python 회문 판별, N-gram 만들기
-회문(palindrome): 거꾸로 읽어도 똑같은 단어나 문장(ex. level)
-회문 판별 기준은 맨 처음, 맨 마지막 글자가 같고, 안쪽으로 한 글자씩 좁혔을 떄 서로 같아야 함.
-회은 유전자 염기서열 분석, N-gram은 빅데이터 분석, 검색 엔진에 많이 쓰임.
회문검사 방법 1: 복문
word = input('단어를 입력하세요')
is_palindrome = True
for i in range(len(word) // 2):
if word[i] != word[-1 -i]:
is_palindrome = False
break
print(is_palindrome)
결과: True회문검사 방법 2: 슬라이스 활용
*참고: [::-1]은 전체를 뒤부터 가져오는 문법
word = input('단어를 입력하세요')
print(word == word[::-1])회문검사 방법3: 리스트, reversed 사용
word = 'level'
>>> list(word) ==list(reversed(word))
True -리스트에 문자열 넣으면 문자 하나하나가 리스트의 요소로 들어간다.
l,e,v,e,l
문자열의 join 메서드와 reversed 사용하기
word = 'level'
>>> word == ''.join(reversed(word))
True-join은 구분자 문자열과 문자열 리스트의 요소를 연결
-빈 문자열''에 reversed(word)의 요소를 연결했으므로 문자 순서가 반대로 된 문자열을 얻을 수 있다.
-join은 요소 사이에 구분자를 넣지만 빈 문자열''을 활용하여 각 문자를 그대로 연결하는 방식.
N-gram 만들기
- N-gram은 문자열에서 N개의 연속된 요소를 추출
예) banana를 2-gram단위로 추출하면?
ba
an
na
an
na반복문으로 N-gram 출력
2-gram
text = 'ediya'
>>> for i in range(len(text)-1):
print(text[i], text[i+1], sep='')
ed
di
iy
ya3-gram
text = 'favorite'
>>> for i in range(len(text)-2):
print(text[i], text[i+1], text[i+2], sep='')
fav
avo
vor
ori
rit
ite공백을 기준으로 단어 단위 2-gram 출력
text = 'The secret to great flavor'
>>> words = text.split()
>>> for i in range(len(words)-1):
print(words[i], words[i+1])
The secret
secret to
to great
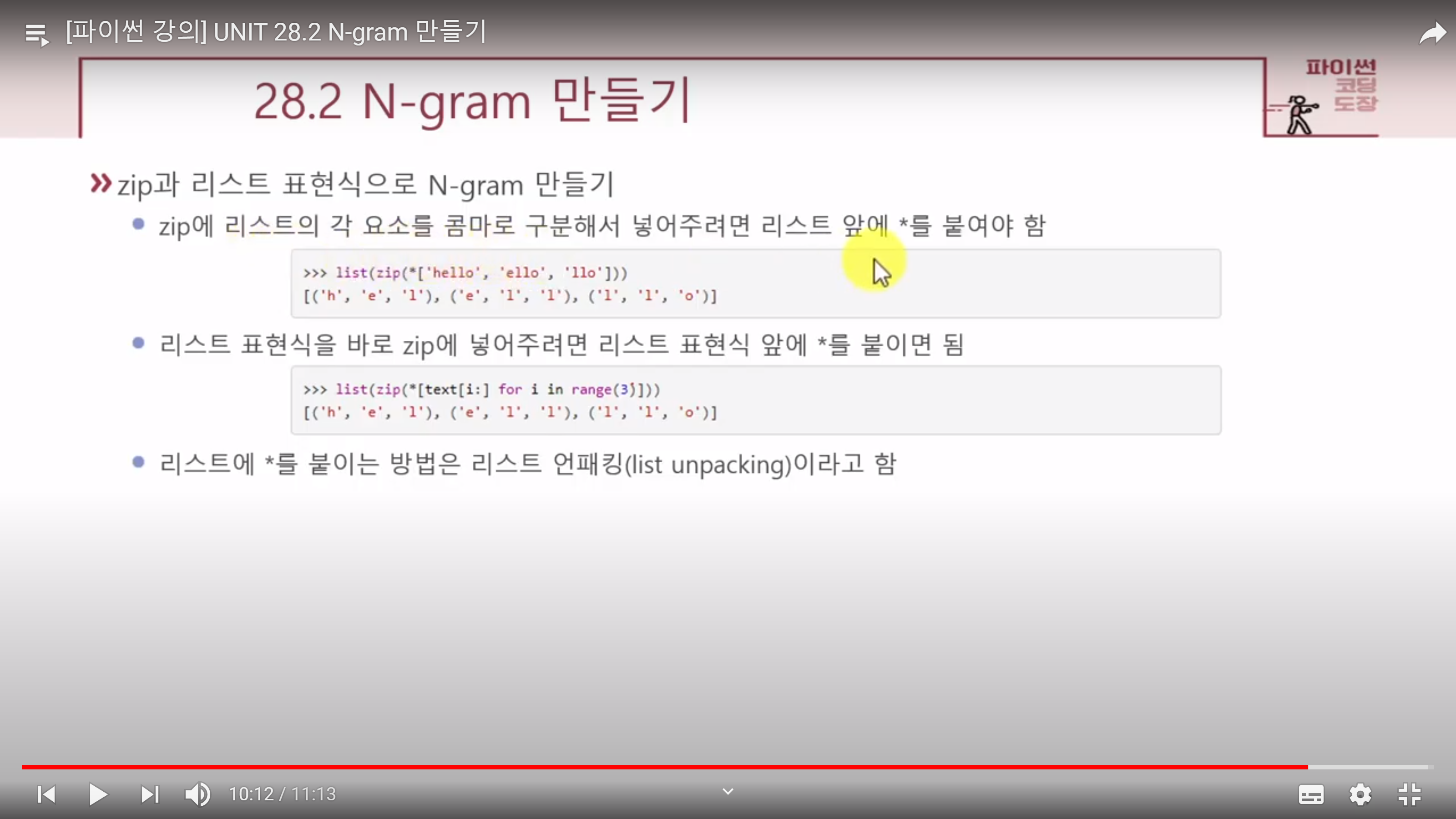
great flavorzip으로 2-gram 만들기
text = 'hello'
>>> two_gram = zip(text, text[1:])
>>> for i in two_gram:
print(i[0], i[1], sep='')
he
el
ll
lo-지금까지 zip 함수는 리스트 두 개를 딕셔너리로 만들 때 사용했는데, zip 함수는 반복 가능한 객체의 각 요소를 튜플로 묶어줌
text = 'hello'
>>> list(zip(text, text[1:]))
[('h', 'e'), ('e', 'l'), ('l', 'l'), ('l', 'o')]-단어 단위 2-gram도 같은 방법이다.
text = 'The secret to great flavor'
>>> words = text.split()
>>> list(zip(words, words[1:]))
[('The', 'secret'), ('secret', 'to'), ('to', 'great'), ('great', 'flavor')] 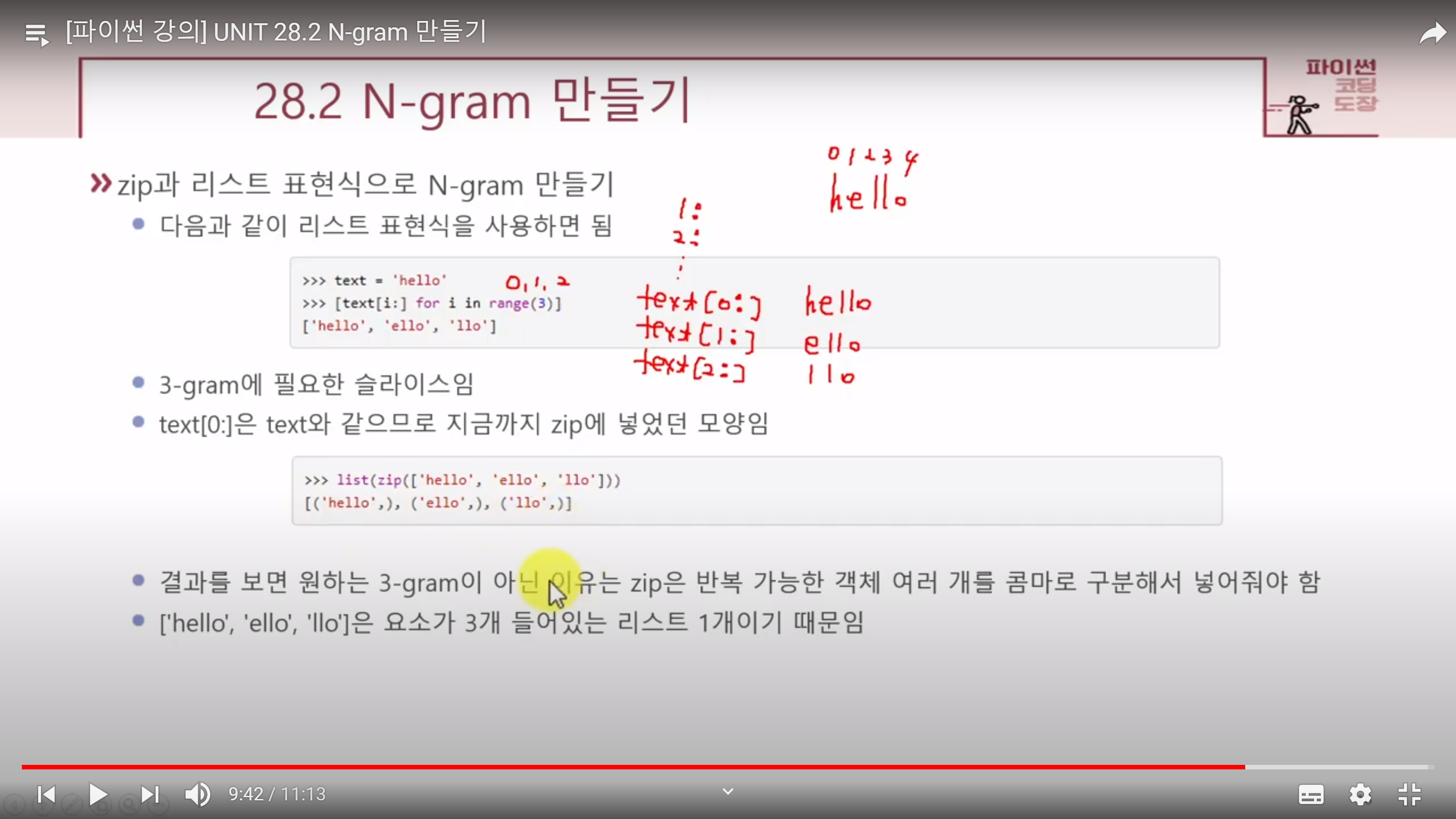

Never stop asking why