
목표
자바의 프리미티브 타입, 변수 그리고 배열을 사용하는 방법을 익힙니다.
학습할 것
- 프리미티브 타입 종류와 값의 범위 그리고 기본 값
- 프리미티브 타입과 레퍼런스 타입
- 리터럴
- 변수 선언 및 초기화하는 방법
- 변수의 스코프와 라이프타임
- 타입 변환, 캐스팅 그리고 타입 프로모션
- 1차 및 2차 배열 선언하기
- 타입 추론, var
프리미티브 타입 종류와 값의 범위 그리고 기본 값
프리미티브 타입은 영어로 primitive type, 원시 타입 또는 기본형 타입이라고 한다. 우선 타입이란 데이터 타입을 줄인 말로 자료형이라고도 한다.
컴퓨터 관점에서 타입은 데이터가 메모리에 어떻게 저장될 것이고 또 어떻게 다뤄져야 하는지에 대해 알려주는 것이다.
다음은 프리미티브 타입의 종류를 표로 정리한 것이다.
| 구분 | 프리미티브 타입 | 메모리 크기 | 기본 값 | 표현 범위 |
|---|---|---|---|---|
| 논리형 | boolean | 1byte | false | true, false |
| 정수형 | byte | 1byte | 0 | -128 ~ 127 |
| short | 2byte | 0 | -32,768 ~ 32,76 | |
| int | 4byte | 0 | ~ | |
| long | 8byte | 0L | ~ | |
| 실수형 | float | 4byte | 0.0F | ~ 의 근사값 |
| double | 8byte | 0.0 | ~ 의 근사값 | |
| 문자열 | char | 2byte | '\u0000' | 0 ~ 65,535 |
외우지 말고 이해하자.
1byte = 8bit이며 1bit로 2진수 한 자리를 나타낼 수 있다.
1bit당 표현할 수 있는 수는 2배씩 증가한다.
이를 대입해서 계산하면 값을 표현 범위를 알 수 있다.
그럼, short 타입의 경우 이므로 256이 아닌가?
할 수 있지만, 부호가 있는 자료형의 경우 이를 표현하는데 1bit를 활용한다. 여기에는 최상위 비트(가장 왼쪽의 비트)를 활용하기 때문에 MSB(Most Significant Bit)라고도 한다.
실수는 부호, 가수(mantissa), 지수(exponent)로 구성되며, 부동 소수점 방식을사용한다. 부동 소수점 방식은 모든 가수를 0보다 크거나 같고 1보다 작은 값의 범위로 만든 뒤, 지수를 통해 표현하는 방식이다.
float타입은 부호(1bit) + 지수(8bit) + 가수(23bit)
double타입은 부호(1bit) + 지수(11bit) + 가수(52bit)
참고하기
1. Java8 부터 부호자리도 데이터자리로 활용하는 unsigned 자료형을 지원하는 static 메소드가 지원된다.(하지만 불편하다.)
2. 정확한 실수계산이 필요한 경우에는 꼭 정수형을 활용하여 계산한다.(값을 저장하면서 데이터 손실이 발생할 수 있다.)
3. byte나 short를 활용해 연산을 진행하는 경우, 이는 int형으로 변환되어 연산을 진행한다.
프리미티브 타입과 레퍼런스 타입
프리미티브 타입(permitive type)은 기본 데이터 자료형이라고 위해서 살펴 보았다.
레퍼런스 타입(reference type)은 참조 데이터 자료형이다.
참조란 무엇일까?
실제 값이 저장되어 있는 곳의 위치를 저장한 값(주소 값)을 뜻한다.
종류에는 배열, 열거(enum), 클래스, 인터페이스가 있다.
기본 타입과 참조 타입을 구분하는 방법은 생각보다 단순하다.
저장되는 값이 실제 값 그 자체이냐 아니면 메모리의 주소값이냐에 따라 구분할 수 있다.
그럼 이 값들은 어디에 저장 되는 걸까.
JVM의 메모리(런타임 데이터 영역)이다.
그 중에서도 런타입 스택 영역과 가비지 컬렉션 힙 영역에 저장 된다.
예시로 알아보자.
package koyo.study.week2;
public class Exam_001 {
public static void main(String[] args){
String name = "koyo";
int age = 27;
}
}레퍼런스 타입의 name 변수와 프리미티브 타입의 age 변수는 런타임 스택 영역에 생성 된다.
그리고 레퍼런스 타입의 값인 주소값과, 프리미티브 타입의 값인 17 역시 런타임 스택 영역에 저장 된다.
다만, 레퍼런스 타입의 값인 주소값이 가리키는 실제 값은 가비지 컬렉션 힙 영역에 객체가 생성된다.
그래서 값을 복사할 때 조심해야한다.
그 이유는 레퍼런스 타입의 경우 실제 값이 아닌 주소값이 복사되기 때문이다. 보통 이러한 경우를 주소에 의한 복사(Call by Reference)라고 한다. 아래의 복사의 방식을 참고하여 프로그램의 의도에 맞도록 복사해야한다.
복사의 방식
- 값에 의한 복사 : 프리미티브 타입의 경우에 일어나며, 실제 값을 복사하는경우
- 주소에 의한 복사 : 레퍼런스 타입의 경우에 일어나며, 가비지 컬렉션 힙 영역에 있는 객체의 주소값을 복사하는 경우
주소에 의한 복사의 경우, 두 가지 경우로 나누어서 볼 수 있다.- 얕은 복사 : 주소값을 복사하여 같은 객체를 참조하는 경우(값을 공유한다고 볼 수 있다. 객체 1개에 이름표 2개)
- 깊은 복사 : 새로운 객체를 생성하여 해당 주소를 참조하는 경우(값을 공유하지 않는다. 객체 1개당 이름표 1개)
리터럴
리터럴은 실제로 저장되는 값 그 자체로 메모리에 저장되어있는, 변하지 않는 값을 말한다.
컴파일 타임에 프로그램 안에 정의되어 그 자체로 해석되어야 하는 값을 뜻한다.
상수(Constant)는 리터럴(Literal)과 다르다.
상수 : final 키워드로 선언된 변수
리터럴 : 변하지 않는 고정된 값이라는 것은 동일하나, 실제로 저장되는 어떠한 값 자체를 뜻한다.
변수 선언 및 초기화하는 방법
변수를 선언하는 방법은 기본적으로 그 변수의 타입(자료형) 다음에 변수의 이름을 작성하는 것으로 한다.
초기화하는 방법은 대입 연산자인 등호(=)를 사용한다.
public class Exam_003 {
public static void main(String[] args) {
int value1; // 정수형 타입의 변수 value1을 선언
int value2, value3, value4; // 정수형 타입의 변수 value2, value3, value4 동시 선언
// 1. 선언과 동시에 초기화
int value5 = 10;
// 2. 선언한 다음에 초기화
int value6;
value6 = 20;
}
}
변수의 스코프와 라이프타임
자바는 블록 스코프를 사용한다.(블록은 중괄호 {}를 뜻한다.)
그럼 예시를 살펴보자.
public class Exam_006 {
// 여기 선언된 변수는 Exam_006 {} 블록 내에서 접근 가능하다.
static int myBlock = 10;
public static void main(String[] args) {
System.out.println("result : " + myBlock);
}
}
// 실행결과
// result : 105라인에 선언한 myBlock 변수는 3라인의 Exam_006 {} 블록 내에서 접근이 가능하기 때문에 이 코드를 실행하면
위와 같은 결과를 볼 수 있다.
다른 예시를 살펴보자.
public class Exam_007 {
// 여기 선언된 변수는 Exam_007 {} 블록 내에서 접근 가능하다.
static int myBlock = 10;
public static void main(String[] args) {
int myBlock = 20;
System.out.println("result : " + myBlock);
}
}
// 실행결과
// result : 209라인에 myBlock을 사용할 때, 이 값을 자신과 가까운 블록 스코프에서 찾는다. 없을 경우 상위 블록 스코프에 존재하는지 찾아본다.
런타임 스택 영역에 생성된 변수의 라이프 타임은 블록 스코프에 의존적이다.
즉, 블록 내에서 선언된 변수는 블록이 종료될 때 런타임 스택 영역에서 함께 소멸한다.
타입 변환, 캐스팅 그리고 타입 프로모션
타입이란, 데이터 타입을 줄인 말이고 다른 말로 자료형이라고도 한다.
특정 데이터 타입으로 표현된 리터럴은 다른 데이터 타입으로 변환할 수 있다.
예를 들어 int타입 변수에 담긴 값을 long 타입 변수에 담을 수 있다.
public class Exam_009 {
public static void main(String[] args){
int v1 = 100;
long v2 = v1;
System.out.println("v1 : " + v1);
System.out.println("v2 : " + v2);
}
}
// 실행결과
// v1 : 100
// v2 : 100이렇게 변환될 때 크게 두가지 경우를 생각해볼 수 있다.
- 자신의 표현 범위를 모두 포함한 데이터 타입으로의 변환.(타입 프로모션)
- 자신의 표현 범위를 모두 포함하지 못한 데이터 타입으로의 변환. (타입 캐스팅)
이를 구분하기 위해서는 메모리 크기가 아닌 데이터 표현 범위를 따져봐야 한다.
예를 들어, 실수를 표현하는 float 데이터 타입의 값을 정수로 표현하는 long 데이터 타입 값으로 변환을 시도한다면, long 데이터 타입은 실수를 표현할 수 없기 때문에 원본 데이터에 손실이 발생할 수 있다.
이렇게 원본 데이터가 담긴 데이터 타입의 표현 범위를 변환할 데이터 타입의 표현 범위가 모두 수용하지 못할 경우 데이터 손실이 발생할 수 있는데, 이것을 타입 캐스팅이라고 한다.
밤대로 모두 수용할 수 있다면 타입 프로모션이라고 한다.
long 타입이 float 타입으로 타입 프로모션이 되는 것을 보면 알 수 있다.
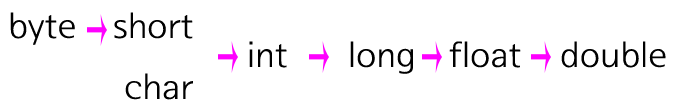
사진출처 : 형변환 - 생활코딩
위와 같은 순서로 타입 프로모션이 가능하다.
1차 및 2차 배열 선언하기
1차, 2차 배열을 선언하기에 앞서 배열이 무엇인지 알자.
배열은 동일한 자료형을 정해진 수만큼 저장하는 순서를 가진 레퍼런스 타입 자료형이다.
배열을 활용하는 이유는 다양한 변수의 이름을 각각 지을 필요가 없어지고, 반복문 및 제어문을 통해 간단하게 접근할 수 있기 때문이다.
참고
배열은 순서(index)를 0부터 n-1까지 가진다. 이를 zero base라고도 표현한다.
Java에서는 어떻게 1차원 배열을 선언하는지 예시로 알아보자.
public class Exam_014 {
public static void main(String[] args) {
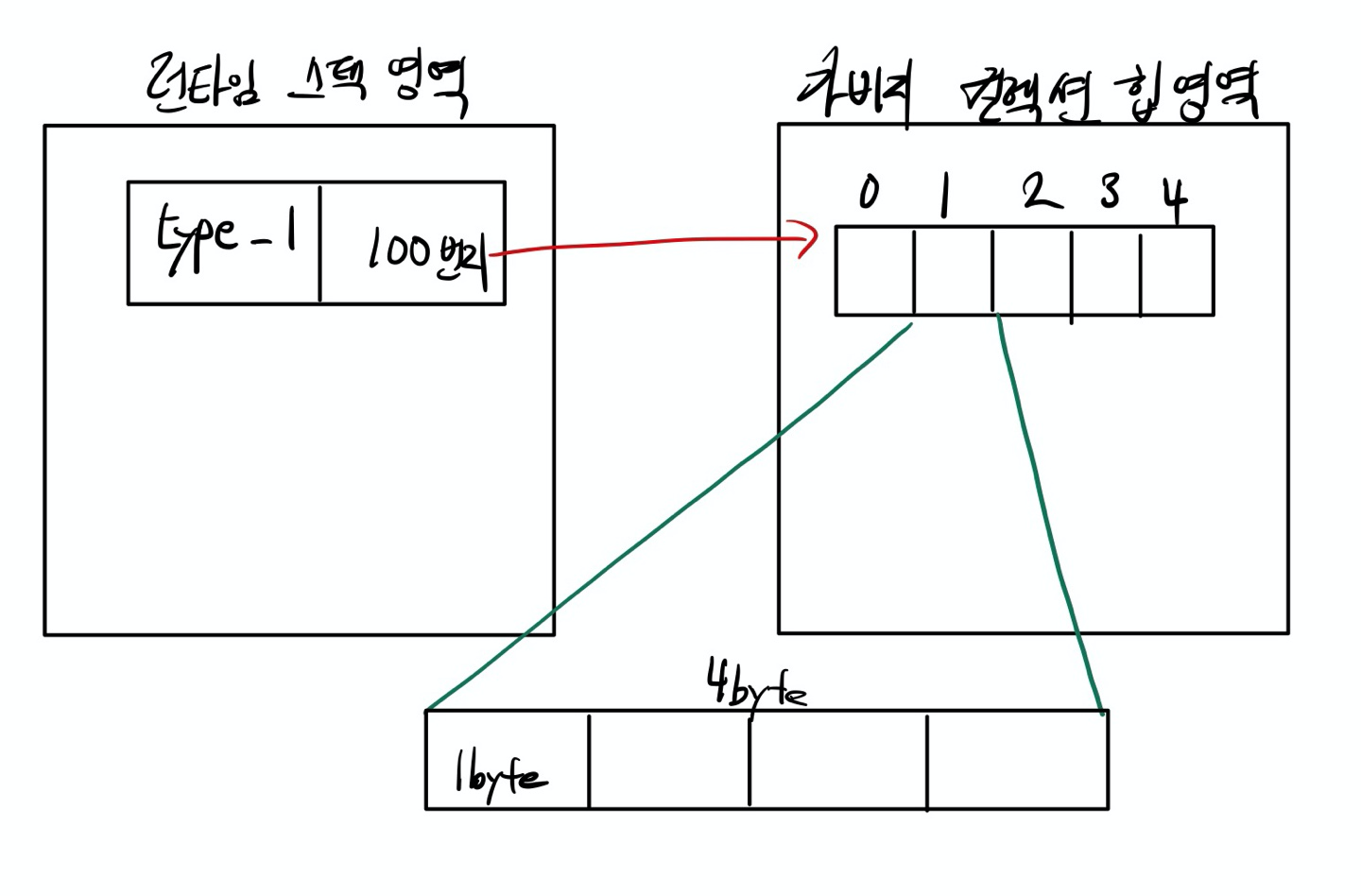
int[] type_1 = new int[5];
int[] type_2 = {10, 20, 30, 40, 50};
int[] type_3 = new int[]{10, 20, 30, 40, 50};
// 2번째 방법은 변수 선언과 동시에 할당하는 경우만 사용할 수 있는 방법이다.
// type_2 = {10, 20, 30, 40, 50} 은 안된다!
}
}이와 같은 경우 메모리 영역에서는 아래와 같이 할당된다.
그럼 2차원 배열은 어떻게 선언할지도 알아보자.
public class Exam_015 {
public static void main(String[] args){
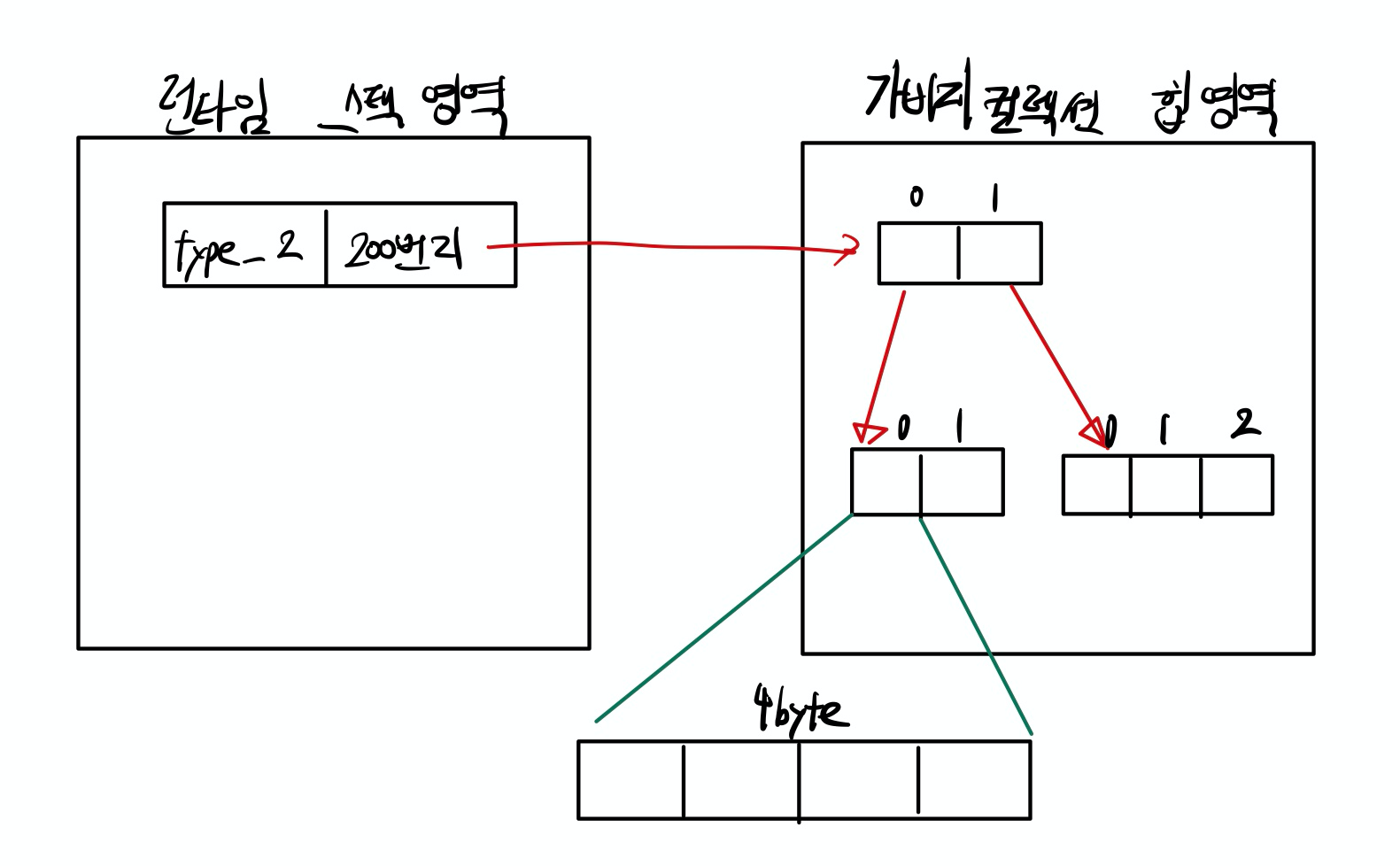
int[][] type_1 = {{1, 2}, {3, 4, 5}};
int[][] type_2 = new int[2][3];
int[][] type_3 = new int[][]{{1, 2}, {3, 4, 5}};
}
}2차원 배열의 선언시에 메모리 영역에서는 아래와 같이 할당된다.
참고
2차원 배열의 경우, type_2[0]이 가지고 있는 값은 가리키는 배열의 시작주소인 type_2[0][0]의 주소 값이다.
또한, 행에 대해 열의 기링가 다른 배열을 지그재그하다고 해서 재기드배열(jagged array)라고도 한다.
타입 추론, var
타입 추론(Type inference)란, 값을 보고 컴파일러가 데이터 타입이 무엇인지 추론하는 것을 의미한다.
이는 javascript나 python과 같은 언어에서 데이터 별 타입을 선언하지 않거나 동일하게 선언하여 쓰는 경우에서 볼 수 있다.
타입 추론에 대해서는 대표적으로 제네릭에서 볼 수 있다.
import java.util.HashMap;
public class Exam_019 {
public static void main(String[] args) {
HashMap<String, Integer> myHashMap = new HashMap<>();
}
}myHashMapdp HashMap 객체를 할당할 때 new HashMap<String, Integer>()를 사용하지 않고, new HashMap<>()을 사용했다. 이것은 myHashMap 변수에 담길 데이터 타입이 HashMap<String, Integer> 라는 것을 myHashMap 변수의 데이터 타입을 바탕으로 추론해낼 수 있기 때문이다.
var를 사용하면 제약 사항이 몇가지 존재한다.
1. 로컬 변수여야 한다.
2. 선언과 동시에 값이 할당되어야 한다.
자바는 다른 언어에 비해 타입 추론 개념이 늦게 도입되었다. 이는 하위 호환성을 중요하게 생각하며 자바 개발진이 보수적이기 때문이다.
Java 10에서 var 제대로 사용하기 1
Java 10에서 var 제대로 사용하기 2
해당 문서는 백기선 님의 스터디할래를 공부하면서 정리한 글로, 다음 링크의 글을 많이 참고하였습니다.
참고. nimkoes님의 블로그
