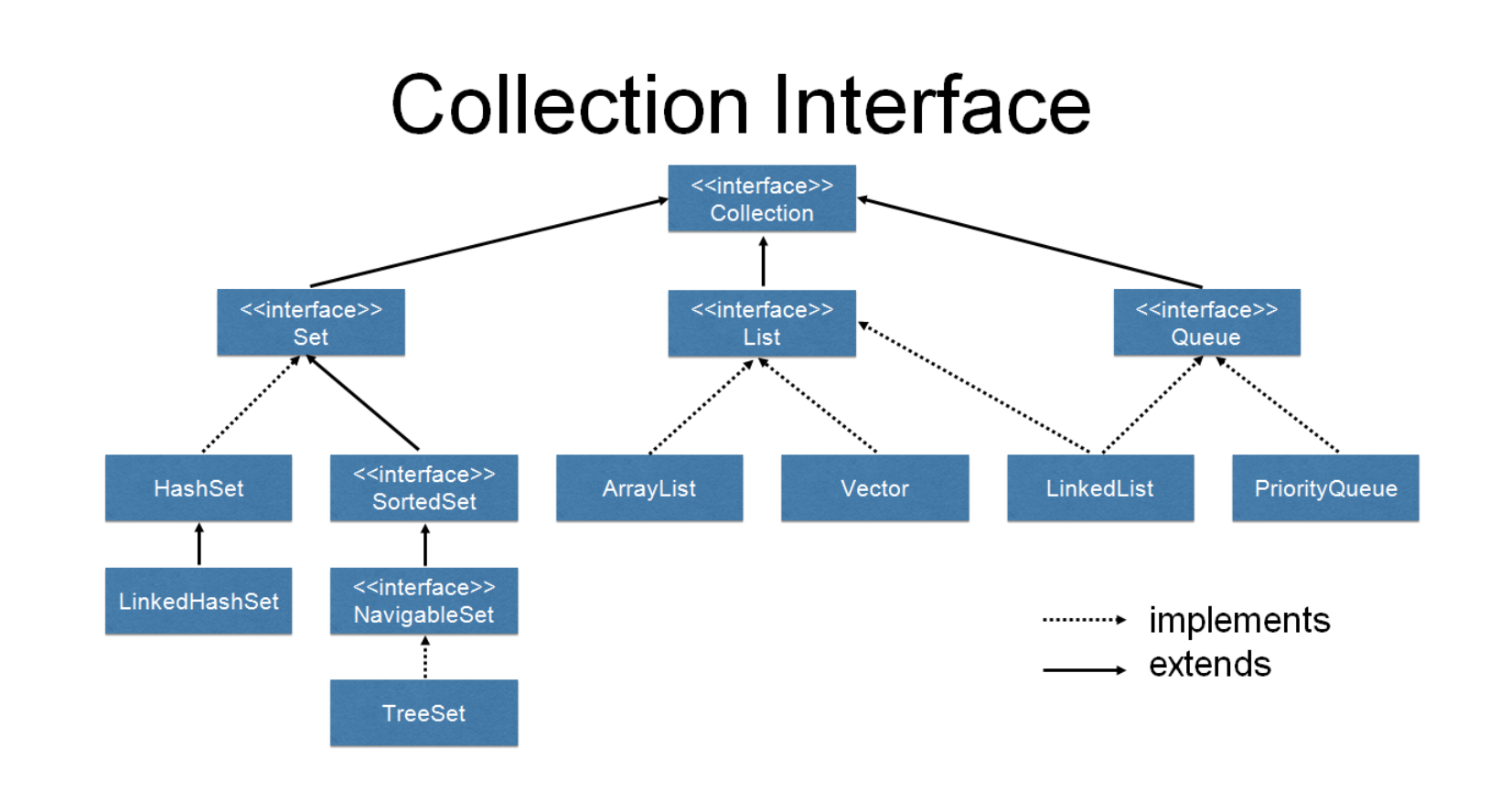
ArrayList, LinkedList, Stack, Queue 알아보기
ArrayList
- List인터페이스를 구현하기 때문에, 데이터의 저장순서가 유지되고 중복을 허용한다는 특징을 갖는다.
- 기존의 Vector를 개선한 것으로 Vector와 구현원리와 기능적인 측면에서 동일하다고 할 수 있다.
- 배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장된다.
- 데이터를 읽어오는데 걸리는 시간이 가장 빠르다.(index로 접근시에 상수시간안에 접근이 가능하다)
- 크기를 변경할 수 없고, 데이터를 배열의 중간에 추가하거나, 배열 중간의 데이터를 삭제하는 것에는 새로운 빈자리를 만든 후, 다른 데이터들을 복사해서 이동해야 되기 때문에 시간이 오래걸리는 단점을 가지고 있다.
주요 method
- boolean add(Object o) : ArrayList 마지막에 객체를 추가.
- boolean contains(Object o): 지정된 객체가 포함되어 있는지 확인.
- Object get(int index): 지정된 위치에 저장된 객체 반환.
- int indexOf(Object o): 지정된 객체가 저장된 위치를 찾아 반환.
- boolean isEmpty(): ArrayList가 비어있는지 확인.
- Iterator iterator(): Iterator 객체 반환.
- int lastIndexOf(Object o): o가 저장된 위치를 끝부터 역방향으로 탐색.
- Object remove(int index): 지정된 위치에 있는 객체 제거.
- List subList(int fromIndex, int toIndex): fromIndex부터 toIndex사이에 저장된 객체를 반환.
LinkedList
- 배열의 단점을 보완하기 위해 만들어진 자료구조이다.
- 데이터들이 불연속적으로 존재하고, 서로 연결되어 있다.
- 현재 노드는 다음 노드의 주소를 저장하고 있다.
- 새로운 데이터를 중간에 추가할 때는 새로운 요소를 추가한 후, 현재 위치의 이전 요소의 참조를 새로운 요소에 대한 참조로만 변경하고, 새로운 요소가 그 다음 요소를 참조하도록 변경하면, 새로운 데이터를 중간에 쉽게 추가할 수 있다.
Doubly linked list
- 링크드 리스트는 이동방향이 단방향으로 되어 있어, 다음 요소에 대한 접근은 쉽지만, 이전 요소에 대한 접근이 어렵기 때문에 이를 보완하기 위해, 이전 요소도 참조할 수 있는 참조 변수를 추가해, 양쪽을 참조할 수 있는 링크드 리스트를 만들었다.
주요 method(ArrayList와 겹치는 거 제외)
- Object set(int index, Object element) : 지정된 위치의 객체를 주어진 객체로 바꿈
- Object peek(): LinkedList의 첫번째 요소를 반환
- Object poll(): LinkedList의 첫 번째 요소를 반환후 제거.
- void addFirst(Object o) : 맨 앞에 객체를 추가
- void addLast(Object o): 맨 끝에 객체를 추가
LinkedList vs ArrayList 속도 비교
순차적으로 추가/삭제하는 경우: ArrayList > LinkedList
중간 데이터를 추가/삭제하는 경우: ArrayList < LinkedList
원하는 index의 데이터 읽는 경우: ArrayList > LinkedList
- ArrayList는 각 요소들이 연속적인 메모리에 존재한다. 그렇기 때문에, 간단한 계산(배열의 주소 + 인덱스 값 * 데이터 타입의 크기)로 요소의 주소를 얻어서 데이터를 읽어올 수 있고, LinkedList는 불연속적으로 위치한 각 요소들이 서로 연결된 것이라 처음부터 n번째 데이터까지 차례대로 따라가야만 원하는 값을 얻을 수 있다.
Stack
LIFO(마지막에 저장한 데이터를 가장 먼저 꺼내는 구조)
- 한 방향으로만 빼고 넣을 수 있는 구조.
- 순차적으로 데이터를 추가하고 삭제하는 자료구조기 때문에, ArrayList와 같은 배열기반의 컬렉션 클래스를 사용하여 구현하는 것이 적합하다.
주요 method
-
boolean empty(): Stack이 비어있는 지 여부를 알려줌
-
Object peek(): 가장 맨 위에 있는 데이터를 가져온다. 비어있을 시 EmptyStackException이 발생한다.
-
Object pop(): Stack의 맨 위에 저장된 객체를 꺼낸다. 비어있을 시 EmptyStackException이 발생한다.
-
Object push(Object item): Stack에 객체를 저장한다.
-
int search(Object o): Stack에서 주어진 객체를 찾아서 그 위치를 반환.
-
다른 List구현체들과 method명이 달라서, 사용할 때 헷갈렸지만, push, pop이 Stack에 좀 더 어울리는 method명인 거 같다.
Queue
FIFO(가장 먼저 들어온 데이터를 가장 먼저 꺼내는 구조)
- 맨 앞에서는 뺄 수 있고, 맨 뒤로는 넣을 수 있는 구조.
- 큐는 스택과 다르게 데이터를 꺼낼 때 항상 첫 번째 저장된 데이터를 삭제하기 때문에, ArrayList와 같은 배열기반의 컬렉션 클래스를 사용한다면, 데이터를 꺼낼 때마다 빈 공간을 채우기 위해 데이터를 복사하고 다시 대입하는 일이 생기기 때문에 비효율적이다. 그래서 데이터의 추가 삭제가 쉬운 LinkedList로 구현하는 것이 적합.
주요 method
-
boolean add(Object o): 저장된 객체를 Queue에 추가. 저장공간 부족시 IllegalStateException 발생.
-
Object remove(): Queue에서 객체를 꺼내 반환. 비어있으면 NoSuchElementException
-
Object element(): 삭제없이 요소를 읽어오고, 비어있으면 ElementException
-
Object poll(): Queue에서 객체를 꺼내서 반환, 비어있으면 null
-
Object peek(): Queue가 비어있으면 null을 반환.
-
자바는 Stack클래스를 구현하여 제공하고 있지만, 큐는 Queue인터페이스로만 정의해 놓고, 별도의 클래스는 제공하고 있지 않다. Queue인터페이스를 구현한 클래스들을 선택해서 사용하면 된다.(ex. LinkedList, PriorityQueue)
PrirorityQueue
Queue인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위가 높은 것부터 꺼내는 특징을 가지고 있다.
- Heap 자료구조의 형태로 저장한다.
- Comparator를 사용하여, 직접 우선순위를 설정할 수 있다.
Deque
큐는 한 쪽 끝으로만 추가/삭제할 수 있지만, Deque는 양쪽 끝에 추가/삭제가 가능한 자료구조이다.
- Deque의 조상은 Queue이며, 구현체는 ArrayDeque와 LinkedList가 존재한다.
Reference
- Java의 정석 2편 - 남궁성
