4. 데코레이터를 사용하는 이유는 무엇일까요? 설명 해주세요.
데코레이터 정의: 함수를 인자로 받아 꾸며진 함수를 리턴하는 기능
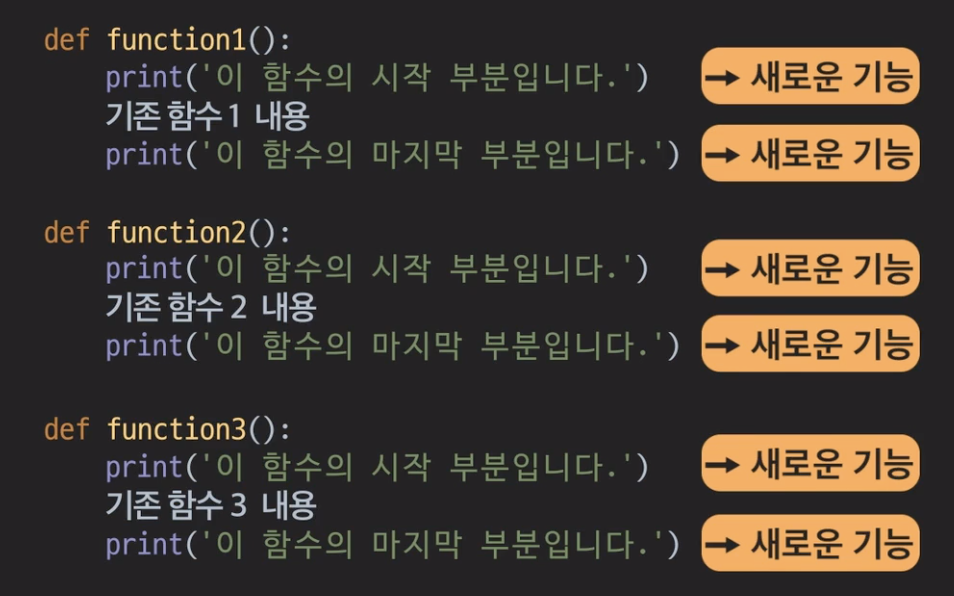
데코레이터를 사용해 중복을 줄일 수 있다.
예를들어 함수 3개가 있는데, 각 함수 시작과 끝에 특정 내용이 출력되야 한다고 하자. 데코레이터가 없다면, 각각의 함수에 중복되는 내용을 넣어야 한다. 데코레이터를 사용해 중복되는 부분을 만들면 반복작업이 줄어들어 코드의 중복이 줄고 가독성이 증가한다.
6. AWS에서 로드밸런서가 하는 일은 무엇이고 왜 사용할까요?
참고자료: https://opentutorials.org/course/608/3008
ESB(Elastic Load Balancing)
Elastic: 유연하게 로드밸런싱을 만들 수 있다.
Load: 시스템에 걸리는 부하
Balnancing: 그 부하를 여러대의 컴퓨터로 분산시켜주는 장치
ELB는 트래픽과 밀접한 연관.
사용자의 증가->부하 증가->여러대의 컴퓨터를 ELB로 부하 조절.
시나리오)
1) 적은 수의 사용자->EC2 1대로 서버 운영
2) 사용자 증가-> EC2의 성능개선(Scale Up)
3) 사용자 더 증가->한 대의 컴퓨터로 처리의 한계->여러 대의 EC2 운영(Scale Out)
트래픽 진입시 단일 진입점(ELB)이 받아냄->컴퓨터들로 분산시킴
특징
-트래픽 분산
-자동확장(스케일을 AWS측에서 자동으로 조절해줌)
-인스턴스의 상태를 자동 감지해서 오류가 있는 시스템은 배제
-사용자의 세션을 특정 인스턴스에 고정
-SSL 암호화 지원
-IPv4, IPv6 지원
-CloudWatch를 통해 모니터링
14. DNS는 무엇인가요?
인터넷에 연결된 컴퓨터 한 대 한 대를 host라 부른다.
host끼리 통신하기 위해선 주소가 필요하다.
이를 위해 사용하는 주소를 IP address라 한다.(261.142.219.111)
문제는 이 주소를 기억하는 것이 너무 어렵다는 것이다.
이를 해결하기 위해 Jon Postel, Paul Mockapetris에 의해 DNS가 개발됐다.
DNS의 핵심은 DNS Server, 이 서버엔 수많은 Ip주소의 도메인 이름이 저장되있다.
모든 운영체제엔 hosts라는 파일이 있다.
만약, hosts파일에 naver.com의 ip를(예.124.35.311.3)적어놨다면,
후에 naver.com에 접속할 때 hosts파일에서 ip주소를 읽어 거기로 접속한다.
이것이 hosts파일의 역할이다.
17. hash의 용도는 무엇일까요?
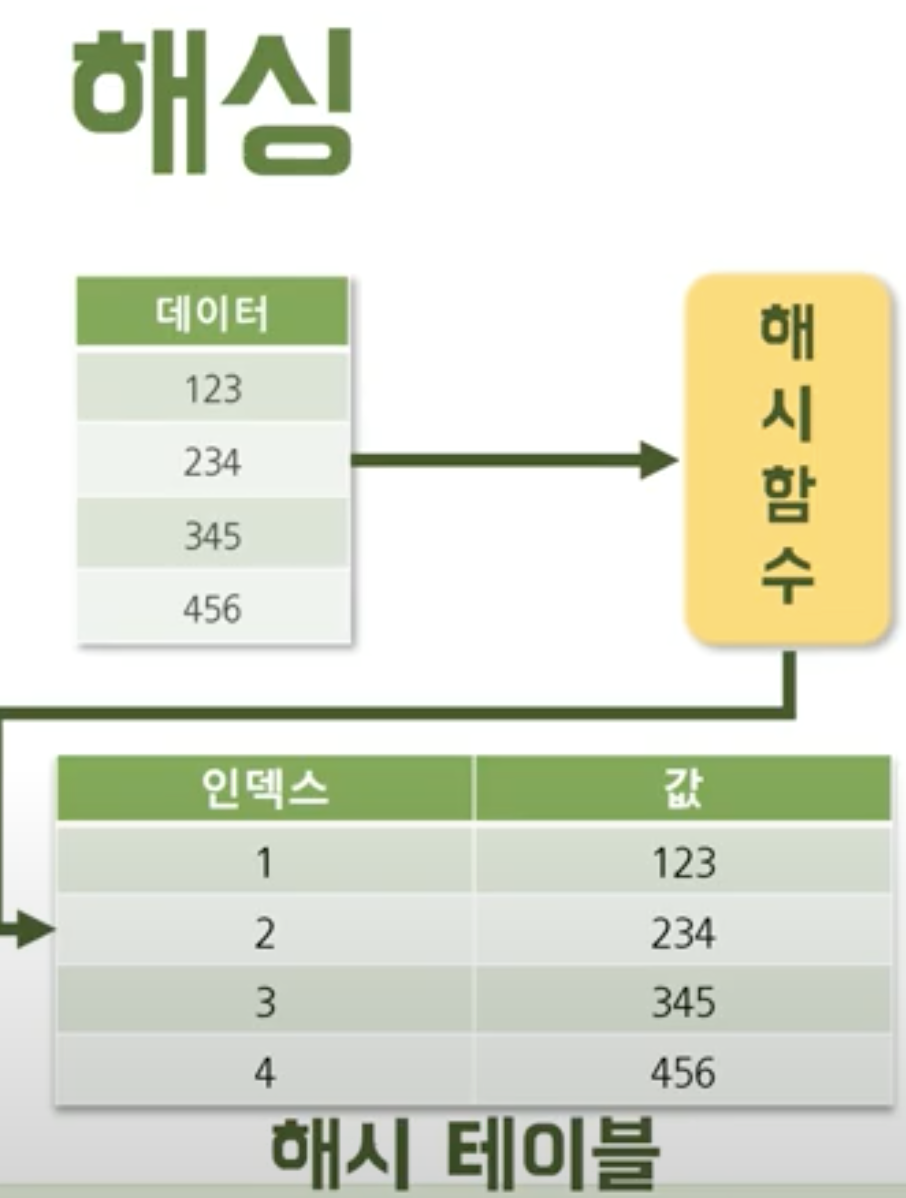
hash는 데이터를 관리/유지하는 자료구조다.
원하는 데이터를 빠르게 찾는 장점이 있다.
python의 dictionary에 해당한다.
특정 데이터가 들어오면, 해쉬함수를 통해 데이터의 key값을 생성해 데이터를 저장한다.
data search할 때 key만 찾아 거기로 가면 되니 빠르다.
중복 key가 발생할 때 문제가 생기는데, 이를 해결하려 나온 방법은 두 가지.
하나는 linked list처럼 한 row에 값을 더하는 방법(chaining)이다.
linear probing은 키값이 중복될 경우, 값이 비었는 키를 찾아 아래로 내려가서, 빈 자리에 data를 넣는 방법이다.
참고자료
https://www.youtube.com/watch?v=xls6jEZNA7Y
mit hashing 강의
hash는 cs에서 가장 중요하고 자주 쓰이는 형태 중 하나다.
python의 dictionary의 해당한다.
Dictionary: Abstract Data Type(ADT)
각 값들은 key를 가진다.
-insert(item)
-delete(item)
-search(key): return item with given key or report doesn't exist key
overwite any existing key
lecture's topic is how to search faster than log(n) time.
dictionary는 거의 모든 곳에 존재한다.
-hashing을 사용하는 db, search tree를 사용하는 db로 나뉜다.
-우리가 사용하는 변수는, 컴퓨터에게 어떤 주소를 의미하게 된다. 컴퓨터가 그 주소(key)를 찾아가 value를 사용하게 된다.
-router(라우터)또한 dictionary형태다.
-Ctrl F로 특정 문자를 찾는 것도 dictionary로 이루어진다.
Badness
1) keys may not be integers
2) gigantic memory hog
solotion
1) prehash(python calls it hash, it's not hashing, be careful)
-in theory, keys are finite & discrete (string of bits)
-in python, hash(x) is the prehash of x
2)hashing
21. TDD에 대해 설명 해주세요.
Test-driven Development(테스트 주도 개발)
간단히 말해 선 테스트 코드 작성, 후 구현.
매우 짧은 개발 사이클은 반복하는 소프트웨어 개발 프로세스 중 하나이다.
1)먼저 요구사항을 검증하는 자동화된 테스트 케이스를 작성한다.
2)그 테스트 케이스를 통과하는 최소한의 코드를 생성한다.
3)작성한 코드를 표준에 맞도록 리팩토링한다.
장점: 테스트케이스를 주로 작은 단위로 만들기에, 코드가 방대해지지 않고, 코드의 모듈화가 자연스럽게 이루어진다.(객체지향적 코드개발, 재사용성 증가)
테스트 커버리지가 높아진다 ->리팩토링, 유지보수 쉬워진다->프로젝트 퀄리티 보장.
협업이 용이해진다.
25. 캐싱을 해야하는 이유를 설명해주세요.
캐싱: 좀 더 빠른 memory영역으로 데이터를 가져와 데이터에 접근하는 방식
저속인 hard disk의 data를 좀 더 빠른 memory영역으로 가져와 memory에서 읽기, 쓰기 수행할 때, "데이터를 메모리에 캐싱한다"고 한다.
마찬가지로, memory상의 data를 더 빠른 메모리인 cpu메모리 캐시로 가져와 작업하는 것도 캐싱한다고 표현한다.
캐시는 데이터의 지역성(Locality)이라는 특성을 이용해 성능 개선을 이룬다.
지역성은 공간 지역성/시간지역성으로 나뉜다. 전자는 한 번 접근한 데이터의 인근에 저장되어 있는 데이터가 다시 접근될 가능성이 높은 특징을 의미한다.
후자는 한 번 접근된 데이터가 가까운 시간내에 다시 접근될 가능성이 높은 특징을 의미한다.
배포, Bycrpt
배포
배포 절차 설명해달라
개발->코드리뷰->CI test ->QA test -> 빌드 -> 스토어 등록 ->심사-> 출시
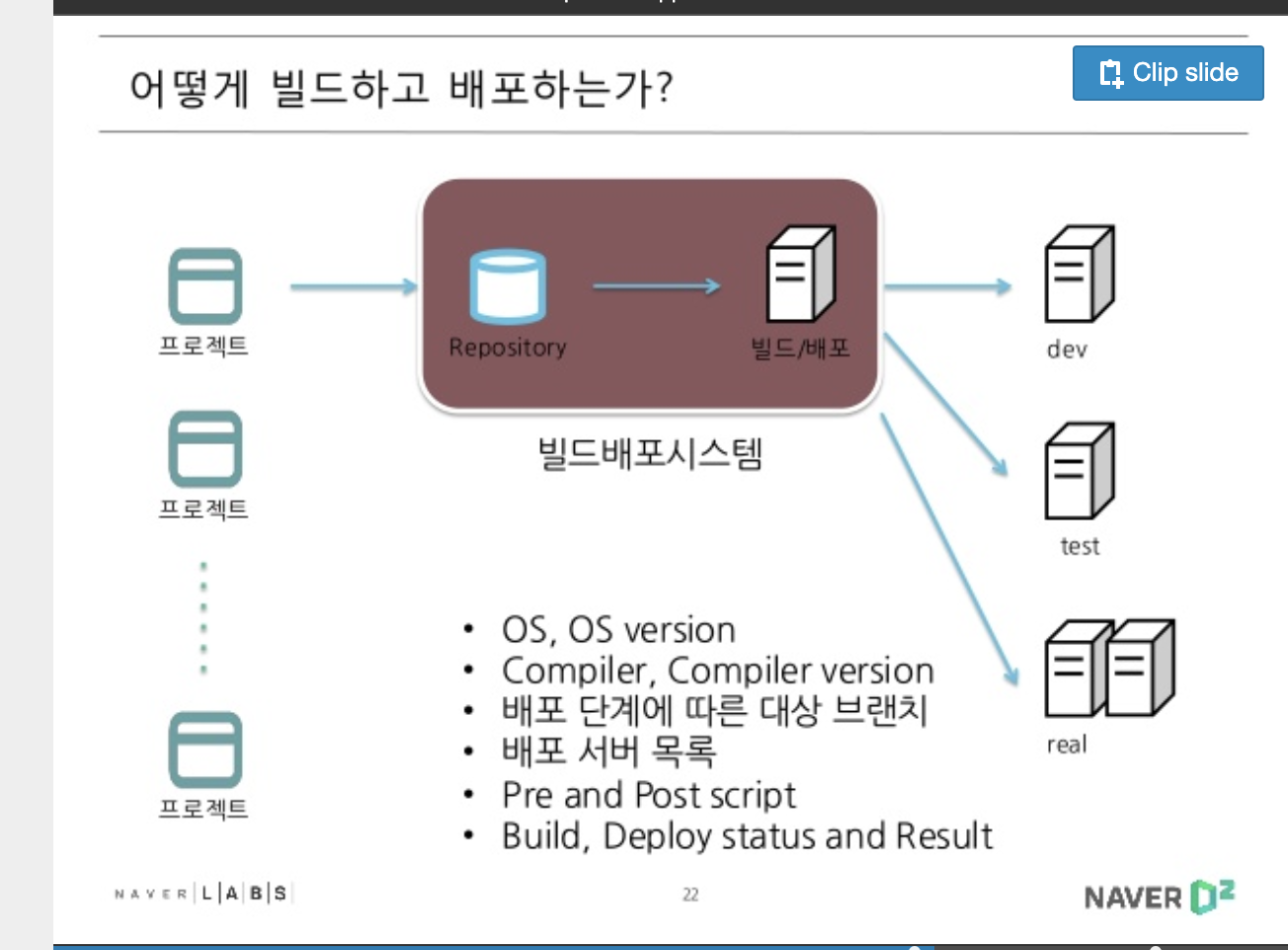
프로젝트->Repository->빌드/배포->개발/테스트/배포서버
Docker를 사용하는 이유는 ?
https://www.youtube.com/watch?v=2-w679FFMrc 공부자료
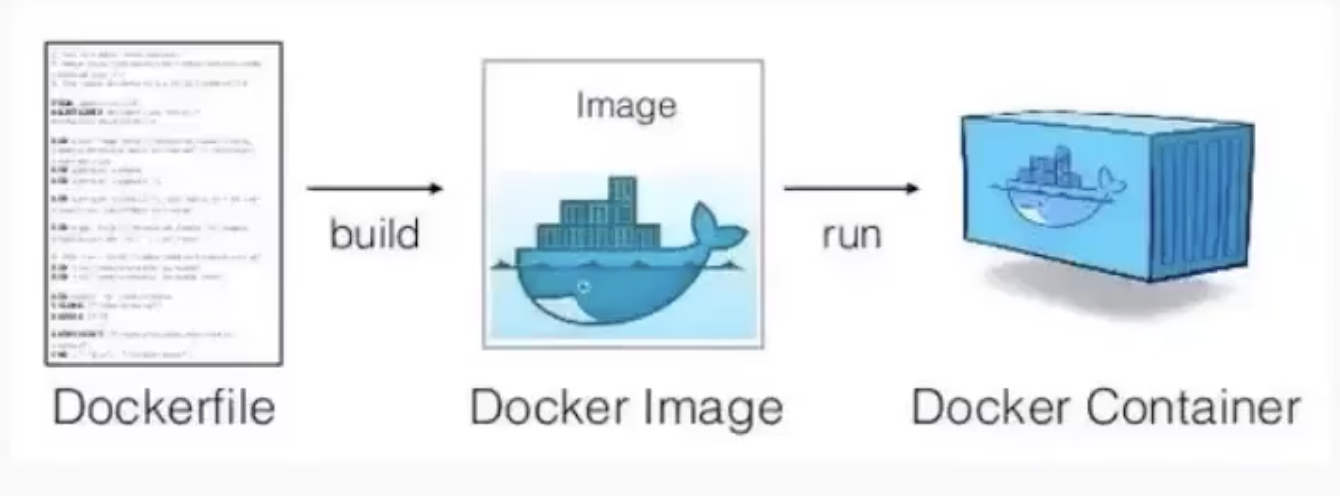
-서비스를 패키징, 배포하는데 유용한 오픈소스 프로그램
-서비스 개발 후 배포할 때 해당 프로그램이 어디에선가 손쉽게 구동되기 위함.
-보통 카페24, 가비아, aws등의 클라우드 서비스를 이용해 배포하는데 각각 서비스에 맞는 환경설정을 해줘야 하는 어려움이 있었다.
도커를 활용하면, 어느 환경에서든지 편리하게 작동가능.
-가상화를 하지 않고, 프로세스만 격리해서 빠르게 실행시키는 기술.
-운영체제 위에 운영체제를 새로 깔아 독립적 환경을 구성하는 것이 아니다.
-가상머신을 설치한 것과 거의 동일한 효과를 낸다.
-가상머신을 설치하는 것은 많은 용량을 필요로하고, 느리다는 단점이 있다.
-도커는 프로세스 격리만 할 뿐, os를 새로 깔지 않는다.
-용량을 많이 차지하지 않는다. (장점)
Docker Image 와 Container 란?
-이미지: 실행파일 (실행파일과 라이브러리의 조합)
-컨테이너: 파일을 실행시킨 상태 (이미지를 실행시킨 상태)
-컨테이너 안과 밖은 완전히 독립이다. 밖(로컬)에서 설치한 것과 컨테이너안에서 설치한 것은 서로 전혀 상관없다.
AWS에서 어떤 것들 사용했는지?
EC2(Amazon Elastic Compute Cloud)
RDS(Amazon Relational Database Service)
직접 인스턴스들을 만들었는지?
EC2에 배포는 어떻게 했는지?
도커를 통해 EC2에 이미지와 컨테이너를 올려서 배포.
s3 앞단에 다른 클라우드 서비스 붙여서 사용해봤는지? —> 아니오?
-S3(Simple Storage Service)
-Cloud 기반의 Object File System
-특징: MetaData, Key & Value
-장점: 저렴한 비용, 무제한 용량, 빠른 속도
simple storage service(s3)
-일종의 파일서버로 어떤 파일을 저장하고, 파일을 필요한 사람에게 제공하는 서버.
-어떤 서비스를 이용한 때 사진을 찍어업로드 한다치면, 업로드한 사진이 저장되고, 제공하는 역할을 하는 곳
-파일이라는 표현을 쓰지 않고 '객체'라는 표현을 쓴다.
특징
1) 많은 사용자가 접속을 해도 이를 감당하기 위해 시스템적인 작업을 하지 않아도 된다.(아마존이 해줌)
2) 저장할 수 있는 파일 수의 제한이 없다.
3) 1개파일 기준 최소1bytes ~최대 5TB 데이터 저장, 서비스 가능.
4) 파일에 인증을 붙여 무단 엑세스 방지 가능(인가되지 않은 사람의 접근 금지)
5) HTTP와 BitTorrent프로토콜 지원
BitTorrent는 p2p방식의 배포방식
보통 서버와 클라이언트는 1:N의 관계인데, 여기선 각각의 클라이언트가 다운로드를 요청한 각각의 컴퓨터가 클라이언트면서 동시에 서버 역할을 하게 되고 결과적을 훨씬 빠른 방식으로 서비스 제공 가능.
6) 데이터를 여러 시설에서 중복을 저장->데이터의 손실이 발생할 경우 자동으로 복원 가능
7)버전관리 기능을 통해 사용자에 의한 실수도 복원 가능
8) 정보의 중요도에 따라 보호 수준 차등가능, 이에 따라 비용 절감 가능(RSS)
주요개념
객체
object, AWS는 S3에 저장된 데이터 하나 하나를 객체라고 명명하는데, 하나 하나의 파일이라고 생각하면 된다.
버킷
bucket, 객체가 파일이라면 버킷은 연관된 객체들을 그룹핑한 최상위 디렉토리라고 할 수 있다. 버킷 단위로 지역(region)을 지정 할 수 있고, 또 버킷에 포함된 모든 객체에 대해서 일괄적으로 인증과 접속 제한을 걸 수 있다.
버전관리
S3에 저장된 객체들의 변화를 저장. 예를들어 A라는 객체를 사용자가 삭제하거나 변경해도 각각의 변화를 모두 기록하기 때문에 실수를 만회할 수 있다.
BitTorrent
분산된 파일 배포 시스템이라고 정의 할 수 있다. 여기서 분산이란 하나의 서버에서 파일을 배포하는 것이 아니라, 파일을 가지고 있는 컴퓨터들로부터 조금씩 파일을 다운받은 후에 이것을 붙여서 완전한 파일을 만드는 방식이다. 대용량의 파일을 배포할 때 BitTorrent를 사용하면 비용을 크게 절감 할 수 있다. BitTorrent에 대한 자세한 설명은 생활표현의 BitTorrent 수업을 참고한다.
RSS
Reduced Redundancy Storage의 약자로 일반 S3 객체에 비해서 데이터가 손실될 확률이 높은 형태의 저장 방식. 대신에 가력이 저렴하기 때문에 복원이 가능한 데이터, 이를테면 섬네일 이미지와 같은 것을 저장하는데 적합하다. 그럼에도 불구하고 물리적인 하드 디스크 대비 400배 가량 안전하다는 것이 아마존의 주장
Glacier
영어로는 빙하라는 뜻으로 매우 저렴한 가격으로 데이터를 저장 할 수 있는 아마존의 스토리지 서비스
Bcrypt
Bcrypt에 대해 설명 해주세요.
bcrypt는 단방향 해시함수다.
방향개념에는 단방향과 양뱡향이 있다.
단방향은 복호화가 불가능하고, 양뱡향은 복호화가 가능하다.
해시 알고리즘을 사용해야 하고 요즘은 흔히 SHA-256알고리즘을 적용한다.
원문을 해시하여 저장하고 복호화가 불가능하기 때문에 데이터를 봐도 원본 값을 알 수 없어 안전하다. 하지만 완전히 안전한 것은 아니다.
해싱된 값(다이제스트라 부른다)을 대규모로 확보한 뒤 특정 해싱값을 반복대조하면 원본을 찾아낼 수 있다. 이렇게 대규모로 확보한 대이터를 Rainbow Table이라하고, 이를 활용한 공격이 Rainbow Attack이다.
해시함수 자체의 원래 목적은 암호화가 아니고 빠른 data search이기에, 공격자가 빠르게 해킹할 수도 있다. (MD5를 사용하면, 1초에 56억개의 다이제스트를 대입할 수 있다.)
이를 보안하기 위해 salting개념이 도입되었다. 음식에 소금 치듯, 원본 데이터에 추가 데이터를 더해 함께 해시하는 개념이다. 이를 통해 rainbow attack공격으로부터 어느정도 안전해질 수도 있다.
하지만 이또한 완벽하지 않기에 key stretching을 이용한다.
원본데이터 +salt로 해시한 후, 다시 해시하는 과정을 n번 반복한다.
왜 Bcrypt를 사용 하였는지?
한국 인터넷진흥원(KISA)에서 비밀번호는 해시함수를 적용할 것을 적시하고 있다.
또 2013년 이후 SHA1는 권고되지 않고, SHA2(SHA-224)이상 사용을 권고한다.(SHA-224/256/384/512 등)
우선 비밀번호기에 단방향 암호화를 적용했다.
PBKDF2, bcrypt, scrypt를 고려했었는데, Bcrypt는 salt와 key stretching으로 공격을 방어할 수 있고, C,C++,C#,go,java,js,PHP,Python,Ruby등 다양한 언어에서 지원된다는 장점과 간단하게 구현될 수 있다는 장점 떄문에 골랐다.
Bcrypt 단점에 대해 설명 해주세요.
단점은 위해서 말한대로 rainbow attack으로부터 완전히 안전하지는 않다는 것.
충분히 긴 시간이 주어진다면 보안이 뚤릴 수 있다(6개월마다 비밀번호 바꾸기 권장하는 이유)
Bcrypt 말고 다른 암호화 라이브러리 아는게 있는지?
1)PBKDF2
가장 많이 사용되는 key derivation function은 PBKDF2(Password-Based Key Derivation Function)이다. 해시 함수의 컨테이너인 PBKDF2는 솔트를 적용한 후 해시 함수의 반복 횟수를 임의로 선택할 수 있다. PBKDF2는 아주 가볍고 구현하기 쉬우며, SHA와 같이 검증된 해시 함수만을 사용한다.
PBKDF2의 기본 파라미터는 다음과 같은 5개 파라미터다.
DIGEST = PBKDF2(PRF, Password, Salt, c, DLen)
PRF: 난수(예: HMAC)
Password: 패스워드
Salt: 암호학 솔트
c: 원하는 iteration 반복 수
DLen: 원하는 다이제스트 길이
PBKDF2는 NIST(National Institute of Standards and Technology, 미국표준기술연구소)에 의해서 승인된 알고리즘이고, 미국 정부 시스템에서도 사용자 패스워드의 암호화된 다이제스트를 생성할 때 사용한다.
2)scrypt
scrypt는 PBKDF2와 유사한 adaptive key derivation function이며 Colin Percival이 2012년 9월 17일 설계했다. scrypt는 다이제스트를 생성할 때 메모리 오버헤드를 갖도록 설계되어, 억지 기법 공격(brute-force attack)을 시도할 때 병렬화 처리가 매우 어렵다. 따라서 PBKDF2보다 안전하다고 평가되며 미래에 bcrypt에 비해 더 경쟁력이 있다고 여겨진다. scrypt는 보안에 아주 민감한 사용자들을 위한 백업 솔루션을 제공하는 Tarsnap에서도 사용하고 있다. 또한 scrypt는 여러 프로그래밍 언어의 라이브러리로 제공받을 수 있다.
scrypt의 파라미터는 다음과 같은 6개 파라미터다.
DIGEST = scrypt(Password, Salt, N, r, p, DLen)
Password: 패스워드
Salt: 암호학 솔트
N: CPU 비용
r: 메모리 비용
p: 병렬화(parallelization)
DLen: 원하는 다이제스트 길이
3)AES
양방향암호화.
2020.08.23 면접준비
Argon 2
2015년 Password Hashing Competition에서 우승한 암화화 세계의 떠오르는 강자
장고의 디폴트 암호화 알고리즘은 아니지만, 장고 docs에서도 argon2사용을 추천함
Argon2 is not the default for Django because it requires a third-party library. The Password Hashing Competition panel, however, recommends immediate use of Argon2 rather than the other algorithms supported by Django
파이썬에서 사용하는 간단한 예시

출처: https://velog.io/@rosewwross/Argon2-%EC%95%94%ED%98%B8%ED%99%94-tool
읽어볼 만한 자료: https://argon2-cffi.readthedocs.io/en/stable/argon2.html
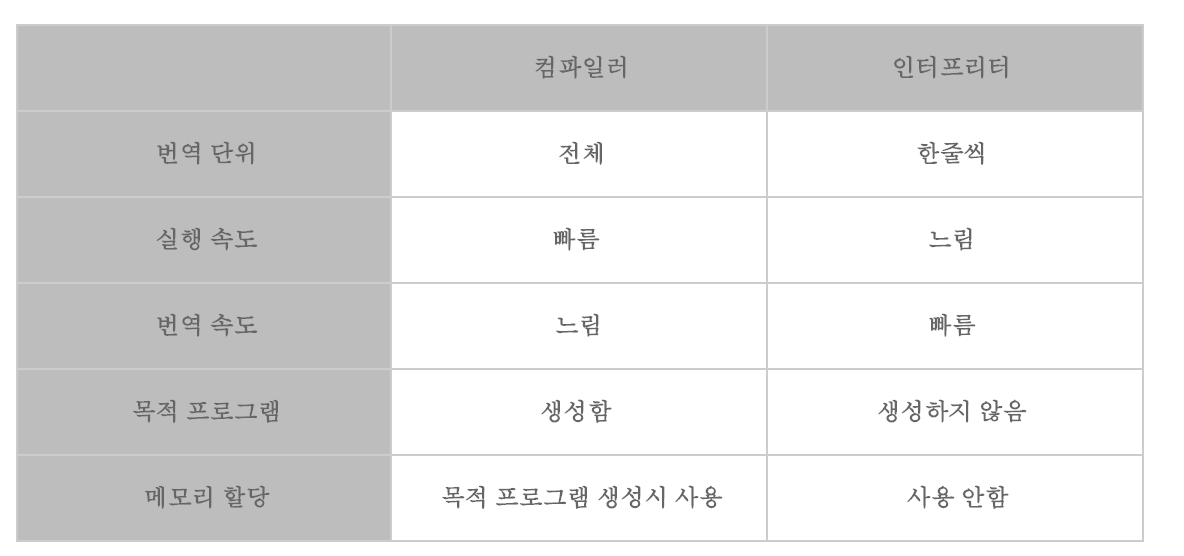
Compiler vs Interpreter 비교 정의
기계는 0과1로 이루어진 이진코드만 이해 가능 ->기계어, 저급언어
코딩할 땐 0과1이 아니라 명령어로 이루어진, 사람이 알 수 있는 언어->고급언어
고급 언어를 저급 언어(기계어)로 바꿔주는 방식에 따라 compiler언어, interpreter언어로 구분됨
interpreter
동시통역, 한 줄 한 줄 해석해서 바로바로 컴퓨터에 전달
compiler보다 느리지만 실시간 debuging가능한 장점.
ex) python, JS, PHP
- 컴파일러는 소스코드 전체를 한 번 훑고 컴퓨터 프로세서가 실행 할 수 있도록 바로 기계어로 변환한다. 인터프리터는 고레벨 언어를 중간 코드(intermediate code)로 변환하고 이를 각 행마다 실행한다. 이 중간 코드는 다른 프로그램에 의해 실행된다.
- 일반적으로 컴파일러가 각 행마다 실행하는 특성을 가진 인터프리터보다는 실행시간이 빠르다.
- 컴파일러는 전체 소스코드를 변환 한 뒤 에러를 보고하지만 인터프리터는 각 행 마다 실행하는 도중 에러가 보고되면 이후 작성된 코드를 살펴보지 않는다. 이는 보안적인 관점에서 도움이 된다.
compiler
고급 언어를 잘 해석해서 컴퓨터에게 전달하는 방식
끝까지 듣고 정리한 다음에 한 번에 컴퓨터에게 전달
인터프리터 보다 빠르다.
ex) c언어
프로그래밍 언어를 Runtime 이전에 기계어로 해석하는 작업 방식이다.
이때 원래의 소스를 원시 코드, 바뀐 코드를 목적 코드(Object Code) 라 한다.

자바는 interpreter, compiler 둘 다 사용
추상화란?
객체지향 프로그래밍의 4가지 기둥:
1)추상화(Abstraction)
2)캡슐화(Encapsulation)
3)상속(Inheritance)
4)다형성(Polymorphism)
커피머신의 복잡한 원리와 구조를 알아야만 커피를 마실 수 있다면 어떨까?(엄청 불편하겠지요)
그런것을 몰라도 버튼만 누르면 커피를 마실 수 있다.
이처럼 꼭 알아야 할 부분만 드러내는 것을 추상화라 한다.
프로그래밍에서 추상화란, 특정 코드를 사용할 때 필수적인 정보를 제외한 세부사항을 가리는 것
추상화 잘하는 법
1)추상화를 잘 하려면 변수, 클래스, 메서드의 이름을 잘 지어야 한다.
이름만 보고 해당 변수, 클래스, 메서드의 기능을 알도록.
2)문서화(docstring)
"""
"""
추상화 안좋은 예시(변수명 막 지었음)
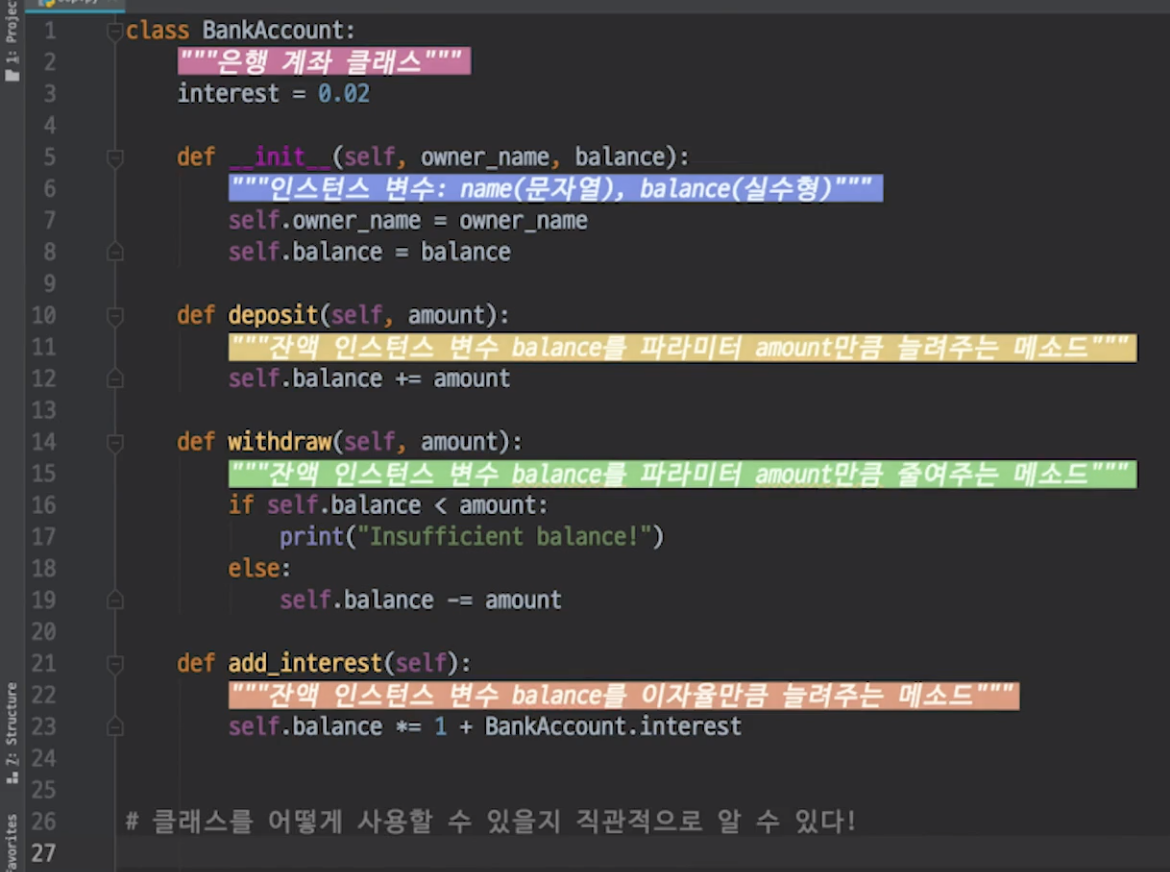
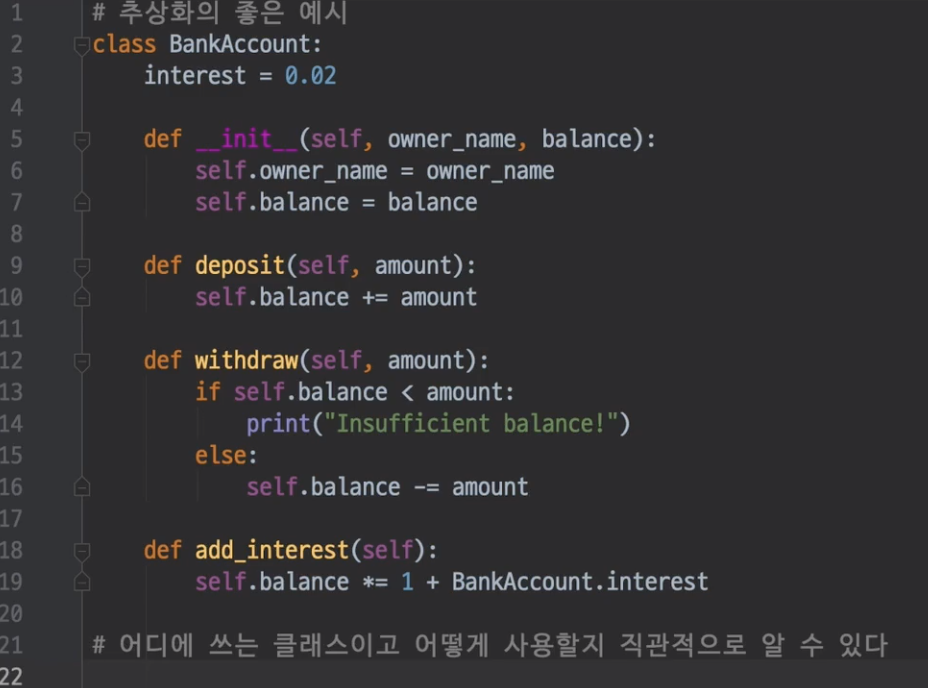
추상화 좋은 예시(변수명 잘 지었음)
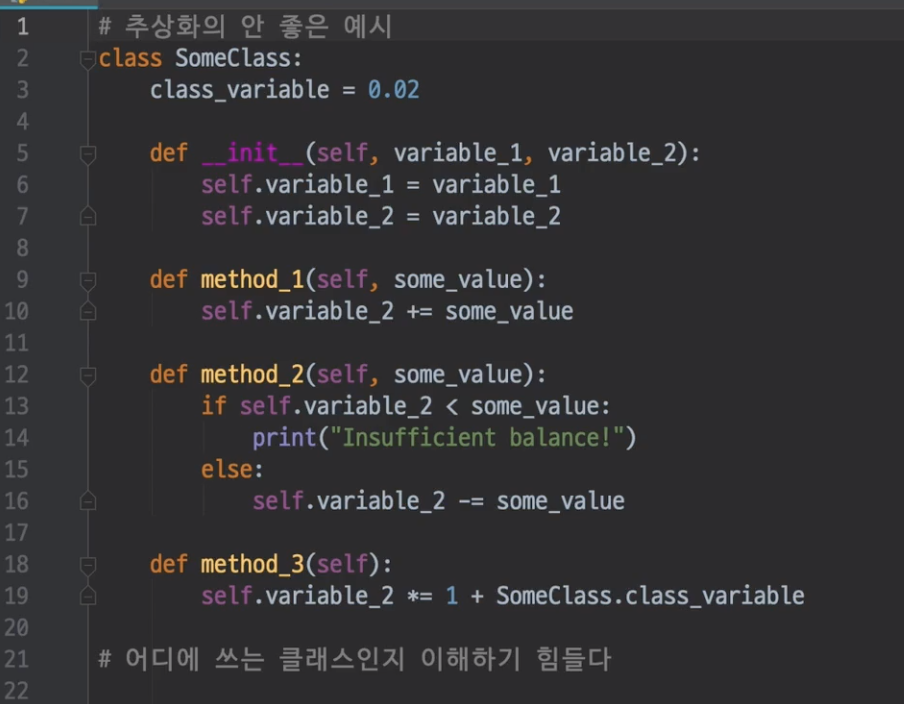
추상화 좋은 예시(변수명, docstring 잘 지었음)
질문1. 변수, 함수, 클래스 모두 추상화의 예시들이다.
1. 맞다
2. 아니다
질문 2. 다음 중 추상화에 대한 설명으로 옳은 것을 모두 고르시오.
1. 변수의 값이나, 메소드 내부의 모든 내용을 샅샅이 알지 못해도 그것들을 사용할 수 있다.
2. 클래스 내부의 속성을 외부로부터 숨길 수 있다.
3. 클래스에 docstring을 남기는 것은 추상화된 클래스의 내용을 이해하는 데 도움을 준다.
4. 어떤 존재를 프로그램에서 쓰일 객체로 표현하려면 이 추상화 과정이 필요하다.
출처: codeit 객체지향 강의(정말 좋아요)
