이번 포스트에서는 REINFORCE 알고리즘을 학습한다. REINFORCE은 목적함수를 따라 정책 경사를 계산하여 정책을 결정하는 파라미터를 최적화하는 방법으로 먼저 목적함수는 다음과 같이 궤적에 대한 이득의 기댓값으로 정의한다.
J(πθ)=Eτ∼πθ[R(τ)]=Eτ∼πθ[t=0∑Tγtrt]
여기서 πθ는 θ라는 파라미터로 표현되는 정책을 의미하며, 심층신경망을 사용하여 정책망을 구현할 경우 심층신경망의 학습가능한 파라미터들이 θ가 된다.
정책 경사 알고리즘은 이렇게 파라미터 θ로 표현되는 목표함수를 θ에 대해 미분하고, 그 결과를 바탕으로 경사기반 최적화를 수행하여 최적의 파라미터를 찾는 알고리즘을 의미한다. 알고리즘의 목표는 목표함수를 최대화하는 것으로 다음과 같이 쓸 수 있다.
θmaxJ(πθ)=Eτ∼πθ[R(τ)]
이를 위해 목표함수 J를 미분하여 다음과 같이 파라미터를 업데이트 할 수 있다.
θ←θ+α∇θJ(πθ)
목표함수 J의 미분과정은 ∇θJ(πθ)=∇θEτ∼πθ[R(τ)]를 수행해야하는데, 이 때, 이득 R은 θ의 식이 아니라서 직접 미분할 수 없다는 문제가 발생한다. 파라미터 θ는 정책을 결정하며, 해당 파라미터에 대한 미분을 수행하기 위해 다음과 같이 식을 수정한다
(Leibniz integral rule, https://freshrimpsushi.github.io/posts/leibniz-integral-rule/).
∇θEx∼p(x∣θ)[f(x)]=∇θ∫dxf(x)p(x∣θ)(기대값의정의)=∫dx∇θ(f(x)p(x∣θ))(Leibnizintegralrule)=∫dx(f(x)∇θp(x∣θ)+∇θf(x)p(x∣θ))=∫dxf(x)∇θp(x∣θ)=∫dxf(x)p(x∣θ)p(x∣θ)∇θp(x∣θ)=∫dxf(x)p(x∣θ)∇θlogp(x∣θ)=Ex[f(x)∇θlogp(x∣θ)](기대값의정의)
위의 식에서 x=τ,f(x)=R(τ),p(x∣θ)=p(τ∣θ)를 대입하면 다음과 같다.
∇θJ(πθ)=Eτ∼πθ[R(τ)∇θlogp(τ∣θ)]
여기서 p(τ∣θ)를 좀 더 계산하기 용이한 형태로 바꿀 수 있다.
p(τ∣θ)logp(τ∣θ)logp(τ∣θ)∇θlogp(τ∣θ)∇θlogp(τ∣θ)=t≥0∏p(st+1∣st,at)πθ(at∣st)=logt≥0∏p(st+1∣st,at)πθ(at∣st)=t≥0∑(logp(st+1∣st,at)+logπθ(at∣st))=∇θt≥0∑(logp(st+1∣st,at)+logπθ(at∣st))=∇θt≥0∑logπθ(at∣st)
이렇게 계산된 식을 대입하면 다음과 같다.
∇θJ(πθ)=Eτ∼πθ[t≥0∑TR(τ)∇θlogπθ(at∣st)]
다만 위의 식을 그대로 학습에 사용할 경우 R(τ)에서 전체 궤적에 대한 보상을 모두 고려하기 때문에 큰 분산을 갖는다. 이러한 문제는 시각 t에서의 보상 만을 고려하여 해결할 수 있으며, 다음과 같이 쓸 수 있다.
R(τ)=R0(τ)=t′=0∑Tγt′rt′→t′=0∑Tγt′−1rt′=Rt(τ)
이를 적용하면 다음과 같이 최종적인 식을 작성할 수 있다.
∇θJ(πθ)=Eτ∼πθ[t≥0∑TRt(τ)∇θlogπθ(at∣st)]
여기서 기대값은 몬테카를로 방법을 통해 계산할 수 있으며, 여러 에피소드를 수행하여 데이터를 수집하고 그에 대한 평균을 낸다.
또한 추가적으로 행동에 영향을 받지 않는 기준값을 다음과 같이 이득에서 뺴어 조절함으로써 분산을 줄어 학습을 도울 수도 있다. 여기서 사용할 수 있는 기준값으로는 가치함수나 궤적에 대한 평균 이득 등이 될 수 있다. 평균 이득을 사용할 경우 state에 대해서 변화하지 않아 분산은 줄지 않을 수 있지만 분포가 0을 중심으로 형성되게 하여 학습을 도울 수 있다.
∇θJ(πθ)≈t=0∑T(Rt(τ)−b(st))∇θlogπθ(at∣st)

그림 1. REINFORCE 알고리즘
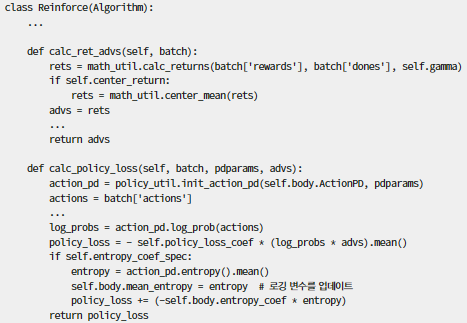
그림 2. 손실함수 계산

글 잘 봤습니다, 감사합니다.