
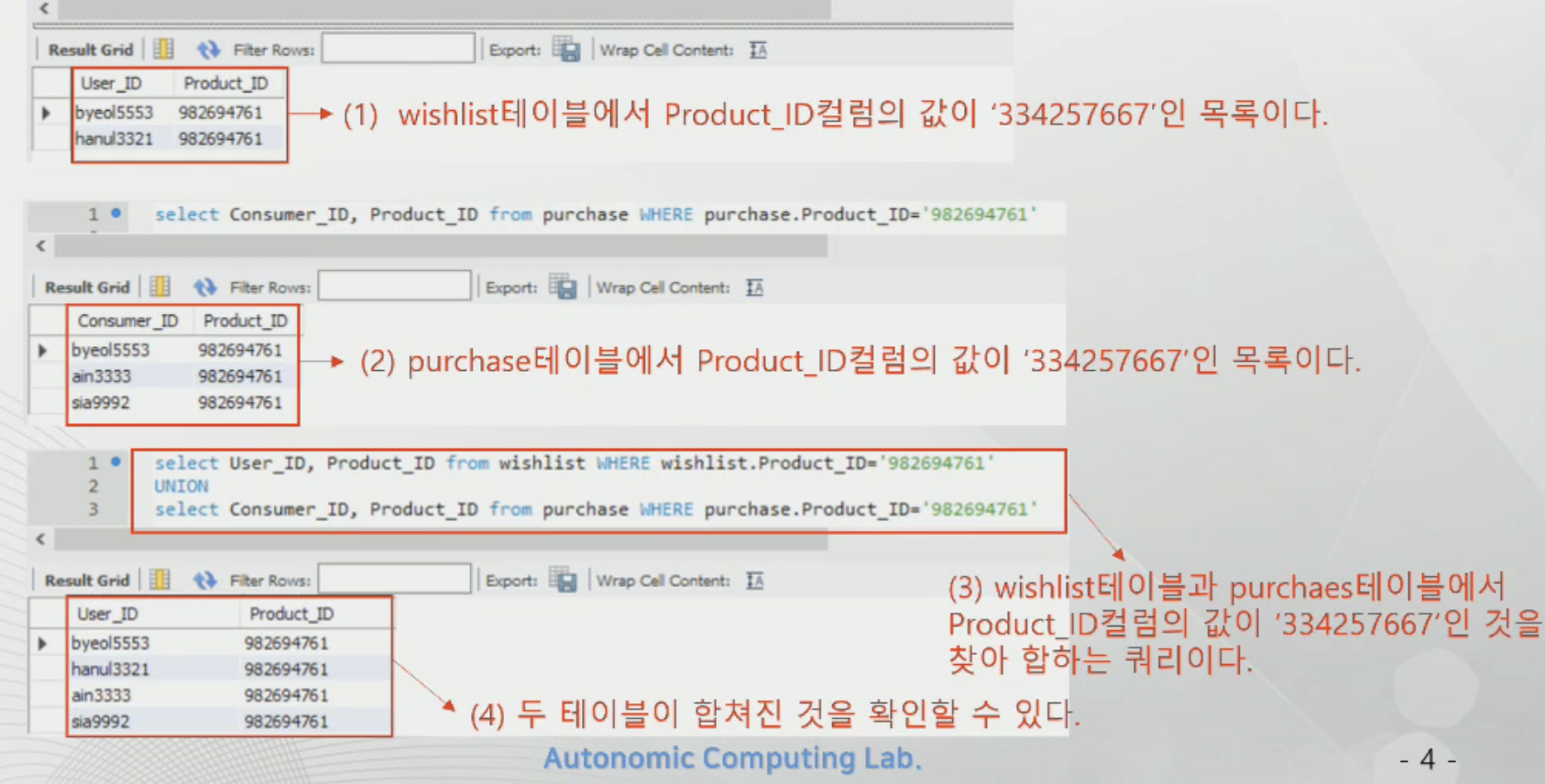
SELECT
UNION - 합집합(중복 허용)
주의사항
User_ID와 Consumer_ID, Product_ID와 Product_ID는 type이 동일해야 한다.
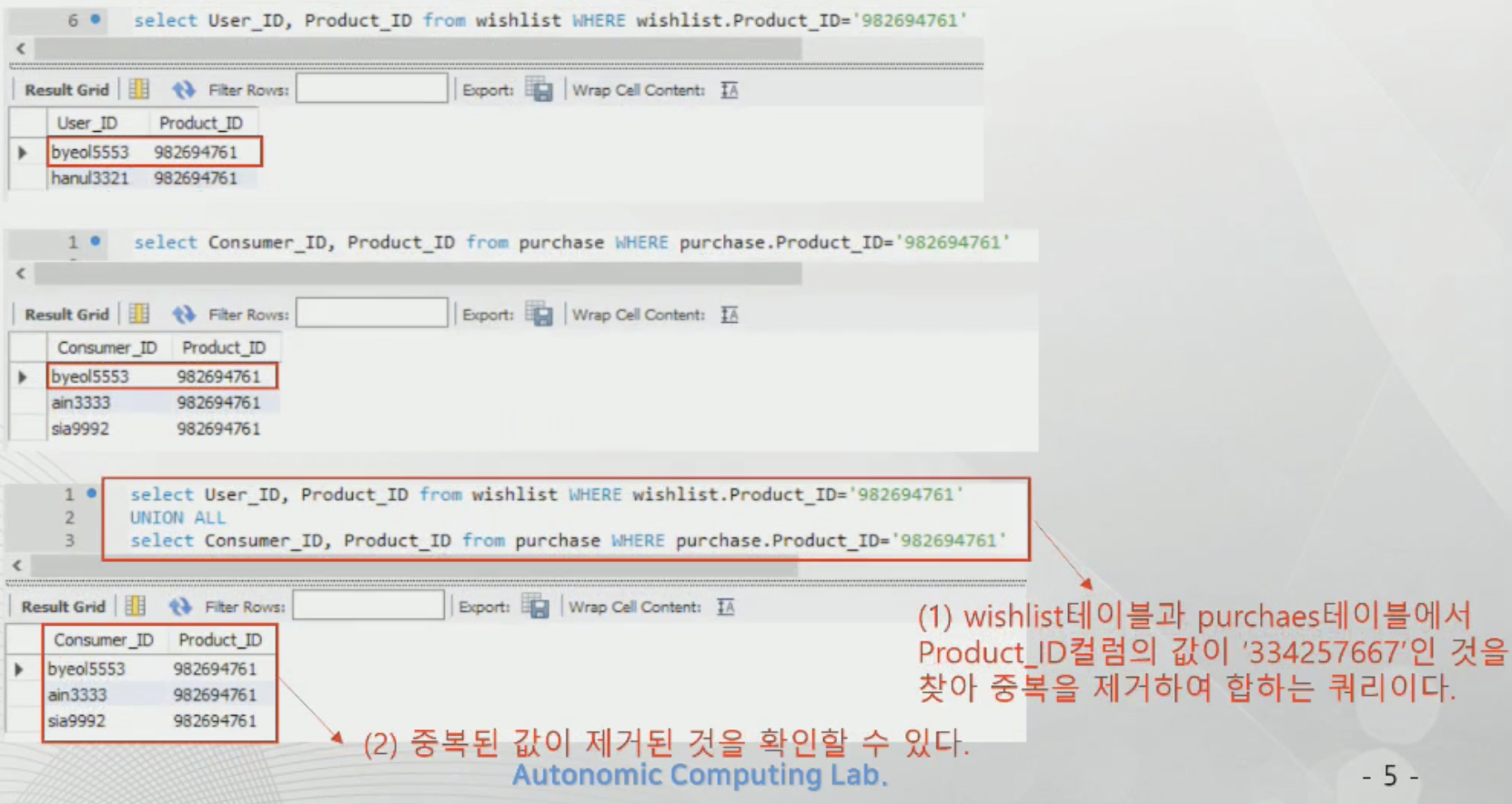
UNION ALL - 합집합(중복 제거)
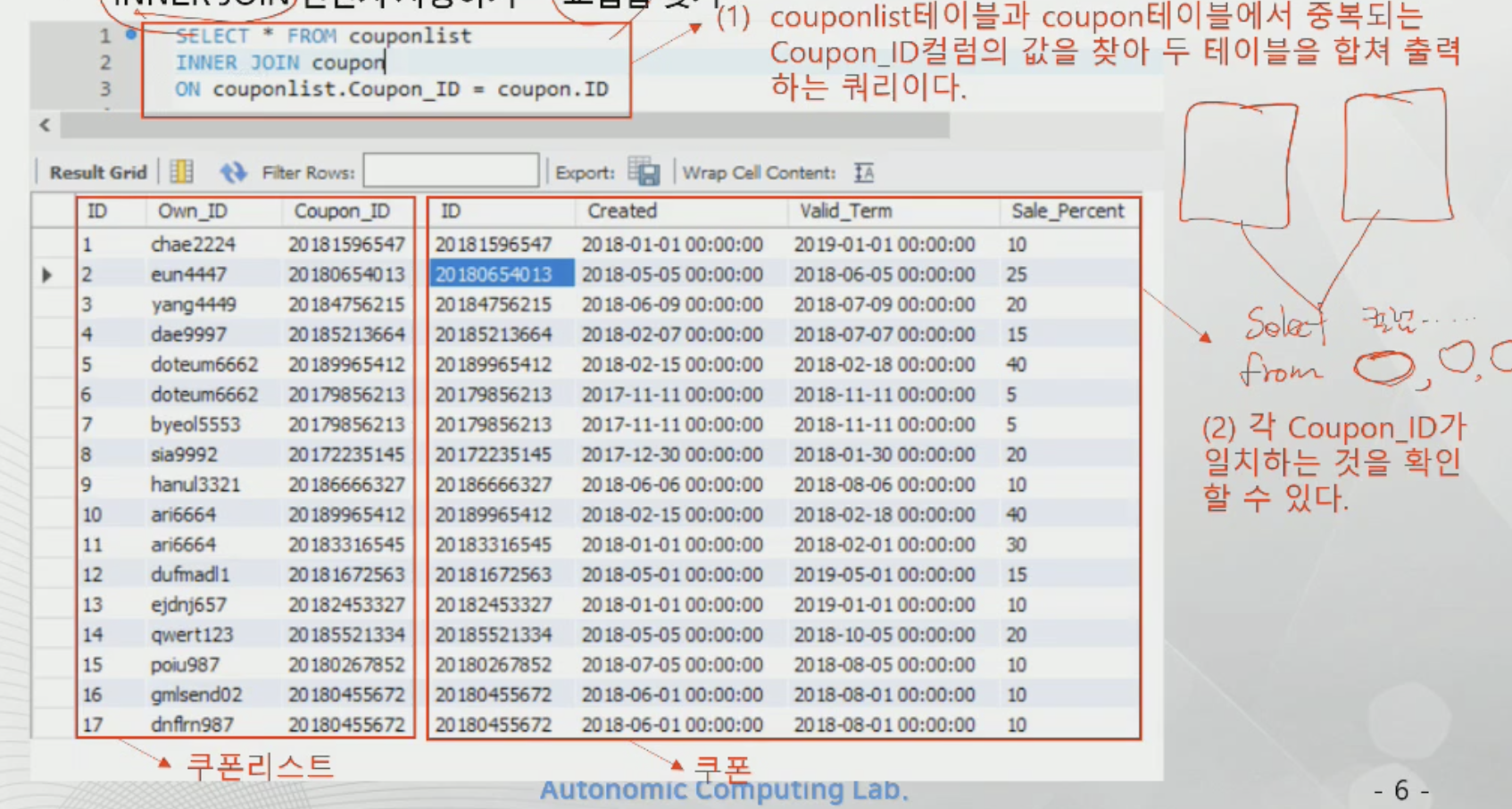
INNER JOIN - 교집합 찾기
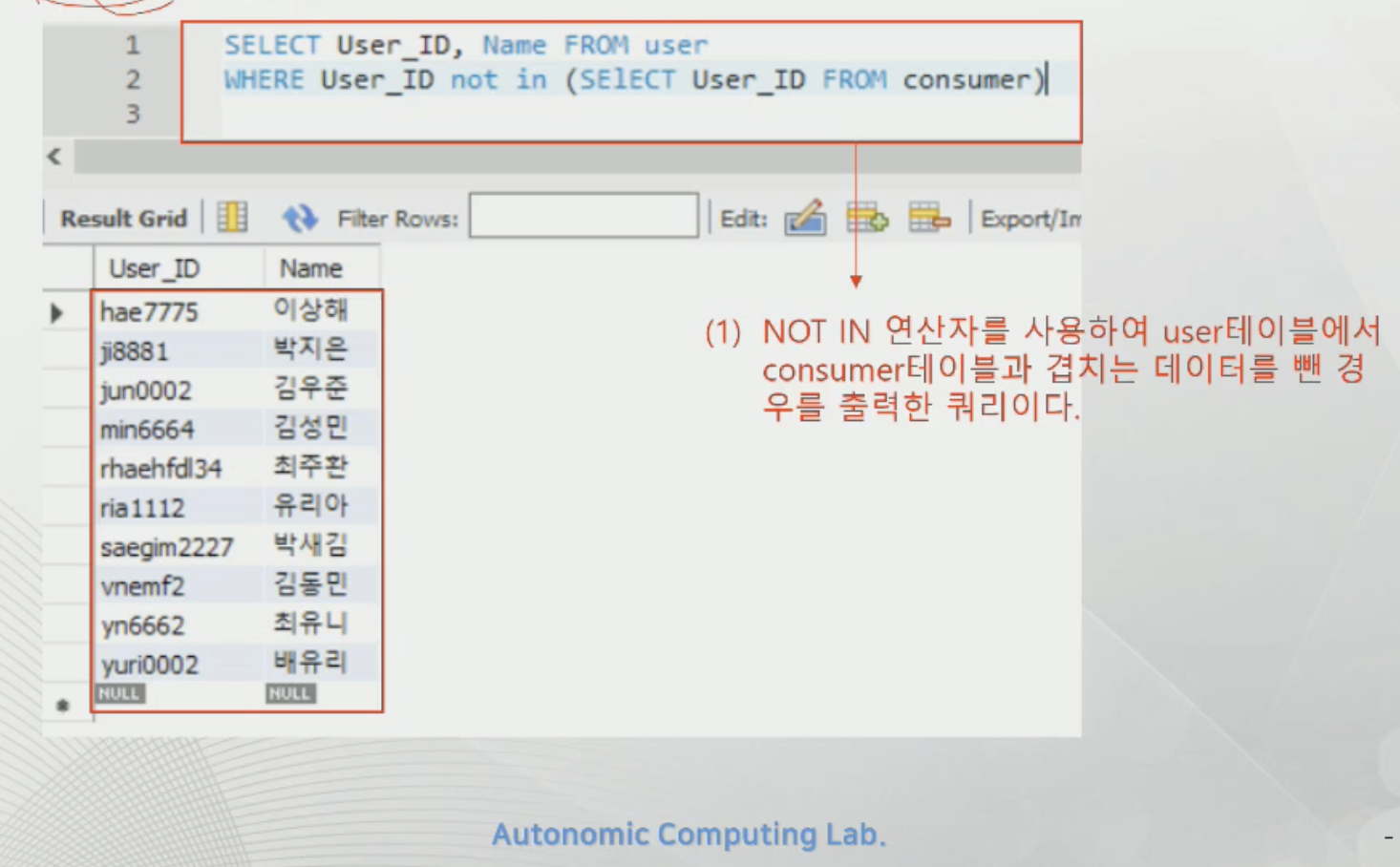
NOT IN - 차집합
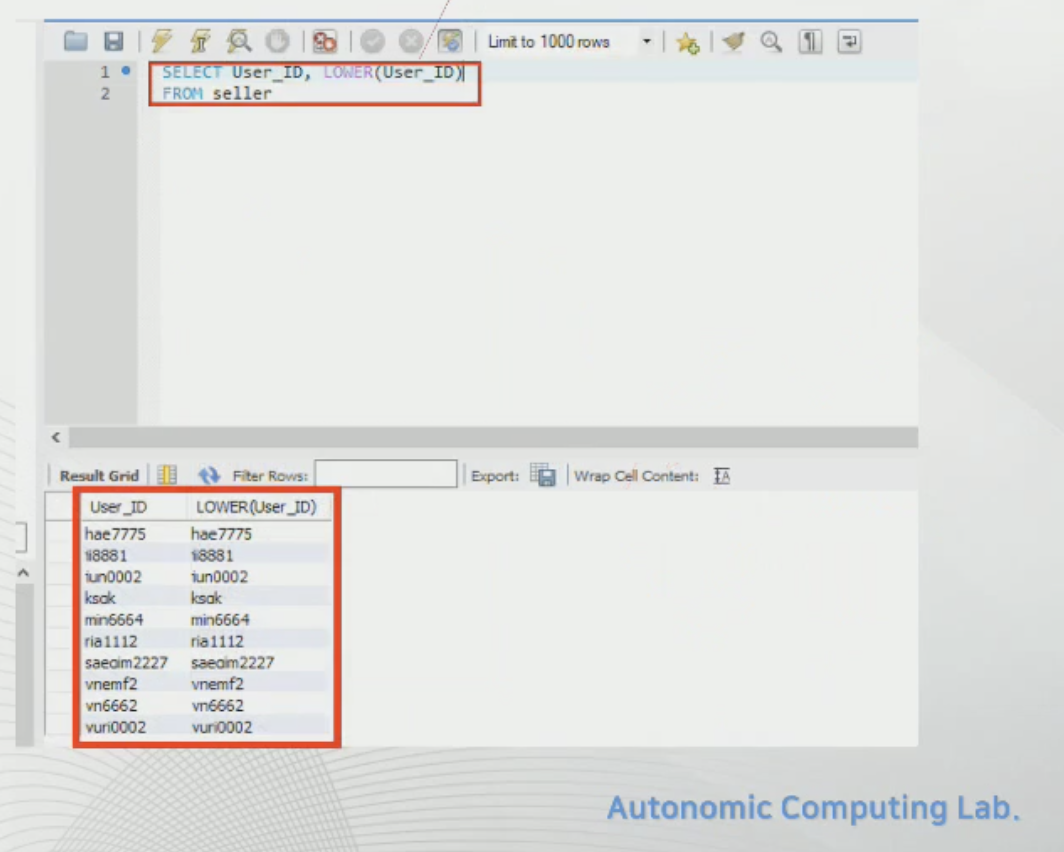
LOWER - 소문자 변경
UPPER - 대문자화
SELECT email, UPPER(email) FROM users
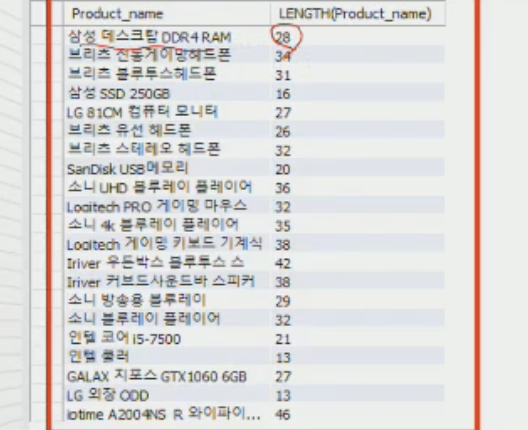
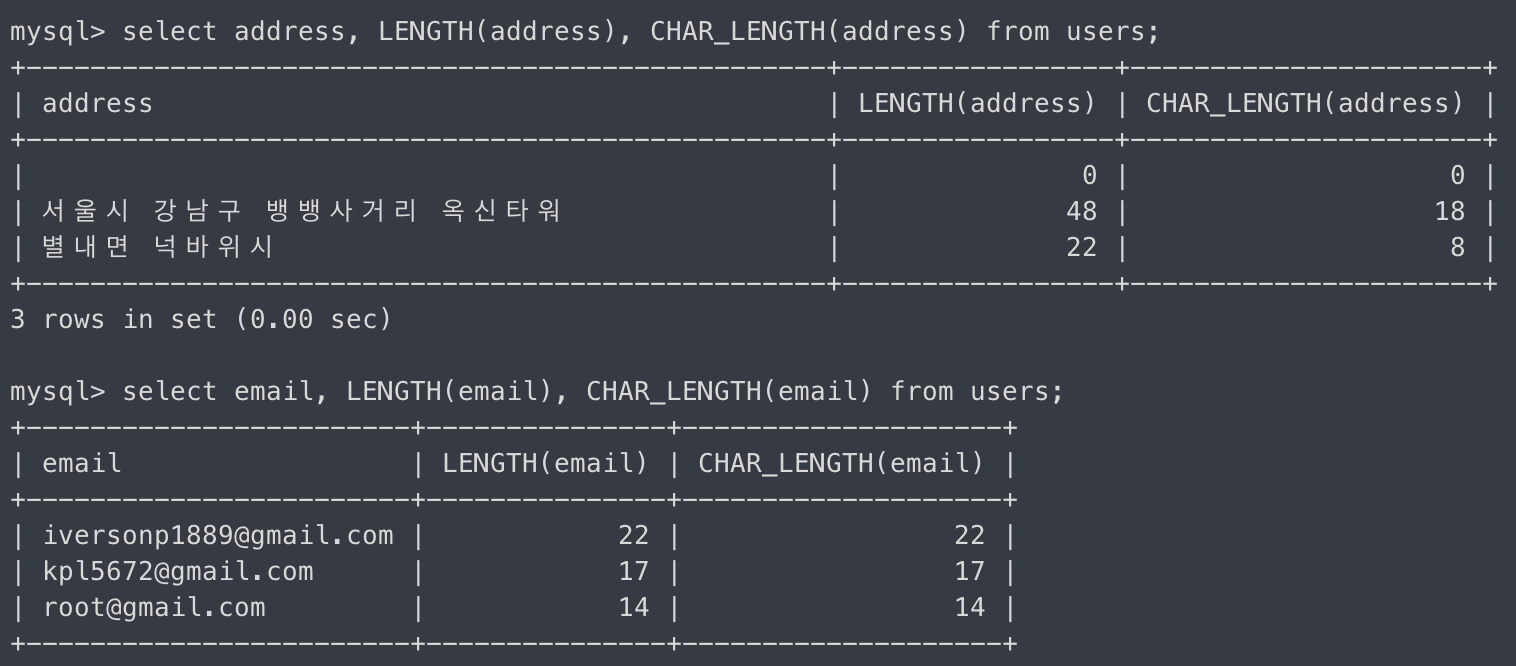
LENGTH - 컬럼의 길이(Byte) 반환
SELECT username, LENGTH(username) FROM users
CHAR_LENGTH - 컬럼의 길이(글자 수) 반환
SELECT username, CHAR_LENGTH(username) FROM users
CONCAT - 컬럼 하나로 결합시켜 반환
select CONCAT(username, gender), username, gender from users;

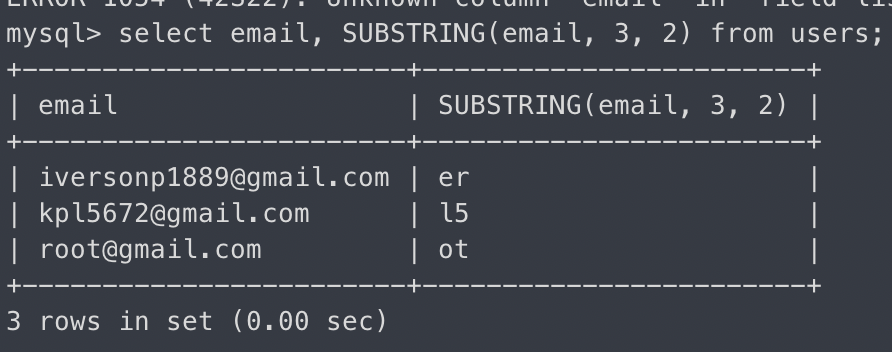
SUBSTRING - a~b까지 문자 반환
select email, SUBSTRING(email, 3, 2) from users;
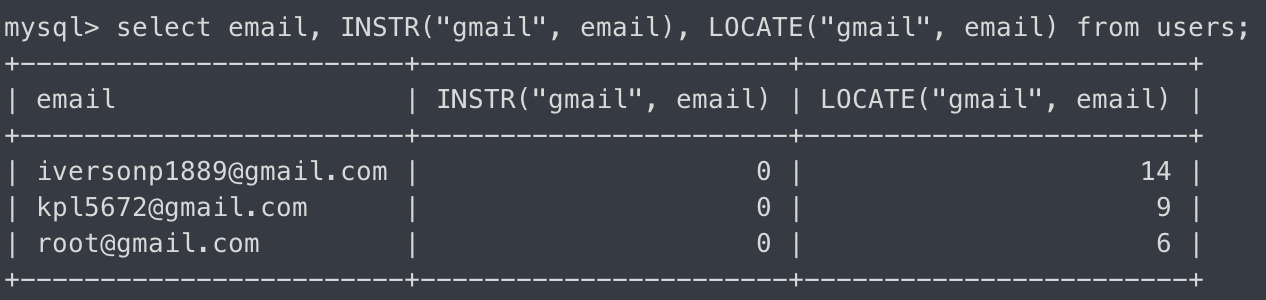
INSTR -첫번째 인자를 찾아 boolean반환(전체 일치)
문자열 전체가 일치해야 한다
select email, INSTR("root@gmail.com", email) from users;
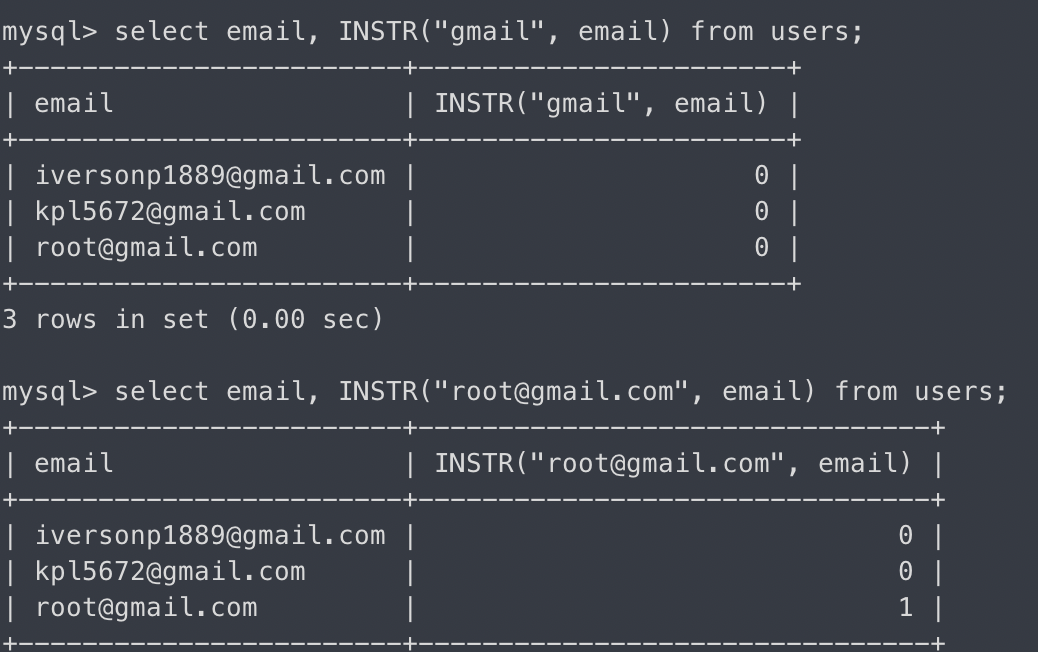
LOCATE - 첫 번째 인자를 찾아 boolean반환(부분 일치)
select email, INSTR("gmail", email), LOCATE("gmail", email) from users;
인강이랑 다르다. 인강에선 LOCATE는 일치하는 부분이 있으면 1을 반환한다 했는데, 실제 mysql에서 일치하는 부분의 인덱스가 반환된다. 업데이트 된건가?
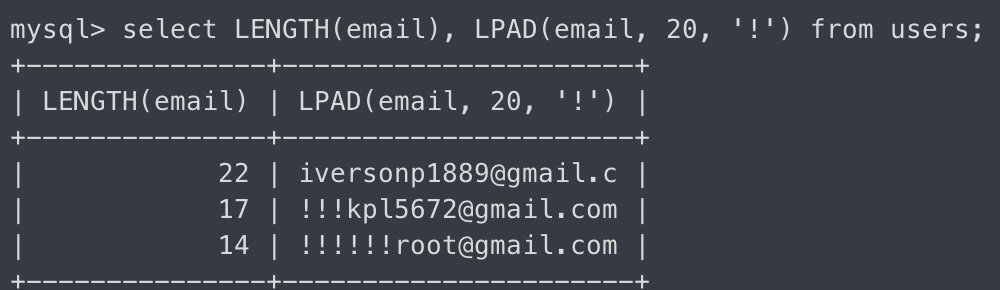
LPAD
-두 번째 인자 미만의 문자열일 경우, 남은 공간을 왼족에서부터 세 번째 인자로 채움.
select LENGTH(email), LPAD(email, 20, '!') from users;
RPAD
-설명 생략
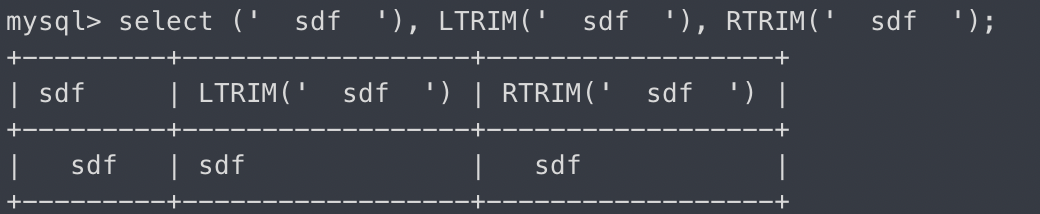
LTRIM, RTRIM
-문자열에서 왼쪽/오른쪽 공백 제거
select (' sdf '), LTRIM(' sdf '), RTRIM(' sdf ');
TRIM(LEADING [원하는 문자열] FROM 컬럼)
왼쪽부터 원하는 문자열을 제거하는 쿼리
select email, TRIM(LEADING "@gmail.com" FROM email) from users;
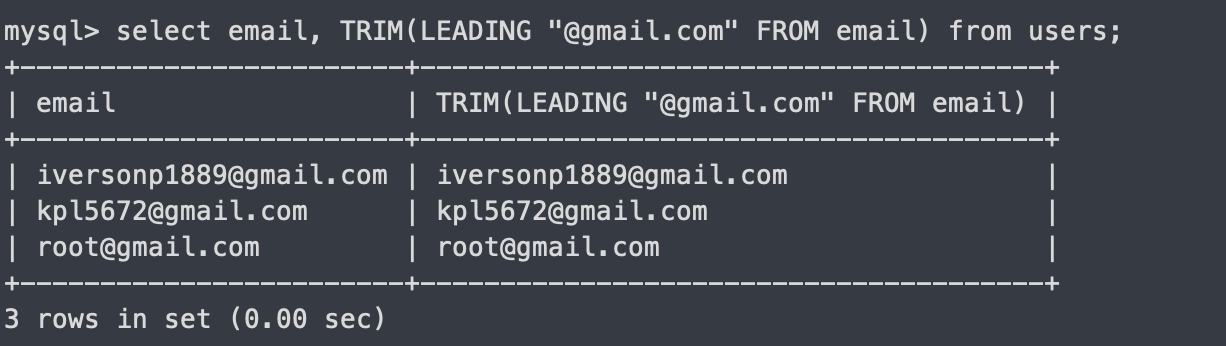
안되는데요....(오른쪽문자열을 해서 그런가보다)
select email, TRIM(TRAILING "@gmail.com" FROM email) from users;
이렇게 왼쪽 문자열 하니까 된다.
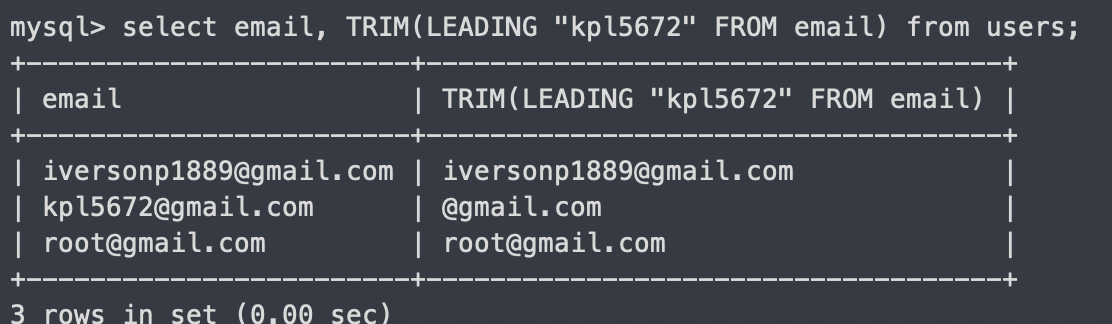
TRIM(TRAILING [원하는 문자열] from 컬럼)
오른쪽부터 원하는 문자열을 제거하는 쿼리
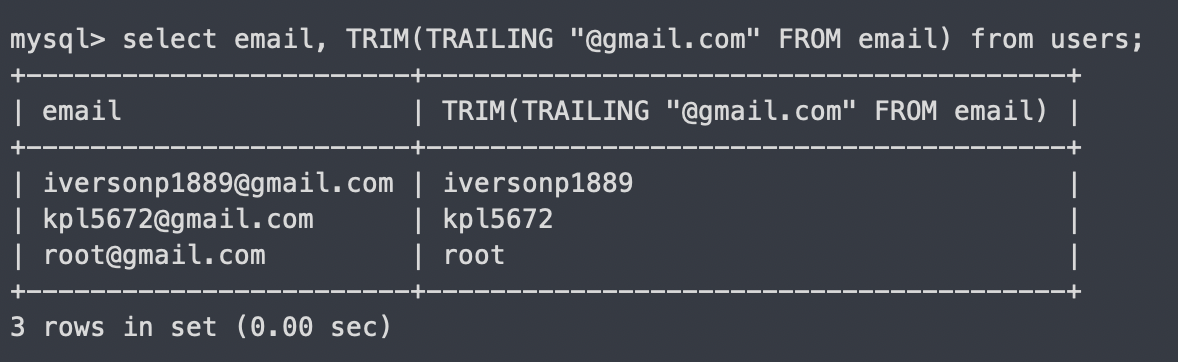
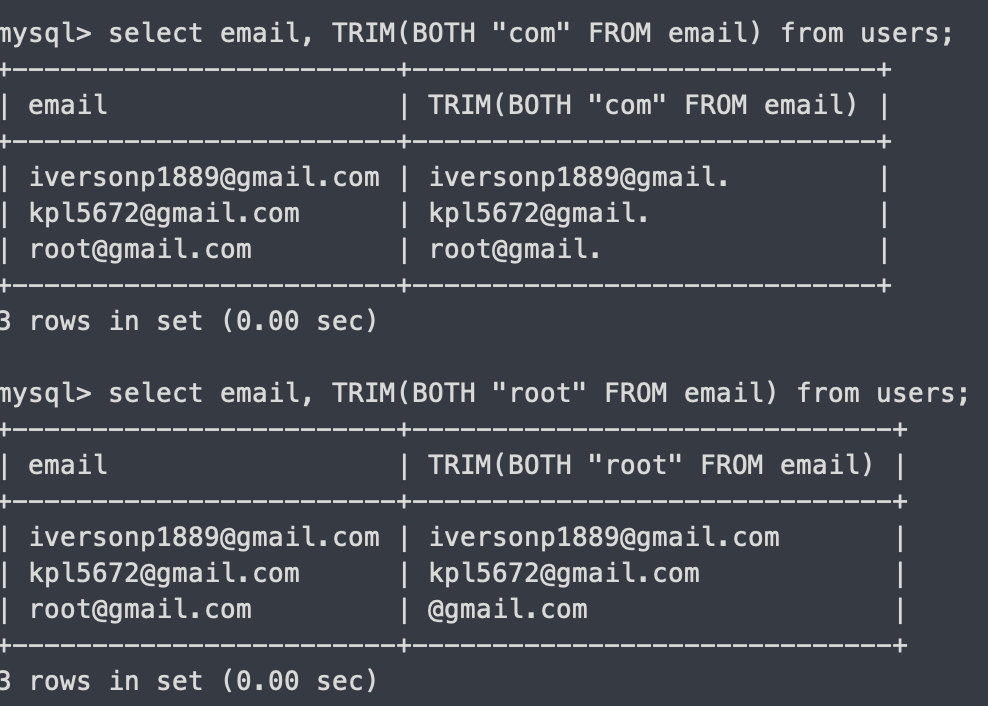
TRIM(BOTH [원하는 문자열] from 컬럼)
양쪽에서 원하는 문자열 제거
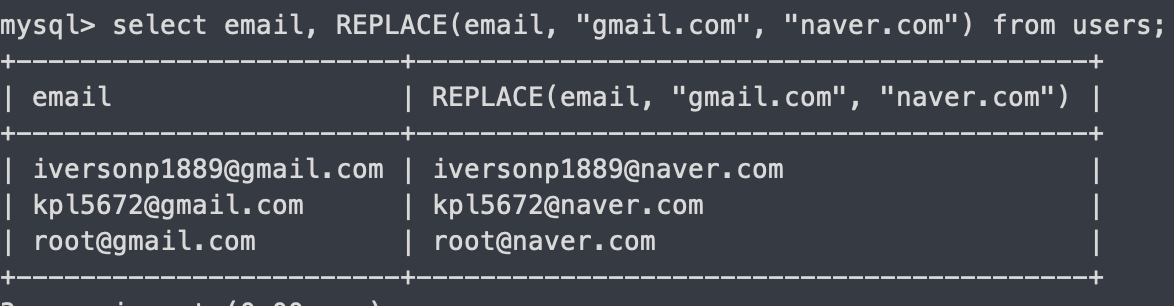
REPLACE - 컬럼에서 두번째 인자를 찾아 세번째 인자로 바꾸기
select email, REPLACE(email, "gmail.com", "naver.com") from users;
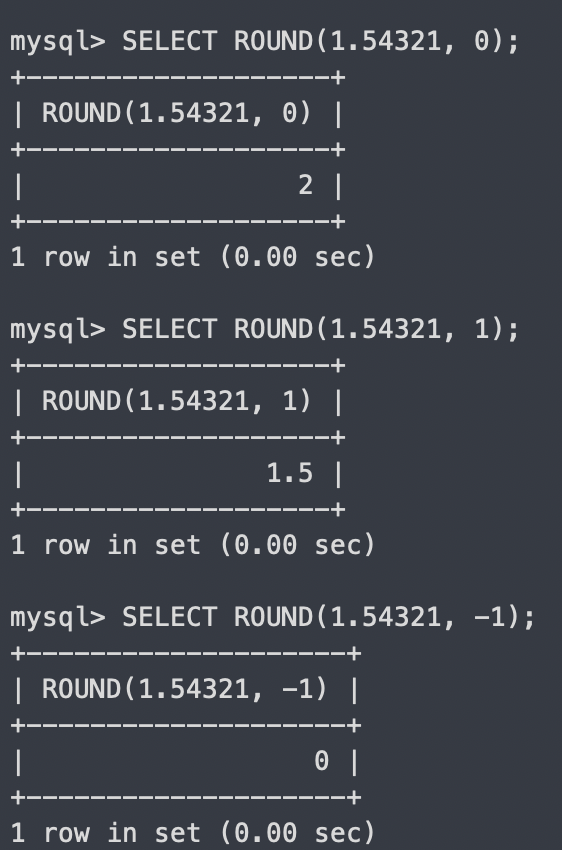
ROUND - (첫 인자)를 (두번째 인자) 자리수로 반올림
두 번째 인자를 설정하지 않을 시 default는 0
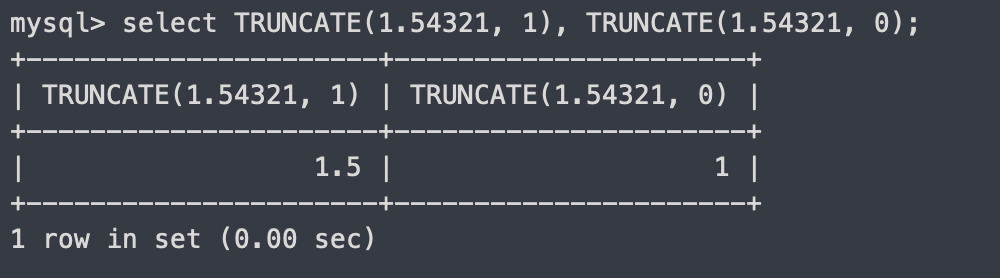
TRUNCATE
-소수점을 (두번째 인자)자리 까지 출력
-(두번째 인자)미설정 시 default는 0
select TRUNCATE(1.54321, 1), TRUNCATE(1.54321, 0);
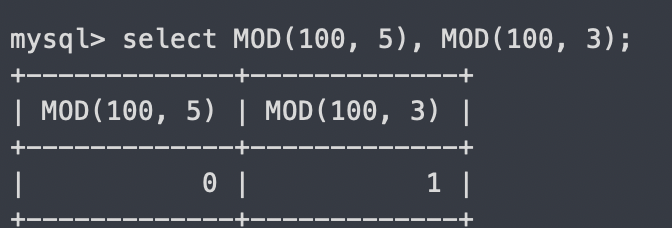
MOD
-(첫 인자)를 (두번째 인자)로 나눈 나머지 값 출력
select MOD(100, 5), MOD(100, 3);
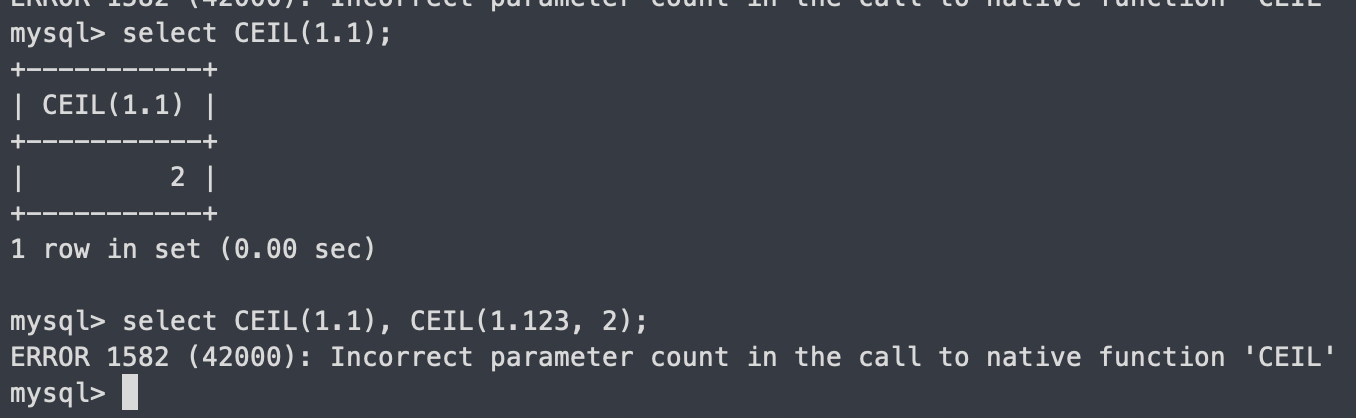
CEIL
-숫자 올림한 값 출력
-두번째 인자 줘도 된다 했는데 실제론 해보면 안됨
FLOOR
숫자 내림한 값 출력
POW
1번째 인자를 2번째 인자만큼 제곱한 값 출력
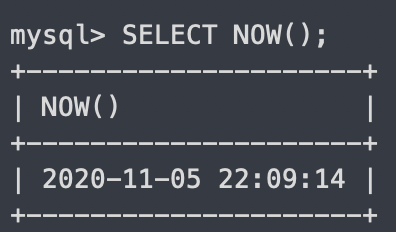
NOW
mysql 시스템의 현재 날짜와 시간 출력
SELECT NOW();
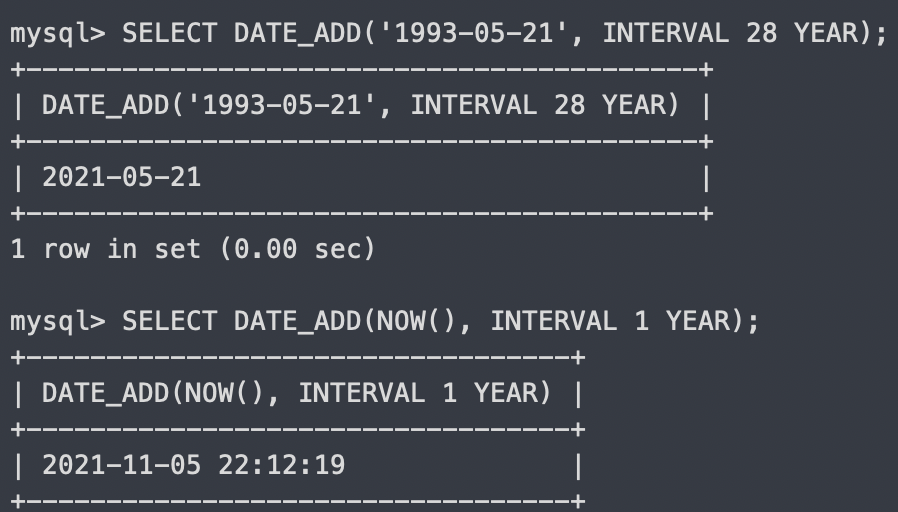
DATE_ADD
주어날 날짜에서 (두번째 인자)만큼 지난 시간을 출력
-시간 단위는 SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, YEAR이 있다.
COUNT
SUM
합계
null값은 포함 안시킴
AVG
평균
null값은 포함 안시킴
MIN, MAX
-최대값 최소값은 기본적으로 데이터 정렬이라는 내부과정을 거치기 때문에,
데이터 양이 클수록 많은 부하가 걸린다.
GROUP BY
-그룹화
HAVING
일반 쿼리 조건문엔 where를, group by에선 having을 써야한다.
SELECT ID, avg(Product_Sum) from purchase group by ID having avg(Product_Sum) > 3
ROLLUP
select ID, sum(product_price) from product group by ID with(rollup);
-product테이블의 product_price컬럼의 레코드의 합을 구하고 이를 id컬럼으로 그룹화 및 rollup(자동소계)하는 쿼리라는데 모르겠다. 엑셀에서 부부합 기능과 유사하다는데,
서브쿼리
단일 행 쿼리, 다중 행 쿼리, 다중 컬럼 쿼리, 상호 연관 커리
단일 행 쿼리는 결과값이 하나일 때, 다중 행 쿼리는 결과값이 여러개 일 때.
단일
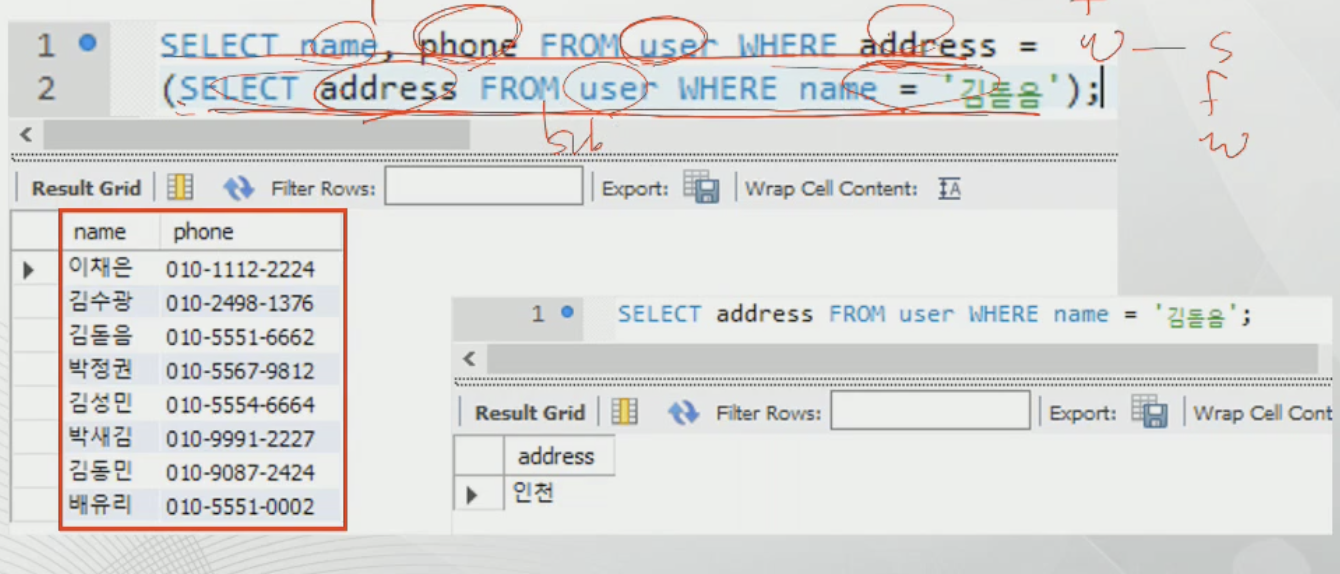
다중
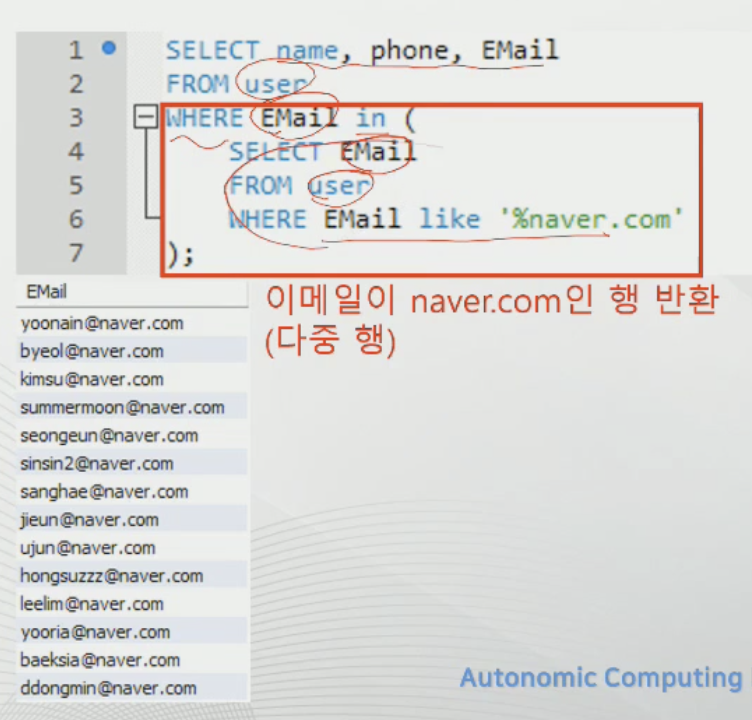
다중 행 쿼리는 컬럼이 여러개 인 것.
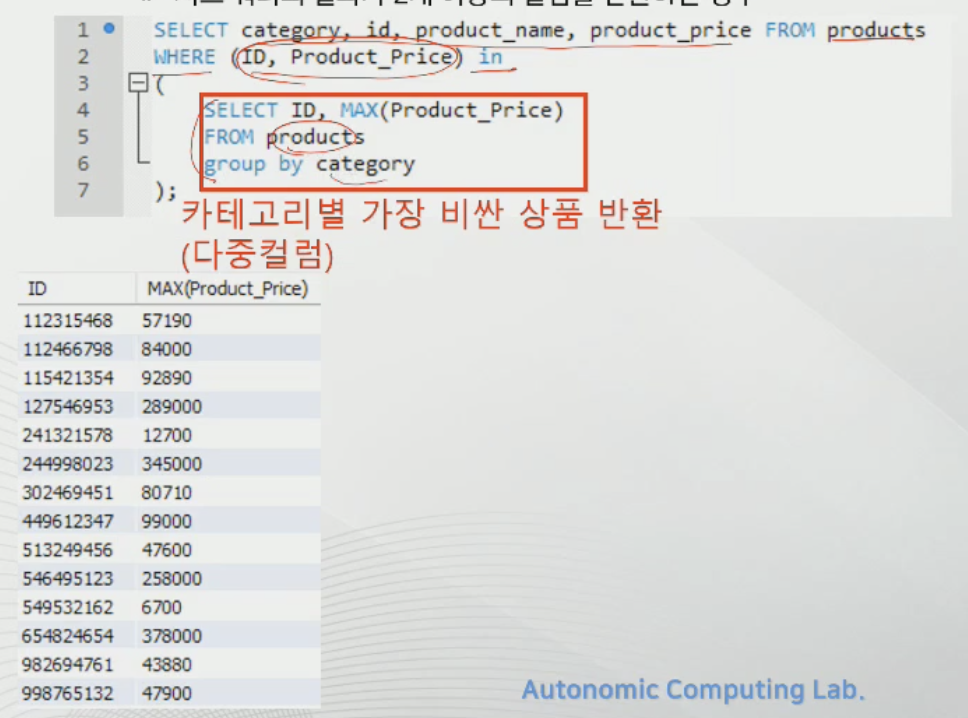
상호 연관 쿼리
메인쿼리의 값을 서브쿼리가 사용하고, 서브쿼리의 값을 받아 메인쿼리가 계산하는 구조
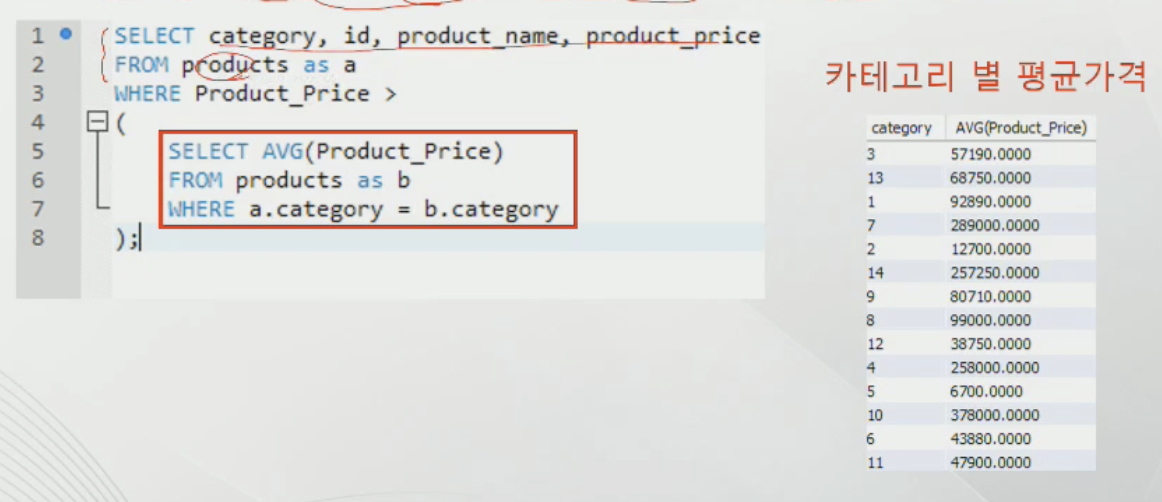
위 조건을 말로 풀어보려 했는데 꼬인다ㅇㄴㅇㄴ
UPDATE
사용법:
UPDATE table SET column = "---", column2 = "---" WHERE 조건;
원랜 김오성님 직장 위치 null이었는데, 학동역으로 update해야될 경우.
UPDATE user set location ="학동역" where name="김오성";
주의!!!
update에 where을 주지 않으면, 모든 location이 "학동역"으로 바뀐다.
DELETE
