-책에서 특정 부분을 찾기 위해 인덱스 보듯이, 정보 빠르게 조회하기 위해 db인덱스 존재
-정렬된 데이터의 키 값과 해당 키의 주소 정보를 이용 -> 키-주소 값으로 표현 가능
-단일 단계 인덱스, 다단계 인덱스, B-tree 인덱스 등 다양한 방법이 존재한다.
-B-tree 인덱스가 가장 많이 사용된다.
인덱스 중요성
-잘못 설계된 인덱스는 오히려 성능 저하 유발
인덱스 설계 조건
-테이블 크기가 작은 경우 인덱스 사용 안하는 것이 더 효율적
-찾고자 하는 데이터가 적은 컬럼에 인덱스 사용(중복값 많으면 비효율적)
-검색 조건으로 자주 사용되는 컬럼에 인덱스 사용
단일 인덱스
-일반적인 인덱스는 데이터 파일보다 크기가 작다.
-따라서 데이터 파일을 탐색하는 것보다 인덱스를 탐색하는 것이 효율적이다.
-단일 인덱스에는 기본 인덱스, 클러스터링 인덱스, 보조 인덱스 등이 있다.
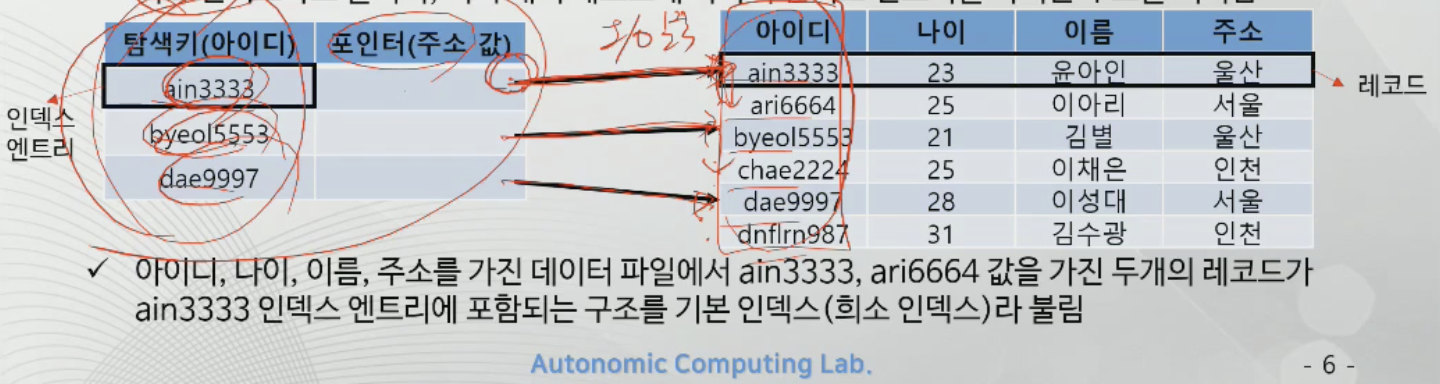
기본 인덱스(Primary Index)
-탐색 키가 데이터 파일의 PK인 index
-하나의 필드는 기본키, 다른 하나는 데이터 위치에 대한 주소 값을 가짐
-희소 인덱스라 불리며, 여러 개의 레코드에 하나의 인덱스 엔트리를 가지는 구조를 의미한다.
-희소 인덱스 vs 밀집 인덱스(뒤에 더 나옴)
-밀집인덱스는 포인터 값을 행마다 모두 지정.
희소 인덱스는 포인트를 블록 단위로 지정.(디스크 i/o단위 블록. 무슨 소리지?)
클러스터링 인덱스(Clustering index)
-논리적으로 관련된 데이터를 물리적으로도 디스크에 인접 시켜 저장하는 index
-키가 아닌 특정 필드 값을 정렬해서 그 값을 탐색키로 사용
-키가 아닌 필드를 탐색 키로 이용하기 때문에 탐색키의 값은 중복될 수 있음
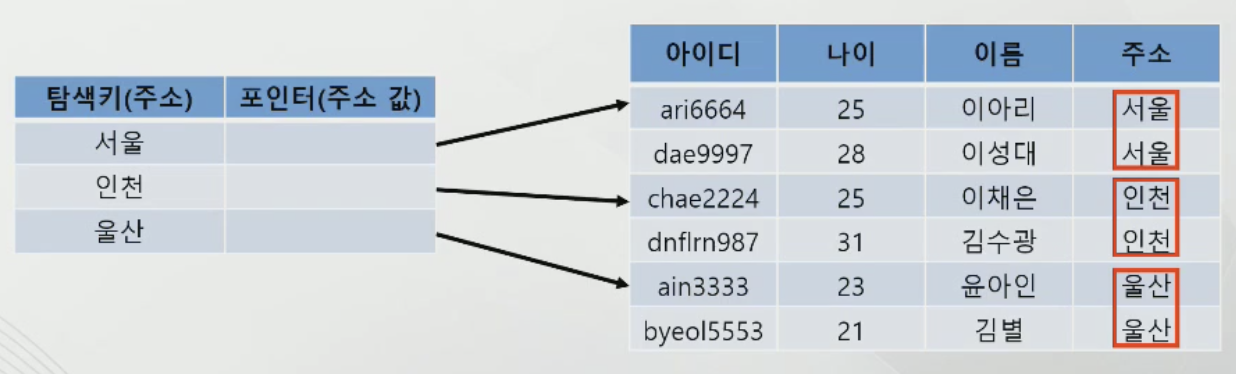
-위 예제는 주소 필드를 탐색키로 사용하여 테이블이 주소에 따라 정렬됨
-장점: 검색이 빠르다.
단점: insert, delete가 느림
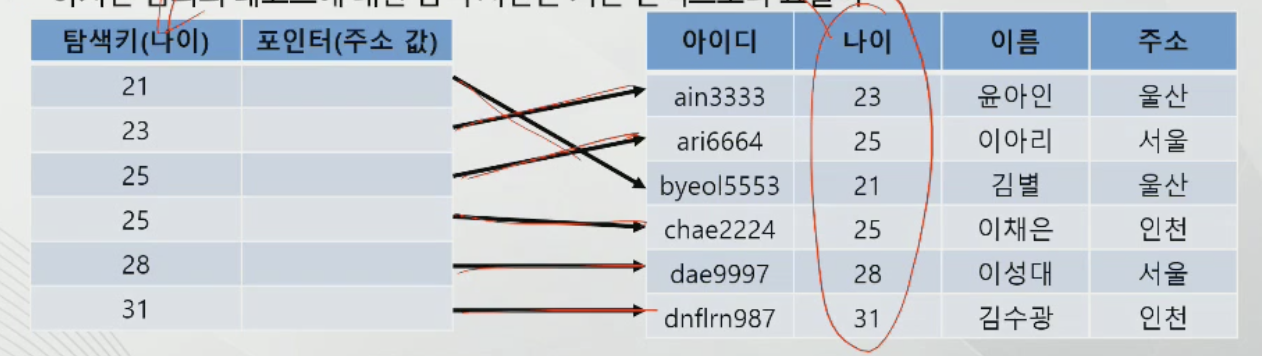
보조 인덱스(Secondary Index)
Non-Clustering index와 같은 의미, 밀집 인덱스라고 불림.
-정렬되지 않은 데이터의 파일을 탐색키의 값으로 가지지만, 인덱스에서 탐색키의 값은 정렬 되어 있음
-보조 인덱스는 기존 인덱스와 비교 시 순차 접근에 대해 비효율적
-같은 파일에 대해 여러 개의 보조 인덱스가 존재하기 때문에 엔트리들의 개수가 많아 기본 인덱스에 비해 더 많은 저장 공간과 검색 시간이 필요함
-하지만 임의의 레코드에 대한 탐색 시간은 기본 인덱스보다 효율적
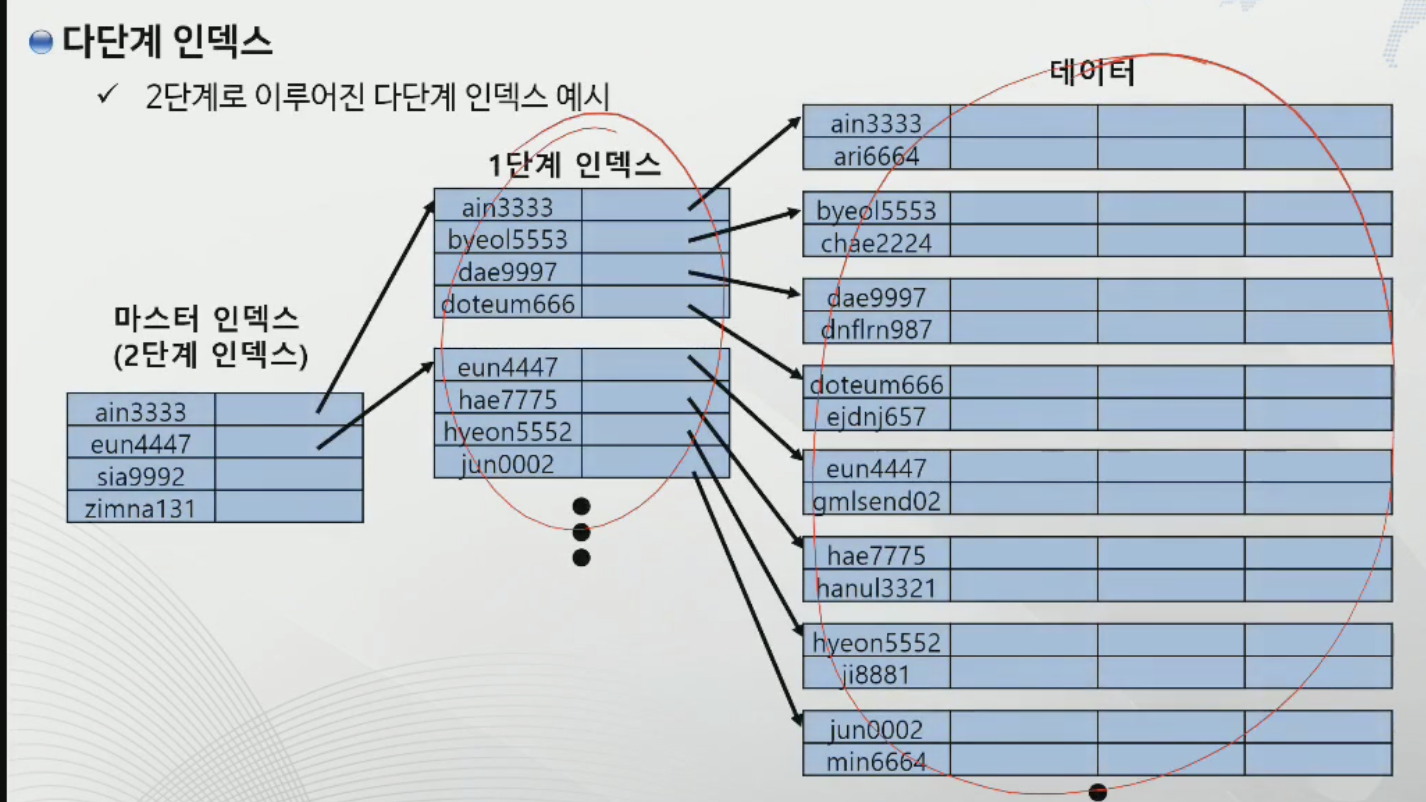
다단계 인덱스
-인덱스를 하나의 파일로 간주하고 이에 대해 다시 인덱스를 정의함.
-인덱스가 방대해지면 인덱스 자체를 검색하는 시간이 오래 걸리는데 이를 보완하고자 사용.
-삽입, 삭제가 매우 복잡.
-원래 인덱스 파일 = 첫 번째 단계 인덱스
-첫 번째 단계에 대한 인덱스 = 두 번째 인덱스
-가장 최 상위 index를 master index라 부름.
B-tree 인덱스(Balance Tree Index)
-RDB에서 사용하는 가장 일반적인 인덱스
-트리를 항상 균형 잡힌 형태로 유지해야 함.
-삭제 시 디스크 공간이 비어 발생하는 메모리 낭비를 감수해야 함.
[참고]
B+tree는 b-tree를 개선한 것으로 마지막 노드들을 linked list로 연결한다.
최하단에 위치한 값 4개를 찾고 싶을 때, b-tree는 탑타운으로 4번을 실행해야 하는 반면,
B+트리는 그렇지 않다.
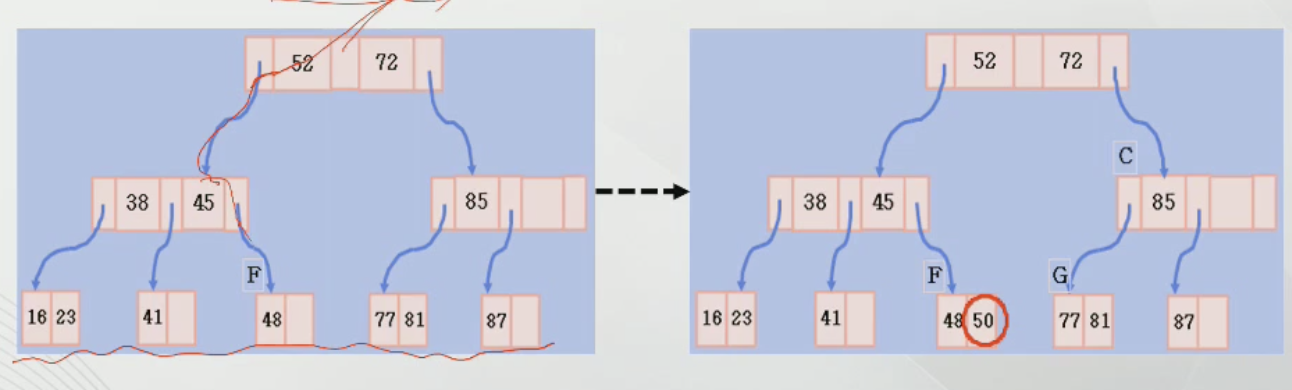
B-tree index 삽입_1
-항상 데이터 구조의 균형을 유지해야 하기 때문에 삽입/삭제가 어렵다.
-새로운 키 값은 항상 리프에 삽입되는데, 노드의 여유가 있는 경우에는 키 값을 적당한 위치에 삽입
-아래 그림에서 50을 추가할 떄, F노드의 48 다음에 삽입 가능
B-tree index 삽입_2
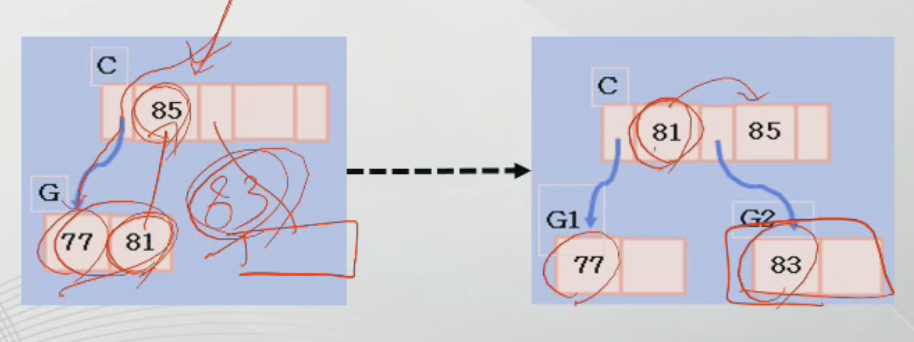
-삽입 시 여유가 없는 경우, 노드를 두개의 노드로 나눈다.
-해당 노드의 키 값과 새로운 키 값 중에서 중간 키 값을 부모 노드로 올리고, 나머지 키 값은 절반으로 나누어 두개의 노드를 만든다.
-아래 그림에서 83을 추가하려면 G노드에 삽입 되어야 하지만, 이미 꽉 차있기 때문에 노드를 두개(G1, G2)로 나눈다.
-나눌 때 중간 값(81)은 부모 노드로 올라가서 삽입되고, 부모 노드에서는 나누어진 노드들을 가리키는 포인터가 추가된다.
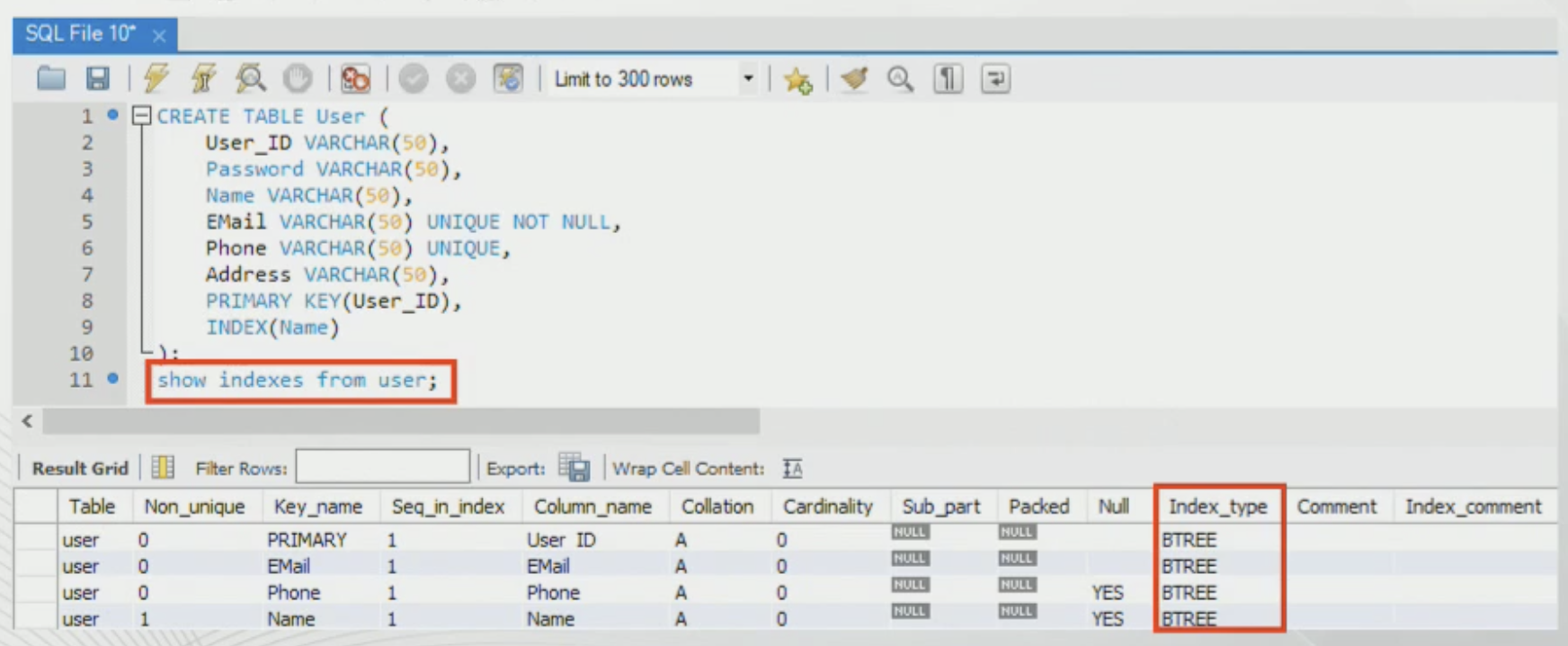
SQL index 실습
인덱스의 생성
-mysql에서는 기본키나, UNIQUE속성을 가진 필드에 자동으로 B-tree인덱스를 생성함
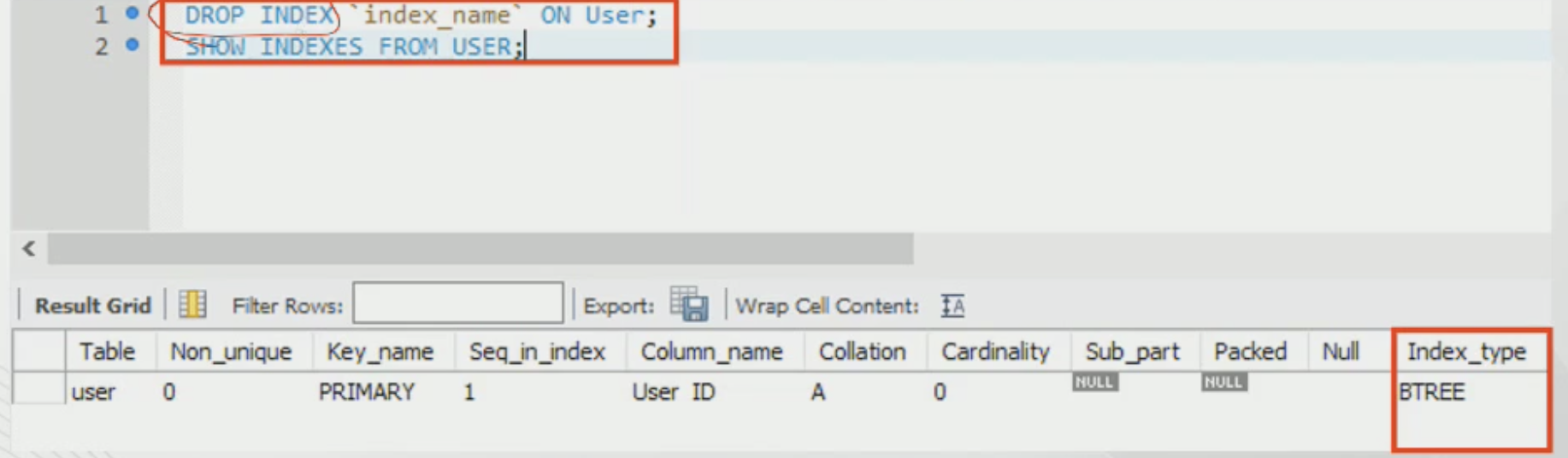
-SHOW INDEXES FROM table_name;
-위 명령어로 테이블에 생성된 인덱스들 확인 가능

(email이 unique=True임)
인덱스 생성 방법
- 테이블 생성시 설정하는 방법
- 테이블 생성 후에 테이블 설정을 수정하는 방법
- 테이블 생성 후에 인덱스를 따로 생성하는 방법
1. 테이블 생성시 설정하는 방법
-PK, UNIQUE속성 가진 필드 인덱스 자동생성.
-INDEX를 통해 직접 추가도 가능
2. 테이블 생성 후에 테이블 설정을 수정하는 방법
-ALTER TABLE table_name ADD INDEX(field_name);
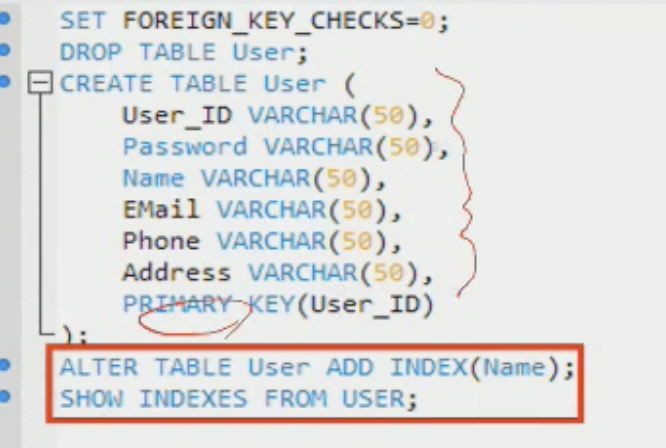
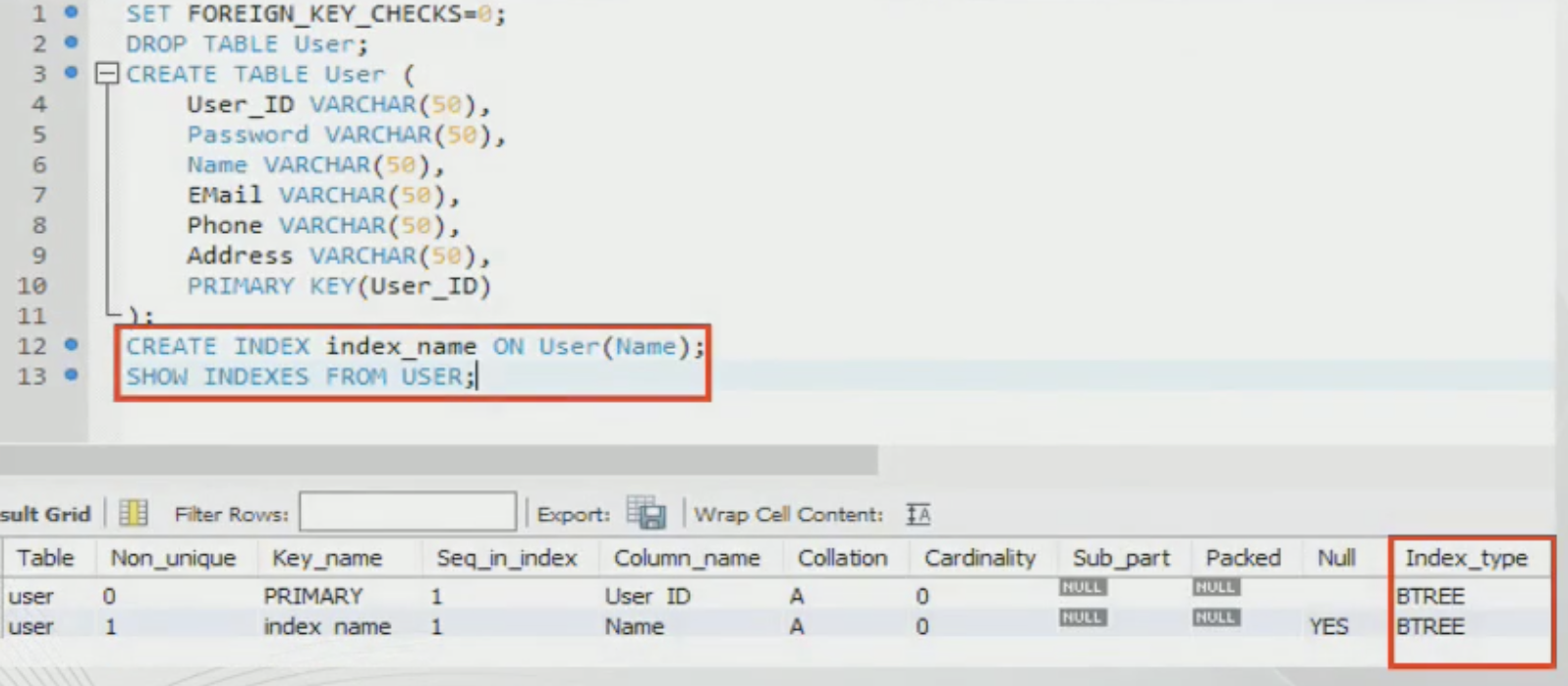
3. 테이블 생성 후에 인덱스를 따로 생성하는 방법
-CREATE INDEX index_name ON table_name(field_name);
index 제거
-DROP INDEX index_name ON table_name;