
최근 리팩토링과 관련된 작업을 많이 진행했다. 이 작업을 진행하며 좋은 코드에 대한 고민을 많이 하게 되었고, 공부도 많이 했다. 클린코드에 관해 공부하다 보면 가독성, SOLID 원칙, 응집도, 결합도 등의 단어를 많이 듣게 된다. 개인적으로 이 단어들 대부분은 처음 듣고 알았을 때 직관적으로 다가오지 않았다. 이 글에서는 응집도, 결합도, 추상화의 관점에서 좋고 나쁜 코드에 대해 공유해보려 한다.
좋은 코드란 무엇이고, 왜 좋은 코드를 작성해야 할까? 내 생각에 좋은 코드를 작성해야 하는 이유는 단 하나다. 변화에 잘 대응하기 위해서다.

헤라클레이토스는 “The only constant is change(세상에서 변하지 않는 것은 오직 변화뿐이다).” 라는 철학적 명제를 남겼다. 이 말은 세상에 존재하는 모든 것은 끊임없이 변화한다는 철학적 메시지를 담고 있다. 변화하는 세상에서 중요한 것은 변화에 대한 적응이다. 아래는 애자일 선언문의 일부 내용이다:
우리는 소프트웨어를 개발하고, 또 다른 사람의 개발을 도와주면서 소프트웨어 개발의 더 나은 방법들을 찾아가고 있다. 이 작업을 통해 우리는 다음을 가치 있게 여기게 되었다: 공정과 도구보다 개인과 상호작용을, 포괄적인 문서보다 작동하는 소프트웨어를, 계약 협상보다 고객과의 협력을, 계획을 따르기보다 변화에 대응하기를 가치 있게 여긴다.
사실 생각해 보면 작성한 그 코드가 변경되지 않을 거라 확신할 수 있다면, 굳이 좋은 코드를 작성하겠다고 시간 들일 필요가 없다. 좋은 코드를 작성하는 이유는 변경에 빠르고 유연하게 대응하기 위해서다. 그런 관점에서 나는 좋은 코드의 가장 중요한 조건 중 하나가 "수정하기 쉬운 코드" 라고 생각한다.
다만 "수정하기 좋은 코드"라는 말은 직관적이지 않다. 그렇기에 SOLID 원칙이나, 추상화, 응집도, 결합도와 같은 직관적인 가이드라인이 존재한다. 하지만 이러한 가이드라인도 이해하기 어렵거나 직관적이지 않은 경우가 많다. 실제로도 응집도, 결합도, 추상화와 같은 단어를 선택해 코드에 관해 설명하면 표정에서 물음표를 보이는 경우가 많다. 응집도, 결합도, 추상화를 중심으로 좋은 코드와 나쁜 코드에 대해서 알아보자.
추상화
추상화란 무엇일까? 나는 개인적으로 추상화를 "인간의 언어에 얼마나 가까운가?" 라고 정의하고 있다.
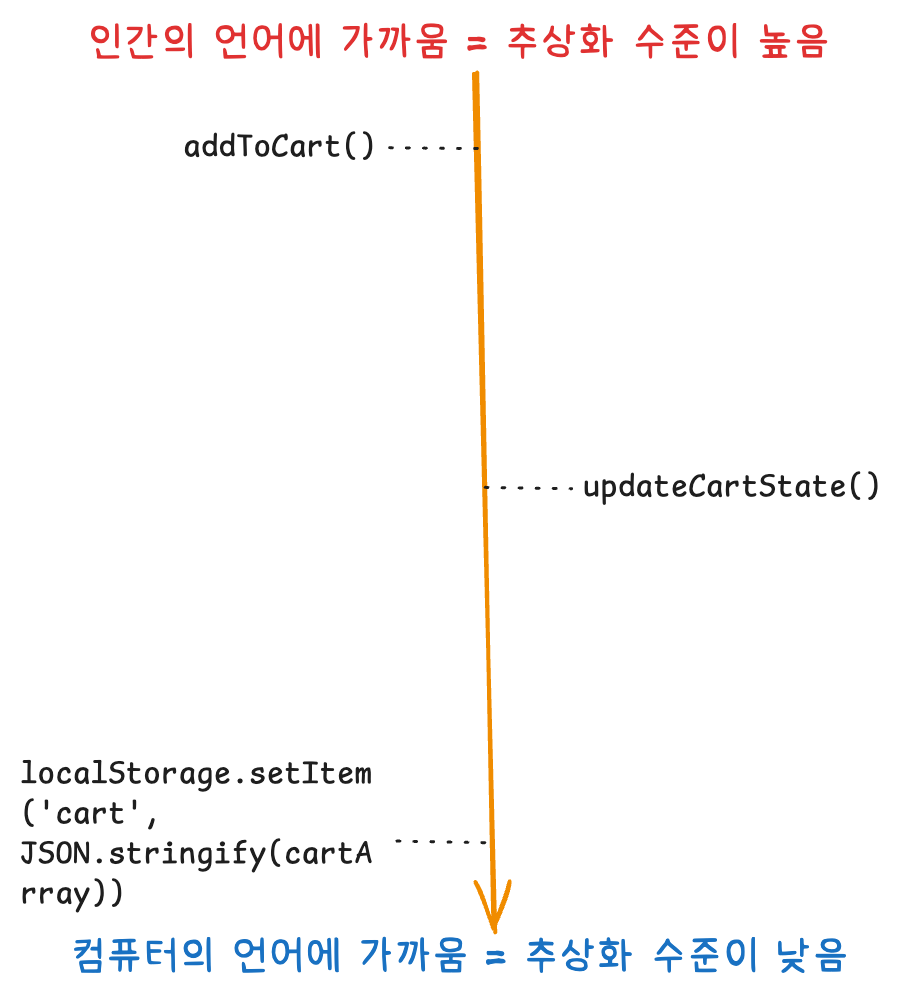
그렇다면 추상화는 언제, 어떻게, 왜 해야할까?
구체적인(추상화 수준이 낮은) 코드는 변경될 확률이 높다. 위 이미지를 예시로 들어보자.
addToCart()updateCartState()localStorage.setItem('cart', JSON.stringify(cartArray))
addToCart 함수는 변경될 확률이 낮다. 추상화 수준이 높으므로 안정적이고 부담 없이 의존할 수 있다. 아마 수정이 발생해도 addToCart 함수의 내부 로직이 변경되지, 인터페이스에는 영향이 없고 이를 사용하는 코드에서도 수정이 필요할 확률은 낮을 것이다.
localStorage.setItem 함수는 변경될 확률이 높다. 지금은 로컬 스토리지에 저장하고 있지만, DB에 영구 저장하기로 기획이 수정되었다고 생각해 보자. 만약 내 코드에서 이 함수에 직접 의존한다며? 나아가서 100개의 코드에서 로컬 스토리지 메서드에 직접 의존한다면? 변경에 대응하기 위해 100개의 코드를 수정해야 할 것이다.
이를 방지하기 위해 필요한게 추상화다. localStorage.setItem에 직접 의존하지 않고, 추상화된 함수에 의존했다면 단 1개의 모듈만 수정해서 이러한 변경에 대응할 수 있을 것이다.
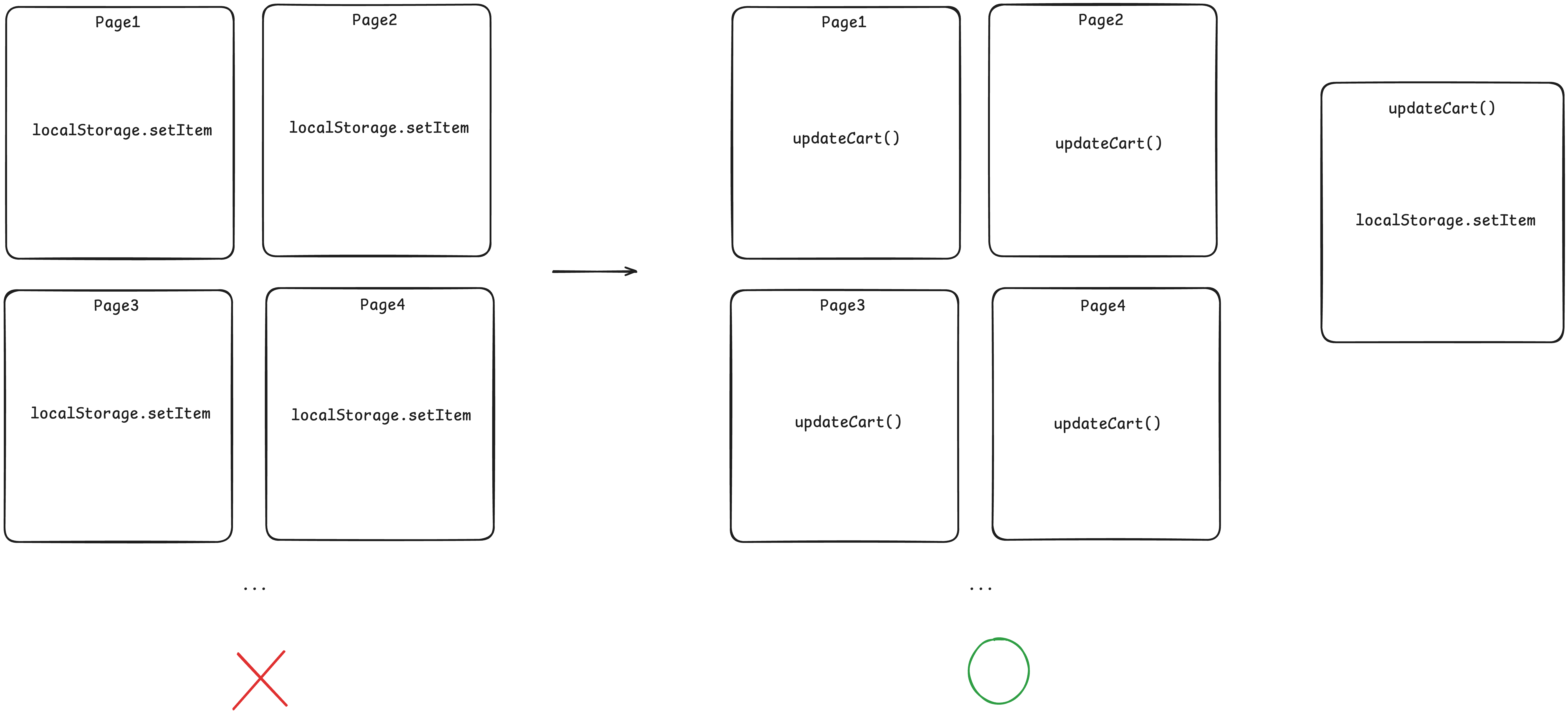
추상화 수준이 낮은 코드는 안정적이지 않다. 추상화를 통해 안정적인 인터페이스를 만들고 변경될 확률이 높은 세부적인 코드를 그 안에 감출 수 있다. 이게 추상화가 필요한 이유이다.
내가 다니는 회사는 데이터베이스 모니터링 소프트웨어를 개발한다. 데이터베이스를 모니터링 할 수 있는 다양한 화면들이 있고, 각 화면에는 필터링 상태들이 있다.
그리고 화면들 사이의 연계 기능이 있는데, A 화면에서의 필터링 조건을 가지고 B 화면으로 이동되어야 하는 그런 기능이다. 우리는 이 기능을 SearchParams를 사용해서 해결하기로 결정하고 아래처럼 코드를 작성했다.
// react-router-dom의 useNavigate()의 반환값인 navigate 함수 및 서치 파라미터 로직에 직접 의존
const handleSqlIdClick = (sqlId: string, filter: FilterState) => {
const params = new URLSearchParams();
Object.entries(filter).forEach(([key, value]) => {
urlSearchParams.set(key, value);
});
const path = `/sql/${sqlId}`
navigate({
path,
params,
});
}이 코드 괜찮을까? 아래와 같은 변경이 발생했다고 가정해 보자.
- 기획상에서 연계에 대한 히스토리를 남기기로 했다.
- 페이지가 이동되어도 기존 페이지의 필터 조건이 유지되어야 한다.
이 두 가지 중 어떤 변경도 대응하기 쉽지 않다. 회사 소프트웨어 대부분의 페이지가 이런 연계 기능을 제공하며 이 페이지가 수십 페이지다. 이렇게 세부 사항에 의존한 코드를 작성하면 간단한 변경을 위해서 수십 개의 페이지를 수정해야 한다. 심지어, 모든 페이지를 올바르게 수정했는지 알 수도 없다.
이 문제의 해결책은 아주 간단하다. 아래와 같이 추상화된 함수를 통해 연계 기능을 구현하면 된다.
const handleSqlIdClick = (sqlId: string, filter: FilterState) => {
const path = `/sql/${sqlId}`
linkage({
path,
params,
});
}linkage 함수 내부적으로는 서치 파라미터를 통해 navigate 하게 되어있다. 언뜻 단순해 보이는 이 추상화가 가져오는 이점이 아주 크다. 다시 1, 2번의 상황을 가정해 보자. 우리는 linkage 함수 하나만 수정해서 이 요구사항을 해결할 수 있다.
이처럼 추상화의 핵심은 세부적인 구현에 직접 의존하지 않게 하기 위함이다. 변경될 확률이 큰 세부 구현에 직접 의존하고 있다면 추상화해야 한다.
응집도
응집도란 연관된 모듈이 얼마나 잘 모여있는가를 의미한다. 초기 프로젝트 아키텍처를 구성하며 열띤 토론을 했던 기억이 난다. 특히 FSD 적용과 관련된 부분이었는데 논쟁의 주제는 아래와 같았다.
- 나: 두 페이지 이상에서 재사용 되는 모듈이 아니라면 feature, entity, widget 등으로 분리하면 안 된다. 해당 페이지 폴더 내부에 코드를 작성하고 재사용되는 순간 해당 계층으로 분리해야 한다.
- 팀원: 일단 먼저 feature, entity, widget 등으로, 수직적으로 분리해야 한다.
결론적으로는 내가 제시한 구조가 되었다. FSD에서 많이들 오해하는 게 바로 팀원분과 같은 게 아닐까 싶다. 공식 문서를 잘 읽어보면 feature에 "재사용 되는" 이라는 단어가 분명하게 붙어있다.

재사용되지 않는 모듈들은 feature, entity, widget 등으로 분리할 필요가 없다. 오히려 그렇게 분리하게 되면 응집도만 떨어지게 된다. 아래의 두 가지 예시를 보자.
1. 재사용 되는 상황에서만 분리한 경우
src/
├── pages/
│ └── cart/
│ ├── ui/
│ │ ├── CartPage.jsx
│ │ ├── CartItemList.jsx
│ │ ├── CartSummary.jsx
│ │ ├── EmptyCartMessage.jsx
│ │ └── ApplyCouponForm.jsx
│ ├── model/
│ │ ├── useCartCalculation.js
│ │ └── cartHelpers.js
│ └── index.js
├── shared/
│ ├── ui/
│ │ ├── Button/
│ │ ├── Input/
│ │ └── Card/
│ └── lib/
│ └── formatPrice.js
└── features/
└── checkout/ // 다른 페이지에서도 사용되기 시작한 기능
└── ui/
└── CheckoutButton.jsx2. 일단 분리한 경우
src/
├── pages/
│ └── cart/
│ └── index.jsx // 단순 조합만 담당
├── features/
│ ├── cart-item-list/
│ │ └── ui/
│ │ └── CartItemList.jsx
│ ├── cart-summary/
│ │ └── ui/
│ │ └── CartSummary.jsx
│ ├── apply-coupon/
│ │ └── ui/
│ │ └── ApplyCouponForm.jsx
│ └── checkout/
│ └── ui/
│ └── CheckoutButton.jsx
├── entities/
│ └── cart/
│ ├── model/
│ │ ├── useCartCalculation.js
│ │ └── cartHelpers.js
│ └── ui/
│ └── EmptyCartMessage.jsx
├── shared/
│ ├── ui/
│ │ ├── Button/
│ │ ├── Input/
│ │ └── Card/
│ └── lib/
│ └── formatPrice.js
└── widgets/
└── cart-widget/
└── ui/
└── CartWidget.jsx다음과 같은 수정을 하기로 했다고 생각해 보자:
"장바구니 총액이 5만원 이상일 때 무료배송 표시 및 배송비 계산 로직 추가"
아래는 각 방식에 따른 수정 범위다:
1번의 경우(높은 응집도)
src/
├── pages/
│ └── cart/
│ ├── ui/
│ │ ├── CartPage.jsx ✅ (무료배송 안내 컴포넌트 추가)
│ │ └── CartSummary.jsx ✅ (배송비 표시 및 조건부 렌더링)
│ └── model/
│ └── useCartCalculation.js ✅ (배송비 계산 로직 추가)
│ └── shipping.js ✅ (배송비 상수 추가)
수정 파일: 4개 (모두 연관된 위치에 모여있음)2번의 경우(낮은 응집도)
src/
├── pages/
│ └── cart/
│ └── index.jsx ✅ (새 위젯 import 및 배치)
├── features/
│ ├── cart-summary/
│ │ └── ui/
│ │ └── CartSummary.jsx ✅ (배송비 props 추가)
│ └── free-shipping-notice/ ✅ (새 feature 폴더 생성)
│ └── ui/
│ └── FreeShippingNotice.jsx
├── entities/
│ └── cart/
│ └── model/
│ └── useCartCalculation.js ✅ (계산 로직 수정)
├── widgets/
│ └── shipping-info/ ✅ (새 widget 폴더 생성)
│ └── ui/
│ └── ShippingInfo.jsx
└── shared/
├── constants/
│ └── shipping.js ✅ (배송비 상수 추가)
└── lib/
└── calculateShipping.js ✅ (배송비 계산 유틸 추가)
수정 파일: 7개 + 2개 새 폴더 (여러 계층에 분산됨)극단적인 예시일 수 있지만 확실한 건 1번의 경우 pages/cart 폴더 내부 모듈의 수정만으로 그칠 수 있다는 거고, 2번은 그렇지 않다는 것이다. 수정을 위해서 수많은 폴더를 탐색해야 한다.
응집도는 페이지 단위에서만 적용되는 이야기가 아니다. 컴포넌트, 함수, 커스텀훅 등등 다양한 형태인 모듈의 응집도를 높여야 한다. 그렇다면 높은 응집도를 가장 직관적으로 파악할 수 있는 방법은 뭘까?
나는 개인적으로 특정 모듈을 삭제하는 상황을 그려본다. 예를 들어 cart 페이지를 삭제하는 상황을 가정해 보자:
1번(높은 응집도)
src/
├── pages/
│ └── cart/ ❌ (폴더 전체 삭제)
│ ├── ui/
│ │ ├── CartPage.jsx
│ │ ├── CartItemList.jsx
│ │ ├── CartSummary.jsx
│ │ ├── EmptyCartMessage.jsx
│ │ └── ApplyCouponForm.jsx
│ ├── model/
│ │ ├── useCartCalculation.js
│ │ └── cartHelpers.js
│ └── index.js
└── features/
└── checkout/ ✅ (다른 페이지에서도 사용 중이므로 유지)
└── ui/
└── CheckoutButton.jsx
작업: 1개 폴더 삭제로 완료
남은 잔재: 없음2번(낮은 응집도)
src/
├── pages/
│ └── cart/
│ └── index.jsx ❌ (삭제)
├── features/
│ ├── cart-item-list/ ❓ (이게 cart 전용인지 확인 필요)
│ │ └── ui/
│ │ └── CartItemList.jsx ❌ (cart 전용이면 삭제)
│ ├── cart-summary/ ❓ (다른 곳에서 쓰는지 확인 필요)
│ │ └── ui/
│ │ └── CartSummary.jsx ❌ (cart 전용이면 삭제)
│ ├── apply-coupon/ ❓ (checkout에서도 쓸 수 있음)
│ │ └── ui/
│ │ └── ApplyCouponForm.jsx ⚠️ (사용처 확인 후 결정)
│ └── checkout/ ✅ (다른 페이지에서 사용 중)
├── entities/
│ └── cart/ ❓ (전체를 삭제해야 하나?)
│ ├── model/
│ │ ├── useCartCalculation.js ⚠️ (mini-cart에서도 쓸 수 있음)
│ │ └── cartHelpers.js ⚠️ (전역적으로 쓰일 수 있음)
│ └── ui/
│ └── EmptyCartMessage.jsx ❌ (cart 전용이면 삭제)
└── widgets/
└── cart-widget/ ❓ (헤더의 미니 장바구니용일 수도)
└── ui/
└── CartWidget.jsx ⚠️ (사용처 확인 필요)
작업:
- 최소 5개 이상의 폴더 확인
- 각 파일의 의존성 분석 필요
- 삭제 가능 여부 개별 판단
잠재적 문제:
- 남은 고아(orphan) 코드 발생 가능
- 실수로 필요한 코드 삭제 위험
- 불필요한 코드가 남아있을 가능성이처럼 삭제하는 상황을 상상해 보는 게 가장 좋았다. 페이지, 컴포넌트, 함수 단위로 그런 상상을 하며 관련 위치를 고려한다. 이 컴포넌트 한 번에 삭제할 수 있나?, 이 함수 한 번에 삭제할 수 있나? 이런 식으로 이 기능을 제거하기 위해서 어느 정도의 자원이 필요한가를 상상하곤 한다.
결합도
결합도란 다른 모듈에 얼마나 의존적인지를 의미한다. 결합도가 높은 모듈은 수정하기 어렵다. 의존하는 모듈에서의 수정으로 연쇄적인 수정이 발생하기도 하고, 다른 모듈들을 연쇄적으로 수정해야 하기도 한다.
결합도는 정말 다양한 방식으로 생긴다(참고). 내 개인적인 경험으로 결합도는 줄이는 것도 좋지만, 결합도의 영향을 최소화 하는 형태의 대응책이 가장 유의미했다. 나는 결합도에 대응하는 핵심 원칙 3가지가 있다.
- 추상화를 통해 의존하는 모듈의 변경으로 인한 연쇄적인 수정을 방지한다. 세부적인 의존성에 직접 의존하지 않고 추상화를 통해 안정적인 인터페이스를 만든다.
- 특정 모듈에 의존해야만 하는 상황이라면 엄격한 타입 시스템으로 모든 수정 되어야 하는 에러를 컴파일 단계에서 확인할 수 있게 한다.
- 필요한 경우 의존성 주입을 통해 필요한 부분에서만 의존성을 가질 수 있게 영향 범위를 최소화한다.
외부 의존성과의 결합은 어쩔 수 없는 경우가 많았다. 결합도 자체를 줄이는 것도 좋지만, 변경으로 인한 불필요한 연쇄적인 수정을 방지하는 해결책이 실질적으로 도움이 되었던 경우가 많았다. 1, 2, 3번에 대한 각 예시를 통해 한 번 살펴보자.
추상화를 통해 안정적으로 의존하기
예를들어 Next.js 프로젝트에 axios를 사용하고 있고, fetch와의 호환성을 위해 ky 라이브러리로 마이그레이션을 진행해야 한다고 생각해보자.
직접적으로 의존하는 경우 아래와 같은 코드가 작성되어 있을것이다:
const getUser = (userId: string) => axios.get(`/user/${userId}`);추상화를 통해 의존하게 되면 아래와 같은 코드가 작성되어 있을것이다:
// getUser.ts
const getUser = (userId: string) => apiClient.get(`/user/${userId}`);그렇다면 각 두 상황에 axios 에서 ky로 마이그레이션 하려 하면 어떤 일이 벌어질까? 첫 번째 예제 처럼 직접적으로 의존하게 되면 그와 관련된 수많은 파일들을 수정해야 한다. 다만 두 번째 예제처럼 추상화를 통해 의존하게 되면 apiClient만 수정하면 된다.
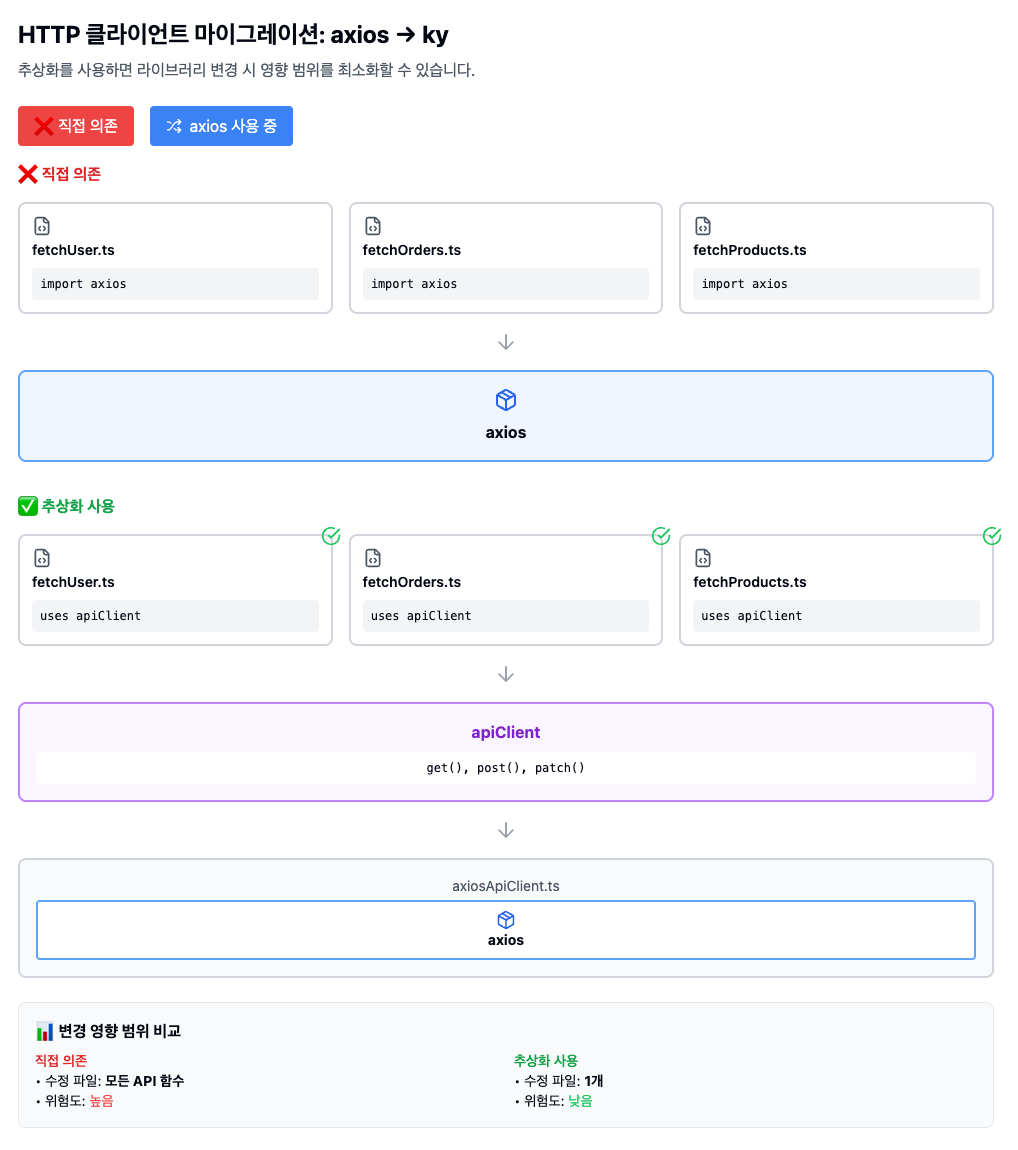
이처럼 변경될 확률이 높고, 결합도가 높아질 수 밖에 없는 모듈이 있다면 추상화를 통해 의존해 안전하게 의존할 수 있다.
타입 시스템을 통해 변경 지점 파악하기
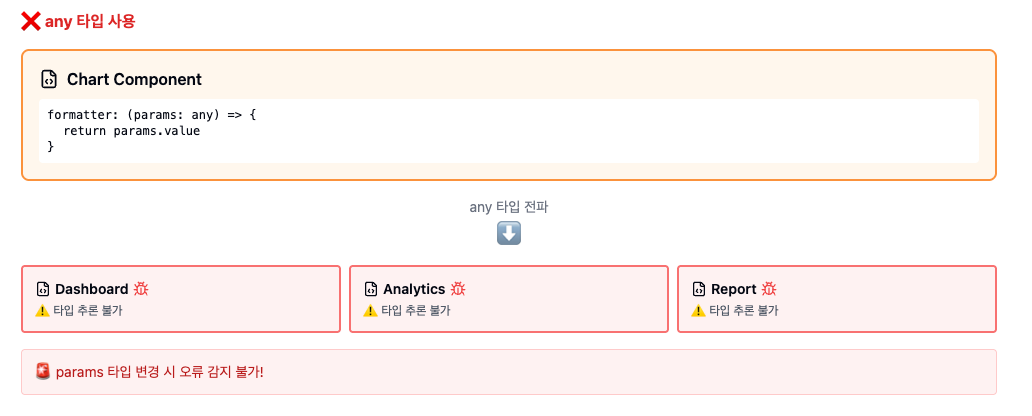
그런데도, 의존하는 모듈의 인터페이스 수정으로 연쇄적인 수정이 발생할 수밖에 없는 상황이 있다. 그런 경우에는 견고한 타입 시스템으로 컴파일 단계에서 수정 사항들을 모두 잡아낼 수 있게 해야 한다. 최근 프로젝트에서 많이 느꼈는데, 다른 컴포넌트에서 많이 의존해야 하는 모듈이라면 절대 any 타입을 사용해서는 안 된다. 그러한 모듈에서 생성된 any 타입은 수많은 컴포넌트에 전파되어 오염시키고, 결국에는 해당 모듈에 대한 수정이 불가능한 수준이 되어버리는 경우도 있었다.
다만 외부 의존성에는 타입을 파악하기 어려운 라이브러리가 분명 있긴 하다. 사내에서는 echart 라이브러리를 사용하는데 formatter의 콜백 파라미터 타입을 정확하게 제공해 주지 않는다. 차트 타입과 옵션에 따라 파라미터의 값이 바뀌기 때문에 어쩔 수 없기도 하다. 그렇다면 이러한 상황에서는 어떻게 하면 좋을까?
나는 개인적으로 두 가지 해결책을 두는 편이다.
- 타입을 명시하기 어려운 공용 컴포넌트 에서는 타입에 제약 조건을 할당하거나,
unknown을 할당한다. - 사용하는 코드 에서는
assertType함수와zod스키마 검증을 통해 런타임 검증 되게 한다.
코드를 예시로 알아보자. 아래는 any 타입을 사용하는 경우다:
// ❌ echart formatter에서 any 사용
const chartOption = {
formatter: (params: any) => {
return `${params.name}: ${params.value}`
}
}
// any가 전파되어 타입 체크 무력화
function processChartData(data: any) {
// data.value가 number인지 string인지 알 수 없음
// API 변경 시 런타임 에러 발생
return data.value * 100
}any 타입으로 인해 컴파일 타임에 에러를 통해 수정을 알아낼 수 없고, 런타임에서도 언제 어떻게 에러가 터질지 파악하기도, 예측하기도 어렵다.
아래는 unknown과 런타임 검증을 사용하는 경우다:
// ✅ 1. 공용 컴포넌트에서 unknown 사용
interface ChartProps {
formatter: (params: unknown) => string
}
// ✅ 2. 사용처에서 zod로 검증
import { z } from 'zod'
const ChartParamSchema = z.object({
name: z.string(),
value: z.number(),
data: z.unknown() // 가변적인 부분
})
const chartOption = {
formatter: (params: unknown) => {
const validated = ChartParamSchema.parse(params)
// 이제 validated.value는 확실히 number
return `${validated.name}: ${validated.value}`
}
}컴파일 단계에서는 여전히 알아낼 수 없지만, 런타임에서는 빠르게 에러를 잡아내고 디버깅 할 수 있게 된다.
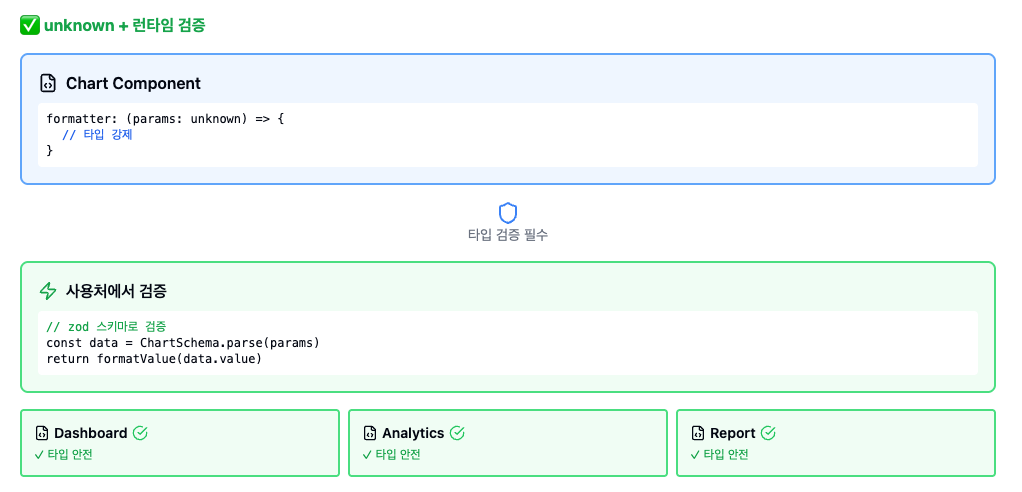
이처럼 제어할 수 없는 외부 의존성에 의존해야 하고 라이브러리가 제공하는 타입이 불확실한 상황이라면 방어적 프로그래밍을 통해 에러를 최대한 예측 가능하게 만드는 것도 높은 결합도에 대응하는 하나의 방법이라고 생각한다.
불필요한 의존 제거하기
가장 좋은 예제는 Props Drilling이 아닐까 하는 생각이 든다. 아래 이미지를 보자:
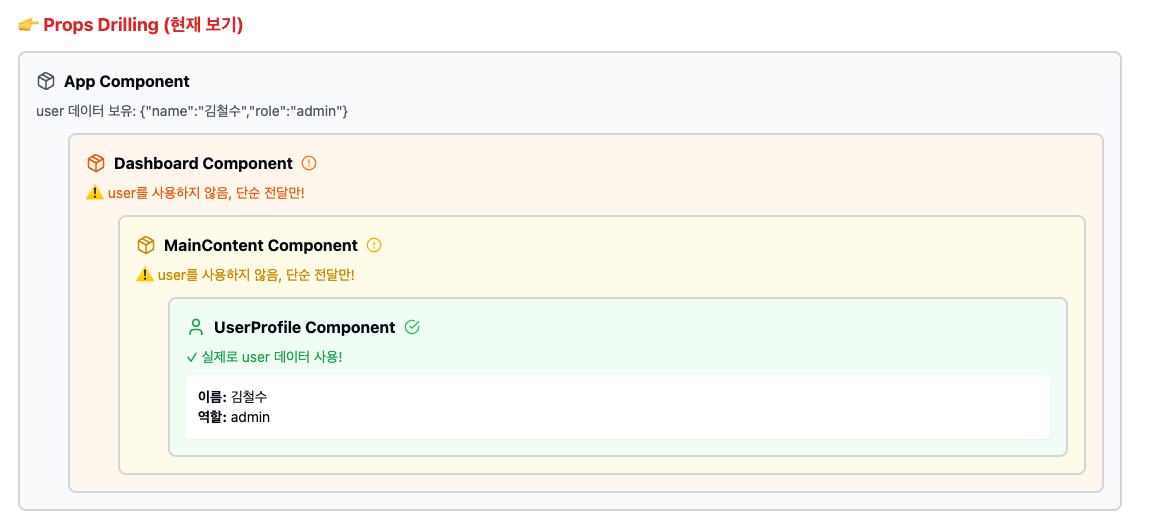
위 이미지에서 user 데이터는 UserProfile 컴포넌트에서만 필요하다. 하지만 이 값을 전달하기 위해 Dashboarad, MainContent 컴포넌트가 userData를 전달받아 다시 내려다 주고 있다. 나는 이러한 컴포넌트를 개인적인 용어로 "통로 컴포넌트" 라고 한다. 이 통로 컴포넌트는 userData에 대해서 전혀 알 필요가 없지만 데이터 전달을 위해 불필요하게 userData에 의존하고 있다. 그로인해 userData에 발생한 수정이 Dashboard, MainContent 컴포넌트에 영향을 주어 불필요하게 수정되어야 하는 상황이 생기게 된다.
이미지에도 나와 있지만 Context API를 사용한 데이터 공유를 통해 이러한 문제를 해결할 수 있다. Context API를 전역 상태 도구 정도로 이해하는 사람을 많이 본거 같다. Context API는 전역 상태 관리 도구가 아닌 데이터 공유 도구다. Context API를 사용하면 어떤 효과를 얻어낼 수 있을까?
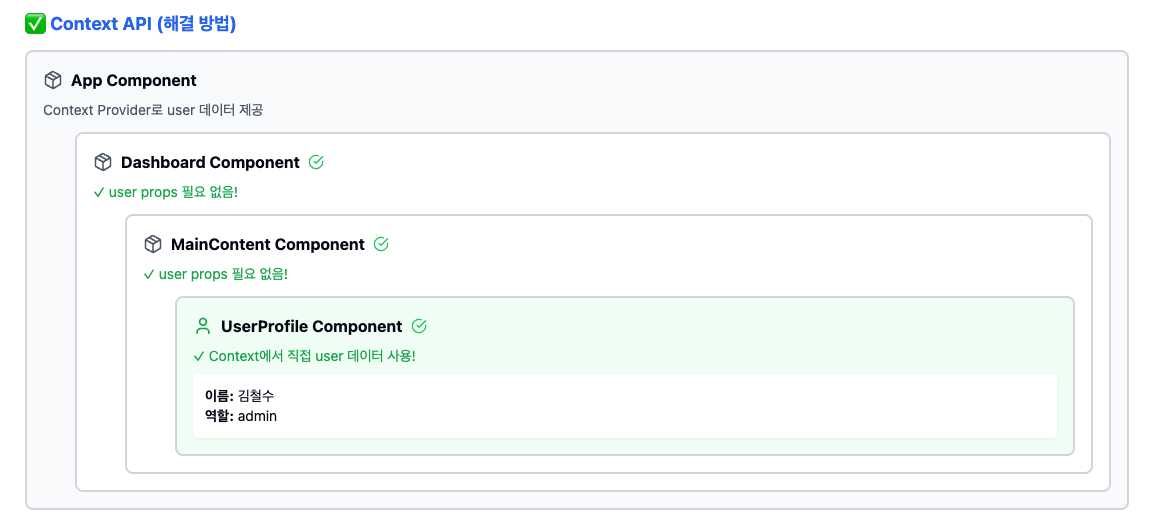
이처럼 수정해야 하는 범위를 획기적으로 줄일 수 있다. 이전에 Props Drilling에 대한 대안으로 Context API를 사용하는 것에 대해 동료와 이야기한 경험이 있다. 당시 동료가 했던 얘기는 depth가 어느정도 되면 Context API를 사용하나요? 였다. 내 개인적인 생각에 Context API를 사용해 Drilling을 해결하는건 depth의 문제가 아니다. Context API를 도입해 수정해야할 범위를 줄일 수 있다면 적극적으로 도입하는 편이다. 물론 주입하는 데이터를 어디에서 소모하는지 데이터 흐름 추적이 어려워 지는 트레이드오프가 있긴 하다. 다만 그보다 Context API를 사용해 수정 범위를 줄이는것의 효과가 더 크다고 판단되면 도입한다.
결론
클린코드 관련 글을 쓰고 싶었고, 거의 2달 정도 준비했다. 다만 결과는 이렇게 부실한 글이 나오게 되었다. 자료 조사나 공부는 물론 많이 했다. <은탄환은 없다>, <타르 웅덩이 밖으로>, <클린 코드>, <클린 아키텍쳐> 등등 정말 다양한 책과 글을 통해 자료를 모았고 글을 쓰려 했지만, 내용이 너무나도 방대하고 글을 잘 다룰 자신이 없었다.
그래서 어떤 글을 쓸까 고민하다, 최근 리팩토링을 진행하며 얻었던 인사이트를 토대로 클린코드 라는 주제에 항상 등장하는 응집도, 결합도, 추상화 라는 단어를 직관적이고 쉽게 풀어보자는 생각을 하게 되었다. 사실 그렇게 잘 풀어내진 못한것 같다. 공부하면 공부할수록 한없이 작아지는 주제가 아닌가 싶다.

17개의 댓글


안녕하세요. 좋은 글과 생각 나눠주셔서 감사합니다!
추상화 부분에서 궁금한 점이 있어 댓글 남깁니다.
기존의 handle... 함수를 linkage로 바꾸면 1,2번 문제를 해결할 수 있다고 하셨는데, 여기가 이해가 잘 안되어서요. 어떻게 히스토리랑 filter 정보 유지가 가능한가요?
어떻게 대응 가능한지 잘 몰라서 여쭈어봅니다.


저도 역시 좋은 코드의 가장 중요한 요건은 "수정하기 쉬워야 한다" 라고 생각하고 있고, 시간이 갈수록 이 생각은 점점 강해지고 있습니다. 좋은글 감사합니다.

좋은 글 감사합니다! 글을 읽고 돌이켜보니 최근에 제가 사내에서 짰던 코드들이 수정하기 참 어려웠다는 생각이 드네요.. 더 깔끔한 코드를 짜도록 노력해야겠습니다!
훌륭한 코드가 무엇이며 왜 좋은 코드를 작성해야 하는지에 대한 귀하의 생각에 전적으로 동의합니다. 특히 "변화에 잘 대응하기 위해서" 라는 핵심 메시지와 "수정하기 쉬운 코드"가 좋은 코드의 가장 중요한 조건 중 하나라는 점에 깊이 공감합니다. 헤라클레이토스의 명언과 애자일 선언문을 인용한 것도 매우 적절하다고 생각합니다. https://www.dogsounds.net

안녕하세요! 저는 이제 막 1년차가 된 FE엔지니어입니다! 저는 최근에 좋은 코드에 대해 관심을 가지게 되었고, FSD, 클린코드, 클린 아키텍처 등을 공부하기 시작했는데, 대부분의 자료에서 예제가 자바로 구현되어 있어서 프론트엔드(TypeScript)에 적용하기 힘들기도 했고, 이론적인 용어들을 볼 때면 직관적이지 않아서 이해하기 힘들었습니다.. 그런데 이번 아티클에서 정말 직관적이게 설명해주셔서 저에게 정말 큰 도움이 되었습니다!
특히 "두 페이지 이상에서 재사용 되는 모듈이 아니라면 feature, entity, widget 등으로 분리하면 안 된다." 는 개념이 와닿았습니다 :) 그냥 감사의 말씀을 드리고 싶어서 댓글 남깁니다!!
우와! 너무 좋은 글 잘봤습니다. AI시대에는 점점 더 삭제하기 좋은 구조가 중요해진다 생각하고 있는데 응집도에 대한 이해를 폴더 째로 삭제하기에 좋은 구조라고 생각하는 멘탈모델은 참 좋네요.
제공되는 아키텍쳐의 구조의 배경이 아니라 분류법 그자체에만 매몰되는 경향이 있는데 결국에는 기본기가 참 중요한것 같아요~ 좋은 글 잘 봤습니다 :)