
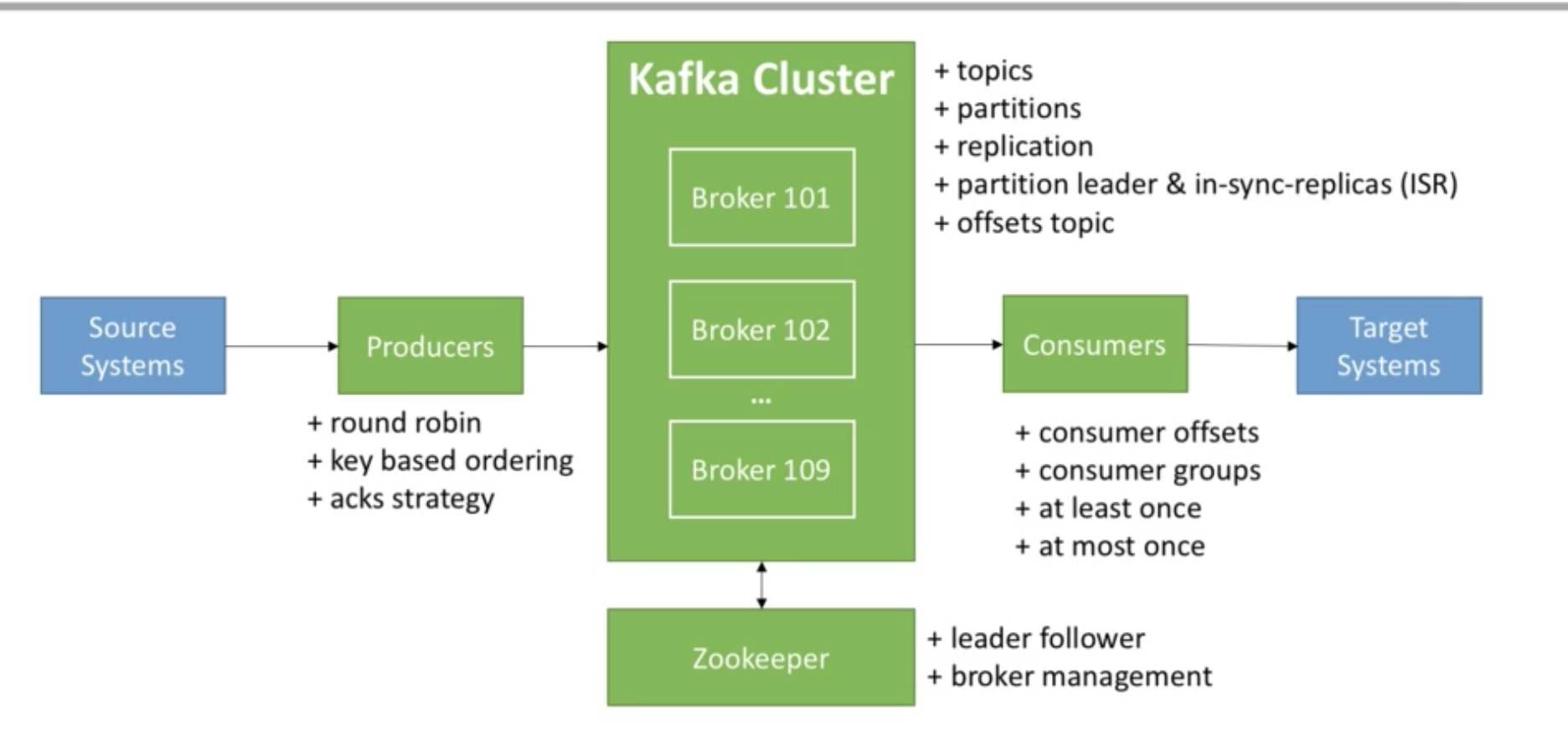
Kafka Theory
Topics, Partitions, Offsets
Topics: a particular stream of data
- similar to a table in a database (without all the constraints)
- You can have as many topics as you want
- A topic is identified by its name
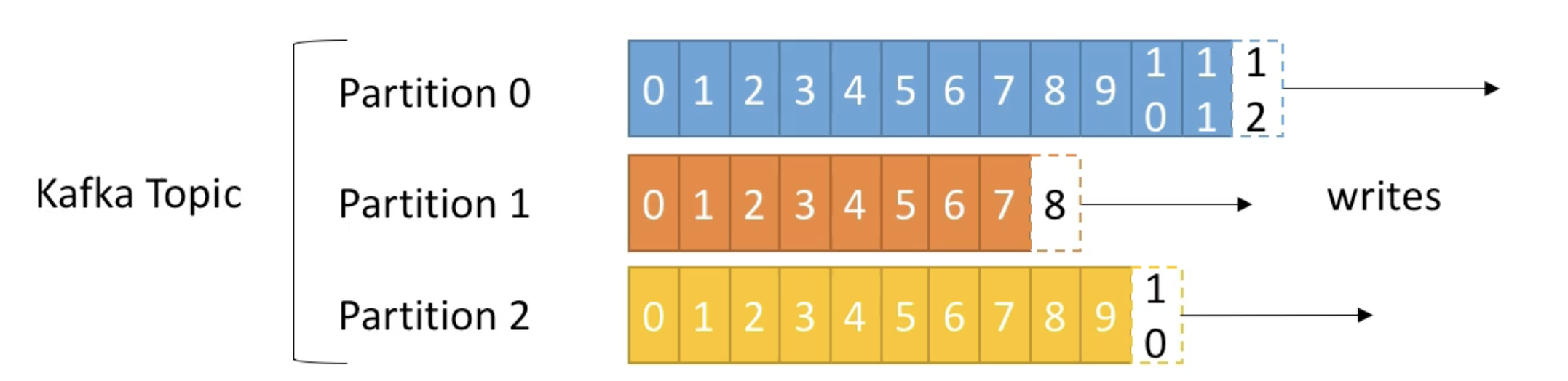
Partitions
- Topics are split in partitions
- each partition is orderd
- Each message within a partition gets an incremental id, called offset
- Topic을 만들 때 partition개수를 정해야 한다. 물론 나중에 바꿀 수 있다.
Offsets
- Offset only have a meaning for a specific partition
- E.g. offset 3 in partition 0 doesn't represent the same data as offset 3 in partition 1
- Order is guaranteed only within a partition ( not across partitions)
- Data is kept only for a limited time ( default is one week)
- Once the data is written to a partition, it can't be changed (immutability)
- Data is assigned randomly to a partition unless a key is provided (more on this later)
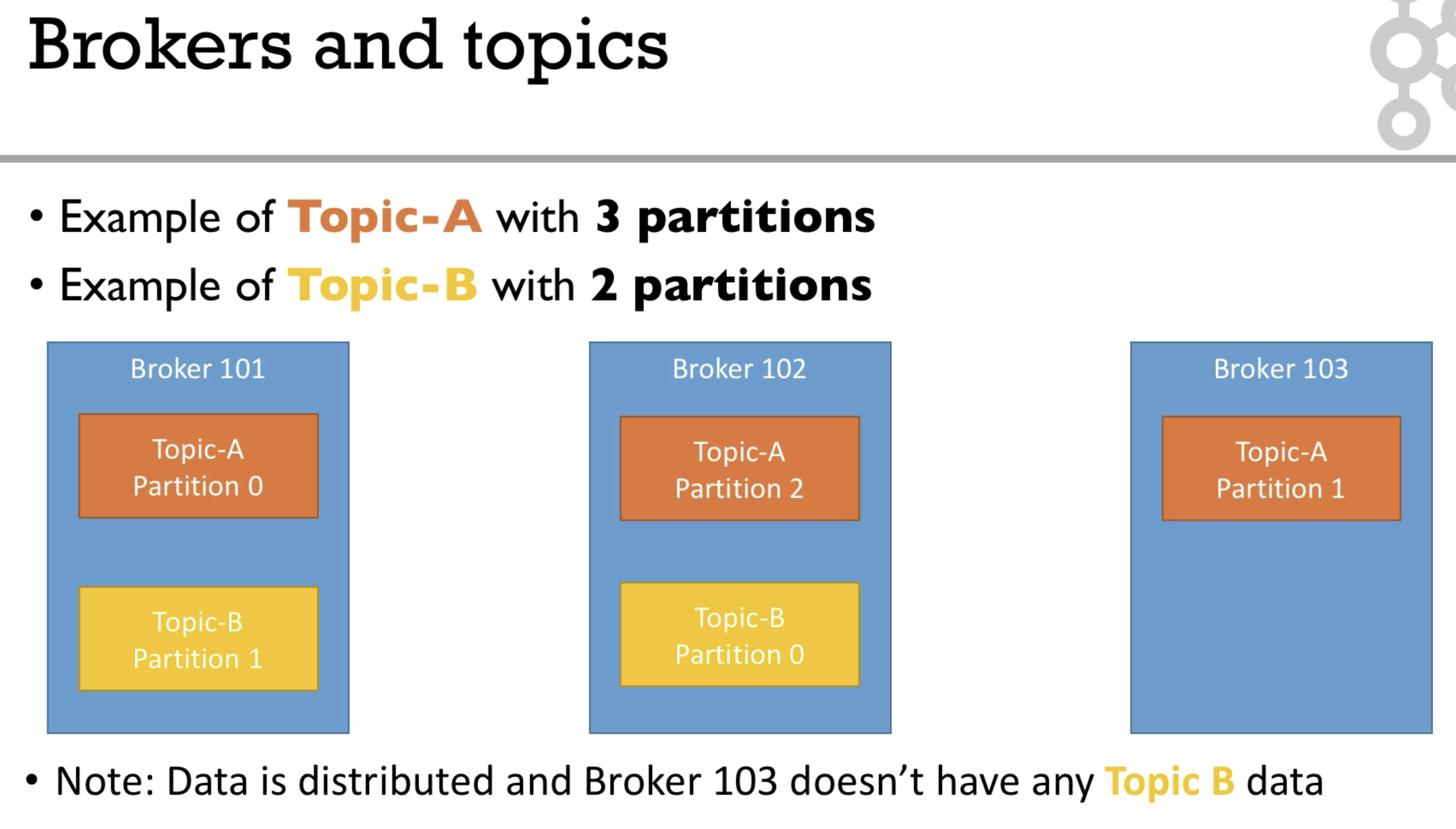
Brokers and Topics
- each broker is a server
- A kafka cluster is composed off multiple borkers (servers)
- Each broker is identified with its ID (integer)
- After connecting to any broker (called a bootstrap broker), you will be connected to the entire cluster
- A good number to get started is 3 brokers, but some big clusters have over 100 brokers.
- In example broker id starting at 100 (arbitrary)
Example
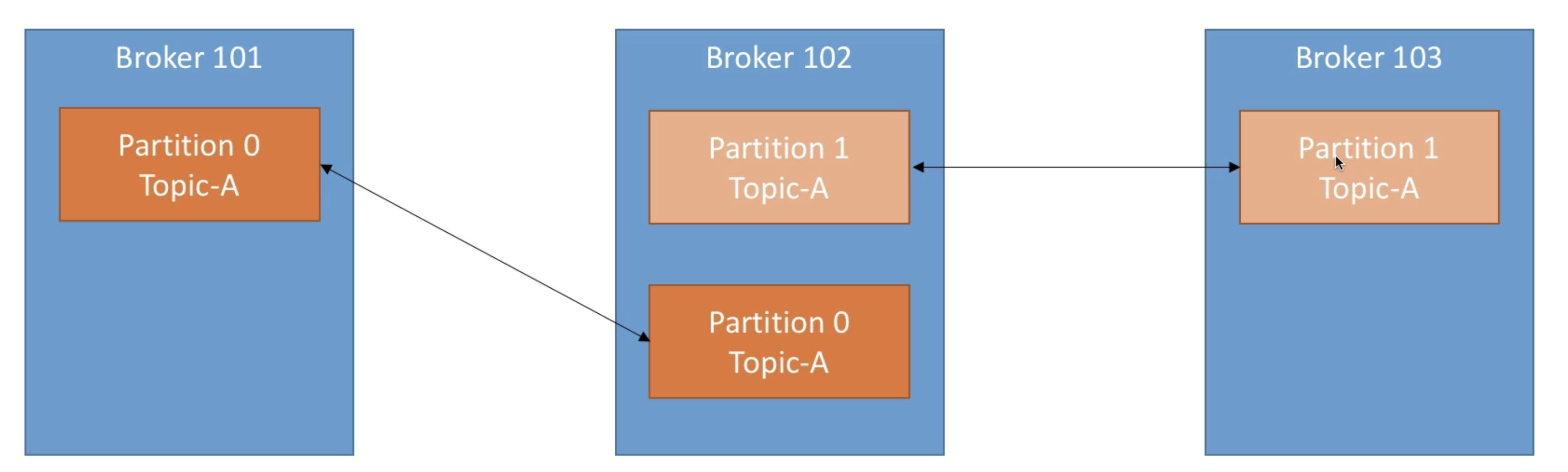
Topic Replication
- 머신 하나가 down되도 서비스가 지속될 수 있게 하기 위해 replication이 필요하다.
- Toplics Should have replication factor more than 1 (usually between 2 and 3)
- This way if a broker is down, another broker can server the data
- Example: Topic-A with 2 partitions and replication factor of 2

- 위 그림처럼 broker 102가 고장나도 replication덕에 서비스에는 문제가 없다.
Leader for a Partition
- At any time only ONE broker can be a leader for a given partition
- Only that leader can receive and serve data for a partition
- The other brokers will synchronize the data
- Therefore each partition has one leader and multiple ISR (in-sync reaplica)
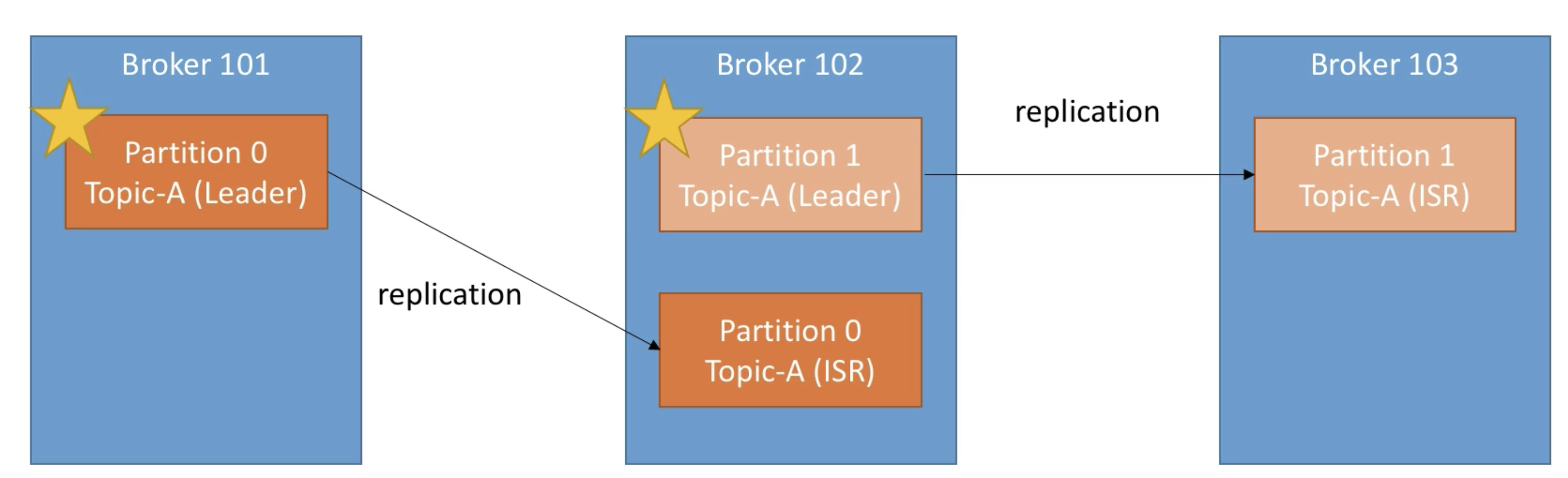
- 위 그럼처럼 각 partition마다 리더가 있다.(별표)
- 만약 Broker 101이 down되면, Broker 102에 있는 partition 0이 리더가 된다.
- broker 101이 회복되면 다시 리더를 되찾기 위한 시도가 일어난다.
Producers and Message Keys
Producers
- write data to topics(which is made of partitions)
- automatically know to which broker and partition to write to
- in case of Broker failures, Producers will automaticaaly recover
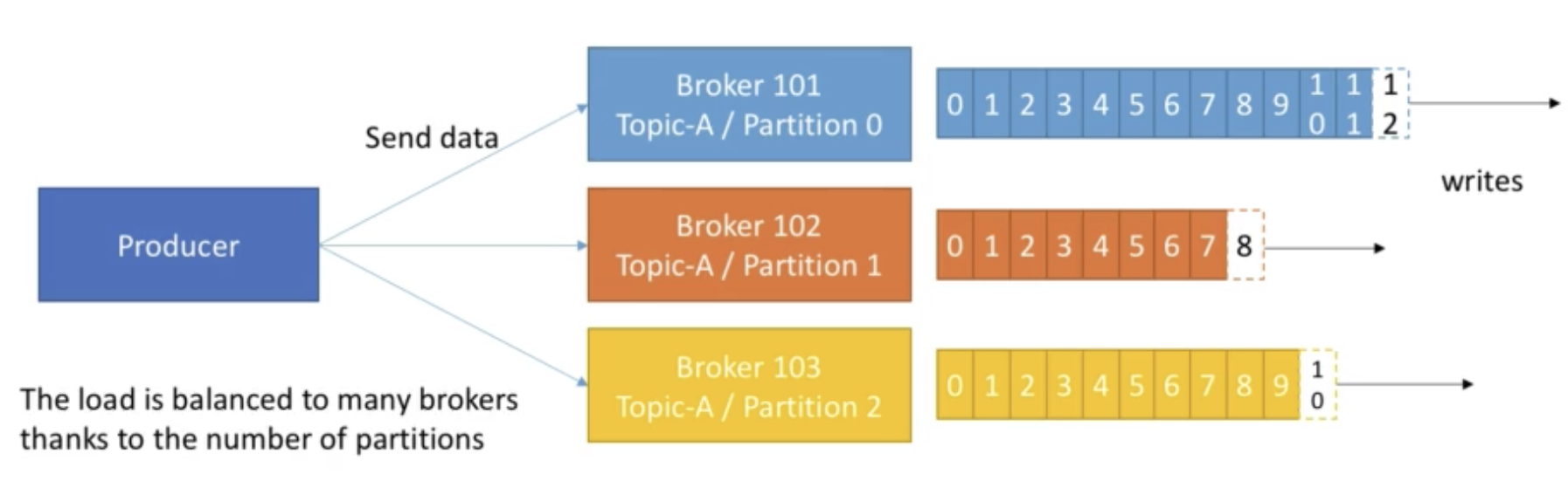
- Producers can choose to receive acknowledgement of data wirtes:
- acks=0: Producer won't wait for acknowledgement(possible data loss)
- acks=1: Producer will wait for leader acknowledgement(limited data loss)
- acks=all: Leader + replicas acknowledgement(no data loss)
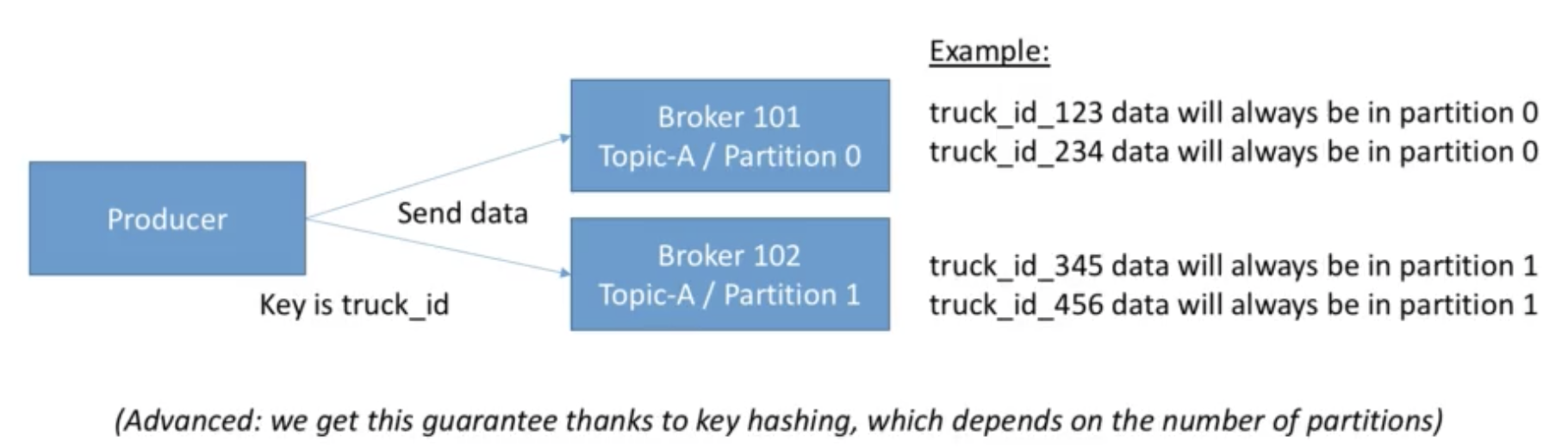
Producers:Message keys
- Producers can choose to send a key with the message(string, number, etc)
- if key=null, data is sent round robin(broker 101 then 102 then 103...)
- if a key is sent, then all msg for that key will always go to the same partition
- A key is basically sent if you need msg ordering for a specific field(ex: truck_id)
Consumers & Consumer Groups
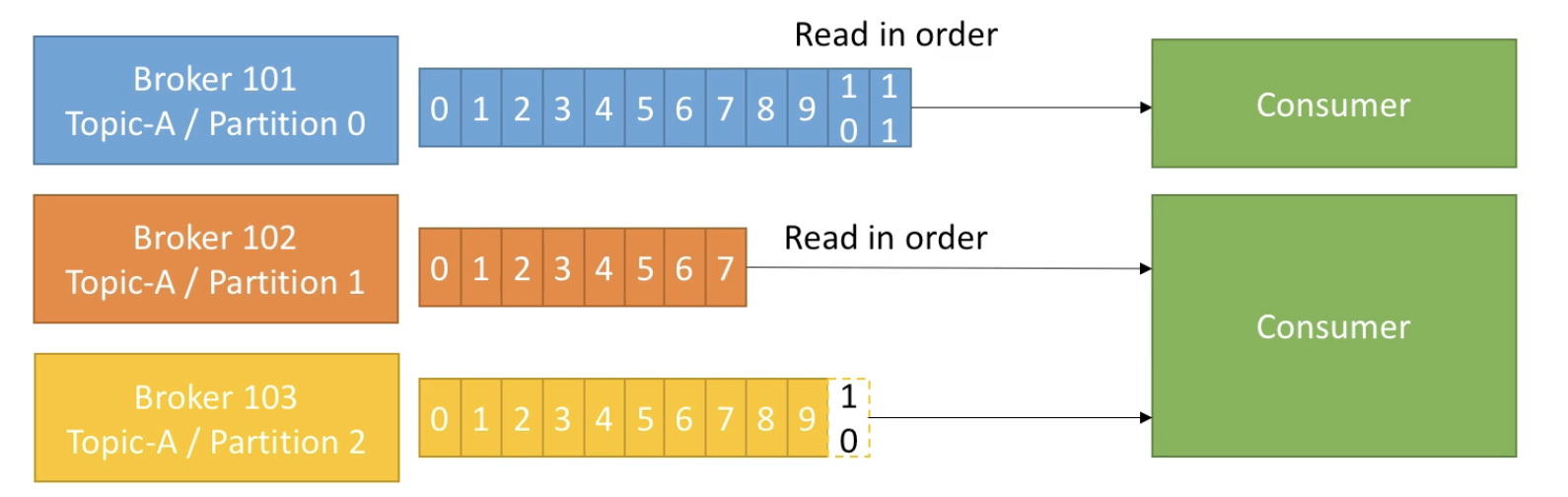
Consumers
- Consumers read data from a topic(identified by name)
- Consumers know which broker to read from
- In case of broker failures, consumers know how to recover
- Data is read in order within each partitions
Consumer Groups
- consumer는 애플리케이션이다. 예를 들면 django application.
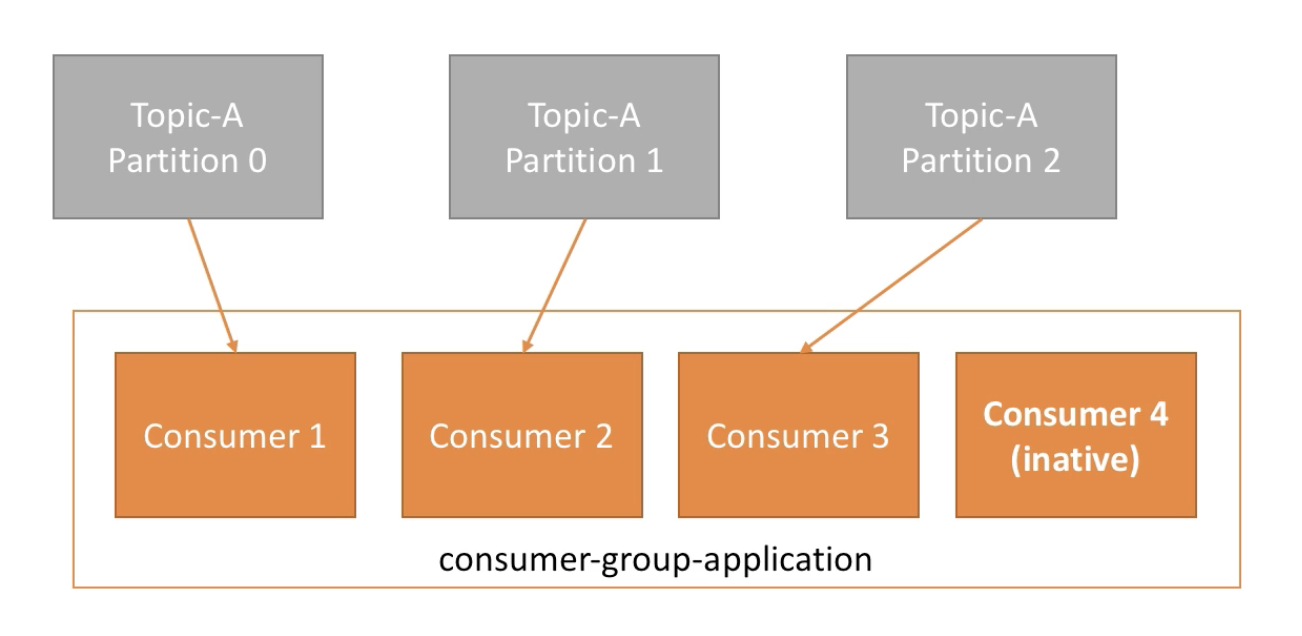
- Consumers read data in consumer groups
- Each consumer within a group reads from exclusive partitions
- If you have more consumers than partitions, some consumers will be inactive
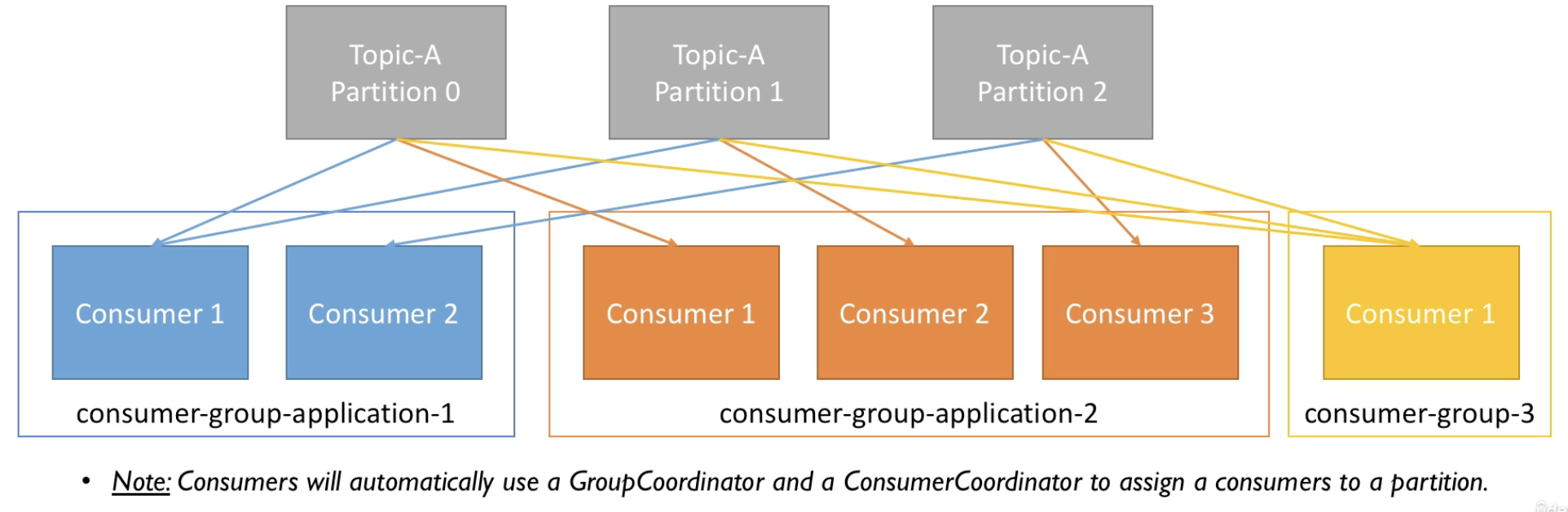
What if too many consumers
- If consumers num > partitions num, some consumers will be inactive
Consumer Offsets & Delivery Semantics
Consumer Offsets
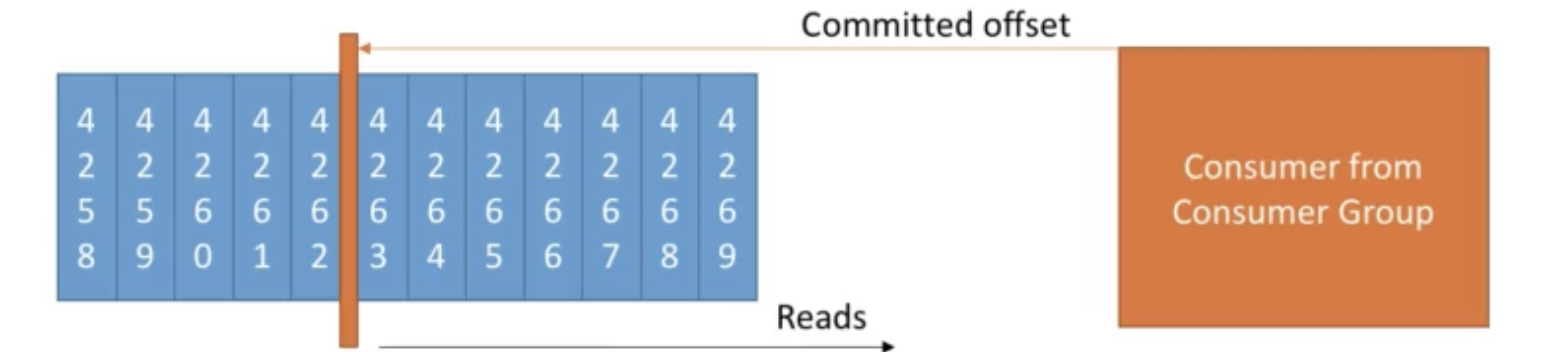
- consumer offsets은 consumer가 어디까지 읽었는지 표시하는 책갈피 같은 기능이다.
- 이기능을 통해 혹시 consumer가 down되어도 다시 up했을 때 어디부터 읽어야 할지 알 수 있다.
- Kafka stores the offsets at which a consumer group has been reading
- The offsets committed live in a Kafka topic named
__consumer_offsets - When a consumer in a group has processed data received from Kafka, it should be committing the offsets
- If a consumer dies, it will be able to read back from where it left off thanks to the committed consumer offsets!
Delivery Semantics
- Consumers choose when to commit offsets.
- There are 3 delivery semantics:
- At most once:
- offsets are committed as soon as the msg is received
- If the processing goes wrong, the msg will be lost(it won't be read again)
- At least once(usually preferred)
- offsets are committed after the msg is processd
- If the processing goes wrong, the msg will be read again.
- This can result in duplicate processing of msg. Make sure your processing is idempotent(i.e. processing again the msg won't impact your systems)
- Exactly once
- Can be achieved for Kafka -> Kafka workflows using Kafa Streams API
- For Kafka -> External System workflows, use an idempotent consumer
- At most once:
Kafka Broker Discovery
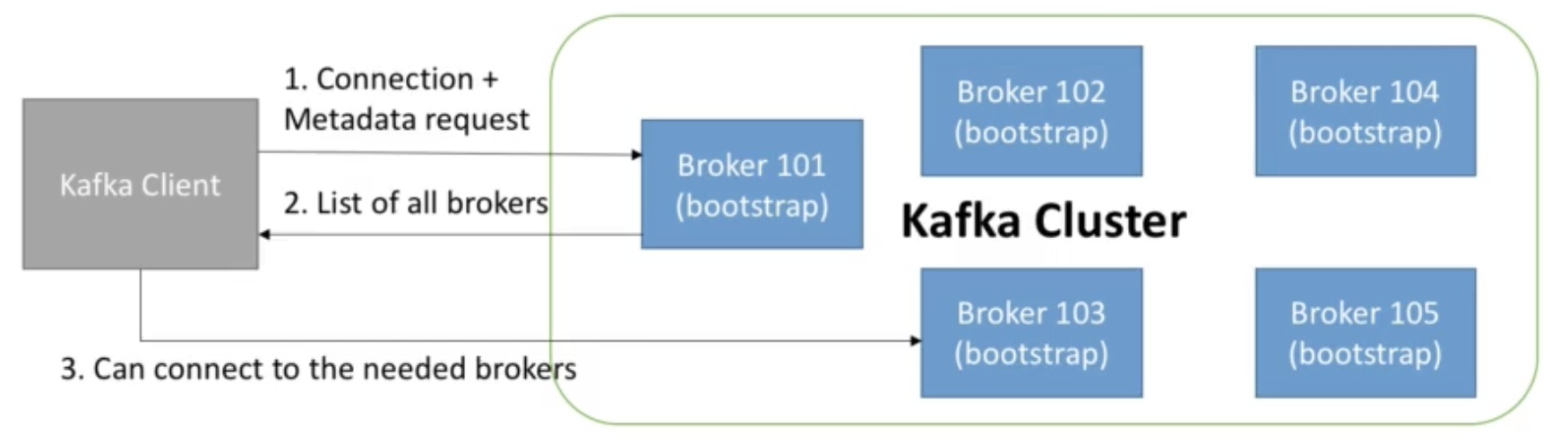
- Every Kafka broker is also called a "boostrap server"
- That means that you only need to connect to one broker,
and you will be connected to the entire cluster. - Each broker knows about all brokers, topics and partitions (metadata)
Zookeeper
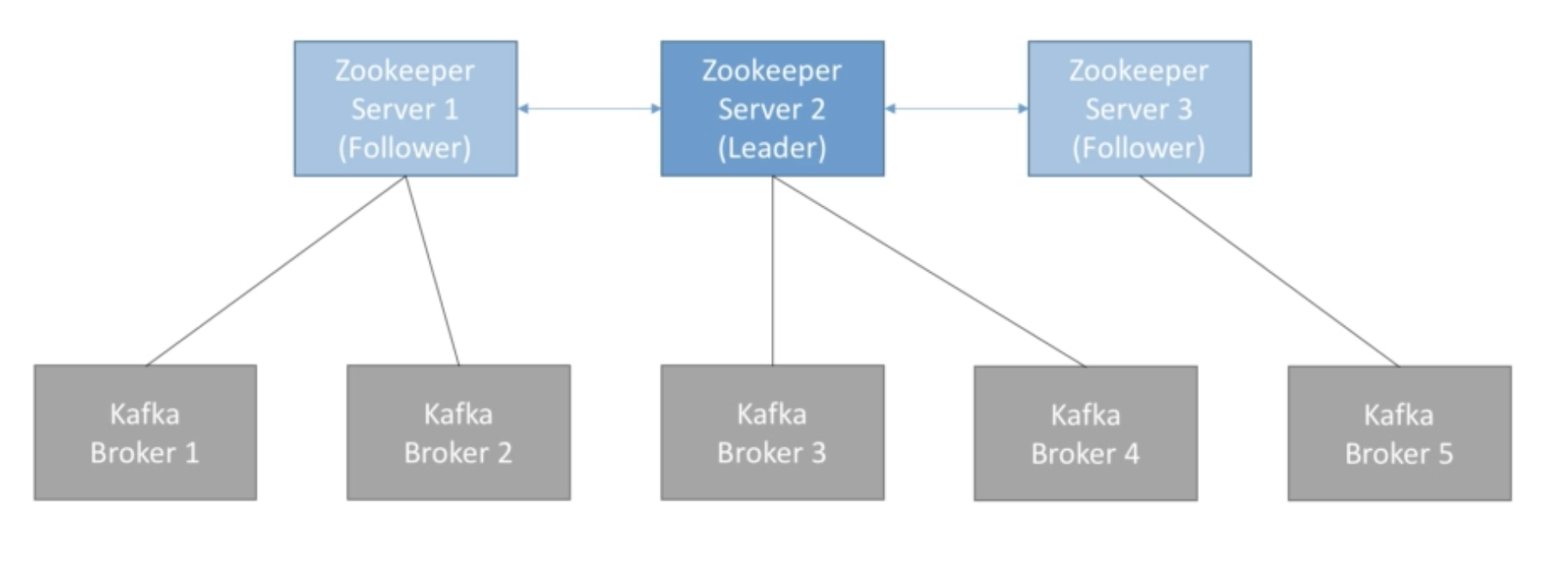
- Zookeeper manages brokers (keeps a list of them)
- Zookeeper helps in performing leader election for partitions
- Zookeeper sends notifications to Kafka in case of change (e.g. new topic, broker dies, broker comes up, delete topics, etc..)
- Kafka can't work without Zookeeper
- Zookeeper by design operates with an odd number of servers (3,5,7)
- Zookeeper has a leader (handle writes) the rest of the servers are followers (handle reads)
- (Zookeeper does NOT store consumer offsets with Kafka > v0.10)
Kafka Guarantees
- msgs are appended to a topic-partition in the order they are sent
- Consumers read msg in the order stored in a topic-partition
- With a replication factor of N, producers and consumers can tolerate up to N-1 brokers being down
- This is why a replication factore of 3 is a good idea:
- Allows for one broker to be taken down for maintenace
- Allows for another broker to be taken down unexpectedly
- As long as the number of partitions remains constant for a topic (no new partitions), the same key will always go to the same partition
Theory Roundup
Quiz
-
To produce data to a topic, a producer must provide the Kafka client with any broker from the cluster and the topic name
- Very important: you only need to connect to one broker (any broker) and just provide the topic name you want to write to. Kafka Clients will route your data to the appropriate brokers and partitions for you!
-
To read data from a topic, the following configuration is needed for the consumers
- Very important: you only need to connect to one broker (any broker) and just provide the topic name you want to read from. Kafka will route your calls to the appropriate brokers and partitions for you!
Setup Kafka
- kafka를 실행하기 위해선 java를 먼저 깔아야 한다. java와 kafka를 깔아보자.
- 참고로 강사가 무조건 java 8을 설치하라고 한다. 9,10,11 말고 8. 이유는 모르겠다만, 일단 그렇게 하자.
install java on MacOS
- 여기 참고
brew update- `brew tap adoptopenjdk/openjdk``
brew search jdkbrew install --cask adoptopenjdk8(자바 8 설치)
install kafka on MacOS
- kafka공식 사이트에서 다운로드 받는다.
- Binary Downlads로, Scala는 아무거나(나는 2.13)을 받았다.
- 받은 파일을
.디렉토리로 옮긴 뒤tar -xvf kafka_2.13-3.0.0.tgz명령어로 압축을 해제. - 해제한 폴더 안에 들어가서
bin/kafka-topics.sh을 쳤을 때 뭐라뭐라 설명문이 나오면 잘 된거다.
start Zookeeper
- 서버를 실행하기 전 zookeeper와 kafka 서버의 datadir을 바꿔주자.
mkdir data/zookeeper(카프카 루트 디렉토리에서)mkdir data/kafka(카프카 루트 디렉토리에서)config/zookeeper.propertie의 dataDir값을 위에서 만든 data/zookeeper의 절대경로 값으로 바꿔준다.config/zookeeper.propertie의 log.dirs값을 위에서 만든 data/kafka의 절대경로 값으로 바꿔준다.bin/zookeeper-server-start.sh config/zookeeper.properties명령어로 zookeeper서버를 실행한다. 아래 내용이 터미널에 뜨면 잘된거다.INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
- 새로운 터미널에
bin/kafka-server-start.sh config/server.properties로 카프라 서버를 실행한다.
아래 내용이 터미널에 뜨면 잘된거다./Users/hwanil.kim/kafka_2.13-3.0.0/data/kafka`
CLI
- 카프카는 토픽으로부터 시작하기 때문에 CLI도 토픽 먼저 배운다.
bin/kafka-topics.sh로 설명을 볼 수 있다.- topic을 만들어보자.
create topic
try 1.
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create- 에러(
Missing required argument "[partitions]") - 토픽 생성시 partition개수 지정해야 함.
try 2.
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3- 에러(
Missing required argument "[replication-factor]") - 토픽 생성시 replication 개수 지정해야 함.
try 3.
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3 --replication-factor 2- 에러(Error while executing topic command : Replication factor: 2 larger than available brokers: 1.)
- 현재 브로커 서버 1대임. replication 수는 브로커 수를 초과할 수 없다.
try 4.
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3 --replication-factor 1- 성공
list topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
describe topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 first_topic --des cribe- Leader는 broker id를 말한다.

delete topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic first-topic --delete
Kafka Consloe Producer CLI
bin/kafka-console-producer.sh: producer에 대한 설명 볼 수 있는 명령어bin/kafka-console-producer.sh --broker-list 127.0.0.1:9020 --topic first_topic
Kafka Console Consumer CLI
Kafka Consumers in Group
Kafka Consumer Groups CLI
Resetting Offsets
Kafka Java Programming 101
Kafka Twitter Producer & Advanced Configurations
Kafka ElasticSearch Consumer & Advanced Configrations
Kafka Extended APIs for Developers
Real World Insights and Case Studies

Never stop asking why