📌 crawling 크롤링
<교육 세부 일정 >
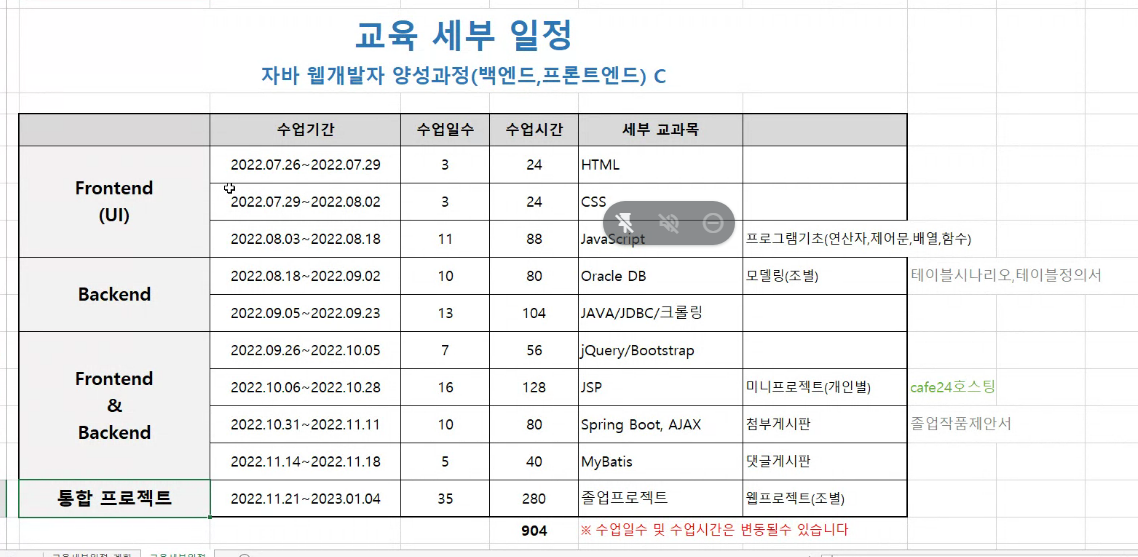
- 10월부터 미니프로젝트 진행 후 졸업작품 제안서 제작 예정
이야.. 이걸 어쩐다..
1. 웹 크롤링 web crwaling 개념
- 크롤링(crawling), 스크레핑(scraping)
- 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위다
- 로봇 배제 표준(robots.txt) : 웹 사이트에 로봇이 접근하는 것을 방지하기 위한 규약
https://www.daum.net/robots.txt
https://www.naver.com/robots.txt
http://world.kbs.co.kr/robots.txt
http://ytn.co.kr/robots.txt
- jsoup 라이브러리
- 자바로 만들어진 HTML parser다.
- parser : 분리되었다는 의미.
- Jsoup는 DOM 구조를 추적하거나 CSS 선택자를 사용하여 데이터를 찾아 추출할 수 있다.
- DOM : HTML의 구조
- 다운로드
https://jsoup.org/download -> jsoup-1.14.3.jar
- 자바로 만들어진 HTML parser다.
- jsoup 라이브러리 핵심 클래스
- Document 클래스 : 연결해서 얻어온 HTML전체 문서
- Element 클래스 : Document의 HTML요소
- Elements 클래스 : Element가 모인 자료형
- [Dynamic Web Project 생성]
- 프로젝트 명 : basic03_crawling
- /src/main/webapp/WEB-INF/lib/jsoup-1.14.3.jar 붙여넣기
- 외부라이브러리 추가하면 해당 프로젝트 새로고침
- 해당프로젝트 우클릭 F5
- 해당프로젝트 우클릭 Validate
- 메뉴 Project -> Clean
내가 검색한 정보
-
정식명칭은 'Web Scraping'
-
웹 페이지의 특정 형태의 정보를 수집하는 것이다.
-
컴퓨터 소프트웨어 기술로 웹사이트들을 돌아다니면서 정보를 수집하는 행위
-
나에게 유용한 정보를 뽑아내야 한다.
-
'페이지 소스보기', '개발자 검사'로 자세히 볼 수 있다.
-
- 정형, 비정형, 반정형 데이터
- 정형 데이터 (Structured Data)
Database - 반정형 데이터 (Semi - Srtuctured Data)
HTML, xml, JSON - 비정형 데이터 (Undtructured Data)
소셜 데이터의 텍스트, 이미지, 영상, 워드나 PDF문서와 멀티미디어 데이터
참고: https://needjarvis.tistory.com/502
- 정형 데이터 (Structured Data)
2. 새 프로젝트 생성
↳ 다이나믹 웹 프로젝트 생성
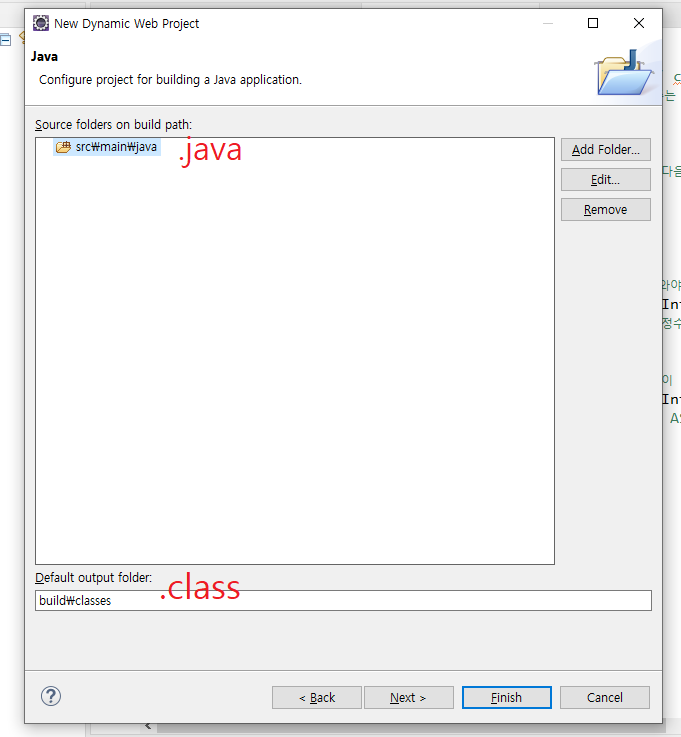
↳ 위에는 .java 소스가 들어가는 파일이고, 밑에는 .class 파일이 들어가는 파일의 경로이다.
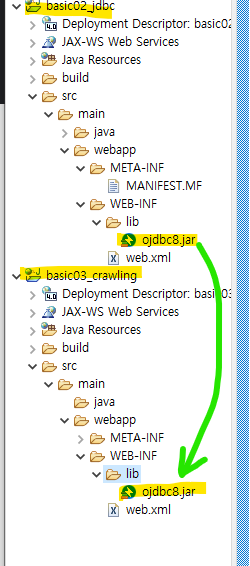
↳ basic02_jdbc 에 넣었던 ojdbc8.jar 파일 복사해서 붙여넣기
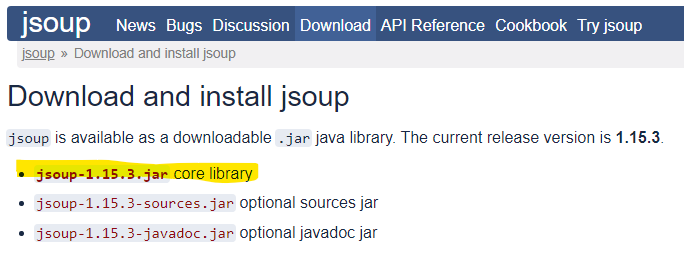
↳ https://jsoup.org/download
사이트 들어가서 jsoup-1.15.3.jar 파일 다운받은 후
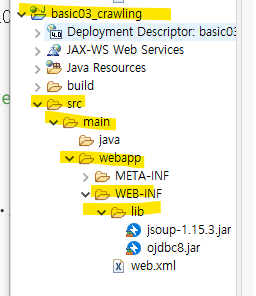
↳ basic03_crawling 프로젝트의
/src/main/webapp/WEB-INF/lib/jsoup-1.15.3.jar 붙여넣기
↳ 외부라이브러리 추가하면 해당 프로젝트 새로고침 하기
- 해당프로젝트 우클릭 F5
- 해당프로젝트 우클릭 Validate
- 메뉴 Project -> Clean
Test01_choongang
3. 중앙정보처리학원 웹페이지의 공지사항 제목만 크롤링 하기
https://www.choongang.co.kr/html/sub07_01_n.php
1) 웹사이트의 페이지 소스보기
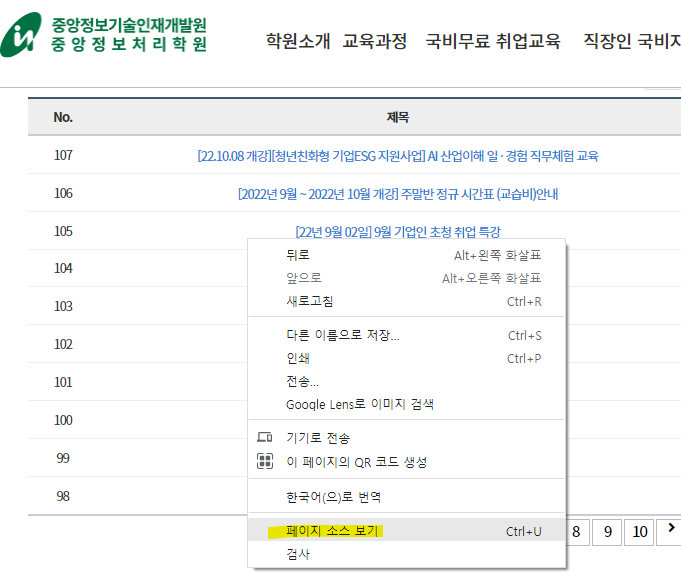
2) 페이지 소스보기 페이지에서 원하는 정보를 가져온다.
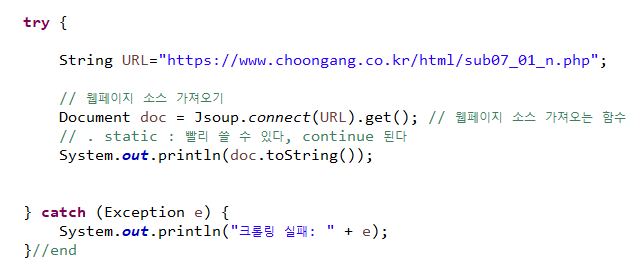
3) 자바로 페이지 소스 가져오기
※ 주의사항
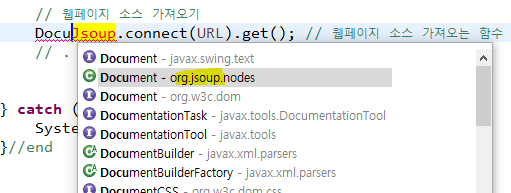
↳ 이름이 똑같은 함수 틀리지 않게 조심하기. 크롤링 할 때는 jsoup이 들어가있는 document 선택해야한다.
4) 결과확인
System.out.println(doc.toString());
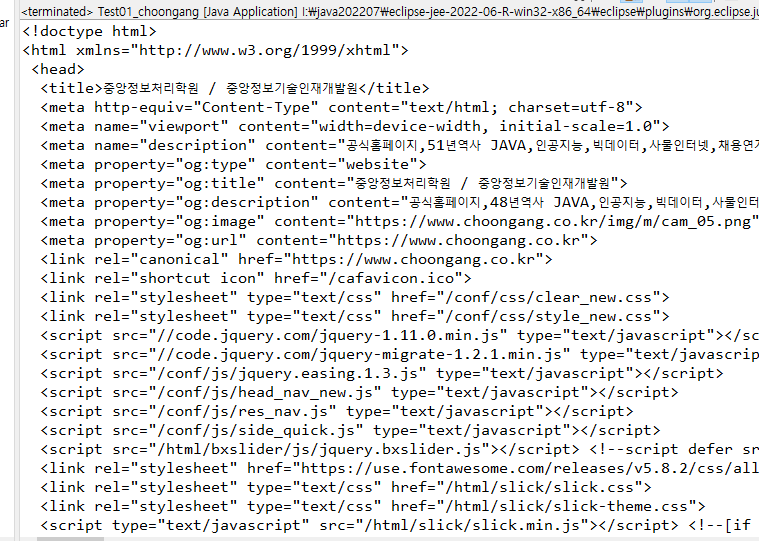
↳ 페이지 소스가 자바프로그램에서 출력된다.
- 페이지 주소 분석 방법

↳ 페이지의 주소를 보면 물음표 ? 를 기점으로
↳ 초록색은 변수
↳ 파란색은 매개변수 (parameter)
↳ 분홍색은 변수를 여러개 준 것. && 연산자 처럼.
↳ page=6 공지사항은 6페이지라는 의미.
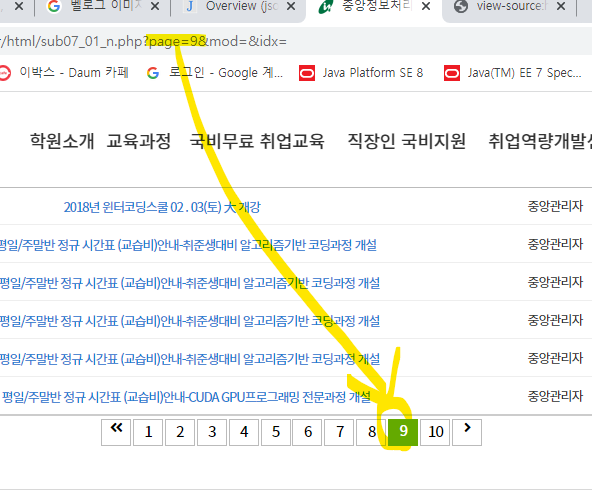
↳ page=6 공지사항은 9페이지라는 의미.
- 전체 페이지를 가져오려면 ?
page=(이부분) 을 변수처리 하면 된다.
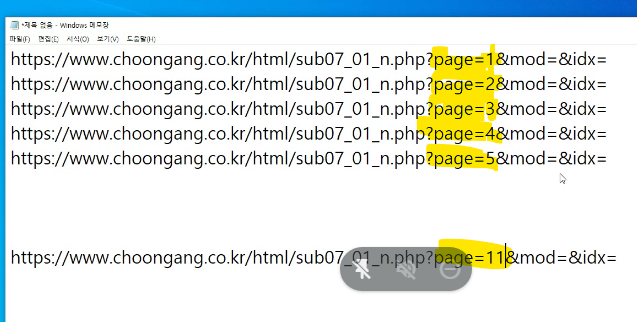
Test02_choongang
공지사항의 전체 페이지 가져오기
1) 웹페이지 주소를 string으로 앞뒤를 구분하여 자른다.
- 자바에서 코딩
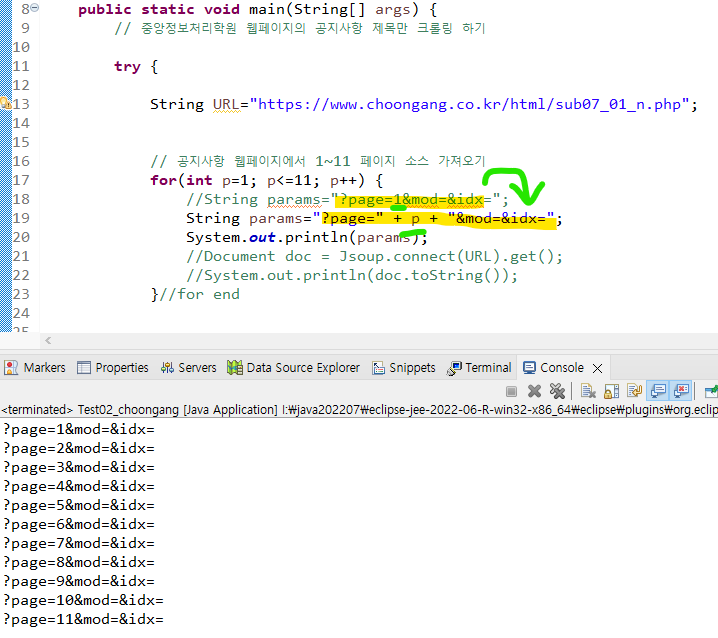
↳ for문으로 1~11페이지까지 반복해주면 11페이지 까지 모두 출력된다.
- ※ 중요포인트
?page=1&mod=&idx= : 원래 주소인 이 부분에서 1 을
"?page=" + p + "&mod=&idx=" : p 변수로 바꿔주면 된다.
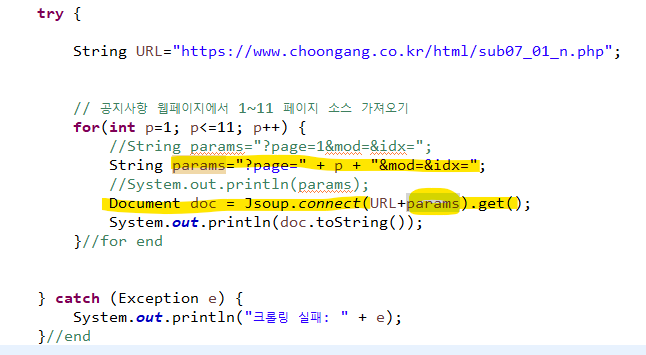
↳ Document doc = Jsoup.connect(URL+params).get();
- ="?page=" + p + "&mod=&idx=" 이 들어있는 params 변수값을 document에 넣어주면 1페이지~11페이지 모든 소스코드가 출력된다.
Test03_choongang
요소 선택하기
1) 개발자 모드 들어가서 페이지 소스 확인하기
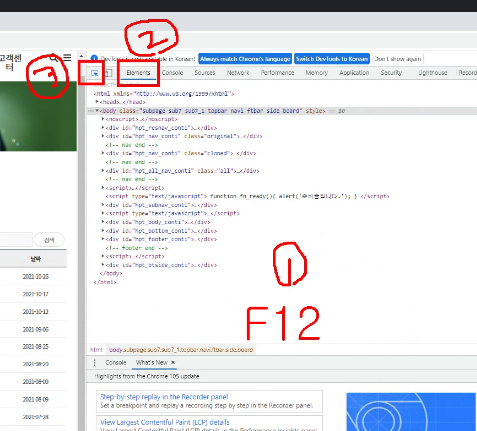
2) 마우스로 제목 소스코드 확인
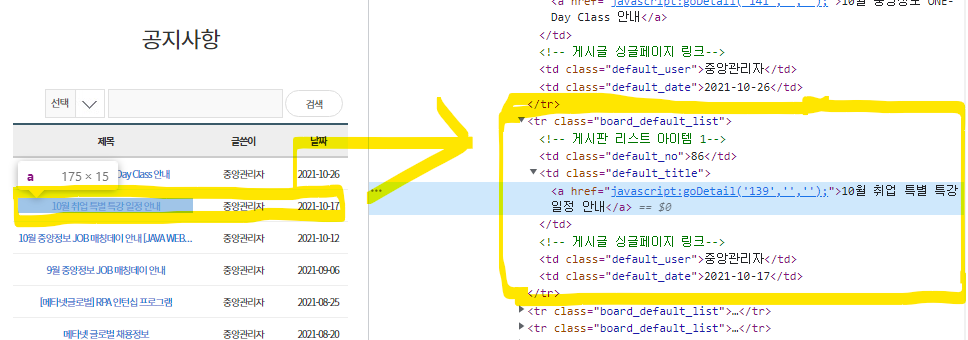
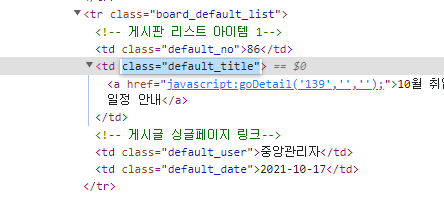
↳ class="default_title" 복사해서 넣으면 제목만 추출이 된다.

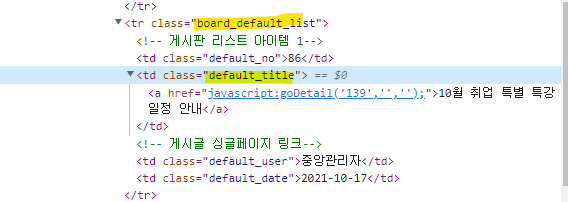
↳ <tr class="board_default_list"> 도 앞에 추가해주면
3) 결과확인


↳ 하위 메뉴들도 추출이 가능하다.
- ※ 주의사항
↳ 크롤링의 임포트 요소들은 jsoup으로 선택해야한다.
Test04_choongang
choongang.txt 파일에 저장
1) 파일 저장 객체 생성

2) 텍스트 파일 출력 명령어 입력 후 닫기
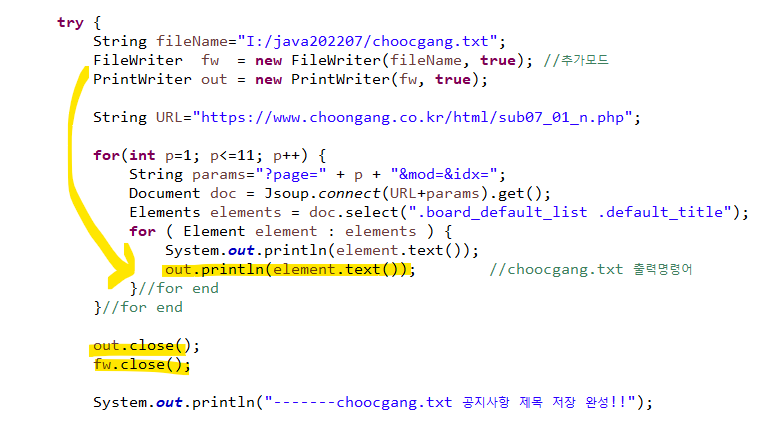
3) 결과 출력
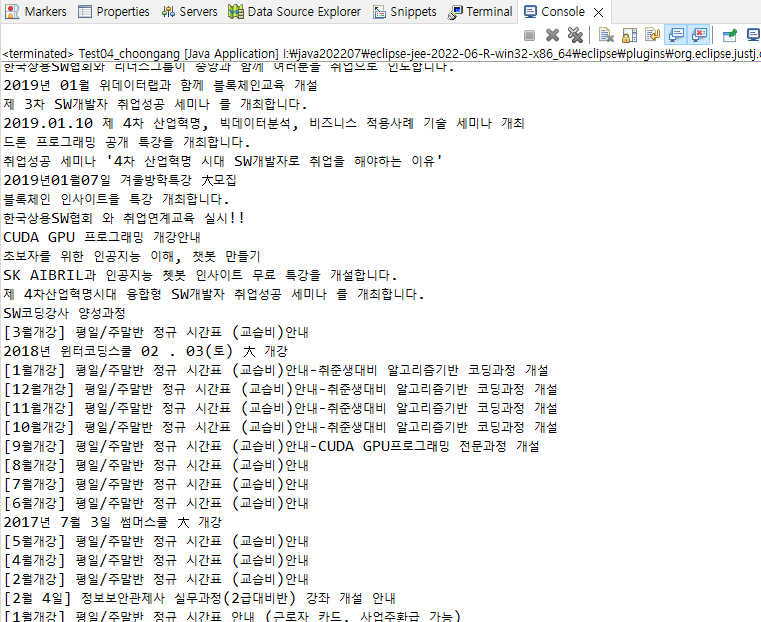
4) choongang.txt 파일에 저장 파일이 지정 경로에 생성된다.
- append()로 값을 계속 추가해야 한다.
override ? ?
Test05_choongang
문제) 솔데스크 웹페이지에서 공지사항 제목만 크롤링해서 soldesk.txt파일에 저장하기
1) 솔데스크 웹페이지 공지사항 사이트에서 주소 복사하기
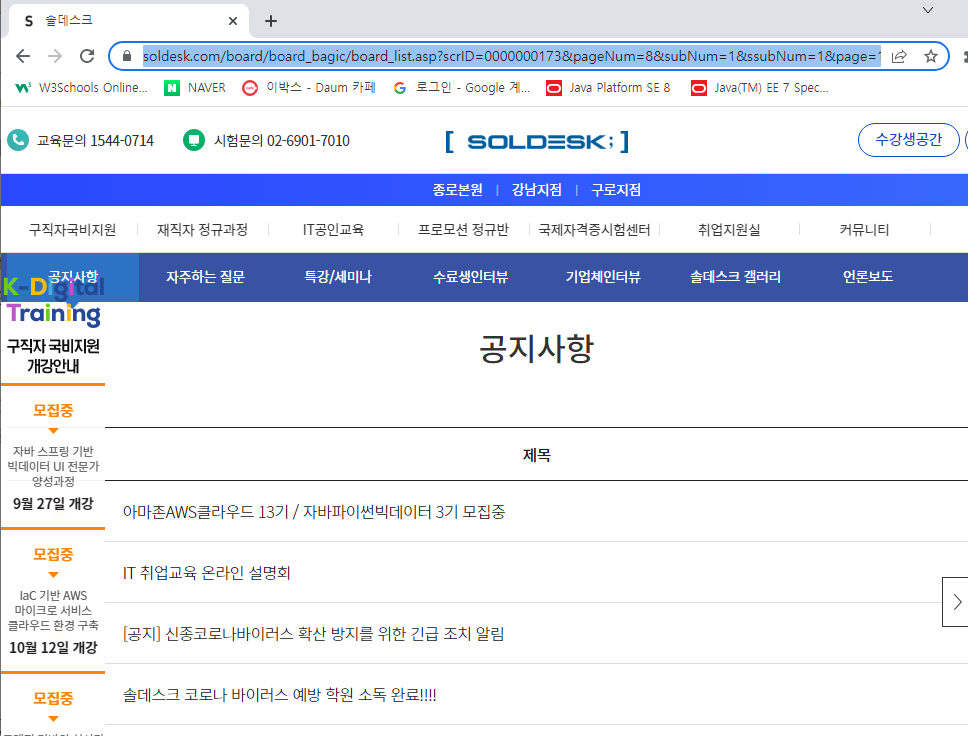
2) 메모장에 페이지별로 복사해서 붙여놓고 어느 부분에서 페이지 숫자가 변하는지 확인하기

3) 자바에서 코딩하기
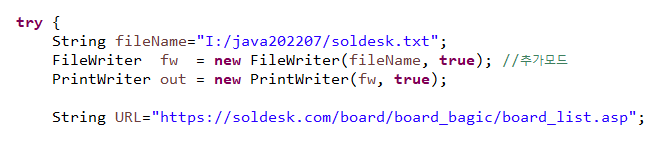
↳ 물음표를 기준으로 주소 부분은 앞부분에 있는 초록색 주소를 넣어주고,

↳ 페이지 넘버가 바뀌는 뒷부분은 파란색 주소를 넣어준다.
4) 결과 확인하기
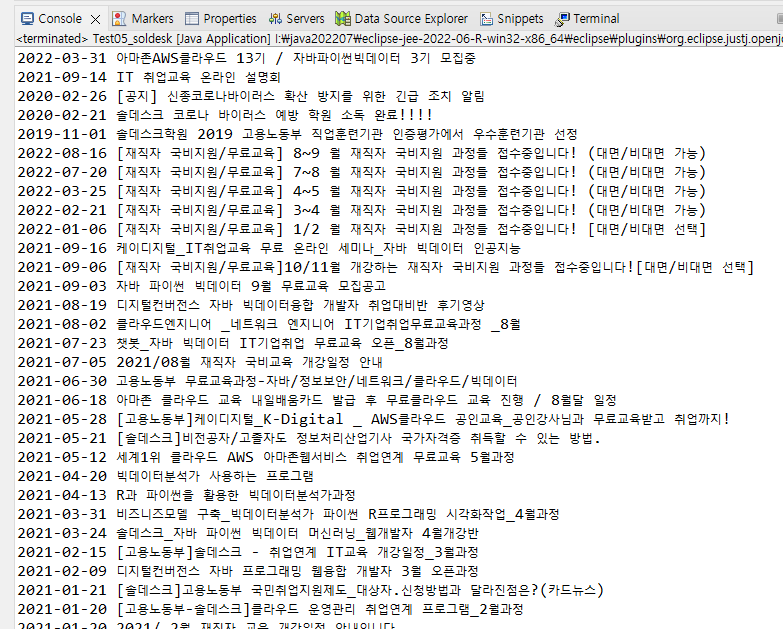
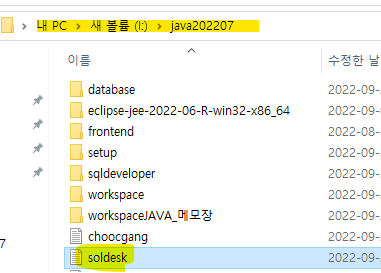
↳ 폴더에도 생성 완료~
※ 하지만, 제목만 필요한데 등록일까지 가져오게된다.

- 개발자모드로 들어가서 날짜 코드 확인하기
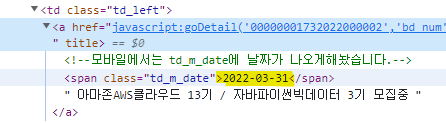
↳ td_m_date 에 날짜정보가 들어가있다.
- remove() 사용해서 날짜만 제거하기

- 출력 확인하기

네이버 영화 평점 댓글 공감순으로 정렬한 것 데이터 가져오기
데이터베이스 공감순, 최신순, 평점순, 낮은순 처리하는 방법
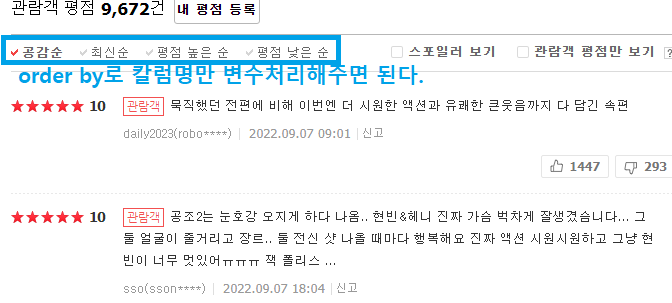

↳ order by로 newest 이부분을 변수처리하면 페이지를 원하는 값을 노출시킬 수 있다.
↳ 네이버 평점은 댓글 페이지가 변해도 url이 바뀌지 않는다.
↳ url은 안바뀌고 댓글 내용은 바뀜. 어떻게 한거지 ??
↓↓↓↓↓↓↓↓↓↓ 해결방법 ↓↓↓↓↓↓↓↓↓↓
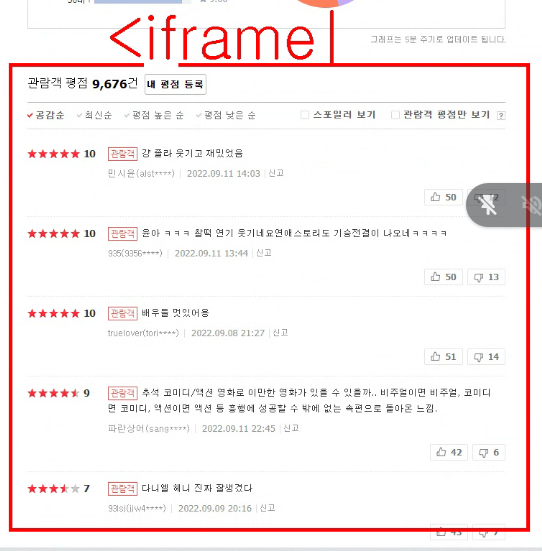
↳ 이부분이 iframe으로 되어있기 때문임.
↳ 페이지 내부에 페이지를 만든 것.
↳ 개발자모드로 iframe 부분을 찾는다.
↓↓↓↓↓↓↓↓↓↓ iframe 찾기 → 그 부분의 페이지 마우스
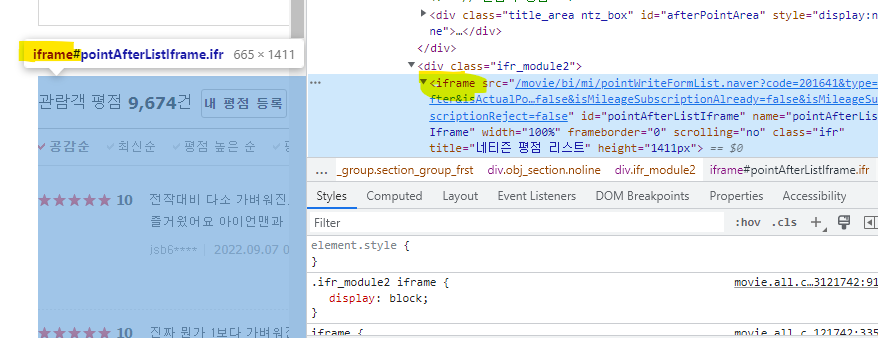
개발자모드 들어가서 페이지 바뀌는 주소 확인하기
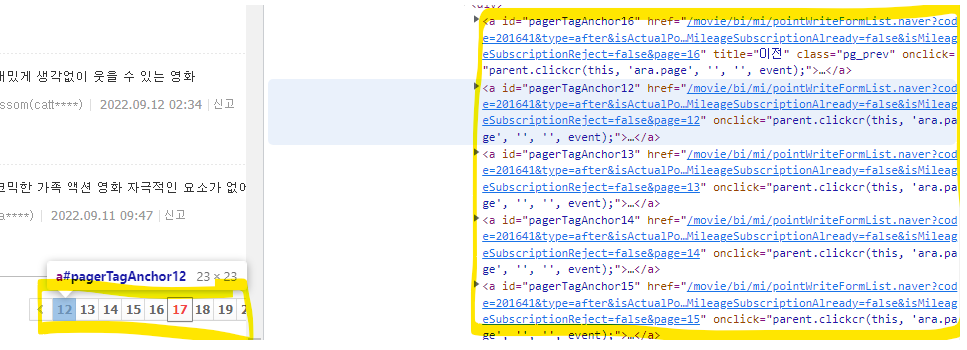
주소를 보고 페이지 번호 바뀌는 것 확인하기

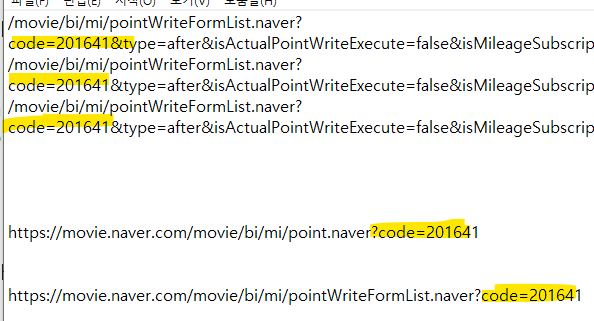
↳ 이부분은 영화 코드번호라는 걸 알 수 있다.
Test06_NaverMovie
네이버 영화 평점 후기 크롤링하기
예) "공조2" 영화 평점 제목을 공감순으로 정렬 후 크롤링하기(1페이지만)
첫번째 방법
태그 분석하기
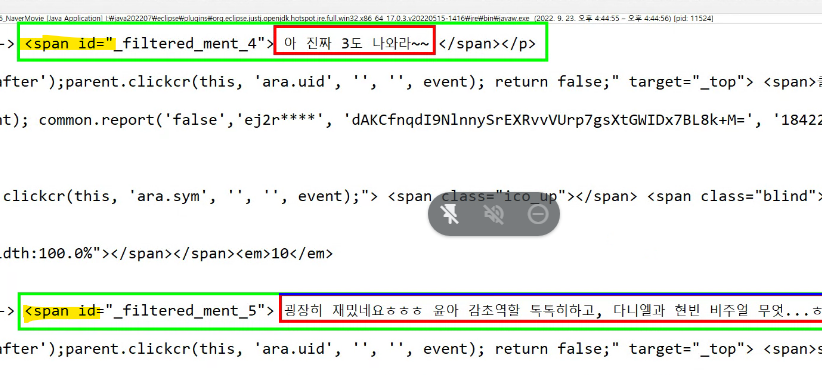
↳ span 태그로 감싸져있고 span안에 있는 빨간 칸 내용이 제목을 처리되어 있다.

↳ id값으로 주었고 뒤에 숫자를 붙여서 일련번호를 지정해줬다.
↳ 최종적으로 이렇게 구성되어있는 것이다.
↳ 뒤에있는 숫자를 변수처리를 해주면 댓글을 모두 가져올 수 있다.
두번째 방법
1) 태그 분석
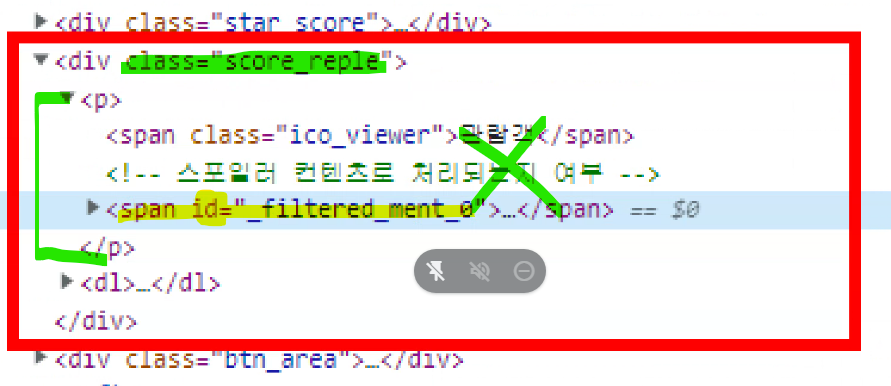
↳ class 태그로 가져올 수 있다. (원래는 id로 가져왔음)
↳ class 태그 score_reple로 가져오면 remove()함수로 관람객을 제거해주면 똑같이 값을 가져올 수 있다.

↳ score_reple을 가져오고, ico_viewer를 제거해주면 똑같은 결과를 도출할 수 있다.
2) 결과

Test07_NaverMovie
네이버 영화 평점 후기 크롤링하기
"공조2" 영화 평점 제목을 공감순으로 정렬 후 크롤링하기 (대량건)
1) 파일출력을 위한 객체 생성
- 맨위

- 맨뒤 (자원반납? 암튼 닫아주기)

2) 평점 url 크롤링 후 변수에 저장

↳ 마지막 &page=부분의 뒤에있는 페이지 숫자는 입력하지 않아야 한다.
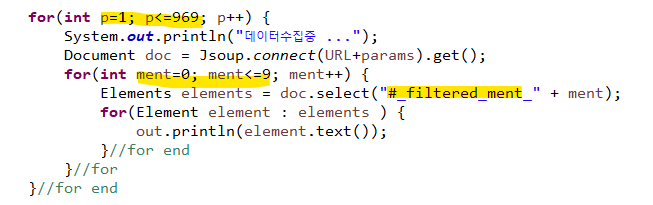
3) 모든 페이지 출력하기 위해 for문으로 1-969페이지까지 출력되도록 짠다.