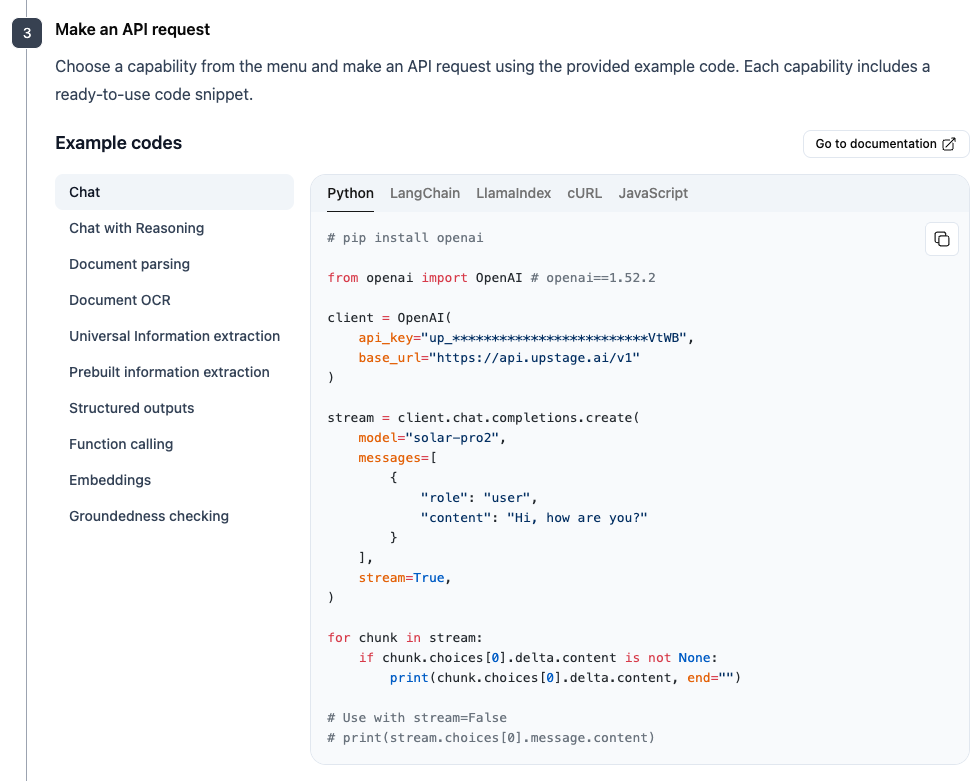
Structured outputs와 Function calling도 해당하긴 하지만 그정도 사용하실 수 있다면, 제 글을 안 보셔도 충분히 하실 수 있으시겠죠?
3.1. Chat, Chat with Reasoning
먼저, Chat과 Chat with Reasoning 을 살펴볼 것인데요. 라이브러리의 영향을 받지 않기 위해 cURL 기준으로 예시 코드를 살펴보겠습니다.
해당 예시 코드를 그대로 AI에게 주고, "이거 사용하게 해 줘"하면 어떤 환경에서든 다 기능 구현 가능하더라구요.
Chat
curl --location 'https://api.upstage.ai/v1/chat/completions' \
--header 'Authorization: Bearer up_********' \
--header 'Content-Type: application/json' \
--data '{
"model": "solar-pro2",
"messages": [
{
"role": "user",
"content": "Hi, how are you?"
}
],
"stream": true
}'Chat with Reasoning
curl --location 'https://api.upstage.ai/v1/chat/completions' \
--header 'Authorization: Bearer up_*********' \
--header 'Content-Type: application/json' \
--data '{
"model": "solar-pro2",
"messages": [
{
"role": "user",
"content": "Hi, how are you?"
}
],
"reasoning_effort": "high",
"stream": true
}'보시면 다른거라곤, reasoning_effort가 high로 들어가느냐 아니냐의 차이 밖에 없습니다. Solar Pro 2 모델의 경우 이번에 추론이 가능한 모델로 출시되었기 때문이죠.
3.2. Solar Pro 2 모델 소개
사용 한도
solar-pro2모델의 경우 현재 분당 요청수 100번, 분당 토큰량 100,000 토큰을 지원하고 있습니다.
파라미터
앞서, 예시 코드에 있던 reasoning_effort나 stream 을 파라미터라고 하는데요. 이를 설정함으로써, 우리 입맛에 좀 더 맞는 형태로 사용할 수 있습니다. 여기에 대해서는 API Refrence 페이지에서 자세히 확인할 수 있는데, 저랑 같이 간략하게 살펴보겠습니다.
1. reasoning_effort
이 파라미터는 추론 노력의 수준을 제어합니다. 'high'는 추론을 활성화하고, 'low'는 비활성화합니다. 추론을 활성화하면 토큰 사용량이 증가할 수 있지만, 복잡한 작업에 대한 응답 품질을 개선할 수 있습니다. 이 매개변수는 추론 모델에만 적용됩니다.
기본값: "low"
값 범위: "low" | "high"
추론을 할 것이냐 하지 않을 것이냐를 선택하는 파라미터인데, 제가 실사용해본 소감으로는 RAG와 같이 참조할 정보량이 많을 때 추론을 하면 좀더 꼼꼼하게 살펴보고 답변하는 경향을 보였습니다.
2. max_tokens
선택적 매개변수로, 생성할 수 있는 토큰의 최대 수를 제한합니다. max_tokens가 설정된 경우, 입력 토큰의 합과 max_tokens의 합은 모델의 컨텍스트 길이와 같거나 더 작아야 합니다.
기본값: "inf"
토큰의 최대 수를 제한하는데, 사실 특정한 경우가 아니면 사용할 일이 없을 것 같습니다. 기본값이 최대치라 따로 파라미터를 설정하지 않으면 최대 토큰으로 설정되어서 토큰량을 제한해야 하는 경우가 아니라면 신경쓰시지 않아도 될 것 같습니다.
3. stream
응답을 스트림으로 전송할지 여부를 지정하는 선택적 매개변수입니다. true로 설정되면 부분 메시지 델타가 전송됩니다. 토큰은 데이터만 포함된 서버 전송 이벤트로 전송됩니다.
기본값: false
값 범위: true | false
입력을 다 기다려서 한 번에 받느냐, 스트리밍으로 받느냐를 설정하는 파라미터입니다. 상용화하는 단계가 아니라면 false로 두는 것이 좋을 것 같습니다.
4. temperature
샘플링 온도를 설정하는 선택적 매개변수입니다. 값은 0과 2 사이여야 합니다. 0.8과 같은 높은 값은 출력에 더 많은 무작위성을 부여하며, 0.2와 같은 낮은 값은 출력의 집중도와 결정성을 강화합니다.
기본값: 0.7
최소값: 0
최대값: 2
형식: "float"
LLM이 다음에 올 단어를 확률적으로 예측해서 제시하는 것이잖아요? temperature를 올리면, 좀 더 창의적인(예상치 못한) 답변을 받을 수 있습니다. 보통 저는 챗봇 같은 경우 기본값을 두는데, 답변 형식이 정해진 사용처에는 0으로 두고 사용합니다.
5. frequency_penalty
모델이 같은 단어나 문장을 반복하는 정도를 조절하는 파라미터입니다. 값은 -2.0 ~ 2.0 사이입니다.
• 양수(예: 1.5) → 반복을 더 많이 벌점 줘서, 같은 말이 덜 나오고 다양한 표현이 나옵니다.
• 0 → 벌점 없음. 그냥 모델이 학습한 대로 말합니다.
• 음수(예: -1.0) → 반복에 관대해져서, 같은 말이 더 자주 나올 수 있습니다.
기본값: 0
최소값: -2
최대값: 2
형식: "float"
예를 들어, 시를 쓸 때 같은 단어가 계속 반복되는 게 싫다면 frequency_penalty를 높이면 됩니다. 반대로 랩 가사처럼 후렴을 반복하고 싶다면 음수로 두면 됩니다.
6. presence_penalty
모델이 이미 등장한 단어나 주제를 다시 꺼내는 정도를 조절하는 파라미터입니다. 값은 -2.0 ~ 2.0 사이입니다.
• 양수(예: 1.5) → 이미 나온 단어나 주제를 다시 쓰는 걸 피하고, 새로운 주제나 아이디어를 더 찾습니다.
• 0 → 제한 없음. 필요하면 이미 나온 말을 또 씁니다.
• 음수(예: -1.0) → 이미 나온 말이나 주제를 다시 꺼내는 걸 장려합니다.
기본값: 0
최소값: -2
최대값: 2
형식: float
예를 들어, 이야기가 한 주제에서 벗어나지 않게 하고 싶다면 음수 값을 주면 되고, 다양한 주제를 계속 탐색하게 하고 싶다면 양수로 두면 됩니다.
7. response_format
모델이 어떤 형식으로 답을 줄지 정하는 옵션입니다.
• {"type": "json_object"} → JSON 형식으로 답을 주지만, 구조는 자유롭게 생성됩니다.
• {"type": "json_schema", "json_schema": {...}} → 내가 정한 JSON 구조(스키마)에 맞춰서 답을 줍니다.
예를 들어, 앱 개발 중이라 모델이 꼭 { "name": "...", "age": ... } 형식으로만 답하게 하고 싶을 때 json_schema를 씁니다. json_schema를 짜두고 거기에 맞게 대답을 하도록 할 수 있다는 점에서 유용한 점이 많습니다.
이 기능은 solar-pro-2 모델에서만 쓸 수 있습니다.
3.3. Document Parsing
제가 Upstage에서 가장 애용하는 기능인데요. 한국어 성능이 굉장히 뛰어날 뿐만 아니라, HWP나 HWPX 파일도 지원한다는 점에서 한국에서 일하는 직장인들이 피해갈 수 없는 장애물을 해결해주는 기능입니다.
사용한도
현재 Document-parse 모델의 경우 동기처리의 경우 초당 10회, 비동기의 경우 초당 30회 요청 제한이 있습니다.
파라미터
chart_recognition
차트를 표로 변환할지 여부를 정하는 파라미터입니다.
• true → 문서 속 차트를 표 형태로 바꿔줍니다.
• false → 차트를 표로 변환하지 않고 그대로 둡니다.
기본값: true
값 범위: true | false
예를 들어, 보고서에 있는 원형 그래프나 막대 그래프를 표로 뽑아내서 분석하고 싶다면 true로 두면 됩니다.
merge_multipage_tables
여러 페이지에 걸친 표를 하나로 합칠지 정하는 파라미터입니다.
• true → 페이지를 넘어가도 표를 이어붙여서 하나로 만듭니다.
• false → 각 페이지별로 표를 따로 둡니다.
기본값: false
값 범위: true | false
예를 들어, 10페이지에 걸쳐 있는 대규모 데이터 표를 엑셀에서 한 번에 보고 싶으면 true로 설정하세요. 되게 유용하겠죠? 특히 표로 점철된 한글파일의 경우에는 더더욱이요.
ocr
이미지 속 글씨를 읽어내는 OCR(광학 문자 인식)을 언제 적용할지 정합니다.
• “auto” → 이미지 문서일 때만 OCR 적용. PDF나 DOCX가 디지털 텍스트이면 OCR 안 함.
• “force” → 항상 OCR 적용. PDF든 워드든 전부 이미지를 만들어서 글씨를 읽습니다.
기본값: “auto”
값 범위: “auto” | “force”
예를 들어, 스캔한 PDF에서 글자를 추출하려면 "force"로 하면 안전합니다.
output_formats
출력 형식을 정하는 파라미터입니다.
가능한 값: "text", "html", "markdown"
기본값: ["html"]
예를 들어, 웹페이지에 그대로 쓰려면 "html", 깔끔하게 텍스트만 받으려면 "text", 노션이나 옵시디언을 주로 사용하신다면 "markdown"을 고릅니다.
coordinates
각 레이아웃 요소(글상자, 표, 이미지 등)의 위치 좌표를 포함할지 정합니다.
• true → 위치 정보(좌표) 포함.
• false → 위치 정보 없이 내용만 줍니다.
기본값: true
값 범위: true | false
예를 들어, 원본 문서 이미지에서 해당 요소를 찾아 표시하고 싶다면 반드시 true여야 합니다. 위치 좌표가 중요할 때 사용하시면 됩니다.
base64_encoding
특정 레이아웃 요소를 이미지(base64 형식)로 제공할지 정합니다.
기본값:[](없음)
예를 들어, ["table"]로 설정하면 표 이미지를 base64로 변환해 응답에 포함합니다.
이렇게 하면 원본 이미지에서 잘라낸 표를 저장하거나 다른 곳에 쓸 수 있습니다. 단, 응답 용량이 커질 수 있습니다.
4. Google Sheets에서 Solar Pro2 사용하기
4.1. 사용 전 설정
현재 구글 시트에서는 실험적으로 =AI(프롬프트, [범위])의 수식을 사용자에게 제공하고 있는데요. 입맛에 맞게 상세한 설정은 제공하고 있지 않습니다.
Upstage의 Solar를 통해 구글 시트에서 Solar를 마음껏 업무편의를 위해 사용해볼 수 있도록 한 번 구성해보았습니다.
사본 만들기를 통해서 사본으로 만들어서 사용하실 수 있습니다.
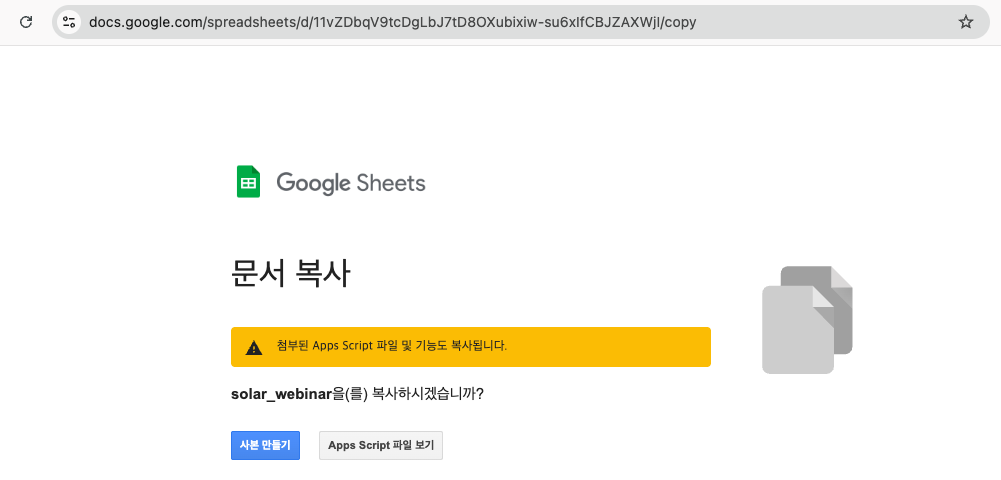
사본을 만들고 나면 잠시 뒤에 Solar 설정 이라는 메뉴가 생깁니다.

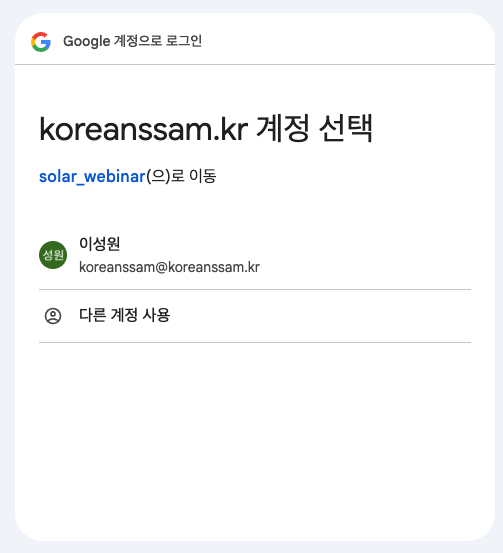
API 키 입력 버튼을 누르면 승인 필요 페이지가 뜨는데,

확인을 누르시고, 계정을 선택합니다.
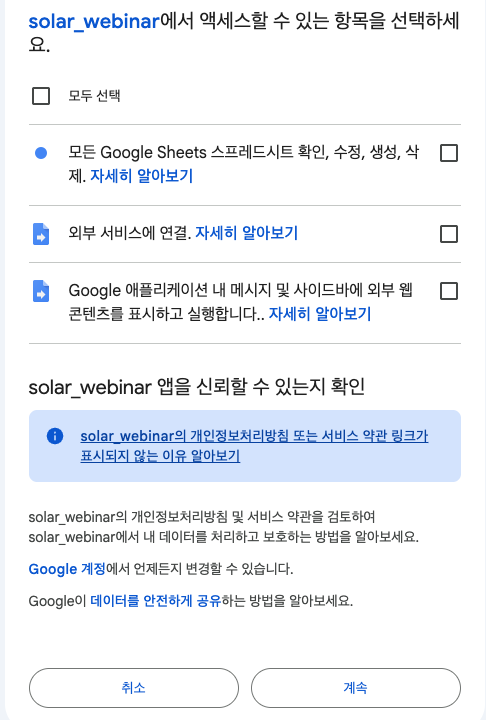
모두 선택을 누르고, 계속 버튼을 누르면 됩니다.
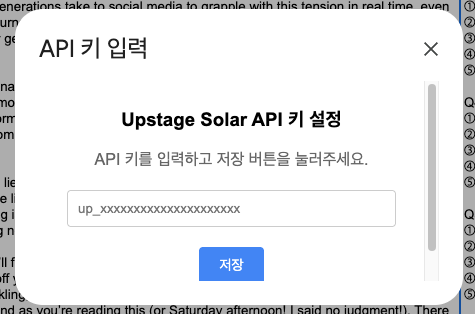
API 키 설정에서 콘솔에서 발급한 API키를 입력하고 저장 버튼을 누르면 설정이 끝이 납니다.
4.2. 사용 예시
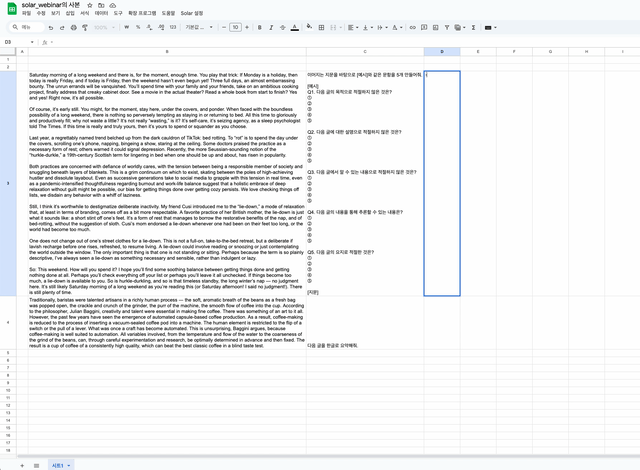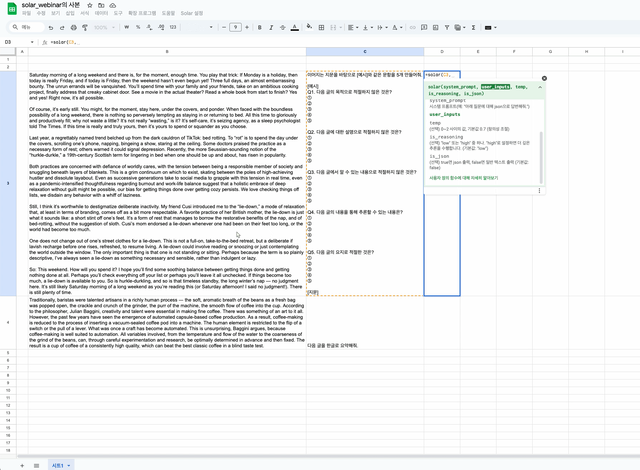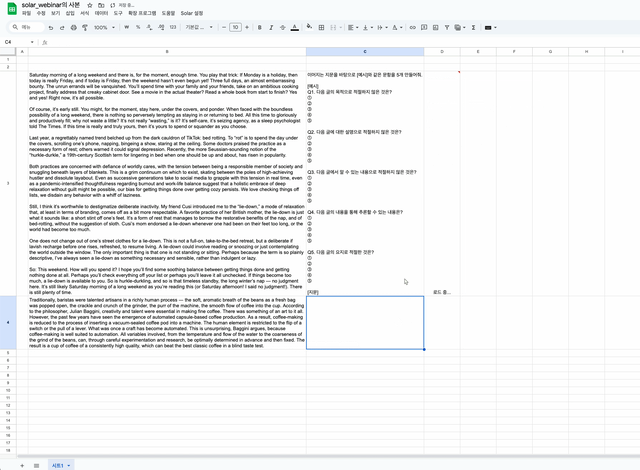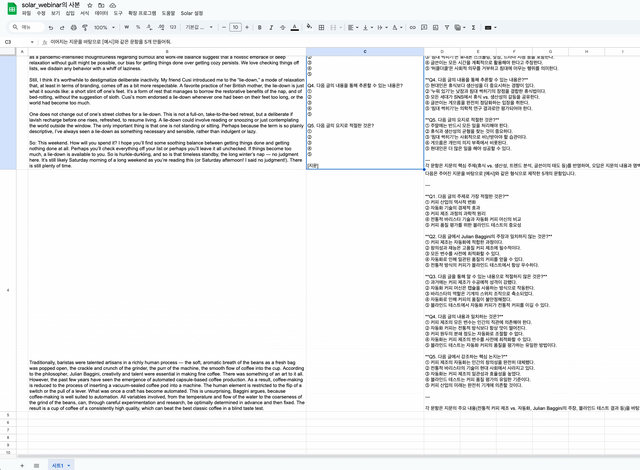
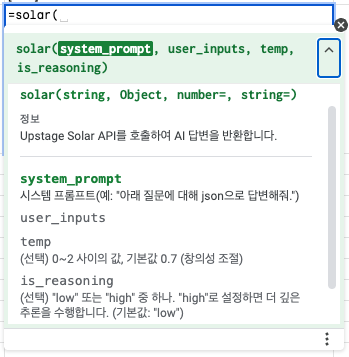
=solar(system_prompt, user_inputs, temp, is_reasoning,is_json)의 형태로 함수를 사용할 수 있는데, temp부터는 선택적으로 입력하는 파라미터입니다.
B3:B4에는 영어 지문이 있고, C2셀에는 시스템 프롬프트를 입력해놓았습니다. 시스템 프롬프트에 따라 지문별로 문항을 자동으로 만드는 것이 목표인데 제대로 만들어지는지 확인해보겠습니다.
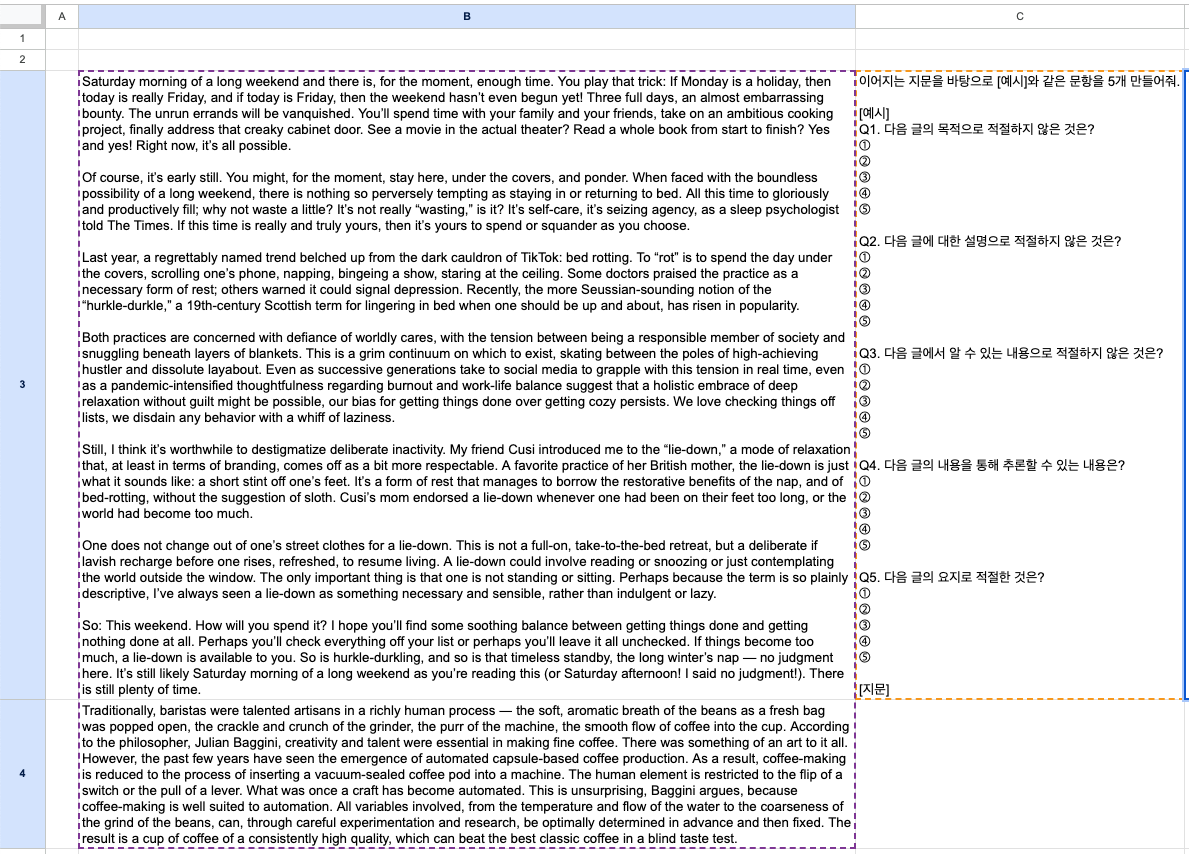
D2셀에 =solar(C3, B3:B4,,"high", true)를 입력해보겠습니다.

다섯 문항을 json형태로 훌륭하게 만든 것을 알 수 있습니다.
D2셀에 =solar(C3,B3:B4,,"high")를 입력하면, json형태가 아닌 일반적인 형태로 답변하는 것을 볼 수 있습니다.

마치며...
사실 Google Workspace Extension으로 배포를 하고 싶었는데, AI를 사용하다보니 개인정보 취급 등등 홈페이지도 구성해야하더라구요. Chrome Extensions 배포보다 굉장히 까다롭고 방법도 몰라서, 이렇게 사본 만들기라는 번거로운 방법으로 공유를 드립니다. Upstage 측에서 여력이 남으시면 Google Workspace Extension으로 배포해줘도 좋을 것 같습니다!
