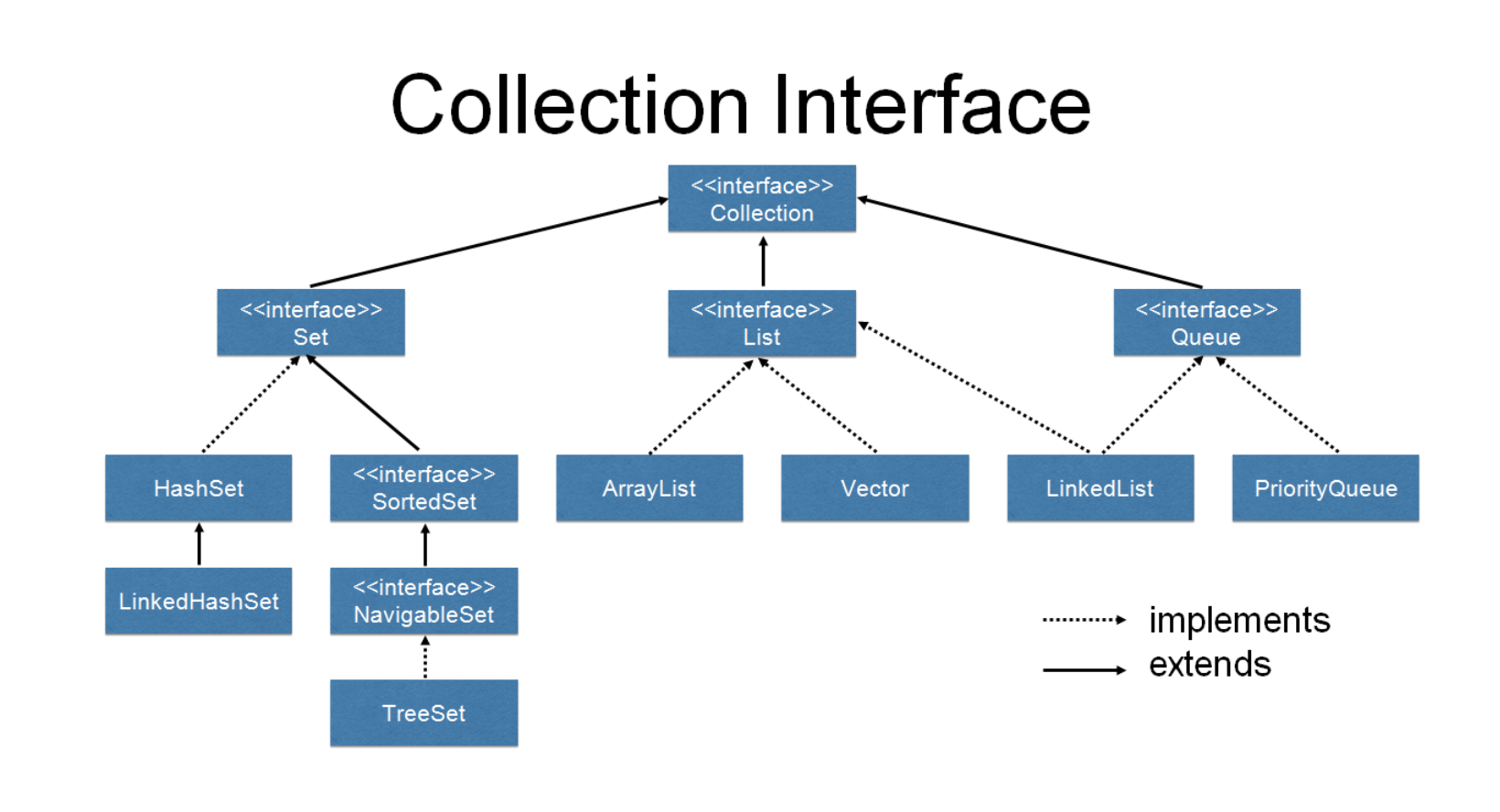
🙌 HashSet, TreeSet을 알아보기
🧐 HashSet이란 ❓
이름에도 나와 있듯이 Set 인터페이스를 구현한 가장 대표적인 컬렉션이다. Set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다. 데이터를 추가하는 메소드를 호출했을 경우, 만약 데이터가 이미 저장되어 있다면 false를 반환한다.
Set인터페이스의 또 다른 특징인 저장순서를 유지하고 있지 않는다. Set이 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
🧐 HashSet은 어떤 method를 가지고 있을까❓
boolean add(Object O) : 새로운 객체를 저장한다.
boolean addAll(Collection c) : 주어진 컬렉션에 저장된 모든 객체들을 추가한다.(합집합)
boolean contains(Object o): 지정된 객체를 포함하고 있는지 알려준다.
boolean containsAll(Collection c): 주어진 컬렉션에 저장된 모든 객체들을 포함하고 있는지 알려준다.
boolean remove(Object o): 지정된 객체를 HashSet에서 삭제한다.
boolean retainAll(Collection c): 주어진 컬렉션에 저장된 객체와 동일한 것만 남기고 삭제한다.(교집합)
🧐 내가 만든 객체를 HashSet에 넣을 때 주의할 점 ❓
해당 예제는 Java의 정석 3판 2편 634페이지에서 참고하였습니다.
import java.util.*;
class HashSetEx4{
public static void main(String[] args) {
HashSet set = new HashSet();
set.add(new String("abc"));
set.add(new String("abc"));
set.add(new Person2("David", 10));
set.add(new Person2("David", 10));
System.out.println(set);
}
}
class Person2{
String name;
int age;
Person2(String name, int age) {
this.name = name;
this.age = age;
}
public boolean equals(Object obj){
if(obj instanceof Person2) {
Person2 tmp = (Person2)obj;
return name.equals(tmp.name) && age == tmp.age;
}
return false;
}
public int hasCode(){
return (name+age).hashCode();
}
public String toString(){
return nbame + ":" + age;
}
}HashSet는 add메서드를 사용해서 새로운 요소를 추가할 때, 기존의 요소와 동일한 요소인지 판별하기 위해, equals와 hashCode 메소드를 호출한다. 그렇기 때문에, 해당 객체를 set에 넣어서 올바른 결과를 얻기 위해서는 equals와 hashCode 메소드를 목적에 맞게 오버라이딩해야 한다.
🧐 TreeSet이란 ❓
이진 검색 트리라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다. 정렬, 검색, 범위검색에 높은 성능을 보이는 자료구조이다. Red-Black Tree로 구현되어 있다.
그리고 TreeSet은 Set인터페이스의 특징도 가지고 있기 때문에 중복된 데이터의 저장을 허용하지 않고, 정렬된 위치에 데이터를 저장하므로 저장 순서도 유지하지 않는다.
Red-Black Tree란
단순히 이진 검색 트리로 데이터를 저장하다보면, 데이터 쏠림 현상이 발생할 수 있다. 데이터 쏠림 현상이 발생하면, 이진 검색 트리를 사용하는 이점이 없어진다. 이진 검색 트리는 O(logH)의 시간 복잡도를 가져야 이점을 얻는 자료구조 인데, 데이터 쏠림 현상이 생긴다면, O(N)의 시간복잡도를 가지기 때문이다.
*여기서 H는 트리의 높이를 의미한다.
Red-Black Tree는 이러한 문제를 해결하기 위해, 만들어진 balanced tree이고 항상 트리가 최적의 높이를 가질 수 있도록 한다.
🧐 HashSet은 어떤 method를 가지고 있을까❓
Object ceiling(Object o): 지정된 객체와 같은 객체를 반환. 없으면 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null
NavigableSet descendingSet(): TreeSet에 저장된 요소들을 역순으로 정렬해서 반환.
Object first(): 정렬된 순서에서 첫 번째 객체를 반환한다.
Object floor(Object o): 지정된 객체와 같은 객체를 반환. 없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null
SortedSet headSet(Object toElement): 지정된 객체보다 작은 값의 객체들을 반환한다.
NavigableSet headSet(Object toElement, boolean inclusive): 지정된 객체보다 작은 값의 객체들을 반환 inclusive가 true이면, 같은 값의 객체도 포함.
Object higher(Ojbect o): 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null
Object last(): 정렬된 순서에서 마지막 객체를 반환한다.
Object lower(Object o): 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null
Object pollFirst(): TreeSet의 첫번째 요소를 반환
Object pollLast(): TreeSet의 마지막 번째 요소를 반환.
Sorted subSet(Object fromElement, Object toElement): 범위 검색의 결과를 반환한다.
NavigableSet subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive): 범위 검색의 결과를 반환한다. fromInclusive가 true면 시작값이 포함되고, toInclusive가 true면 끝값이 포함된다.
SortedSet tailSet(Object fromElement): 지정된 객체보다 큰 값의 객체들을 반환한다.
Reference
- Java의 정석 2편 - 남궁성
