개발동기
원티드x한국관광공사 프롬프톤 대회
저와 평소 친하던 옛 회사 동료 세분과 함께, 원티드와 한국 관광공사가 주최하는 프롬프톤 대회에 참여했습니다. 이 대회는 LLM을 편하게 사용하고 개발하고 협업할 수 있도록 도움을 주는 원티드(채용 사이트 맞습니다)의 LaaS(LLM-as-a-Software)를 사용하여 서비스를 만드는 대회입니다. 이번에는 한국관광공사와 협업하여 TourAPI를 사용하여 서비스를 만드는 대회로 주최되었습니다.
저희는 작년에도 같은 대회에 나가서 상을 탔었습니다. 작년에 같이 개발을 하고 대회를 준비하며 좋은 기억이 많았기에, 이번에도 팀원들과 함께 대회를 나가게 되었습니다. 이번 포스트에서는 대회를 준비하며 사용했던 여러 개발 도구와 실제 서비스 출시를 위해 했던 여러 작업들, 고려사항들의 모든 내용을 기록하고자 합니다. LLM, 데이터 크롤링, DB 입출력, 자원분배 등 다양한 부분에서 실제 서비스 상황에서 발생가능한 문제들에 대해서 신경써서 작업했기에, 그 기록을 남기고 싶었습니다.
1인 개발 혹은 소규모 개발을 해서 LLM 관련 서비스를 출시하시려는 분들의 시행착오를 덜 수 있기를 기대하며, 포스팅을 시작합니다.
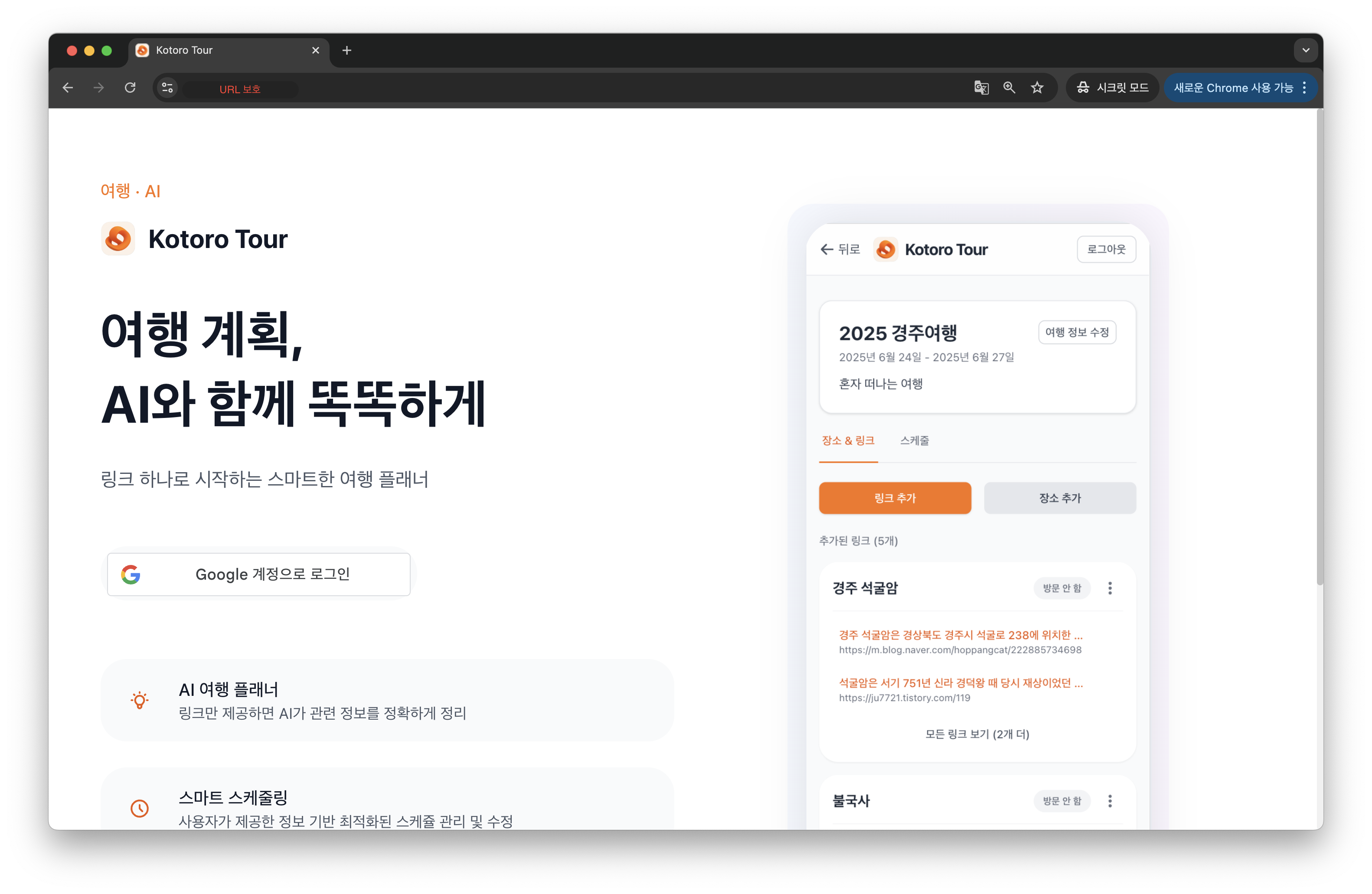
무슨 서비스를 개발했나요?
저는 여행을 다니는걸 좋아합니다. 친구와 여행을 계획하다보면 아래처럼 여러 블로그 글을 수집하는 일이 많습니다. 맛집도 저장하고, 어디 갈지, 여행 꿀팁 등도 작성하곤 합니다. 그리고 마지막으로 일정을 대충 만들어서 메모를 보고 다니곤 합니다.
 |  |
|---|
왜 이런 일정을 짰지? 하고 생각해보면 사실 기억이 안날때가 많습니다. 분명 블로그 어디에서 봤었는데, 기억이 잘 나지 않습니다. 또한, 관련해서 여러 내용을 찾아봤었는데, 그 내용이 뭐였는지 잘 생각나지 않습니다.
저는 이런 저의 개인적 불편함에서 출발해서, AI를 활용한 스마트 여행 플래너를 개발해보고자 하였습니다.
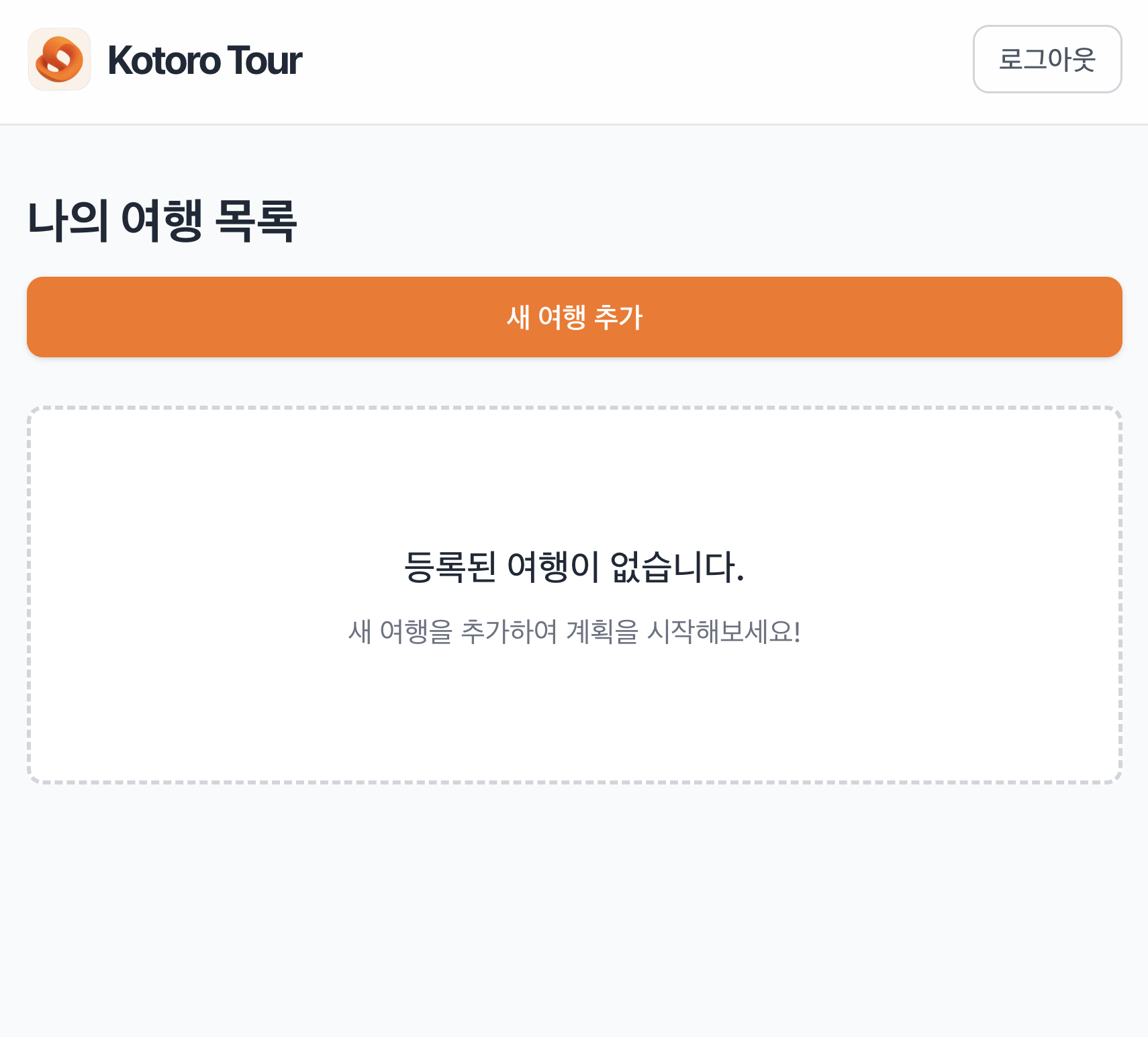
저희 서비스에 처음 로그인을 하면 위와 같은 화면을 마주하게 됩니다. 여기서 새로운 여행을 추가할 수 있습니다.
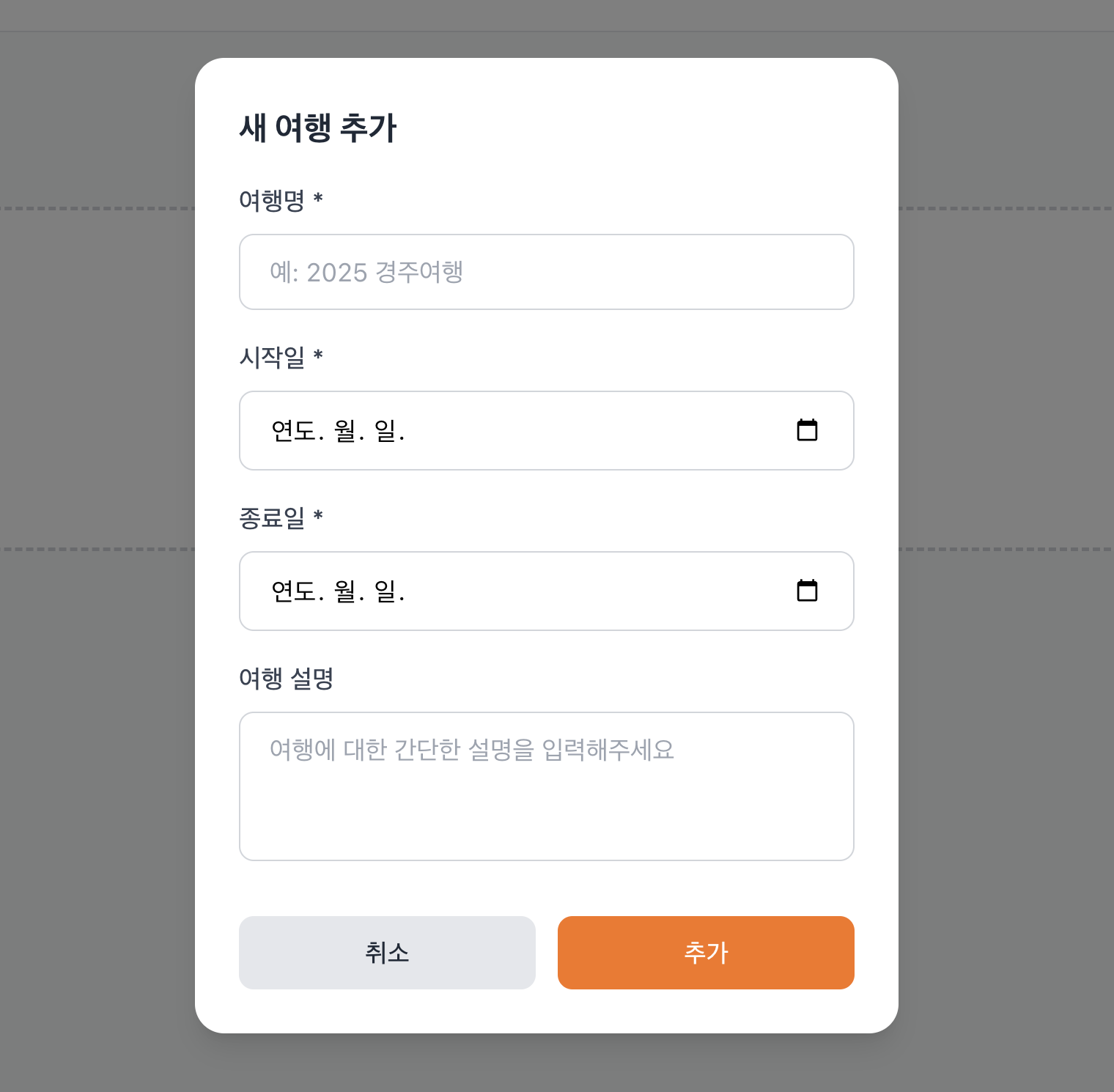
시작일과 종료일, 여행 설명 등을 입력하면, 새로운 여행을 시작할 수 있습니다.
저희 서비스는 총 3가지 메인 기능을 지원합니다.
1. 새로운 링크 추가하기 & AI 링크 분석
여행을 준비하며 봤던 블로그 글을 링크 추가하기를 통해 추가할 수 있습니다. 그럼 아래 그림처럼 AI가 자동으로 링크를 분석해서 링크 내에 있던 장소를 분석하고 각 장소에 대한 내용을 요약해서 보여줍니다.
링크를 그냥 제목과 관광지로 분류하는 것이 아니라, 링크와 장소, 요약에 대한 여러 정보를 자동으로 정리할 수 있기 때문에 여행에 대한 관리를 편하게 할 수 있습니다.
 링크 추가하기 전 링크 추가하기 전 | 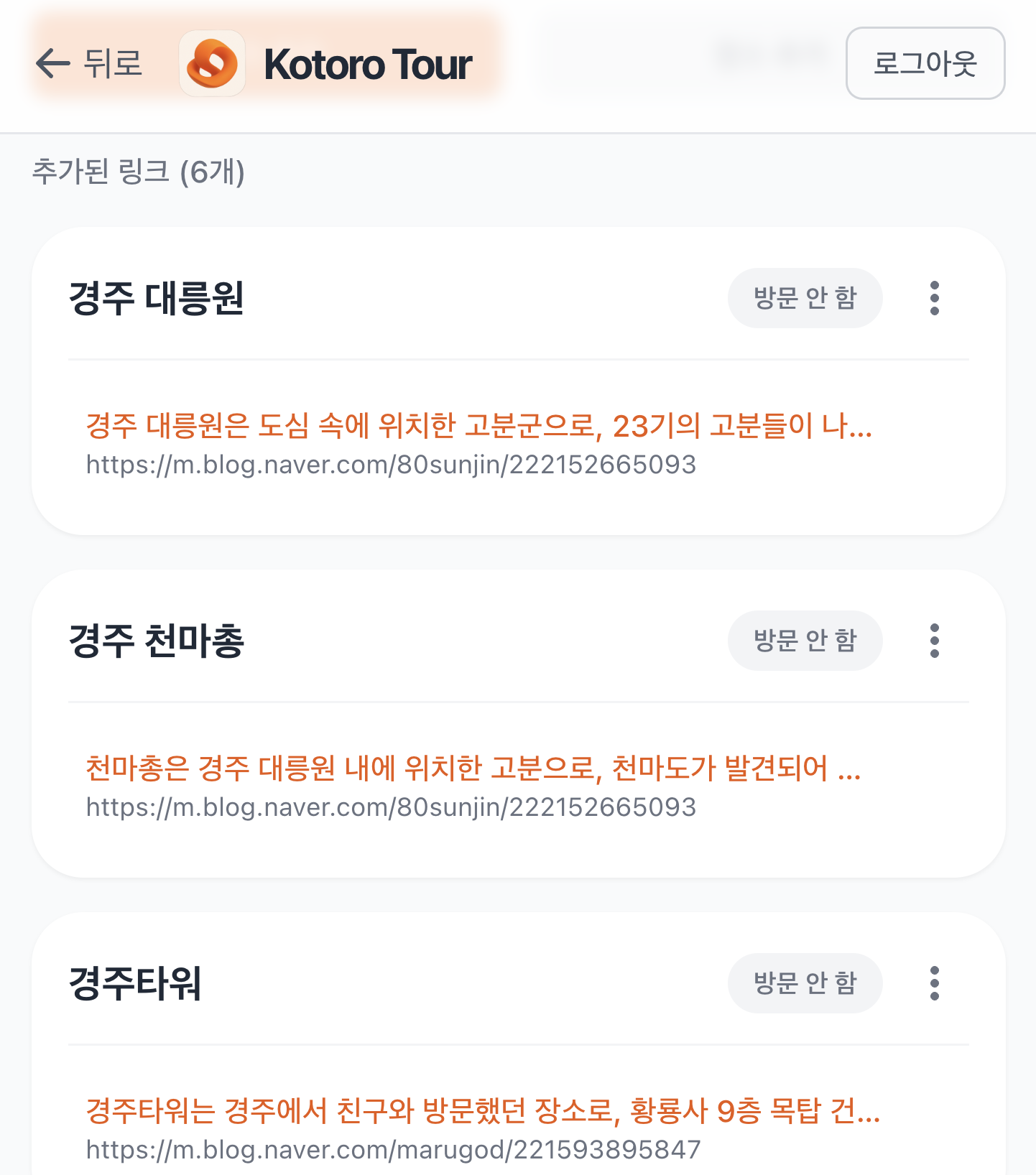 링크 추가한 이후 링크 추가한 이후 |
|---|
2. AI 스케쥴 생성
스케쥴을 짜는 것이 귀찮을 때가 많습니다. 여러 블로그의 내용을 종합적으로 고려해서 안붐비는 시간, 주차, 사진 잘나오는 시간 등 고려할 사항이 매우 많습니다. 저희는 AI를 사용하여 이 블로그의 정보들을 종합하여 스케쥴을 계획할 수 있도록 했습니다. 이를 통해 여러 블로그를 반복적으로 보고 기억하는 수고를 덜 수 있습니다.
AI가 생성한 일정이 맘에 안들거나, 고치고 싶은 경우가 많을 것 입니다. 저희는 자연어를 기반으로 일정을 수정하거나 직접 방문 일정을 수정할 수 있도록 기능을 제공합니다.
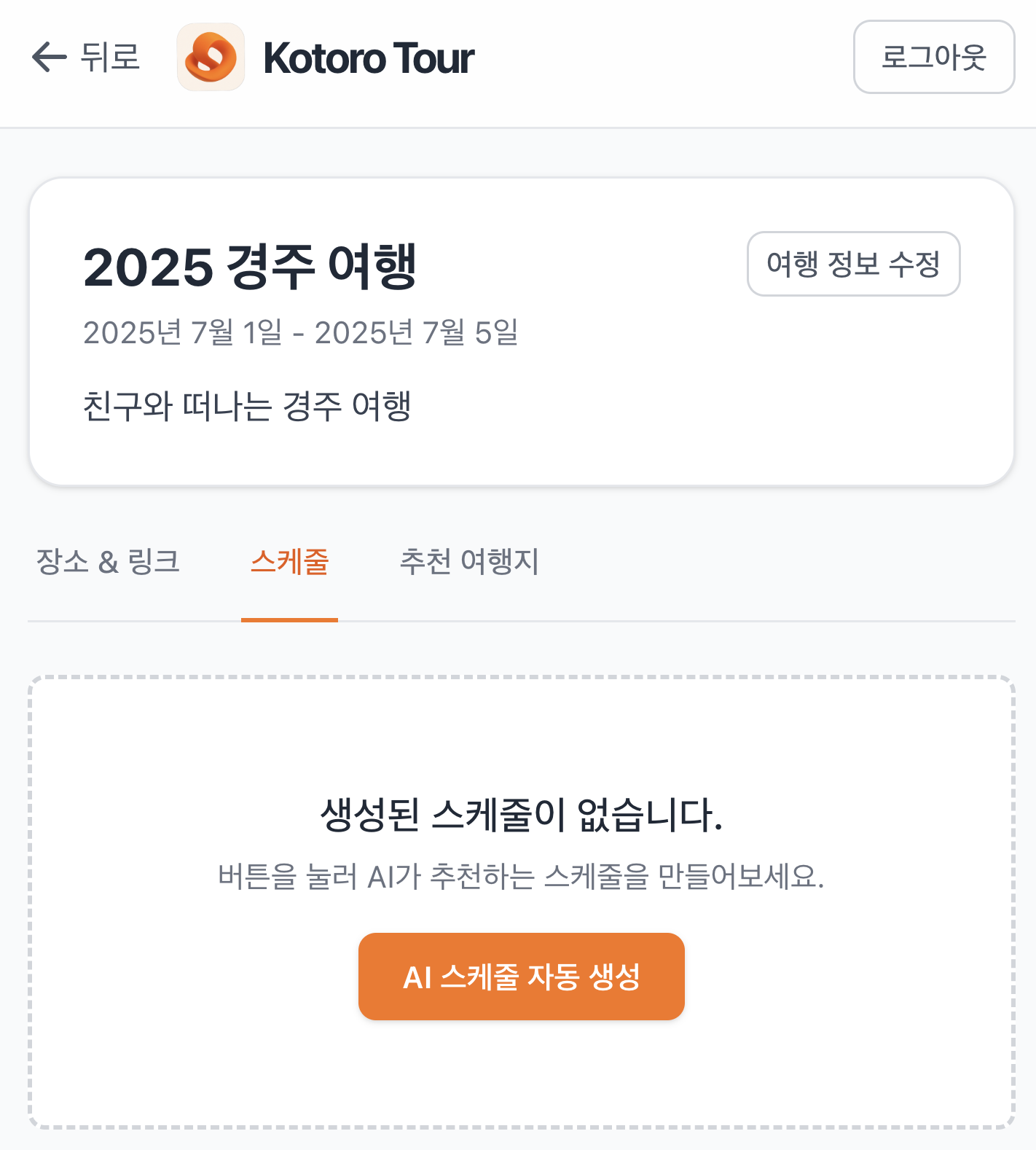 스케쥴 생성 전 스케쥴 생성 전 | 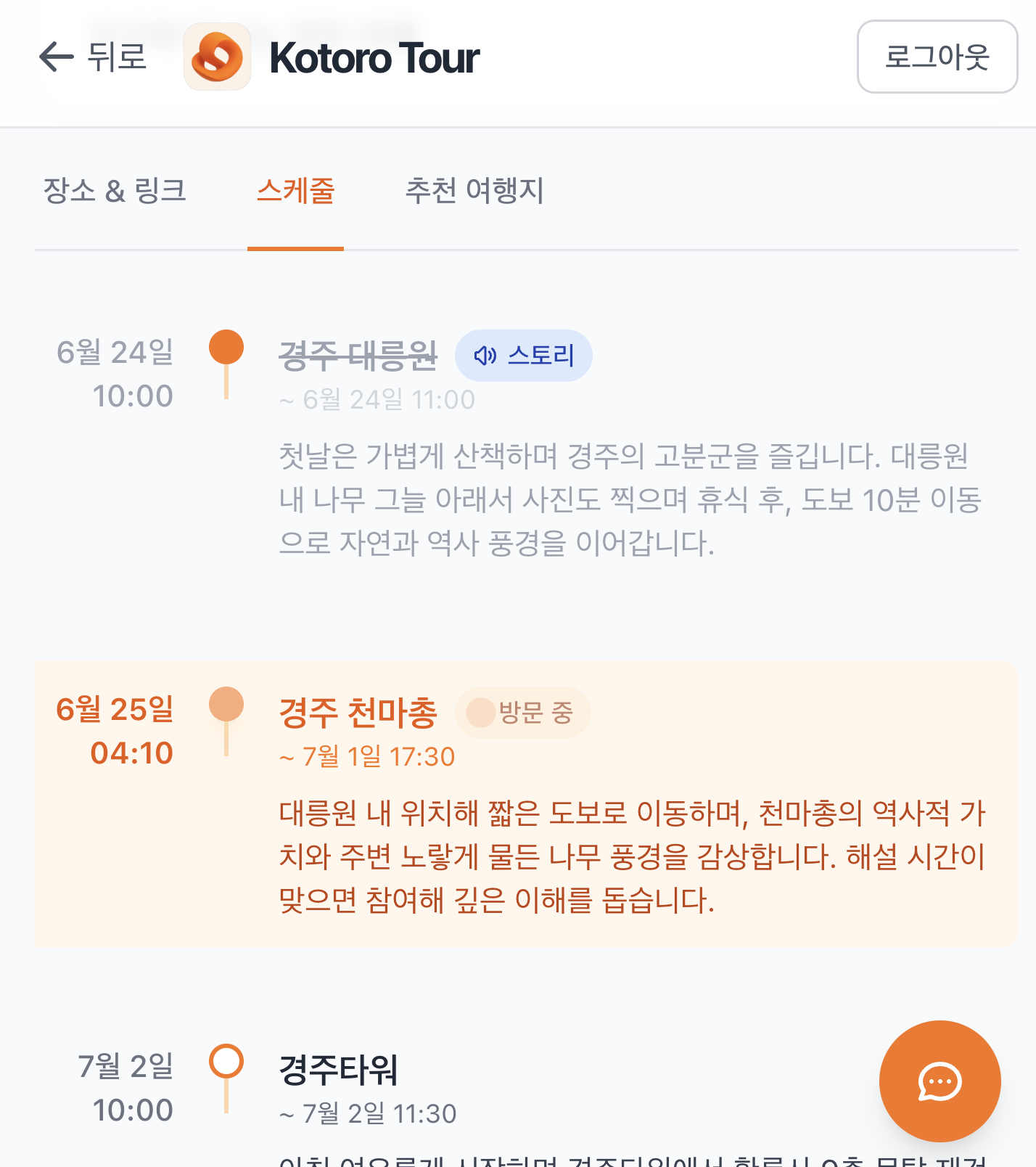 스케쥴 생성 및 여정 모니터링 스케쥴 생성 및 여정 모니터링 | 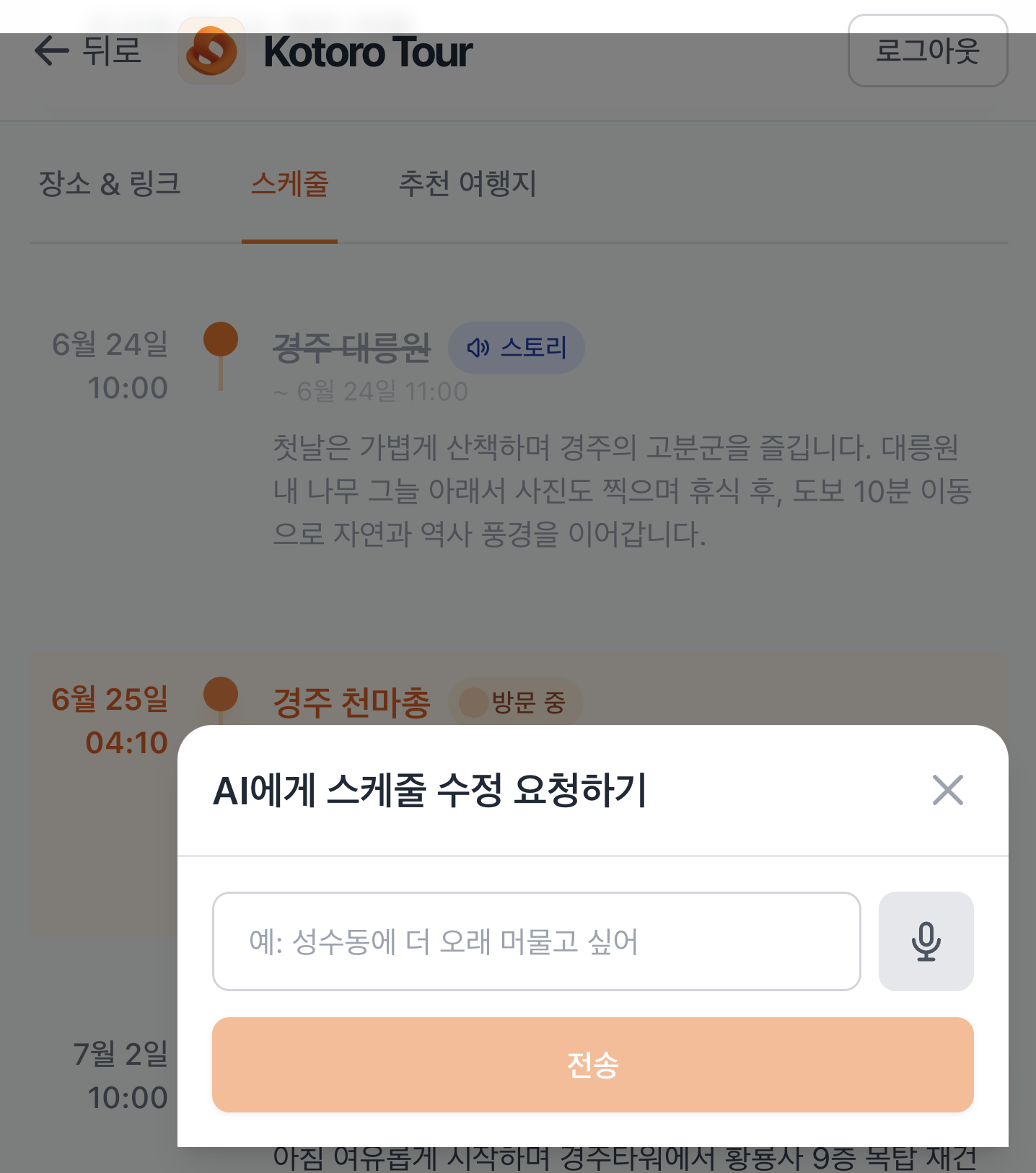 AI 스케쥴 수정 요청 AI 스케쥴 수정 요청 |
|---|
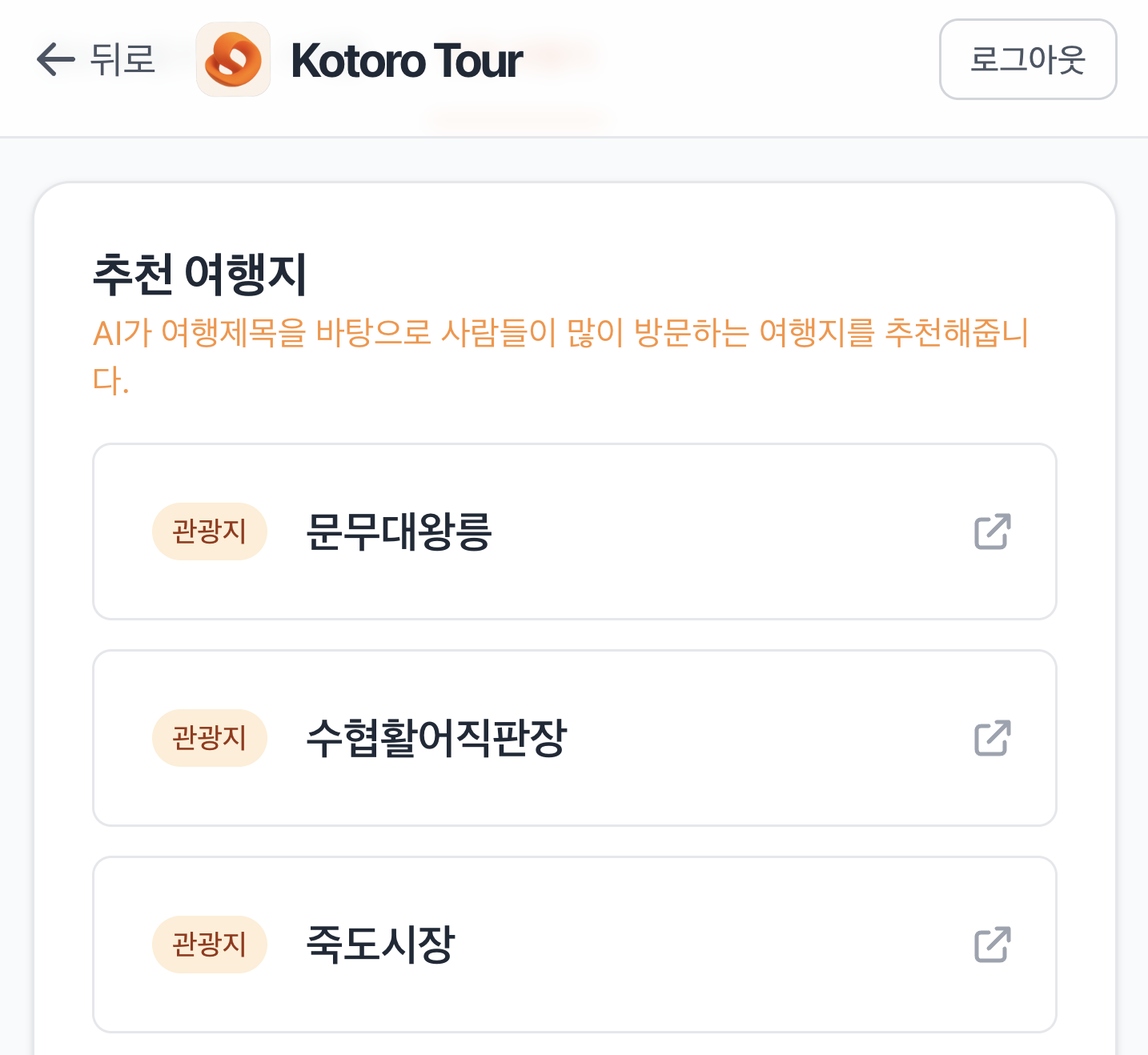
3. 추천 여행지
여행을 계획하다보면, 어디를 가야할지 고민되는 경우가 많습니다. 저희는 한국관광공사의 TourAPI와 LLM을 사용하여 사용자가 작성한 여행 제목과 관련된 추천 여행지를 추천해서 처음 여행 기획하는 사람이 여행 정보 탐색을 손쉽게 시작할 수 있도록 지원합니다.
그외에도..
그 외에도 더 많은 기능이 있습니다. 구글 OAuth로그인, 링크 처리, 크롤링 등 더 많은 기능이 있지만 길이상 미처 소개드리지 못했습니다. 대회가 마무리 된 이후, 좋은 결과가 있다면 서비스를 공개해보도록 하겠습니다.
개발 여정
백엔드 개발하기
저희는 백엔드를 FastAPI를 사용하여 개발했습니다. 가장 큰 이유는 일단 개발팀 전부가 AI/ML Engineer로 파이썬에 익숙하기 때문입니다. Flask나 Django를 고려하지 않은 이유는 외부 LLM을 호출하거나 크롤링을 할 때, 비동기적 작업을 빠르게 수행해야 하는데, FastAPI가 이에 최적화된 라이브러리였기 때문입니다.
프론트, 백엔드, 인프라, LLM까지 모든 것을 개발해야 했기 때문에, Swagger를 통해 편하게 API를 테스트해볼 수 있고, 역할을 분배해서 작업할 수 있으며, 문서 작성의 수고를 덜 수 있었습니다.
비동기로 외부 API 사용하기
저희가 가장 신경쓴 부분은 외부 API를 사용하는 부분에서 서버가 Blocking되는 일이 없어야 하는 것이었습니다.
import requests
response = requests.get(URL)위와 같은 방법이 파이썬에서 가장 손쉽게 URL에 정보를 요청하는 방법입니다. 그러나 이 방법을 사용하면 파이썬의 GIL로 인해, 리퀘스트를 요청하는 동안 서버가 동작하지 않습니다. CPU자원이 여유로움에도 서버가 멈추는 현상이 발생합니다. 만약 API서버가 문제가 있거나, 인터넷 통신이 느린 환경이라면 API를 기다리는 동안 다른 서버의 Endpoint가 작동하지 않을 것입니다. 이러면 FastAPI를 사용하는 목적에 부합하지 않게 됩니다.
이를 해결하기 위해 비동기적으로 외부 API를 호출하는 것이 필요했습니다. 이를 위해 저희는 httpx라는 라이브러리를 활용해주었습니다.
async with httpx.AsyncClient(timeout=60.0) as client:
response = await client.post(api_url, headers=headers, json=data)
response_data = response.json()위와 같은 방법으로 API를 호출해주면 비동기적으로 외부 API를 호출할 수 있습니다. httpx를 쓴다고 다 해결되는 것은 아니었습니다.
import httpx
httpx.get(url)만약 위와 같이 httpx를 사용한다면, 이 방법은 동기적으로 API를 호출하기 때문에, requeset와 동일하게 동작합니다. 정확한 방법을 사용해주는 것이 중요합니다.
저희는 데이터베이스로 MongoDB를 사용해주었는데, 파이썬에서 많이 사용하는 pymongo의 경우 버전에 따라 비동기를 지원하지 않는 경우도 있음으로, motor라는 비동기적으로 몽고디비 클라이언트를 지원하는 라이브러리를 활용해주었습니다.
한정된 컴퓨팅 자원을 유저에게 고루 분배하기
LLM 서비스를 개발하다보면, 여러 제약조건을 마주하게 됩니다. 그 중 가장 큰 제약조건은 비용과 생성속도 제한입니다. 특히 악의적인 사용자가 많은 양의 리퀘스트를 동시에 요청한다면? 생성할 수 있는 속도는 제한적이기 때문에, 순차적으로 처리한다면 다른 유저들이 사용하지 못하게 되는 경우가 발생합니다.
저희는 크롤링도 같이 수행하였는데, 크롤링은 CPU자원을 많이 사용하기 때문에 쾌적한 사용자 경험을 위해 동시에 수행할 수 있는 크롤링의 양을 제한해야 했습니다.
이를 위해 저희는 두가지를 도입했습니다. 첫번째는 동시성 제한입니다.
import asyncio
from loguru import logger
class ConcurrencyLimiter:
def __init__(self, max_concurrent_tasks: int):
self.max_concurrent_tasks = max_concurrent_tasks
self.semaphore = asyncio.Semaphore(max_concurrent_tasks)
async def __aenter__(self):
await self.semaphore.acquire()
return self
async def __aexit__(self, exc_type, exc_value, traceback):
self.semaphore.release()
async def run_with_concurrency_limit(self, coro):
async with self.semaphore:
logger.info(f"Starting background task")
try:
result = await coro
logger.info(f"Completed background task")
return result
except Exception as e:
logger.error(f"Error in background task: {e}")
raise
def create_limited_task(self, coro):
return asyncio.create_task(self.run_with_concurrency_limit(coro))
위의 코드를 통해 동시에 수행할 수 있는 양을 제한하도록 설계하였습니다. 비동기적으로 설계된 함수를 넣어주면 이를 동시에 N개 만큼만 동시에 실행하고, 그 이상의 요청은 자동으로 기다렸다가 처리되도록 해주었습니다.
class BaseProcessingQueue(Generic[T]):
"""
사용자별로 처리 중인 항목을 관리하는 기본 큐 시스템
사용법:
1. 새로운 큐 타입을 만들 때는 이 클래스를 상속받아 구현
2. 제네릭 타입 T를 적절한 타입으로 지정 (예: str, int 등)
3. 필요에 따라 도메인별 메서드명을 제공하는 래퍼 메서드 추가
예시:
class MyProcessingQueue(BaseProcessingQueue[str]):
async def add_my_item(self, user_sub: str, item: str) -> bool:
return await self.add_processing_item(user_sub, item)
"""
def __init__(self):
# 사용자별로 처리 중인 항목들을 저장
# {user_sub: {item1, item2, ...}}
self._processing_items: Dict[str, Set[T]] = {}
self._lock = asyncio.Lock()
async def add_processing_item(self, user_sub: str, item: T) -> bool:
"""
사용자의 처리 중인 항목 목록에 항목 추가
Args:
user_sub: 사용자 식별자
item: 처리할 항목
Returns:
bool: 추가 성공 여부 (이미 처리 중이면 False)
"""
async with self._lock:
if user_sub not in self._processing_items:
self._processing_items[user_sub] = set()
if item in self._processing_items[user_sub]:
return False # 이미 처리 중인 항목
self._processing_items[user_sub].add(item)
return True두번째는 큐 시스템입니다. 사용자가 동시에 여러개의 링크를 넣을 수 있습니다. 만약 사용자별로 관리되지 않고, 전체 입력에 대해 큐를 관리하게 되면 특정 사용자가 악의적인 입력을 했을 때, 다른 일반 사용자들이 서비스를 이용하지 못하는 문제가 발생합니다. 왜냐하면, LLM들은 보통 초당 입력할 수 있는 토큰의 수가 한정되어있고, 여러 백엔드 자원이나 크롤링 같이 높은 자원을 필요로 하는 경우, 같이 사용할 수 있는 양이 제한되기 때문입니다.
저희 팀은 이에 최적화된 큐 시스템을 직접 설계했습니다. 비동기적으로 큐를 관리할 수 있도록 했는데, 모든 작업이 한개의 큐를 사용하는 것이 아니라, 사용자 별로 큐를 두도록 했습니다. 위에는 사용자별로 아이템을 더하는 예제만 있습니다. 이 외에도 큐 한도를 정하거나 현재 처리중인 요청을 조회할 수도 있습니다. 이를 통해 여러 사용자가 한정된 자원을 잘 이용할 수 있도록 설계에 반영하였습니다. 많은 자원이 소요됨에도 저희는 AWS의 작은 서버만으로 문제없이 많은 자원이 필요한 기능을 서빙을 하고 있습니다.
프론트엔드 개발하기
프론트앤드 개발방법
저희 팀에는 놀랍게도 프론트앤드를 개발할 줄 아는 사람이 없습니다. 한분은 AI와 게임엔진을 개발하시는 분이고, 둘은 AI만 해온 사람들입니다. 그럼에도 프론트앤드를 개발할 수 있던 것은 바로 바이브코딩 덕분입니다. 저는 Cursor가 유명해지기 오래전부터 써오던 사람입니다.
제가 출시한 세개의 서비스인 뉴스레터 / AI 성형 코디네이터 / 코토로 세개 모두 Cursor를 사용하여 최소한의 코딩으로 개발을 완료하였습니다.
이번 프로젝트에서는 React만을 사용해서 개발을 진행했습니다. Next.js와 같이 Server-Side Rendering을 할 필요성이 적었던 이유는 대회용이기 때문에 SEO를 잘 할 필요성이 떨어졌고, 저희의 기술 스텍과 맞는 파이썬과 FastAPI를 사용해 백엔드를 개발하고 싶었기 때문에, Client-side Rendering을 지원하도록 개발하였고, 정적 웹페이지로 만들어 배포하였습니다.
프론트앤드 코드의 97%가 커서로 작업되었고, 3%는 약간의 디자인이나 로직의 수정이 이뤄졌습니다. 제가 생각하는 바이브 코딩의 가장 중요한 것은 디자인과 사용자 경험입니다. AI에게 명시적인 디자인 요청과 사용자 경험 개선 요청이 없다면, AI로 만든 웹페이지는 양산형처럼 보여지게 되고, 누가봐도 AI로 대충 만든 웹페이지처럼 보이게 됩니다.
저는 이를 해결하기 위해, 명시적으로 어떤 색상, 어떤 바탕색, 어떤 디자인, 어떤 패딩을 줄 것인지 등의 디자인적 요소를 매우 자세하게 주었습니다. 하나의 디자인을 수정하는데에 거의 10줄 이상의 프롬프트를 작성하였습니다. 또한, AI가 덕지덕지 붙여서 개발한 기능을 어떻게 통합하고 사용자게에 보여주어야 더 좋은 경험을 줄지 직접 이야기해주었습니다.
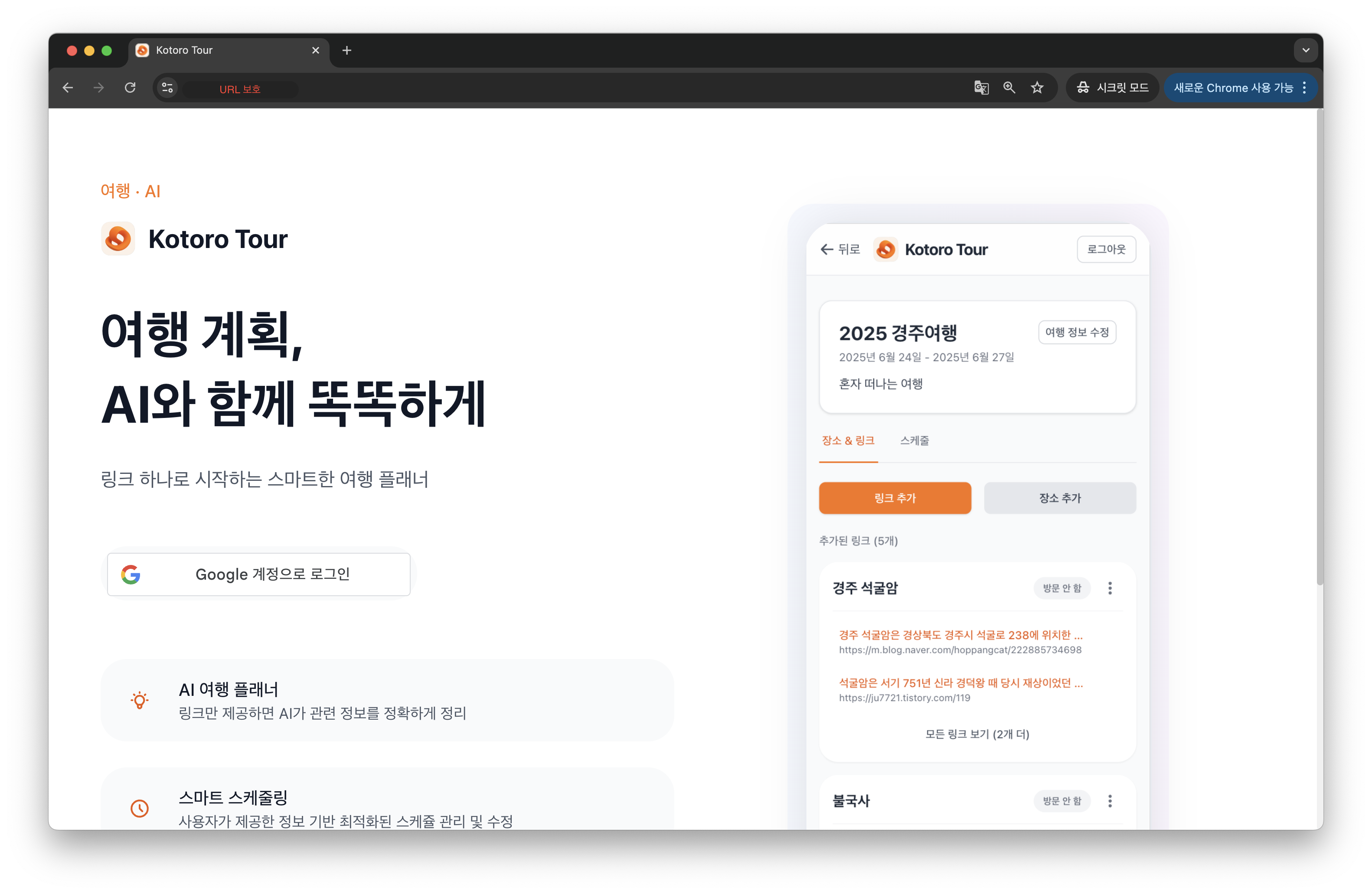
사실 바이브 코딩은 개발만 AI가 해주는 것이고, 그 외에 모든 것은 사람이 해주어야 합니다. 이런 관점에서 접근했고, 저는 아래와 같이 AI가 만든 티가 거의 나지 않는 소프트웨어를 개발할 수 있었습니다.
|  |
|---|
거의 무료로 프론트앤드 서빙하기
저희는 S3를 사용해서 서비스를 배포하였습니다. React를 npm run start를 해서 서빙을 하면 서버 비용을 내야하지만, npm run build를 해서 정적 파일을 만든 후 S3로 배포하면, 복잡한 연산을 프론트에서 처리하기 때문에 EC2와 같은 컴퓨팅 자원 없이도 서빙을 할 수 있습니다.
S3로 개인용 혹은 포트폴리오용 홈페이지를 만들어 서빙할 경우, 거의 0원에 가까운 비용이 청구됩니다. 후에 옵스 세팅에서도 말씀드리겠지만, HTTPS, URL 라우팅 등도 손쉽게 할 수 있습니다. S3로 나만의 웹페이지를 공개하는 방법은 구글에 많이 있으니 관심있으신 분들은 한번 찾아보셔서 직접 본인의 홈페이지를 만들어보시는 것부터 시작해보시길 추천드립니다. 저도 처음에 제 개인 페이지를 만드는 것부터 시작해보았습니다.
구글 OAuth를 사용한 로그인 구현하기
저희는 별도의 회원 관리 시스템을 만들고 싶지 않았습니다. 회원가입, 로그인, 비밀번호 찾기, 이메일 인증 등을 직접 구현하고 웹페이지에 넣다보면 대회를 위한 핵심 기능보다 부차적인 기능에 더 집중하게 될 것 같았습니다. 그래서 저희는 구글 로그인만을 지원하도록 했습니다.
구글 SSO 로그인은 생각보다 구현하기 쉽습니다.
구글 클라우드 플랫폼 (GCP)에서 사용자 인증정보를 만들고, 구글에 서비스를 한다고 신청하기만 하면 무료로 사용할 수 있습니다. 구글 로그인을 통해 클라이언트에서 토큰을 획득하고, 이 직접 구축한 서버에 전송합니다. 서버는 다시 구글API와 통신하여 이 사용자가 정상적인 사용자인지, 토큰이 유효한지 등을 검사합니다. 정상적이라면 해당 토큰으로부터 사용자의 이메일과 사용자의 인증 아이디(실제 아이디와 다름)를 얻게되고, 이 인증 아이디로 사용자를 식별할 수 있습니다.
필요하다면 추가 정보를 입력받아 이 사용자 인증 아이디와 매핑 시킬 수 있고, 저희는 사용자를 식별하는 PK로 사용해주었습니다. 저희는 서버와 GCP세팅만 진행해주었고, 프론트앤드는 이 정보를 바탕으로 AI에게 코드를 작성하도록 했습니다. 이런 관련 예제가 인터넷에 많기 때문에, 매우 높은 퀄리티의 코드를 받을 수 있었습니다.
개발 옵스 세팅하기
AWS 인프라 설정 (EC2, HTTPS, URL, CDN)
아마 모든 개인 개발자가 그렇겠지만, 저희의 가장 큰 화두는 '비용'이었습니다. 적절한 서버를 선택하지 않으면, 서비스도 하지 않았는데 높은 서버 비용으로 피눈물을 흘리는 경우가 많기 때문입니다. 저희가 각 서비스를 선택한 이유와 고려사항을 살펴보시고, 본인의 개발에 맞는 적절한 솔루션을 찾으시기를 바랍니다.
먼저 저희는 AWS를 사용해주었습니다. 네이버클라우드나 GCP, 혹은 가비아와 같이 더 저렴하고 좋은 서버를 대여할 수 있는 클라우드 업체들이 있습니다. 저희가 AWS 선택한 가장 큰 이유는 '익숙함' 때문입니다. 저는 여러 B2C 회사들을 다니며 AWS를 오랜시간 경험했고, AWS를 선택하게 되었습니다. 만약 다른 플랫폼이 익숙하시거나, 익숙한 클라우드 플랫폼이 없다면 비용에 따라, 혹은 내가 가고 싶은 회사의 기술 스텍에 따라 선택하시길 추천드립니다.
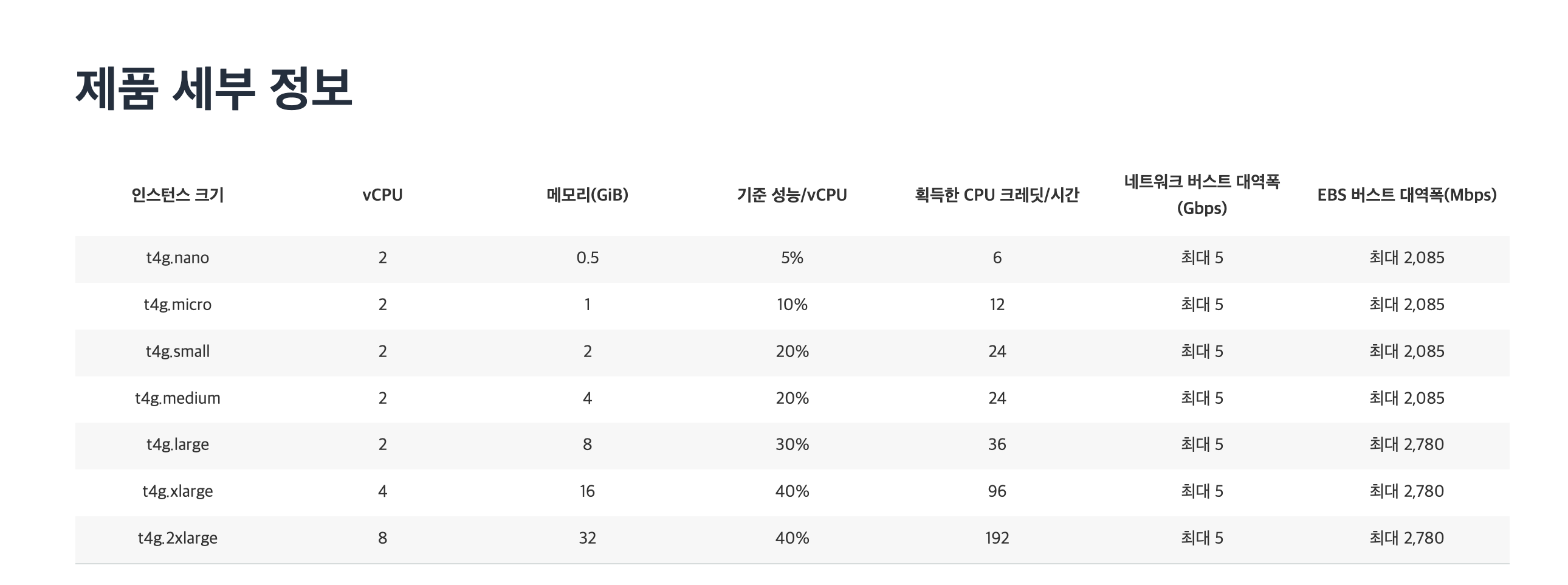
저희는 저렴한 서버인 t4g.micro 를 사용해주었습니다. 이 서버는 ARM기반의 아키텍쳐로(Graviton), 기존 다른 CPU대비 동일 가격에서 40~60% 가량 더 좋은 성능을 보여준다고 알려져 있습니다. t2.micro가 한국 리전에서는 1년간 무료로 제공되나, 저희는 크롤링과 같이 CPU 집약적인 기능이 많이 들어가기 때문에 t2.micro보다 높은 성능을 보이는 인스턴스를 선택했습니다.
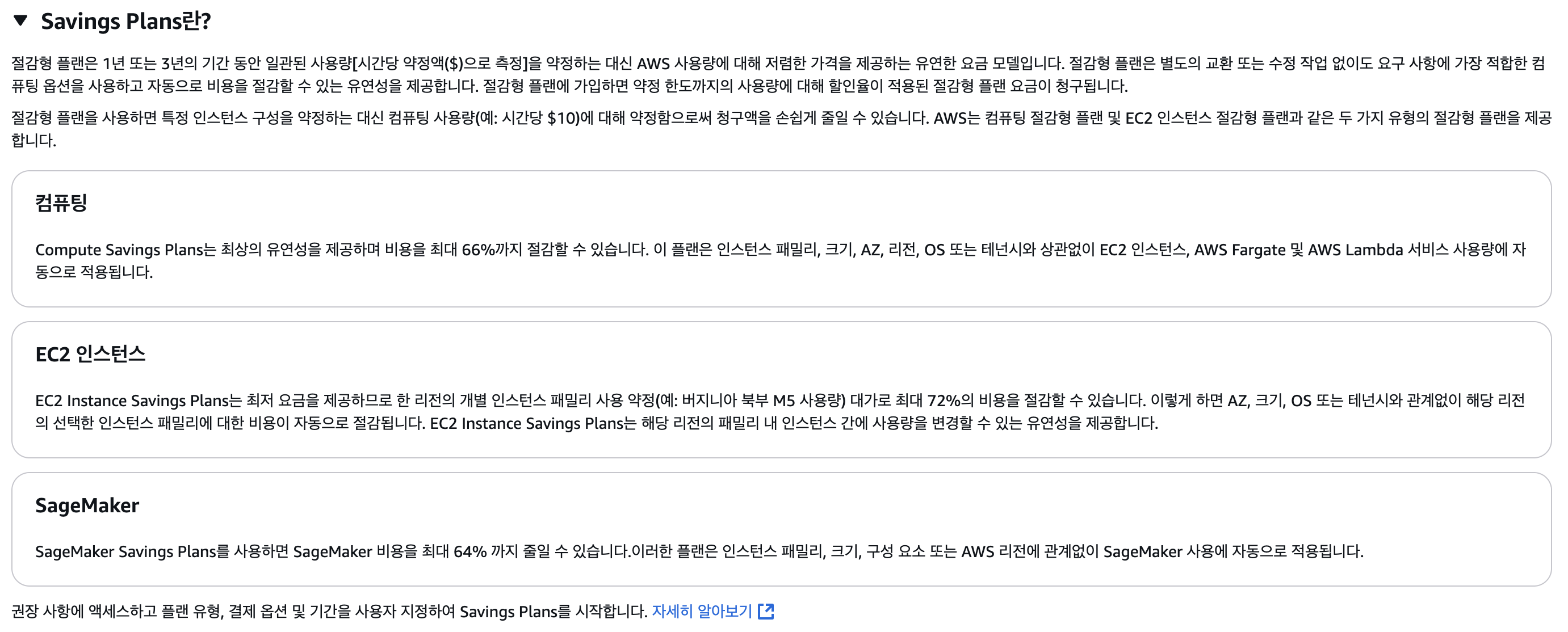
저희는 Savings Plan을 통해 1년동안 정액으로 요금을 내도록 했고, 30% 할인을 받아서, 월에 5$ 수준으로 돈을 지불하고 사용하고 있습니다. 이 서비스 이후, 다른 서비스를 이 서버를 사용하여 배포할 계획이었기 때문에 1년치 요금을 내는 것으로 계약하고 비용할인을 받았습니다.
만약 서비스가 언제 그만둘지, 얼마나 오래할지 모른다면 Free Tier를 사용하거나 Savings Plan, 예약 인스턴스 등을 사용하지 않으시는걸 추천합니다. 만약, 더 저렴하게 구현하고 싶다면 AWS Lambda를 통해 거의 무료로 서버리스 환경에서 파이썬 서버를 구축할 수 있습니다. 저희는 크롤링이나 state를 들고 있어야 하는 기능을 구현했기에 클라우드 컴퓨팅 자원을 구매했습니다.
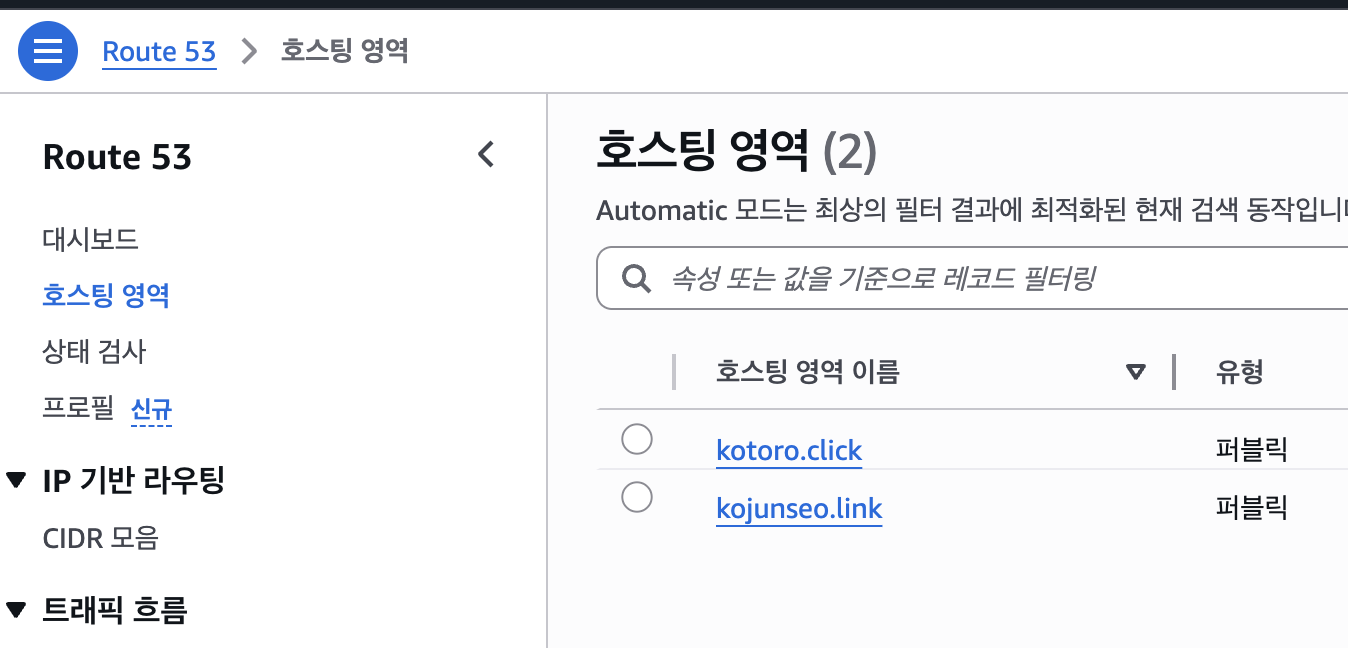
URL 구매는 Route53을 통해서 했습니다. 제 개인 URL과 제가 운영하는 서비스의 URL을 여기서 구매했습니다. 물론 더 저렴한 URL도 있지만, 저는 관리의 편의를 위해 AWS에서 각각 1년에 3로 구매했습니다.

다음은 Cloudfront CDN입니다. 여러 엣지 로케이션에 데이터를 미리 보관해두었다가 빠르게 전송하기 위한 목적으로 사용합니다만, 저희는 HTTPS 적용을 위해 사용해주었습니다.
프론트앤드의 경우
S3 -> Cloudfront -> Route53 -> User
위의 순서로 배포가 됩니다. S3에서 직접 정적 페이지를 배포해도 되고, S3에 직접 접근하는 것을 막고 Cloudfront에서만 배포가 되도록 할 수도 있습니다. (후자가 더 안전합니다) S3에서는 보통 HTTP로 데이터를 전송하고, Cloudfront가 이를 HTTPS로 변환할 수 있도록 해줍니다. 이를 위해서는 Amazon Certicifation Manager(ACM)을 통해 HTTPS 인증서를 발급받고 Cloudfront와 연동해주어야 합니다. ACM은 AWS 서비스를 사용할 경우에 한해서 무료로 제공됩니다.
백엔드의 경우도 비슷합니다. Load Balancer(ALB)를 사용해야만 HTTPS를 쓸 수 있다고 하는 글이 있는데 이는 사실이 아닙니다. ALB는 여러대의 서버를 연동해서 하나의 엔드포인트로 받을 수 있도록 밸런싱을 해주는 역할입니다. 그래서, 한대의 서버를 사용하는 경우에는 필요도 없고, 사용하면 연결되어있기만 해도 월에 2만원 정도 요금이 청구됩니다.
EC2 -> Cloudfront -> Route53 -> API Endpoint
로 구성하면 서비스가 대박나기 전까지는 무료로 HTTPS API 서버를 구축할 수 있습니다. 자세한 방법은 제가 참고한 다른 블로그를 참고해보세요.
저와 동일한 방법으로 구축하셨다면 아래와 같은 요금표를 받게 되실겁니다.
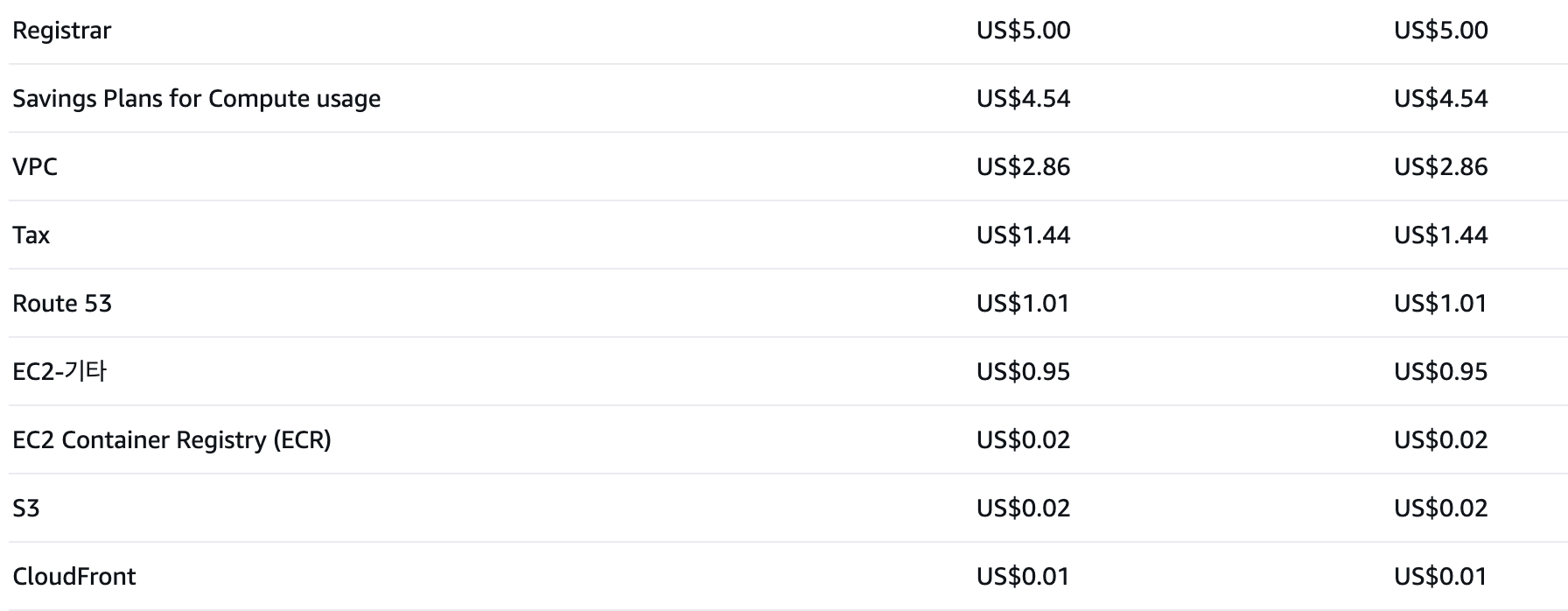
Registrar는 도메인 등록비용이고, 1년에 1회만 청구됩니다. 그 외에 VPC는 EC2를 사용할 때 네트워크 비용이라고 생각해주시면 됩니다. Route53도 제가 URL을 2개 들고 있어서 그렇고, 한개면 0.5$입니다. 그 외에 비용은 무시해도 될 수준입니다. 이 방법을 통해 API서버, 프론트앤드, HTTPS, URL등을 모두 통틀어 월 만원 내외로 안정적으로 서비스를 운영할 수 있습니다.
이 서버가 부족할 정도로 사용자가 몰리면? 그 때는 비용 걱정하지 않으셔도 될겁니다ㅎㅎ 아마 그 이상으로 돈을 버실 수 있으실 겁니다.
무료로 데이터베이스 구축하기 (feat. Atlas)
열심히 서버비용을 아꼈는데, 데이터베이스 비용은 어떨까요? 사실 제일 비싸고 병목이 심한 것이 이 데이터베이스라고 해도 과언이 아닙니다. 서버는 수평적 확장(한개의 서비스를 위해 여러대의 서버를 두는 것)이 용이합니다. 데이터베이스만 같으면 처리는 여러대의 서버에서 해도 무방하기 때문이죠. 하지만 데이터의 무결성을 보장해야하는 데이터베이스는 수평적 확장이 어렵습니다. 그렇기에 데이터베이스는 수직적 확장(크기를 키우는 것)이 필수적입니다.
여러 서비스를 비교해보았고, 서비스를 첫 출시하고 유저가 일정 이상 모일 때까지 사용할 만한 솔루션을 찾아보았습니다.

첫번째는 AWs DynamoDB입니다. 대용량 데이터 처리도 문제 없고, 서버리스이기 때문에 엄청난 양의 데이터를 읽고 쓰거나, 빈도가 높지 않는 초기 서비스에는 거의 무료로 사용할 수 있습니다. 제 뉴스레터 서비스와 코토로 서비스가 다이나모 디비를 사용하고 있습니다. 그러나, 팀으로 개발할 때에는 이 DynamoDB를 위한 AWS 계정을 세팅하고, 동료들에게 권한 설정을 해주고 하는 것이 무척이나 귀찮습니다. 그리고, 여러 제약사항들이 있습니다.
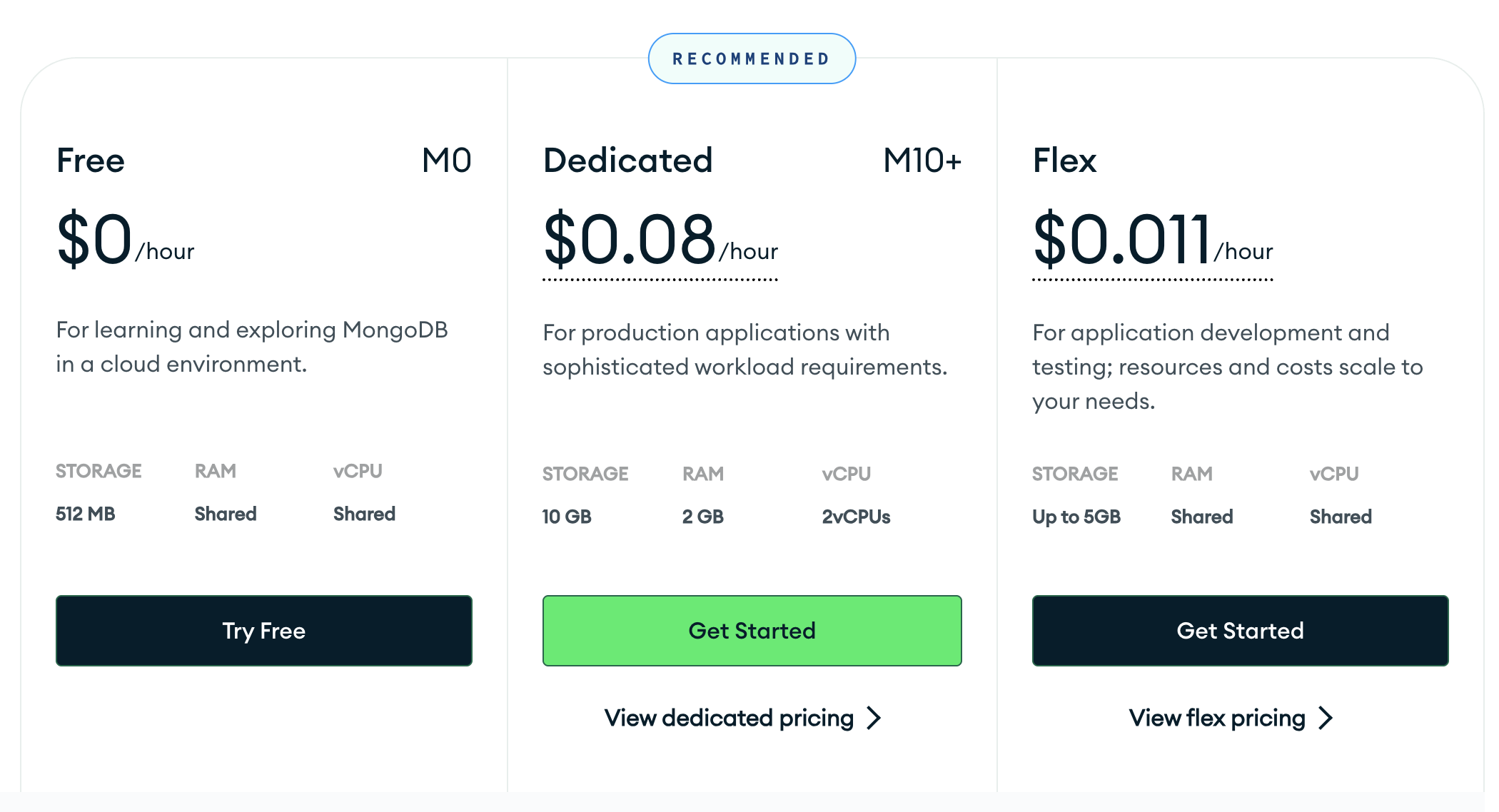
그래서 저희는 몽고디비의 제작사 Atlas에서 제공하는 무료 몽고디비 클러스터를 활용해주었습니다. 여러 계정 세팅이 편하고 속도도 준수하며, 몽고디비라는 안정적이고 표준적인 서비스를 사용할 수 있습니다. 서비스가 커지기 전까지는 무료 디비만으로 충분히 서비스를 운영할 수 있습니다.
초기 서비스 특성상 모든 디비 스키마를 처음부터 정의하기 어렵고, 개발하며 추가되는 스키마가 많기 때문에, SQL보다는 NoSQL인 몽고디비를 선호하는 편입니다.
Github를 활용한 최소 비용 CI/CD
저희는 배포를 완전 자동화해두었습니다. AWS 서버, S3에는 저만 접속하도록 하고 싶고, 팀원들은 배포와 로그 확인만 하도록 하고 싶었습니다. 그래서 Github Actions를 활용하여 배포 파이프라인을 구성하였습니다.
Settings에 환경변수로 AWS접속과 관련한 키를 세팅해둡니다. 이 키는 한번 등록하면 그 이후에는 변경만 가능하고 조회가 불가능하기 때문에 안전하게 유지됩니다. 그리고 .github deploy의 yaml파일로 배포하는 파이프라인을 구성했습니다.
이 파이프라인 구성은 GPT가 아주 잘해줍니다. AWS의 거의 모든 서비스는 awscli를 지원함으로, 대부분의 배포나 변경사항 반영은 github action을 통해 수행할 수 있습니다.
저희는 디스코드 웹훅을 연동하여, 배포나 푸시가 발생하면 알람이 오도록 했습니다. 이렇게 관리할 경우, 우선 깃허브에 없는 코드가 서버나 S3에 배포되는 일이 사라집니다. 가끔 S3에 직접 업로드 하거나 EC2에 업로드하는 경우가 생기는데, 편하게 배포할 수 있으니, 이런 경우가 거의 발생하지 않습니다. 또한, 롤백하기도 수월합니다. 로컬에서 충분한 테스트 후 메인에 머지하고, 배포하는 파이프라인을 태울 수 있습니다.
LLM 개발하기
LLM 기획
저희는 총 5개의 LLM 을 사용해주었습니다.
- (RAG) 크롤링된 내용으로 부터 장소 및 요약 내용 추출
- (RAG) 추출된 장소와 기존 여행지 매칭
- (RAG) 입력된 정보 기반 여행 스케쥴링
- (RAG) 자연어 기반 스케쥴 수정
- (Tool Calling) Tour API 기반 여행지 추천
입니다. 저희는 LLM을 추론머신으로 사용하도록 하였습니다. 저희는 추론하고 싶은 기능이 명확했기 때문에, LLM이 해야하는 역활을 정하고 이에 맞는 프롬프트를 작성하였습니다. 그리고 어떤 입력이 들어왔을 때, 어떤 답변을 하길 원한다는 테스트셋을 만들고, 이 테스트셋을 반복 실행하면서 프롬프트를 고도화시켰습니다.
저희는 이번 프로젝트에서 여러 기술을 사용했습니다. 첫번째는 RAG입니다. 저희는 사용자의 의도와 서비스에 맞도록 사용해주기 위해서, 사용자가 전송한 링크로부터 정보를 추출하고 이 정보를 입력으로 하여 정답을 생성하도록 해주었습니다. 또 하나는 API Calling입니다. 사용자의 입력 정보에 기반하여 LLM이 적합한 API를 선택하고 API로부터 받은 결과를 활용하여 결과를 내는 방식입니다.
LaaS를 사용한 프롬프트 튜닝
사실 이 프롬프트의 버전을 손쉽게 관리하고, 여러 프롬프트를 테스트해보면서, 프롬프트 버전별로 관리를 수행할 수 있었던 비결은 LaaS(LLM-as-a-Software)에 있었습니다.
보통 LLM 프롬프트를 관리하거나 사용한다고 하면, ChatGPT같은 대화형 창을 떠올리거나 .txt, .yaml 파일 등으로 관리하는 것이 일반적입니다. ChatGPT의 경우 반복적인 실험과 테스트, 그리고 서비스에 적용하기 어렵습니다. .txt 파일이나 .yaml파일을 사용하여 API를 호출하면 디테일하고 반복적인 실험은 가능하지만, 파일을 보고 수정하기 어려우며, 여러번 프롬프트를 실험할 때 버전을 관리하는 어려움이 있습니다.
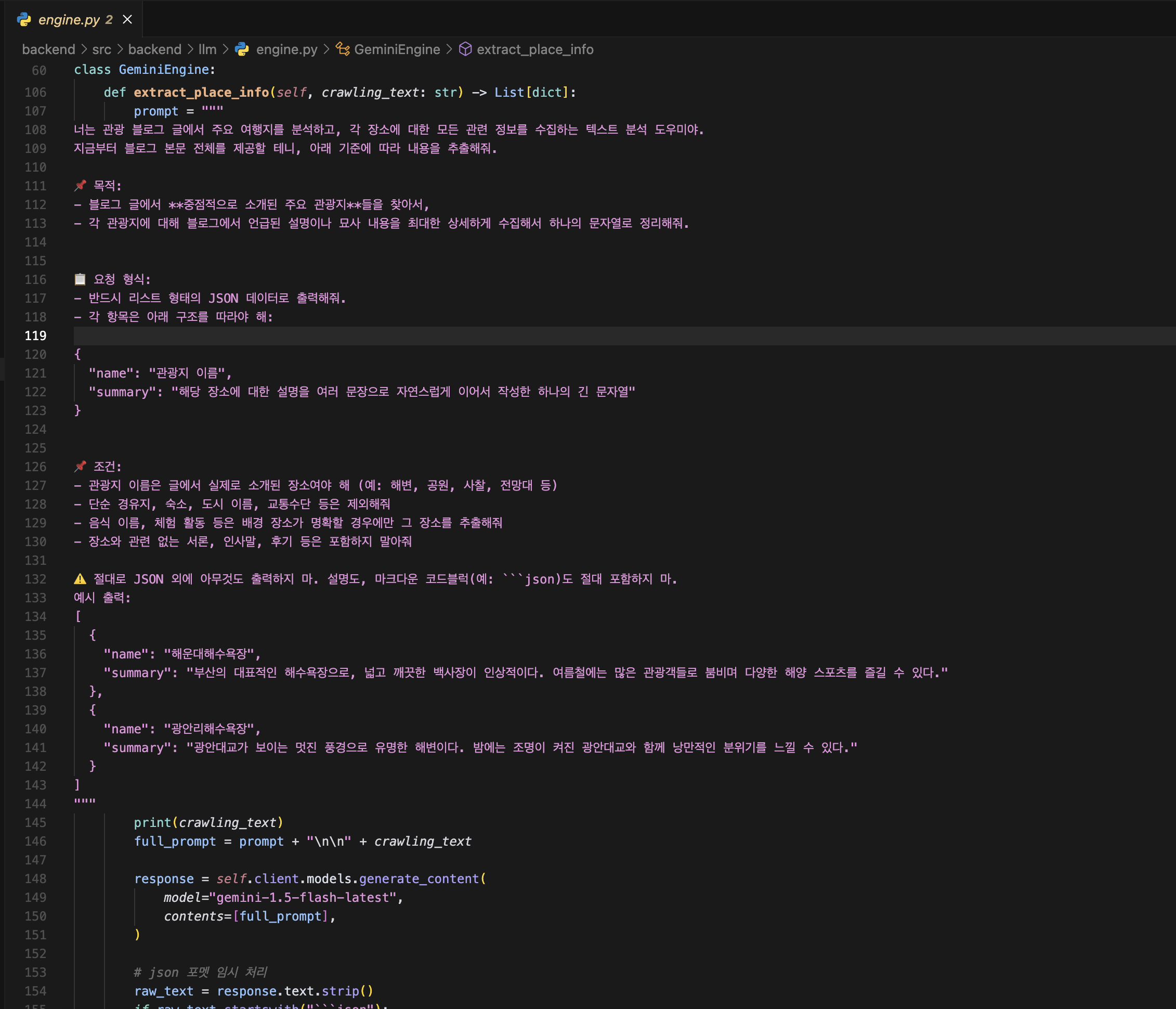
위에는 LaaS를 도입하기 전 저희가 사용한 소스코드 입니다. GenimiEngine이라는 클래스를 만들어서 여러 매써드를 비교적 편하게 관리하려고 했지만, 프롬프트를 코드에 작성하기 때문에 읽고 수정하기 어렵습니다. 이걸 .txt로 분리해서 관리하려고 하니, .txt 파일과 코드를 왔다갔다 하면서 보는 불편함이 있었고, 변수를 자유롭게 세팅하기 어려웠습니다.
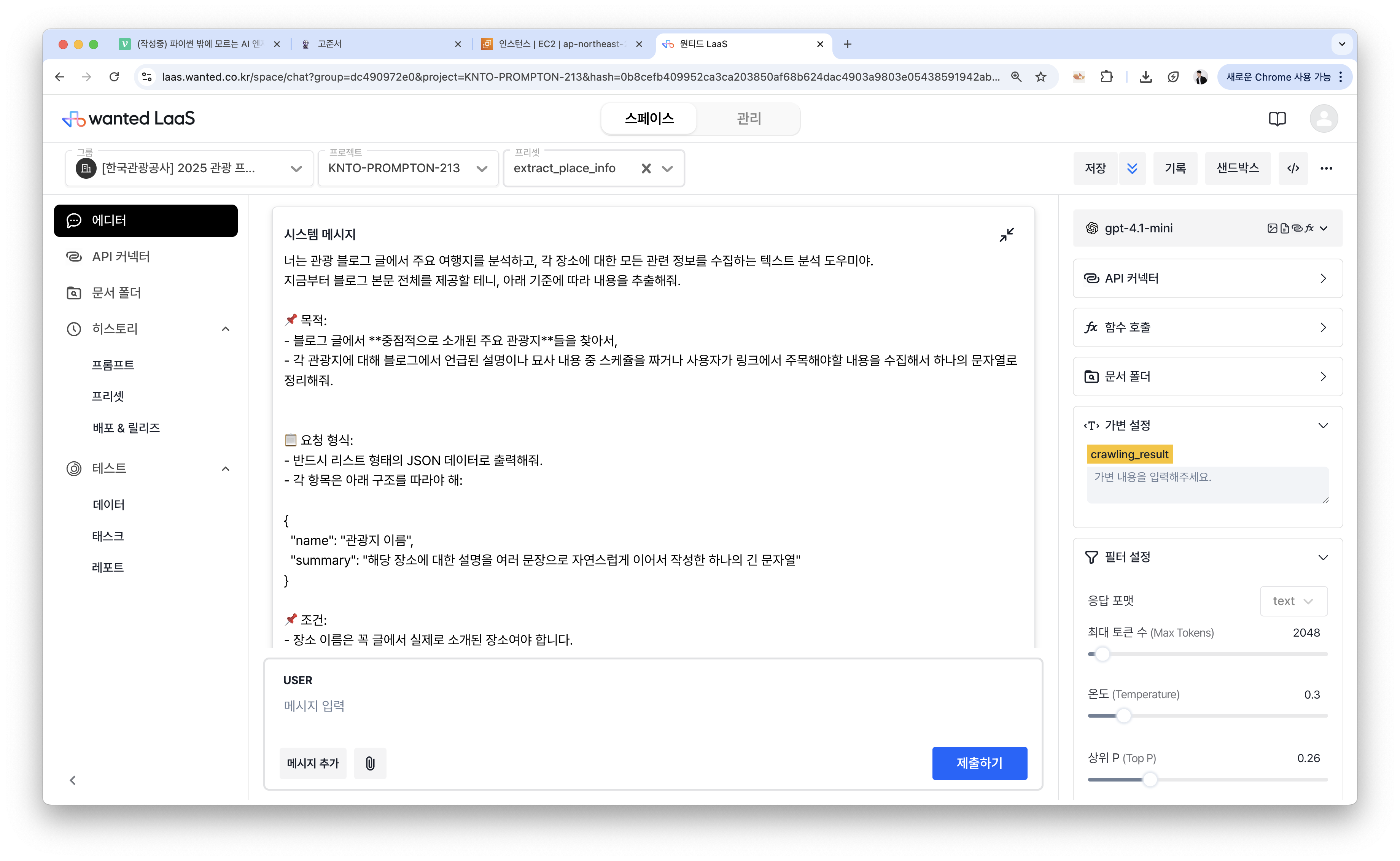
반면 LaaS의 경우 ChatGPT의 편리함과 API 호출의 반복적인 실험과 디테일한 설정이 가능합니다. 복잡한 프롬프트를 편하게 작성할 수 있고, 여러 세팅값을 설정해줄 수 있습니다.
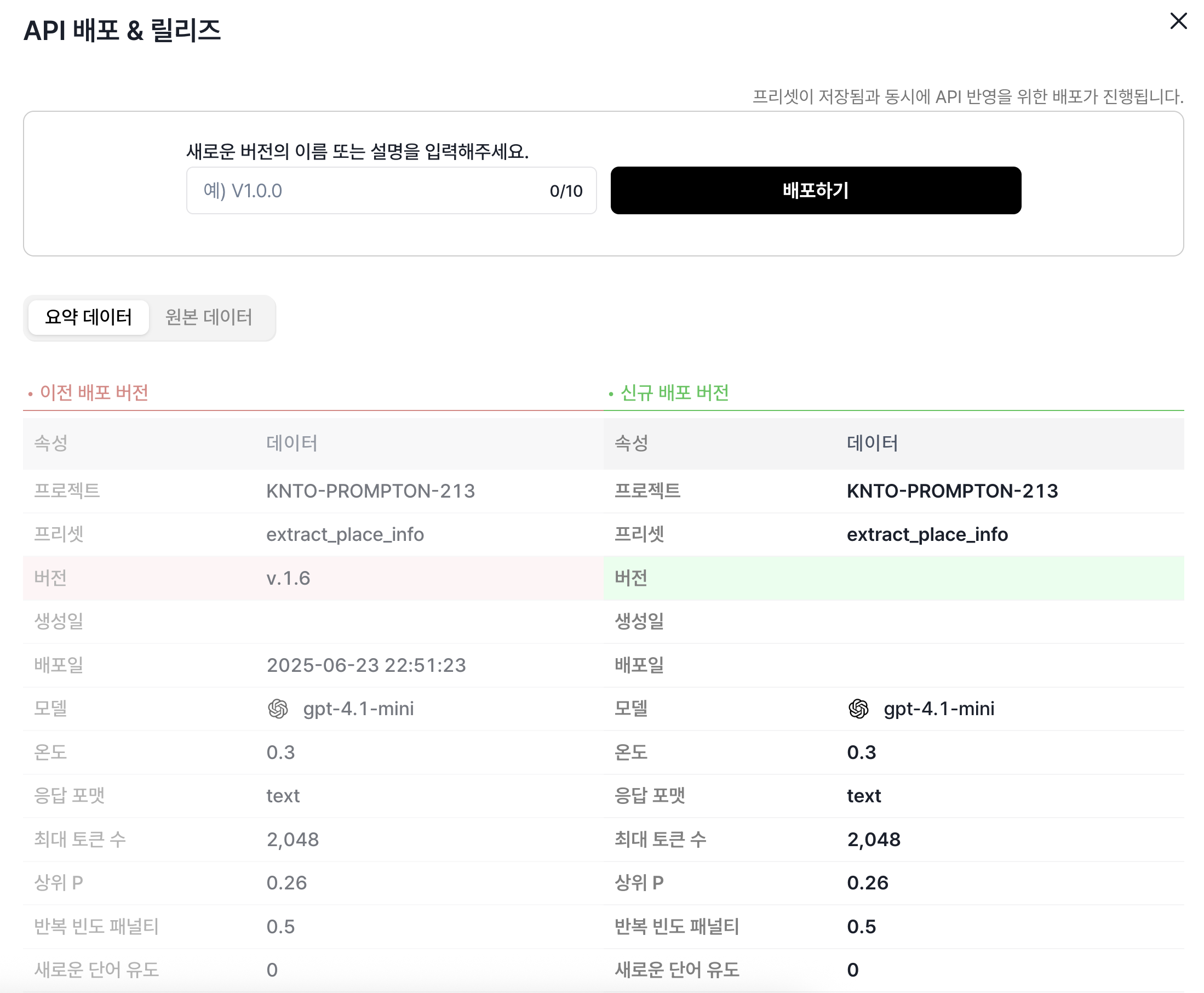 배포 및 버전관리 배포 및 버전관리 | 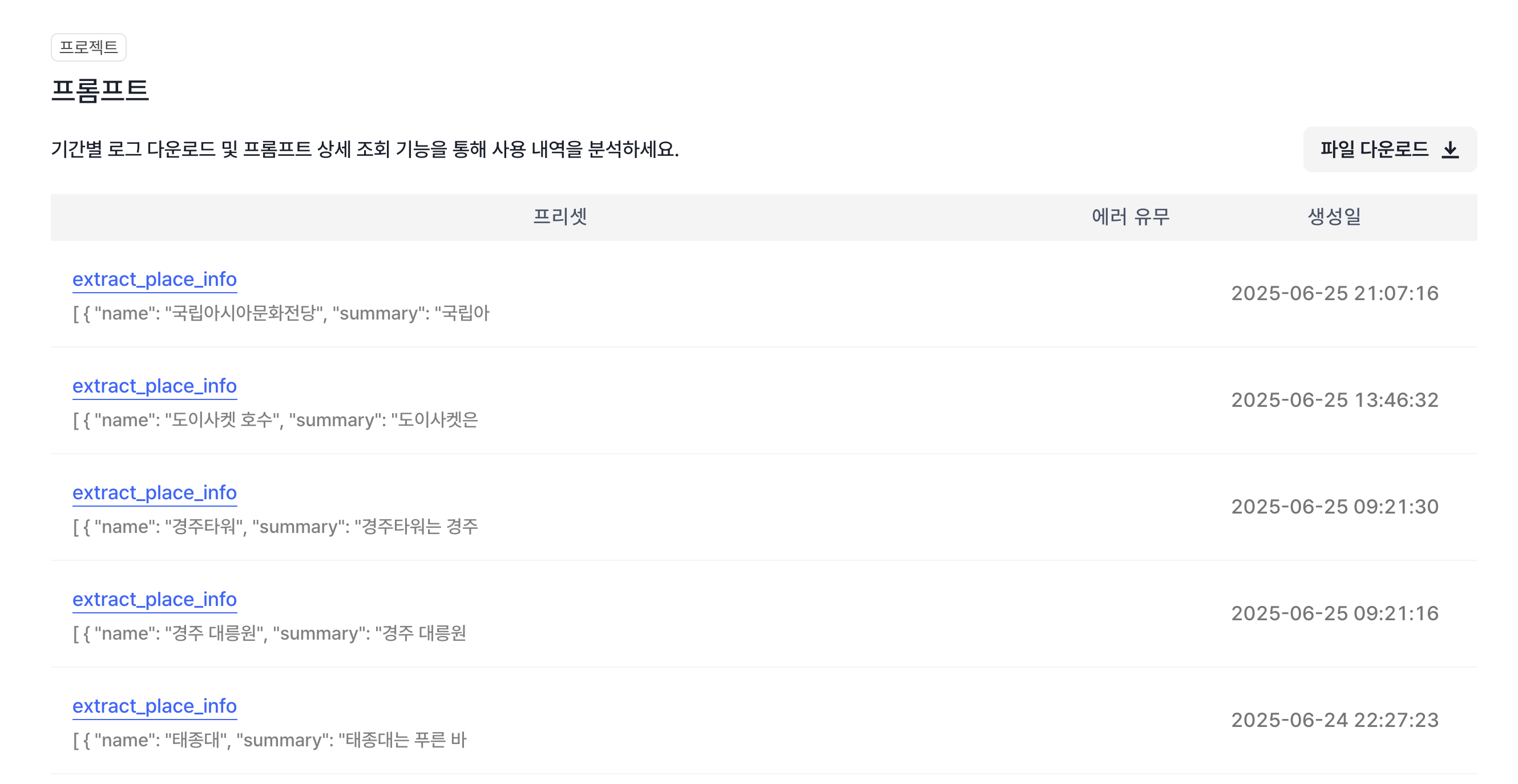 히스토리 관리 히스토리 관리 |
|---|
앞서 설명드린 불편함 중 많은 부분이 해소됩니다. 배포 및 버전관리를 통해 버전별로 실험을 진행할 수 있습니다. 또한, 기존 API는 기록을 보려면 플랫폼에 들어가서 보거나 내용을 기록해두어야 했지만, LaaS는 히스토리 기능을 제공하여 편하게 관리할 수 있습니다.
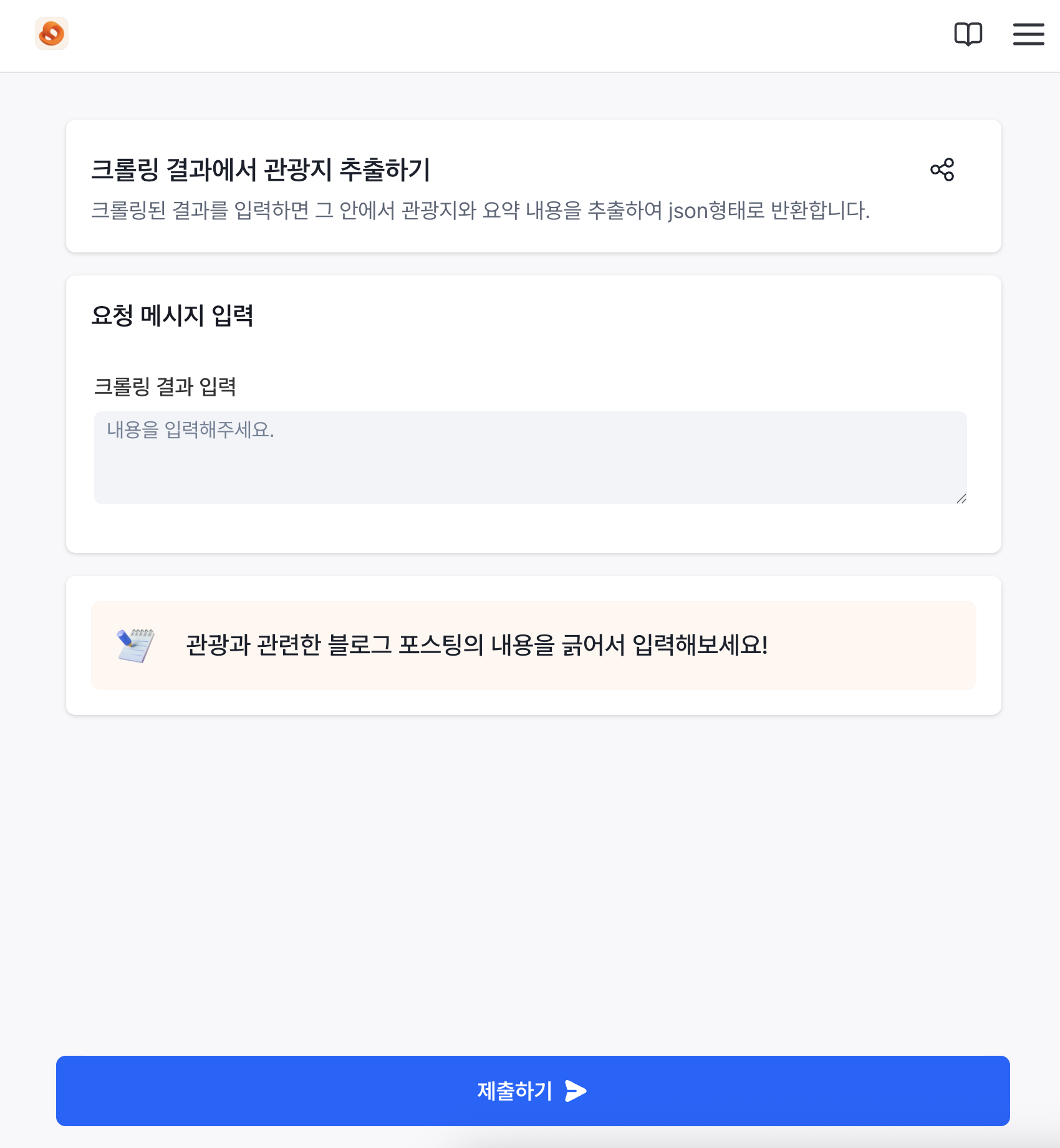
간단한 외부 공개용 웹페이지의 경우 LaaS에서 바로 홈페이지로 만들어줍니다. 여러 설명도 쓸 수 있고, 제 로고를 입력할 수도 있습니다. 만약 개발이 필요없는 간단한 서비스의 경우 LaaS만을 사용해서 배포할 수도 있습니다. 그 외에도 모델을 손쉽게 바꾸거나, 비개발자도 문서를 통해 RAG를 할 수 있도록 지원합니다.
LaaS는 기업용으로 제작된 소프트웨어인만큼 안정성과 사용 편의성을 갖췄습니다. 최근에는 개인용 혹은 작은 스타트업용 요금제도 출시하였기에 기업용 안정적인 소프트웨어를 개인도 충분히 사용해볼 수 있습니다.
LaaS API Connector
 API 설정하기 API 설정하기 | 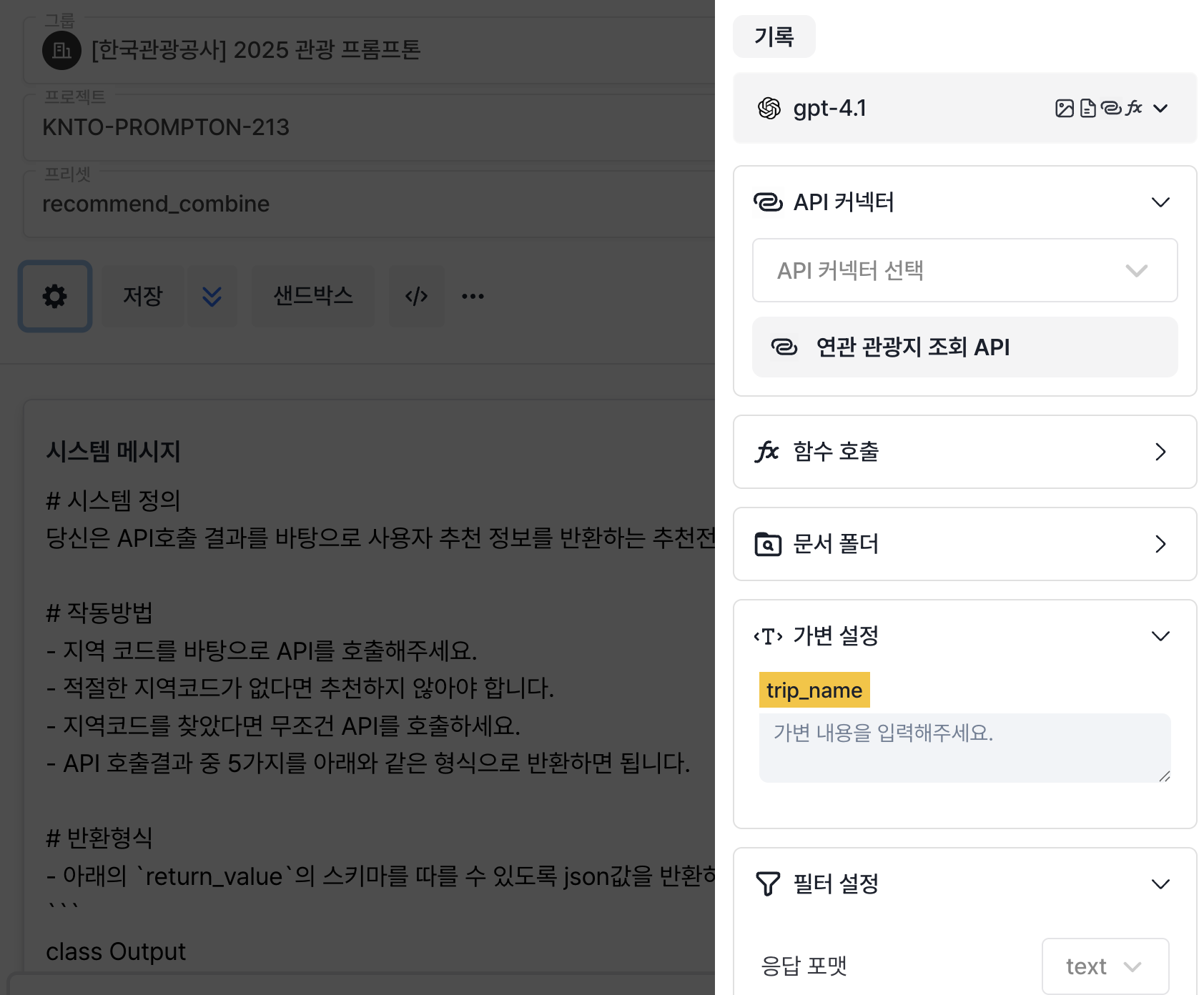 API 커넥터 연결하기 API 커넥터 연결하기 |
|---|
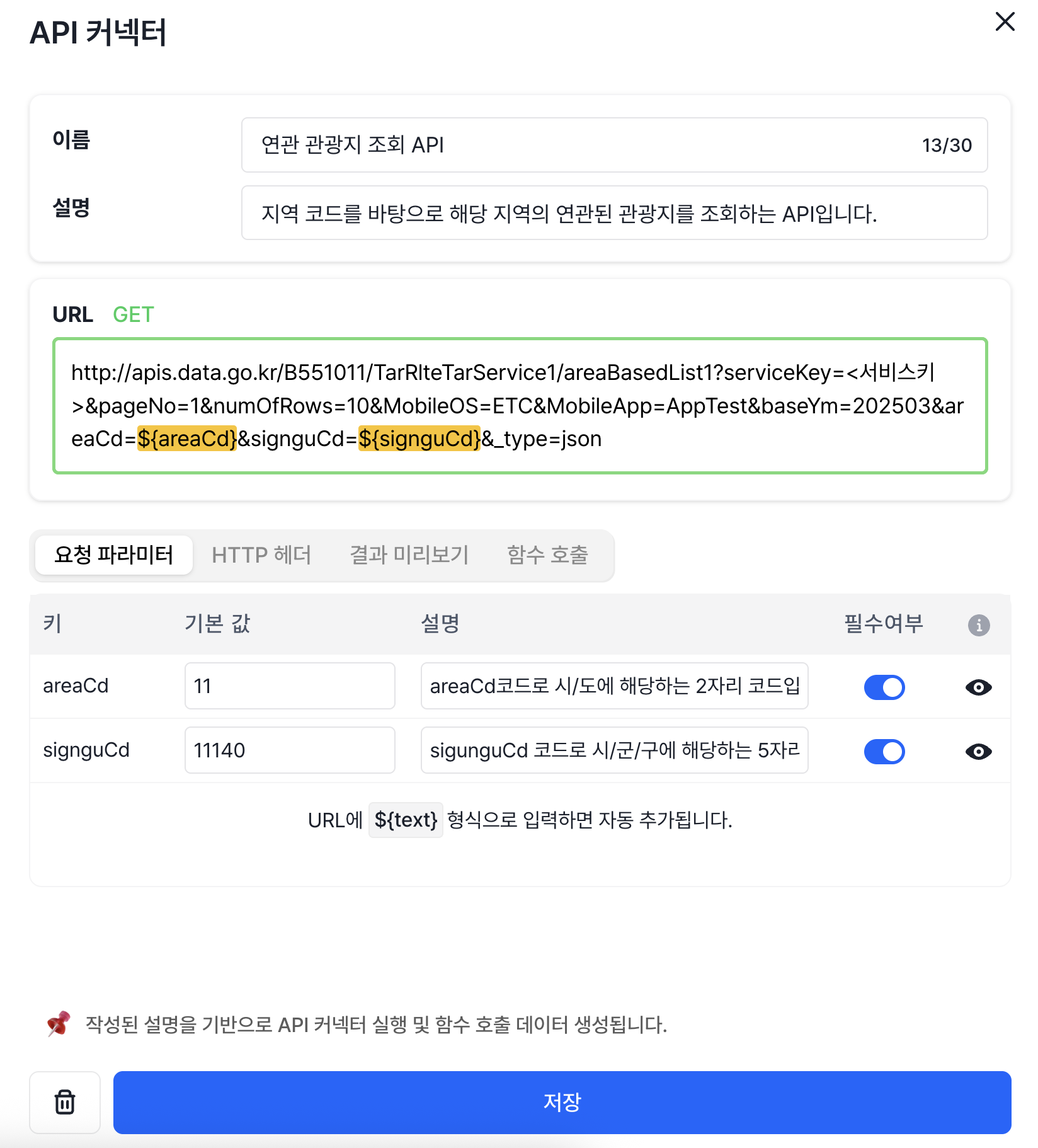
저희는 이번에 새로 나온 API Connector라는 기능도 사용해보았습니다. API를 LaaS의 API 커넥터에 연결하고, API 커넥터를 선택하여 모델로 하여금 직접 API를 호출하도록 할 수 있습니다. 저희는 이번에 한국관광공사의 API를 사용하여 개발을 진행하였는데요. 한국관광공사의 API를 LaaS가 직접 호출해줍니다. LLM으로부터 API에 넣을 파라미터를 추출하고, 이를 바탕으로 서버에서 API를 호출하고 이것을 다시 모델에 넣고 하는 귀찮고 번거로운 작업을 이 API 커넥터 하나로 수행할 수 있는 것입니다.
이 기능을 활용해서 저희는 한국관광공사 '관광지 연관정보'를 바탕으로 사용자가 정한 이름으로부터 관광지를 추천하는 기능을 구현했습니다. API 스키마가 FastAPI와 같은 형태로 나오니까, 직관적이고 사용하기도 수월했습니다. LaaS에 관련 내용을 입력할 때에도 이 스키마가 도움이 되었습니다.
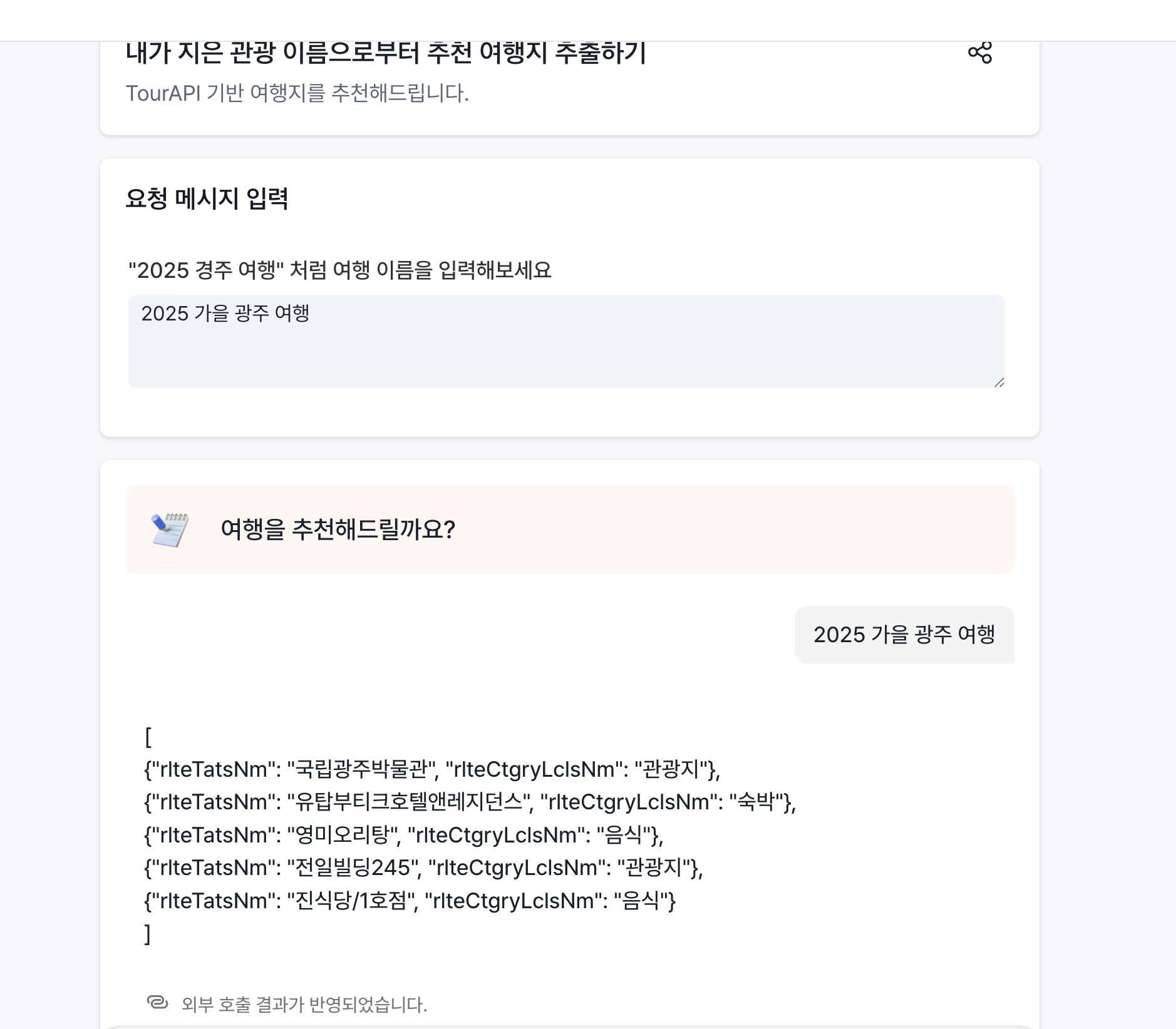
실제 저희가 만든 결과물을 마지막으로 보여드리겠습니다.
대회를 마무리 하며.
저희는 이번 대회에 백엔드, 프론트엔드, 그리고 저렴한 배포환경을 고려하여 실제 서비스 가능한 수준으로 출품작을 끌어올리기 위해 노력했습니다. 그래서 백엔드나 프론트엔드 그리고 사용자 경험에 매우 디테이한 부분까지 신경쓰며 제작하였습니다.
이번 서비스 출시가 제 5번째 완성수준의 프로덕트인데요, 확실히 AI를 사용하여 코딩하니 더 빠르고 안정적인 개발이 가능해진 것 같습니다. 그리고, 여러 비용 절약 노하우나 클라우드 환경에도 익숙해지는 것이 느껴집니다.
이 모든 개발을 2주 안에 수행했는데요, LaaS와 함께 개발했기 때문에 LLM 부분은 LaaS에 역할을 넘기고, 저희는 다른 개발에 몰두할 수 있었습니다. 그래서 LLM과 실제 프로덕트 모두 높은 완성도를 보장할 수 있었습니다.
여러분들도 주저하지 말고 실제 프로덕트를 한번 출시해보시는 것 어떨까요?
