메모리
매번 I/O 요청때마다 디스크에 접근하여 파일을 읽고 쓰게 된다면 상당한 시간을 기다려야 하며, 시스템에도 부하가 일어난다. 이때 사용하는게 캐싱이다.
1. Unix 파일 시스템
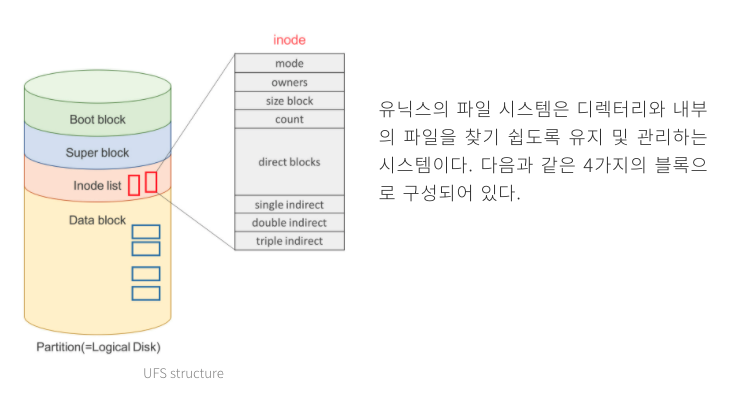
1. Boot Block : 부팅에 필요한 정보를 담고 있다.
2. Super Block : 파일 시스템에 담고 총체적인 정보를 담고있다. 어디서부터 inode인지, data block인지, 파일 시스템의 크기 등을 저장하고 있다.
3. Inode(index node) list : 파일 하나당 inode가 할당되며, 해당 inode는 파일의 메타 데이터를 갖고 있다. 이러한 inode의 묶음이라고 보면 된다.
4. Data Block : 실제로 데이터의 내용이 저장되는 디스크 영역이다. 각각의 데이터 블록은 한 번에 하나의 파일만 할당될 수 있다.
2. Page Cache
커널은 느린 디스크 접근의 단점을 보완하기 위허여 한번 읽은 파일의 내용을 커널 메모리의 일부분인 Page Cache 영역에 저장한다. 다음에 다시 접근이 일어나면 디스크의 내용을 전달하는 것이 아닌 Page Cache 영역에 저장된 내용을 전달한다. (근데 내가 원하는 정보를 뭐로 찾지??? 메모리가 key-value형태로 저장되서 같은 내용을 찾으면 key가 같은가? url이 같나본데,,,? 왜냐면 http통신할때 url같은거 보내면 캐시에 저장된거 가져오니까. 그리고 파일도 url이 있는거같던데. 어디선가 봤어) 이를 Page라는 단위로 관리해서 Page cache라고 한다. (책의 page라고 이해하면 되나?)
프로세스가 파일을 읽어 들이면 커널은 프로세스의 메모리에 파일의 데이터를 직접 복사하는것이 아니라, 커널의 메모리 내에 있는 Page Cache라는 영역에 복사한 뒤 이 데이터를 프로세스 메모리에 복사한다. 커널은 자신의 메모리 안에 Page Cache에 캐싱한 파일과 그 범위 등의 정보를 보관하는 관리 영역을 가진다.(이게 buffer?) 이렇게 커널안의 Page Cache영역은 전체 프로세스의 공유자원이므로 읽어 들인 프로세스는 최초의 데이터에 접근한 프로세스와 달라도 이슈가 없다.(???)
3. Buffer Cache
파일의 내용이 아닌 Super block과 inode block에 해당하는 메타데이터를 저장한다.
4. Slab 영역
커널 역시 프로세스이므로 메모리가 필요하다. Slab은 커널이 사용하는 메모리 영역을 말한다. 커널이 내부적으로 사용하는 캐시라고 표현할 수 있다.
5. 메모리가 부족하다면, buffer, cache는 어떻게 될까?
메모리의 여유가 있을 경우에는 자체적으로 커널에서 I/O 성능 향상을 위한 캐싱 영역을 늘려가며, 반대로 여유가 없을 경우에는 할당한 캐시 영역을 반환함으로써 메모리 공간을 확보한다.
6. buffer, cache 영역을 전부 반환했는데도 메모리가 부족하면?
이때는 커널이 swap영역을 확인 및 사용하게 된다. 하지만 swap 영역을 사용하는 것은 성능 저하를 야기하게 된다. (어째서? 디스크에서 가져오는거랑 비슷해서?)
8. 메모리의 비정상적인 사용이 발견되었다면?
리눅스에서는 /proc/meminfo를 통해 자세한 내용을 볼 수 있다.
- Buffers : 파일 시스템의 메타 데이터가 저장된 Buffer cache의 크기
- Cached : page cache의 크기
- SwapCached : 메모리 부족으로 인하여 swap이 되었다가 다시 돌아왔을 떄, swap 영역에서는 해당 공간을 지우지 않는다. 추후에 다시 부족하게 될 경우 I/O부하를 줄이게 하기 위해서이다.
- Action : 비교적 최근에 사용된 영역으로써, Action(file)과 Action(anon)을 합친 크기
- Inaction : 비교적 참조/사용이 오래된 영역으로써 Swap 영역으로 이동될 수 있는 메모리 영역을 말한다.
- Action(anon) : anonymous의 줄임말로, page cache를 제외한 비교적 최근에 사용된 프로세스들이 사용하는 메모리 영역
- Action(file) : 커널이 I/O 성능 향상을 위해 사용하는 Page cache, Buffer cache 영역의 크기이다.
- Dirty : Page cache를 통해 저장된 파일 내용을 사용하는 과정에서 쓰기 작업이 이루어질 경우, 디스크에 엤는 내용과 Page cache에 있는 내용은 서로 다르게 된다. 이때 커널은 달라졌음을 표시하는 Dirty 비트를 켜고 해당 영역을 Dirty page라고 부른다. 이후 '일정 주기. 일정 크기' 단위로 디스크에 동기화를 한다. 이러한 영역의 크기를 말한다.
buffer => buffer cache , cache => Page Cache + Slabs
Buffer : 커널 버퍼로 사용중인 메모리 / 파일시스템의 메타데이터 저장 /inode값 보관 / 파일의 실 주소 보관 => Disk의 seek time 최소화
- 커널 메모리 = 메모리??? 커널은 OS의 핵심으로 메모리에 상주하는 것. 즉 커널 = 메모리?
커널
1. 커널의 기능
- 메모리 관리 : 메모리가 어디에서 무엇을 저장하는데 얼마나 사용되는지 추적
- 프로세스 관리 : 어느 프로세스가 cpu를 언제 얼마나 오랫동안 사용할지 결정
2. OS내에서 커널의 위치
리눅스 시스템은 3개 레이어로 구성되어 있다.
- 하드웨어
- Linux 커널: OS의 핵심이다. 메모리에 상주하며 CPU에 명령을 내리는 소프트웨어
- 사용자 프로세스 : 실행중인 프로그램으로, 커널이 관리한다. 사용자 프로세스가 모여 사용자 공간을 구성한다.
시스템에서 실행되는 코드는 커널 모드 또는 사용자 모드라는 두 가지 모드 중 하나로 CPU에서 실행된다. 커널 모드에서 실행 중인 코드는 하드웨어에 무제한 액세스가 가능한 반면, 사용자 모드에서는 CPU 및 메모리가 SCI를 통해 액세스하는 것을 제한합니다. => 이는 보안, 컨테이너 구축 및 가상 머신을 위한 권한 구분과 같은 복잡한 작업의 토대가 된다. (마스터 노드는 각각의 컨테이너를 관리할 수 있고 워커노드는 할당된 것만 사용할 수 있는것처럼?), 프로세스가 사용자 모드에서 실패할 경우 손상이 제한적이며 커널에 의해 복구될 수 있음을 의미
모든 내용을 캐시에 저장하는 것이 아니다. 캐시에는 위치, 파일의 정보 등이 담겨잇고 실제로는 디스크에서 가져와야 할 것이다. 왜냐하면 kafka의 내용이 엄청 많을 것이기 때문에. 아마... 자주 쓰는 파일의 내용만 page cache에 저장되는 것이 아닐까?
리눅스
1. 커널정보 확인
커널은 하드웨어를 관리하고 애플리케이션에 하드웨어 작업을 할당하며, 프로세스끼리 영향을 주지 않도록 하기 위해 다양한 방법으로 권한을 관리한다.
uname -a : 커널 버전 확인
dmesg : 커널의 디버그 메시지, 커널이 부팅할 때 나오는 메시지와 운영 중에 발생하는 메시지를 볼 수 있다. 이 명영어로 커널이 메모리로 인식하는 과정과 하드웨어를 인식하고 드라이버(?)를 올리는 과정, 그리고 부팅시 적용된 커널 파라미터(?) 등을 확인할 수 있다. 이때 "crashkernel"이라는 단어가 나오는데 이걸 통해 커널 패닉 상태의 원인을 추적할 수 있다.
more : 파일을 화면 단위로 보여줌
- dmidecode 하드웨어 정보 확인
dmidecode -t bios: bios 키워드는 보통 특정 BIOS 버전에 문제가 있다는 보고가 있고, 내가 사용하는 버전이 이 버전에 해당하는지를 확인할 때 주로 사용
dmidecode -t system: 장비의 모델명을 통해서 해당 장비가 어느 정도의 성능을 낼 수 있는지 확인
dmidecode -t processor: 이거 안나오면lscpu
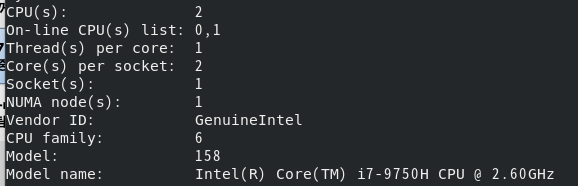
- socket은 물리적인 cpu의 개수. core는 물리적인 cpu안에 몇개의 컴퓨팅 코어가 있는지를 뜻한다.
위의 예시를 보면 socket=1, core per socket=2
해당 예시의 결과를 보면 총 2개의 소켓이 있고 각 소켓에 사용가능한 6개의 코어가 있다.
코어는 6개가 전부 사용되고 있고, 하이퍼스레딩 기능을 통해서 가각의 코어가 멀티로 동작해서 총 12개의 코어를 사용할 수 있는 상황이다.
소켓당 12개의 코어를 사용할 수 있기 때문에 시스템 전체적으로는 24개의 코어를 사용할 수 있는 것이다.(뭔말인지...)
- intel_idle.max_cstate (명령어인지 뭔지 모르겠음)
최근에 사용하는 CPU에는 C-State라는 옵션이 있어서 특별한 작업이 없는 idle상태가 되면 일부 CPU코어를 잠자기 모드로 전환시킨다.
경우에 따라서는 C-state 옵션을 꺼야 하는데, 이 옵션은 부팅시 하드웨어 BIOS 설정에서 설정한다.
하지만 하드웨어 BIOS설정에서 해당 옵션을 꺼둔 상태에서도 소프트웨어 모듈에 의해서 켜지는 경우가 있는데, 바로 intel_idle 모듈 때문이다.
이런 현상을 피하기 위해 부팅시 파라미터로 intel_idle 모듈을 사용하지 않도록 설정하는 것이 필요하다.
1-2. 메모리 정보 확인하기
dmidecode -t memeory | grep -i size:
free -m이 키워드는 크게 Physical Memory Array 와 Memory Device의 두 영역으로 나눌 수 있다.
- Physical Memory Array
하나의 CPU 소켓에 함께 할당된 물리 메모리의 그룹. 최근의 프로세서는 NUMA의 개념을 이용해서 각각의 CPU가 사용할 수 있는 로컬 메모리를 제공 - Memory Device
실제로 시스템에 꽂혀있는 메모리를 의미하며, 메모리의 용량이 얼마인지, 제조사는 어디인지 볼 수 있다.
demidecode를 통해 계산한 메모리 전체 용량과 free 명령을 통해 확인한 전체 메모리 크기와 다르다면, 시스템 메모리 인식에 뭔가 문제가 있는 것이다.
1-3. 디스크 정보 확인하기
-
df -h
서버의 파티션이 몇개인지와 마운트된 위치를 알 수 있다. 또한 시스템에 각 디스크의 네이밍 정보도 알 수 있다. -
sda와 hda의 차이점
디스크의 방식에 따라 dev/sda나 /dev/hda거나 /dev/vda일 수 있다.
시스템이 디스크와 통신하기 위해 사용하는 것 중에 컨트롤러라는 부품이 있다.
이 부품에는 여러 타입이 있는데 그중 가장 대표정인 것이 IDE타입과 SCSI 타입이다.
IDE는 개인용 컴퓨터를 위한 방식, SCSI는 서버용 컴퓨터를 위한 방식이며, 더 많은 장치를 연결할 수 있어서 확장성이 좋고 더 빠른 접근 속도를 제공한다.
IDE 방식의 디스크는 hda 로 SCSI방식의 디스크와 최근에 나오는 SATA, SAS와 같은 일반적인 하드디스크는 sda 로 표시된다.vda는 가상 서버에서 볼 수 있는 디스크 타입이다. XEN, KVM과 같이 하이퍼바이저(Hypervisor)위에서 동작중인 서버들에서 주로 볼 수 있다.
-
lsmod
현재 시스템에서 사용중인 RAID 컨트롤러의 드라이버
1-4. 네트워크 정보 확인하기
ethtool eth0- 해당 네트워크 카드가 어느 정도의 속도까지 지원이 가능한지 여부
- 현재 연결되어 있는 속도 (서버가 의도했던 것만큼 속도가 나오지 않을 때 살펴봐야할 항목이다. 서버와 연결한 네트워크 케이블이 불량이거나, 연결할 때의 옵션이 잘못되어 있으면 속도가 원하는 만큼 설정이 되지 않을 수 있다.)
- 네트워크의 연결이 정상인지 여부.
2. top를 통해 살펴보는 프로세스 정보들
S는 프로세스의 상태를 나타내는 정보이다. 현재 CPU를 사용하면서 작업하는 상태인지, I/O를 기다리는 상태인지, 아니면 아무 작업도 하지 않는 유휴 상태인지를 나타낸다. 역시 시스템의 성능과 관련된 중요한 정보이다.
VIRT, RES, SHR은 프로세스가 사용하는 메모리양이 얼마인지 확인할 수 있는 정보로 이를 통해 프로세스에 메모리 누수가 있는지를 확인할 수 있어 중요한 정보 중 하나이다.
2-1. VIRT, RES, SHR...?
VIRT는 Task, 즉 프로세스에 할당된 가상 메모리 전체의 크기이며,
RES는 그중 실제로 메모리에 올려서 사용하는 물리 메모리의 크기이다.
실제 사용하고 있는 메모리는 RES 영역이기 때문에 메모리 점유율이 높은 프로세스를 찾기 위해서는 RES 영역이 높은 프로세스를 찾아야한다.
- SHR
SHR은 다른 프로세스와 공유하고 있는 shared memory의 양을 의미.
SHR의 구체적인 예에는 라이브러리가 있다. 대부분의 리눅스 프로세스들은 glibc라는 라이브러리를 참조하기 때문에 사용하는 프로세스마다 glibc의 내용을 메모리에 올려서 사용하는 것은 공간 낭비다.
커널은 이런 경우를 대비해서 공유 메모리라는 개념을 도입했고, 다수의 프로세스가 함께 사용하는 라이브러리는 공유 메모리 영역에 올려서 함께 사용하도록 구현했다.
2-2. VIRT와 RES 그리고 Memory Commit의 개념
프로세스는 자신만의 작업 공간이 필요하고, 그 공간은 메모리에 존재한다.
프로세스가 커널에 필요한 만큼의 메모리를 요청하면, 커널은 프로세스에 사용 가능한 메모리 영역을 주고 실제로 할당은 하지 않았지만,
해당 영역을 프로세스에 주었다는 것을 저장해둔다.
이 일련의 과정을 Memory Commit이라고 부른다.
3. NUMA
3-1. UMA, SMP
한번에 한 개의 프로세서만이 동일한 메모리에 접근이 가능하기 때무에 다른 프로세서들을 대기하게 만드는 문제점이 있다. shared memory에 접근할 때, I/O를 사용할 때 병목현상을 일으킬 수 있음.
3-2. NUMA
각 CPU가 독립적인 지역 메모리 공간을 갖고 있어 빠른 메모리 접근이 가능하다. 이러한 구조로 인해 모든 프로세서가 로컬 메모리에 동시 접근이 가능하므로 병목현상이 발생하지 않는다. 하지만 로컬 메모리가 아닌 다른 프로세서의 메모리에 접근하게 될 경우에는 링크를 통한 메모리 접근에 시간이 소요되어 성능 저하가 일어나낟.
