[논문리뷰] MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Contribution
- 처음으로 joint audio-video generation을 위한 Multi-Modal Diffusion model (MM-Diffusion)을 제안하였다.
- Joint audio-video denoising을 위한 Coupled U-Net을 제안하였다.
- audio-video 간의 semantic synchronousness를 위한 새로운 Random-shift based multi-modal attention mechanism을 제안하였다.
Method
Multi-Modal Diffusion Models
Audio data 와 video data 로 묶인 paired data 가 주어졌을 때, 그에 대한 diffusion forward process 식은 아래와 같다.
이에 대한 reverse process는 각 modality의 correlation을 고려하여, unified model로 아래와 같이 정의된다.
그에 대한 training loss 식은 아래와 같다.
Coupled U-Net for Joint Audio-Video Denoising
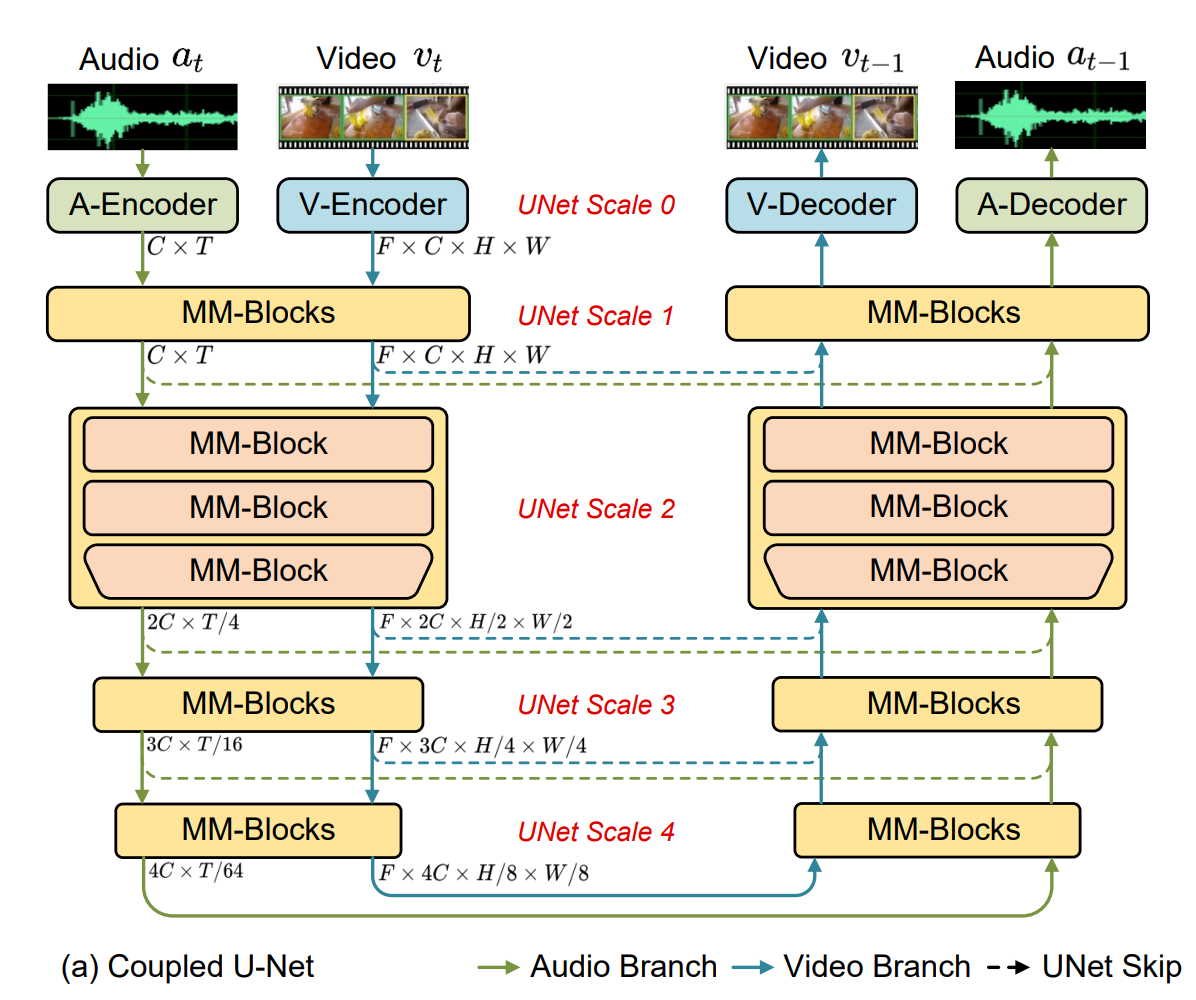
모델의 전체적인 구조는 위와 같이, U-Net 형태로 구성되어 있다.
input으로 audio input , video input 가 들어오며, 는 각각 video frame number, audio sequence number이다.
Efficient Multi-Modal Blocks
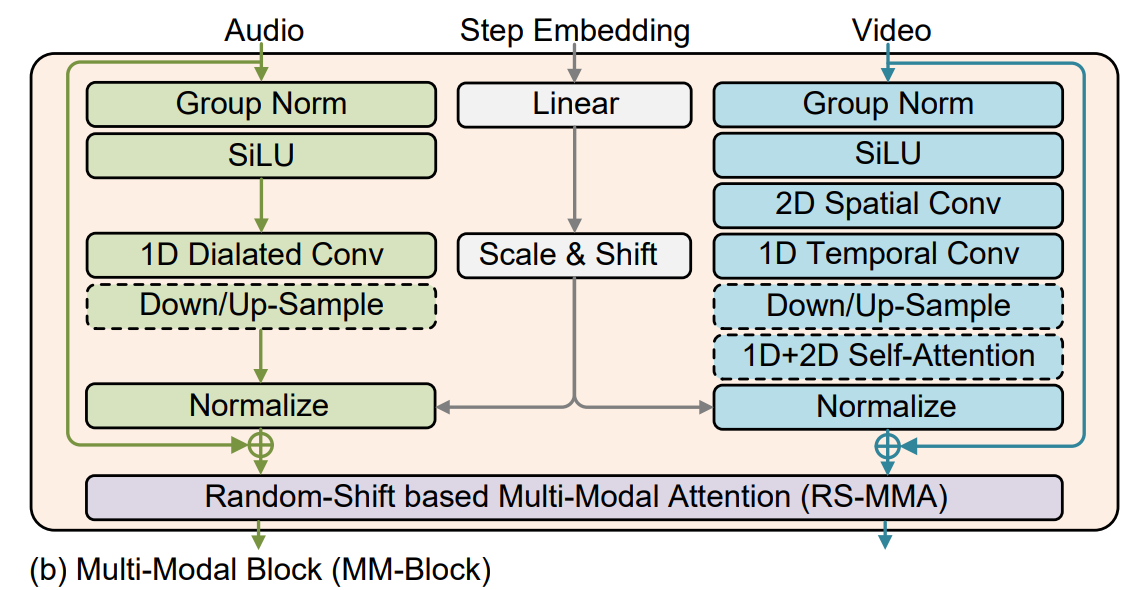
U-Net에서 각 Multi-Modal Block은 위와 같이 구성되어 있다.
먼저 video에서는 2D Convolution, 1D Convolution으로 구성되어 있는데, 이는 기존 video diffusion model에서 주로 computational efficiency를 위해 spatial 부분을 담당하는 2D convolution과 temporal 부분을 담당하는 1D convolution으로 구성하였다.
Attention 또한, 위와 같은 이유로 2D self-attention, 1D self-attention으로 나누어 구성하였다.
Audio의 경우에는, long-term dependency에 대한 modeling이 필요하기 때문에, (audio sequence가 훨씬 길다.) 단순히 1D convolution을 사용하기 보다는 dilated convolution을 사용하였다.
또한, computational efficiency를 위해, temporal attention block을 삭제하였다.
Random-shift based Multi-Modal Attention
이제 Audio, video 간의 alignment를 해야하는데, 이를 단순히 cross-attention으로 구성한다면, attention map의 크기가 너무 커져, computational complexity 문제가 생길 것이다.
그래서, 논문에서는 이를 해결하기 위해, Random-shift based attention mask를 통한 Multi-modal attention mechanism (RS-MMA)을 제안하였다.
이는 아래와 같은 순서로 진행된다.
- audio stream을 video frame timestep과 동일하게 잘라준다.
- 각 modality에서 random하게 shift된 부분과 attention weight을 구한다.
- 예를 들어, window-size를 라 하고, random-shift number를 라 할때, audio-to-video attention map을 구한다면, 와 간의 attention map을 구한다.
이에 대한 그림은 아래와 같다.
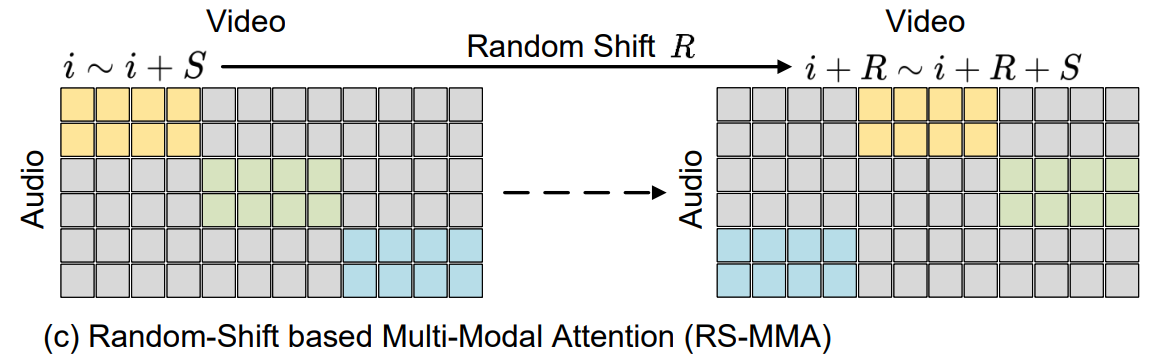
이를 통해, computation complexity 문제를 해결할 수 있고, Neighborhood atttention으로 global attention 효과를 가질 수 있다.
