TIL day-45(반정규화)
반정규화강의 정리
https://www.youtube.com/watch?v=SS6H2whbfwc SQL전문가 정미나 님의 강의
테이블 병합
비지니스 로직상 JOIN되는 경우가 많아 통합하는 것이 성능 측면에서 유리할 경우 고려한다.
1) 1:1 관계 테이블 병합
2) 1:M 관계 테이블 병합
3) 슈퍼 서브 타입 테이블 병합
테이블 분할
1)수직 분할: 컬럼 단위로 테이블 1:1 분리
2)수평 분할: row 단위로 테이블 분리
테이블 추가
1)중복테이블 추가: 타 서버에 있는 테이블과 동일한 구조의 테이블 추가로 원격JOIN 방지
2)통계테이블 추가: 통계값을 미리 계산해서 저장하는 테이블 추가
3)이력테이블 추가: 마스터 테이블에 존재하는 row를 트랜잭션 발생 시점에 따라 복사해두는 테이블 추가
4)부분테이블 추가: 자주 조회되는 컬럼들만 별도로 모아놓은 테이블 추가
중복컬럼 추가
-Join 프로세스를 줄이기 위해 중복 컬럼 추가
-SELECT 비용은 감소하나, UPDATE비용은 증가
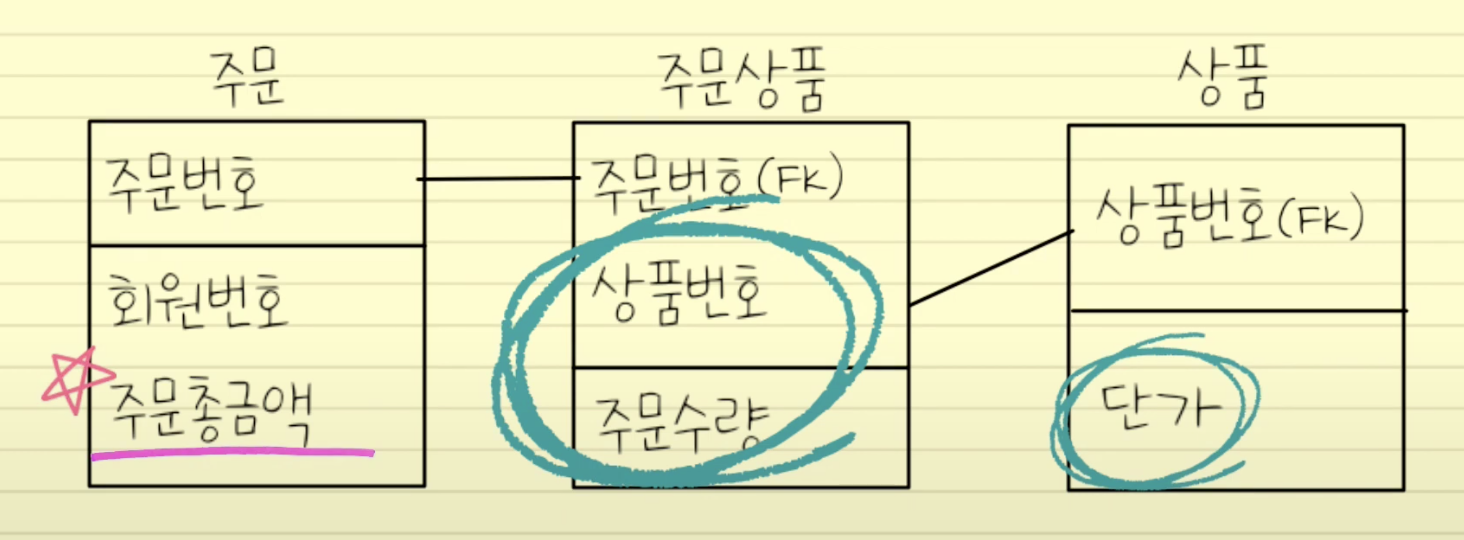
파생컬럼 추가
-계산을 통해 얻어지는 결과값을 테이블에 컬럼으로 저장
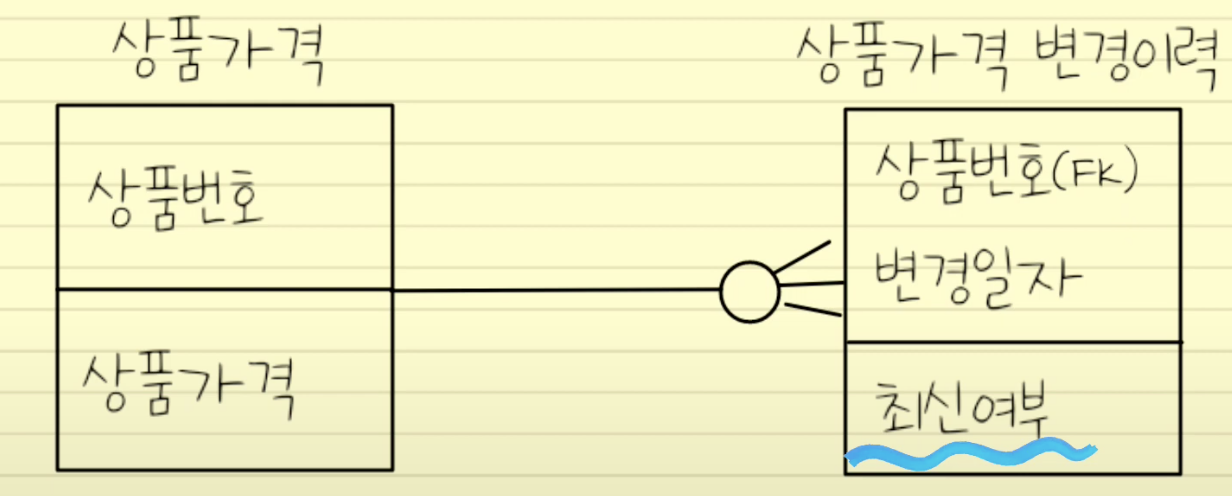
이력테이블 컬럼 추가
-이력 테이블에 기능성 컬럼 추가(최신 여부, 시작일/종료일 등)
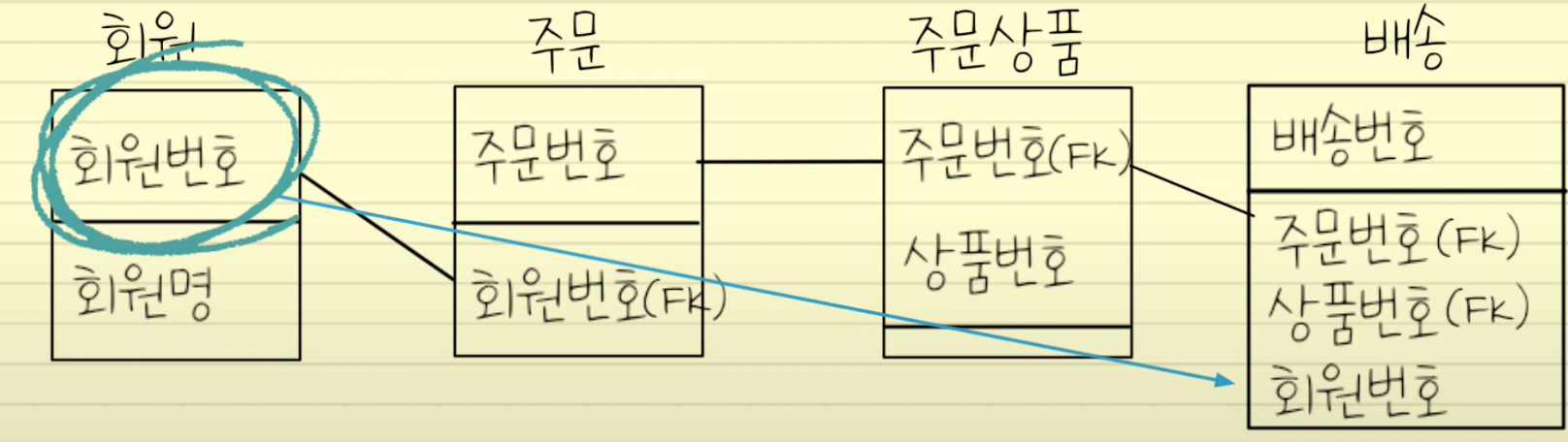
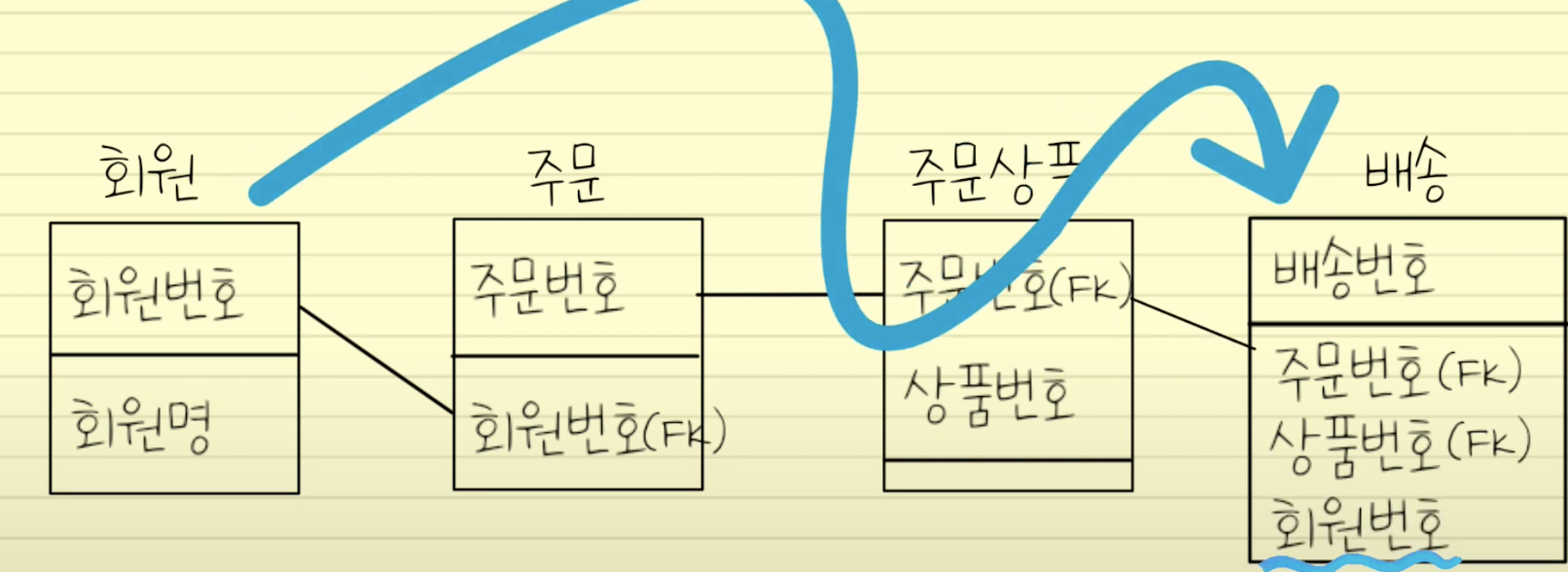
중복관계 추가
-데이터 처리를 위해 여러 경로를 거쳐야 할 경우 관계를 중복시켜 성능 개선
요약
반정규화는 성능 향상을 위해 정규화를 포기하는 것. 데이터 무결성이 보장 되지 않으므로 제한적으로 사용해야 한다.
DATABASE 인강
database란?
"a collection of related data"
서로 관련 있는 데이터들의 모임 by Elmasri and Navathe
ER(Entity-relationship)데이터 모델의 구성요소
-entity(student)
-attribute(phone_number, address)
-relationship(1:1, 1:N, M:N)
entity type
-강한 엔티티 타입
-약한 엔티티 타입: 자신의 키 애트리뷰트가 없는 엔티티 타입
일반적으로 entity type과 entity를 구분없이 쓰지만, 엄밀히 말하면 둘은 다른 것, entity가 entity type에 종속적임.
1)simple Attribute
d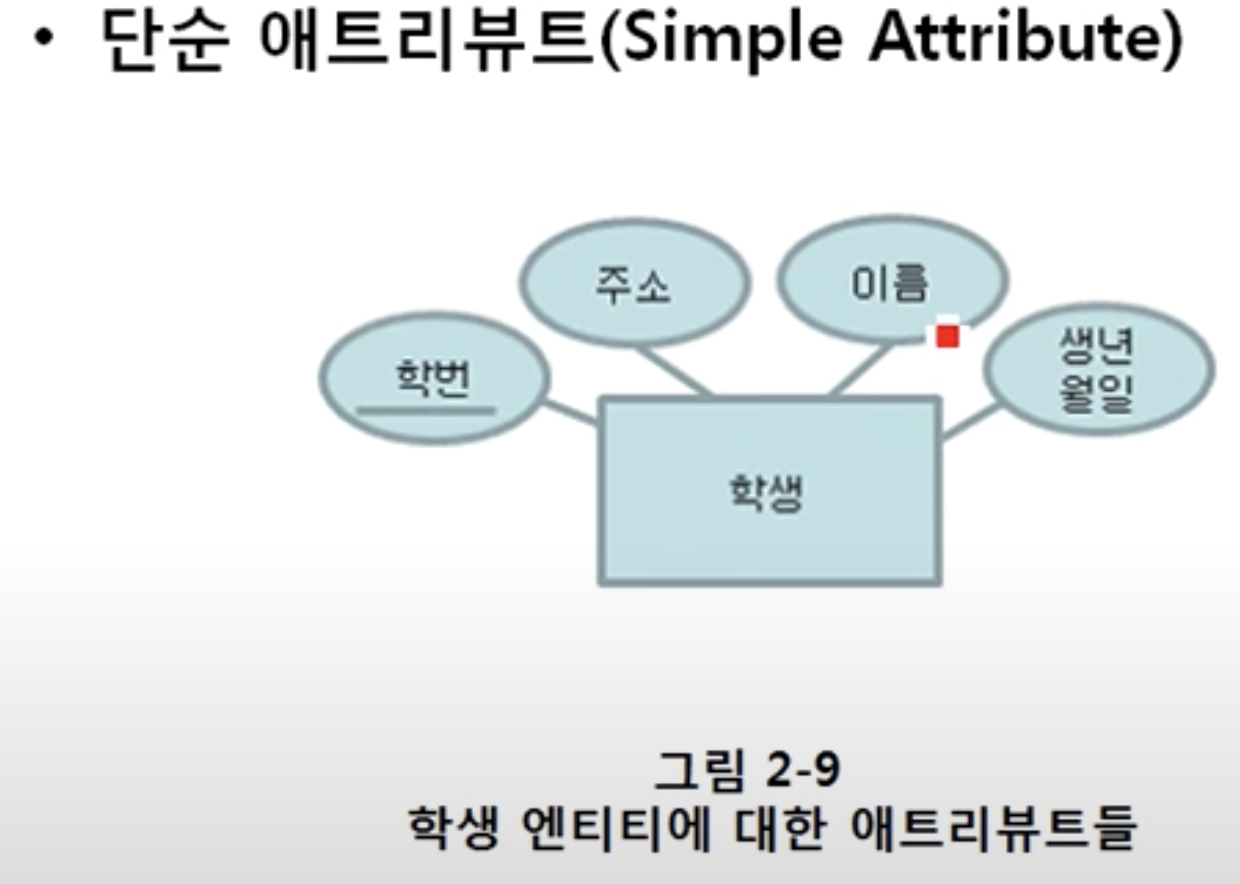
key attribute
-entity들을 식별할 수 있는 유일한 제약조건 갖는 attribute, 밑줄그음.
위에선 학번.
2)composite attribute
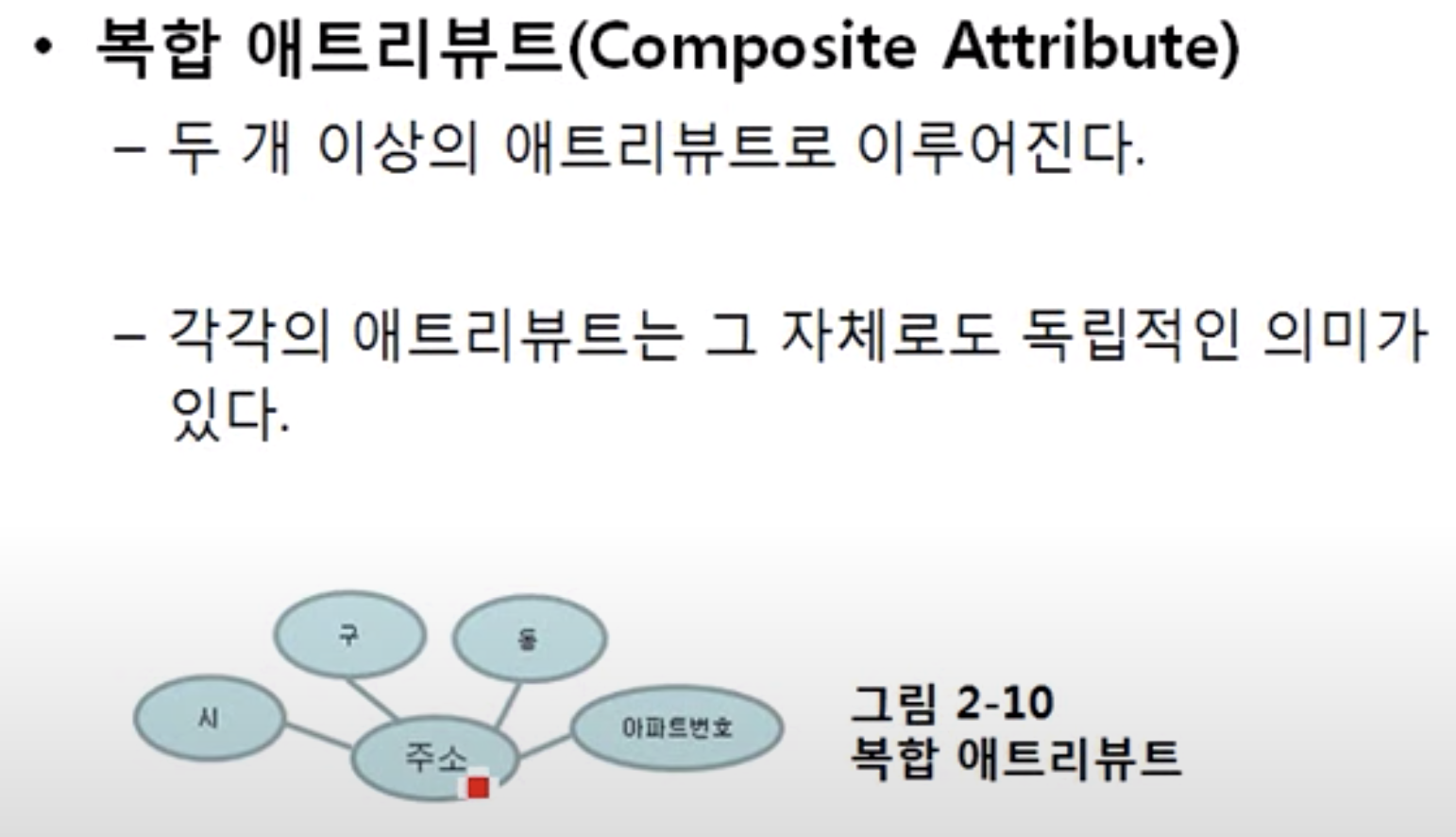
3)다치 애트리뷰트(Multivalue Attribute)
-에트리뷰트 하나에 여러 값이 들어갈 수 있는 애트리뷰트
4)Drived Attribute
-애트리뷰트에 실제 값이 저장된 것이 아니라, 저장된 값으로부터 계산해서 얻은 값을 사용하는 애트리뷰트
5)
