
XML
- 확장 마크업 언어(태그 등을 사용해 데이터의 구조를 명시)로 문서를 인코딩하기 위한 규칙 집합을 정의하는 마크업 언어
- 플랫폼 독립적이기 때문에 다른 플랫폼 간에 데이터 교환에 사용
- 태그로 데이터를 설명할 수 있다
- 텍스트 기반의 간결한 데이터
XML 방식으로 데이터를 처리하는 목적
- 정보와 구조를 포함하고 있기 때문에 사람이나 기계 모두 데이터의 의미를 쉽게 이해할 수 있다
- 사용자 마음대로 태그를 정의해서 사용할 수 있다
well-formed XML, valid XML
W3C의 XML 표준 권고안은 문법적인 측면에서 두 가지 종류의 XML 문서를 정의
1. well-formed XML (문법에 맞는 XML 문서)
- XML 문서로서 가져야하는 최소한의 필수 요건을 충족한 XML 문서를 의미
- XML의 모든 구문을 허용하지만
DTD(Document Type Definition)나 스키마를 사용하지 않음 - 필수 요건
- root 요소를 하나만 가져야 한다
- 모든 XML 요소는 종료 태그를 가져야 한다
- 시작 태그와 종료 태그에 사용된 태그 이름이 대소문자까지 일치해야 한다
- 모든 XML 요소의 여닫는 순서가 지켜져야 한다
- 모든 속성의 속성값이 따옴표로 둘러싸여 있어야 한다
- valid XML (유효한 XML 문서)
- well-formed XML을 더 엄격하게 검증한 문서
- DTD를 가지고 있으며 그에 따라 제대로 검증된문서
DTD스키마: XML이 다른 마크업 언어를 만들기 위해 해당 언어에 필요한 요소와 속성을 파악해야 하는데, 이러한 정보들의 집합DTD는 문서 타입 정의라는 뜻으로 XML 문서의 구조 및 해당 문서에서 사용할 수 있는 적법한 요소와 속성을 정의한다<!DOCTYPE food [ <!ELEMENT food (name,type,cost)> <!ELEMENT name (#PCDATA)> <!ELEMENT type (#PCDATA)> <!ELEMENT cost (#PCDATA)> ]> <!-- <food> 요소가 <name>, <type>, <cost> 세 요소를 반드시 포함 -->
XML과 HTML의 차이
- HTML은 HyperText Markup Language로 웹 페이지 및 응용프로그램의 구조를 만들기 위한 마크업 언어
| XML | HTML |
|---|---|
| 사용자가 임의로 태그를 만들 수 있음 | 미리 정의된 태그가 존재 |
| 대소문자를 구분 | 대소문자를 구분하지 않음 |
| 모든 태그를 닫아야 함 | 일부 태그에 닫는 태그가 없음 |
| 정보 전달에 중점 | 데이터 표시에 중점 |
XML과 JSON의 차이
JSON과 XML의 공통점
- 데이터를 저장하고 전달할 수 있다
- 기계뿐만 아니라 사람이 읽을 수 있다
- 계층적 데이터 구조를 가진다
| XML | JSON |
|---|---|
| 비교적 구문이 긺 | 비교적 구문이 짧음 |
| 배열을 사용할 수 없음 | 배열을 사용할 수 있음 |
| 모든 태그를 닫아야 함 | 닫는 태그가 없음 |
| XML DOM을 사용해 문서에 접근 | 문자열을 바로 파싱해 처리 속도가 빠름 |
<employees>
<employee>
<firstName>John</firstName> <lastName>Doe</lastName>
</employee>
<employee>
<firstName>Anna</firstName> <lastName>Smith</lastName>
</employee>
<employee>
<firstName>Peter</firstName> <lastName>Jones</lastName>
</employee>
</employees>{
"employees":[
{ "firstName":"John", "lastName":"Doe" },
{ "firstName":"Anna", "lastName":"Smith" },
{ "firstName":"Peter", "lastName":"Jones" }
]
}XPath
XML문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어/를 활용해 요소를 연결하며 작성- 속성은
@를 사용해서 표현
/html/body/div/span[@class='regular_price']DOM 파서
- XML, HTML 문서를 해석해 결과를
DOM(Document Object Model)이라는 객체 트리 구조로 생성
DOM 파서의 HTML 문서 분석
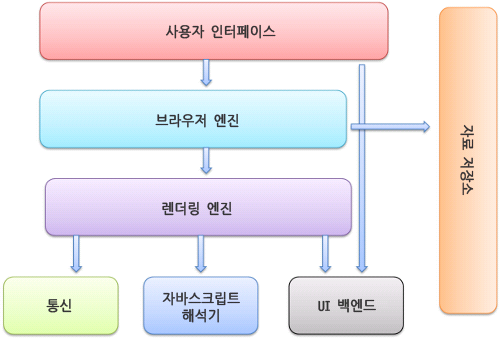
사용자 인터페이스: 요청한 페이지를 보여주는 창을 제외한 주소 표시줄, 뒤로가기 등의 부분브라우저 엔진: 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어렌더링 엔진: 요청한 콘텐츠를 표시통신: HTTP 요청과 같은 네트워크 호출UI 백엔드: 콤보 박스 창 같은 기본적인 장치를 그림자바스크립트 해석기: 자바스크립트 코드를 해석하고 실행자료 저장소: 자료를 저장하는 계층
렌더링 엔진
- 요청받은 내용을 브라우저 화면에 표시
- DOM 트리 구축을 위한 HTML 파싱 → 렌더 트리 구축 → 배치 → 그리기
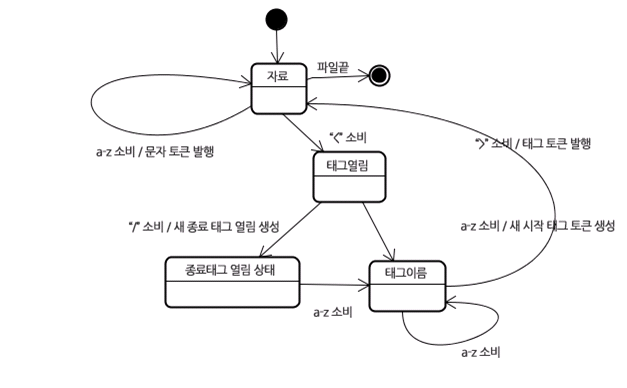
- 토큰화 진행 시 상태 변화
- 초기 상태는 자료 상태
<문자를 만나면 태그 열림 상태
3-1.a-z문자를 만나면 시작 태그 토큰을 생성 → 태그 이름 상태
3-2./문자를 만나면 종료 태그 토큰 생성 → 태그 이름 상태>문자를 만나면 다시 자료 상태로 바뀜
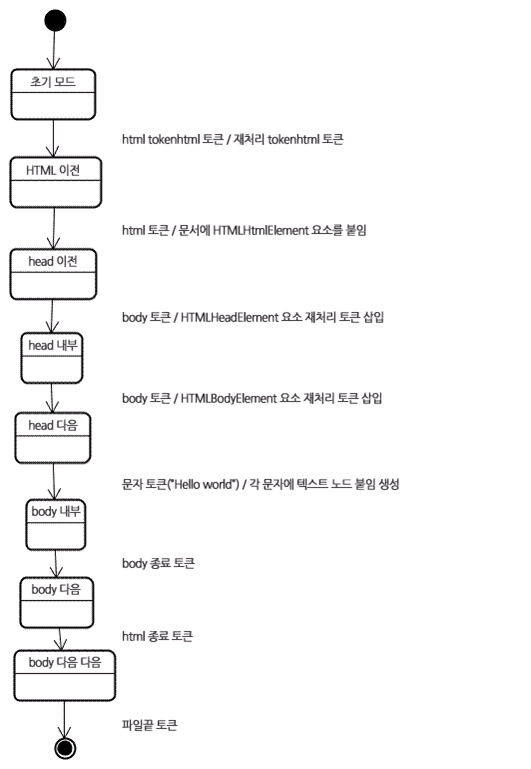
- HTML 트리 구축 예제
Tokenizer, Lexer, Parser
Tokenizer
- 의미있는 요소들을 토큰으로 쪼개는 역할
- 일반적인 token의 종류
identifier: 식별하기 위한 이름 (예시.HTML,BODY)keyword: 미리 지정한 예약어seperator: 글자를 구분하는 문자 (예시.<,>,[,],,)operator: 연산을 위한 심볼 (예시.+,<,=)literal: 숫자, 논리, 문자 (예시.true,NULL)comment: 줄 또는 블록 코멘터리 (예시.<!comment>)
Lexer
- 토큰의 의미를 분석하는 역할
Parser
- 토큰화된 데이터를 구조적으로 나타내는 역할
AST (Abstract Syntax Tree)
- parse tree 중 필수적인 정보만 담은 tree
- parse tree를 축약한 것일 뿐 parse tree와 동일한 정보를 가짐
참고자료
https://d2.naver.com/helloworld/59361
http://www.tcpschool.com/xml/xml_basic_document
