
안녕하세요, K-ROAD 6기 주지윤입니다.
저는 NVIDIA에서 발표한 Alpamayo-R1 논문을 간단하게 리뷰하도록 하겠습니다.
Alpamayo-R1은 이후 CES 2026에서 공개된 NVIDIA의 자율주행 연구 플랫폼 / 개방형 자율주행 포트폴리오 Alpamayo 1의 기반이 되는 모델이기도 합니다.
1. 본 논문에 대해
Alpamayo-R1은 NVIDIA가 CES 2026에서 발표한 차세대 자율주행 포트폴리오의 핵심 모델로, 이번 CES에서 제시된 ‘물리적 AI(Physical AI)’ 비전이 실질적으로 구현된 사례라 할 수 있습니다. 물리적 AI는 디지털 환경에 국한되지 않고 실제 물리적 세계와 직접 상호작용하며 스스로 판단하고 행동하는 지능형 시스템을 의미하며, 이는 Alpamayo-R1이 기존 자율주행 모델과 구별되는 핵심 배경이 됩니다.
기존의 엔드투엔드(End-to-End, E2E) 자율주행 방식이 대규모 주행 데이터의 입력–출력 매핑에 주로 의존해 왔으며, 그 과정에서 모델의 판단 근거가 명시적으로 드러나지 않는 한계가 있었습니다. Alpamayo-R1은 이러한 한계를 넘어, 주행 상황에 대한 판단 근거를 논리적으로 설명할 수 있는 ‘추론 기반 자율주행’이라는 새로운 패러다임을 제시했습니다. 더 나아가 NVIDIA는 자율주행 연구를 위한 모델과 데이터셋, 시뮬레이션 환경을 오픈 소스로 공개하며 단순한 기술적 성과를 넘어 연구 생태계 전반의 표준을 주도하려는 전략을 분명히 했습니다.
2. 들어가며
자율 주행 시스템의 발전은 End-to-End 주행 프레임워크로의 패러다임 전환을 겪고 있으며, 이러한 전환은 업계에서 점차 수용되고 있습니다. 기존의 End-to-End 자율주행 모델은 모방 학습을 통해 방대한 데이터를 학습하며 고속도로 및 정상적 주행 환경에서는 상당히 발전했습니다.
그러나 데이터가 적어 생소한 상황 등과 같은 경우에서는 모델이 단순히 현상을 따라 할 뿐, 왜 그런 행동을 해야 하는지 구체적인 근거를 내리지 못하여 안정적인 의사결정이 어렵다는 문제가 남아 있었습니다.
NVIDIA는 이러한 문제를 해결하기 위해 Vision-Language-Action(VLA) 모델인 Alpamayo-R1을 제안했습니다. Alpamayo-R1은 추론과 행동 예측을 통합적으로 설계하여, 기존 방식보다 드문 상황에서도 안전한 의사결정 능력의 향상을 보여 줍니다. 이 모델은 자동차가 단순히 길을 따라가는 것을 넘어, 주변 상황을 분석하고 인과관계에 따라 추론한 뒤 최적의 경로를 생성합니다.
이 논문은 추론 기반 의사결정을 통해 더 안정적인 주행 계획을 생성하는 것을 목표로 인지와 판단을 연결하는 새로운 학습 구조를 제안합니다.
3. 연구 목표와 배경
3.1 기존 자율주행의 한계
기존의 End-to-End 자율주행 모델은 방대한 데이터 학습을 통해 발전해 왔으나, 다음과 같은 고질적인 문제를 안고 있습니다.
- 데이터 의존성: 학습 데이터가 풍부한 일반적인 상황에만 편중된 성능을 보임
- 블랙박스 문제: 특정 행동을 선택한 논리적 근거를 설명하기 어려움
- 롱테일(Long-tail) 시나리오 취약성: 인과 관계 이해의 부재로 인해 희귀하고 위험한 상황에서 판단이 부정확함
3.2 추론과 행동의 유기적 결합
본 연구는 단순한 모방 학습의 한계를 넘어, 해석 가능한 추론과 정밀한 제어를 결합하여 Level 4 자율주행의 실질적인 구현을 목표로 합니다. 구체적인 목표는 다음과 같습니다.
- 추론 능력의 격차 해소
- 대형 언어 모델(LLM)의 추론 능력을 도입하여, 차량이 행동을 취하기 전 언어 공간 내에서 대안적 결과를 탐색하고 실시간 안전 검증을 수행하도록 합니다.
- 인과 관계에 근거한 의사결정
- 단순한 상황 묘사를 넘어, 관찰된 증거(인과 요인)를 구체적인 주행 결정과 '인과적'으로 연결하는 구조화된 추론 체계를 구축합니다.
- 범용적인 자율주행 정책 수립
- 논리적 추론(Reasoning)이 궤적 생성(Action)의 조건이 되는 모듈형 아키텍처를 통해, 미지의 시나리오에서도 강건하게 대응할 수 있는 지능형 주행 의사결정 체계(정책)를 완성합니다.
4. 핵심 요소
Alpamayo-R1은 다음의 세 가지 요소를 제시합니다.
1) 모듈형 추론 VLA(Vision-Language-Action) 아키텍처
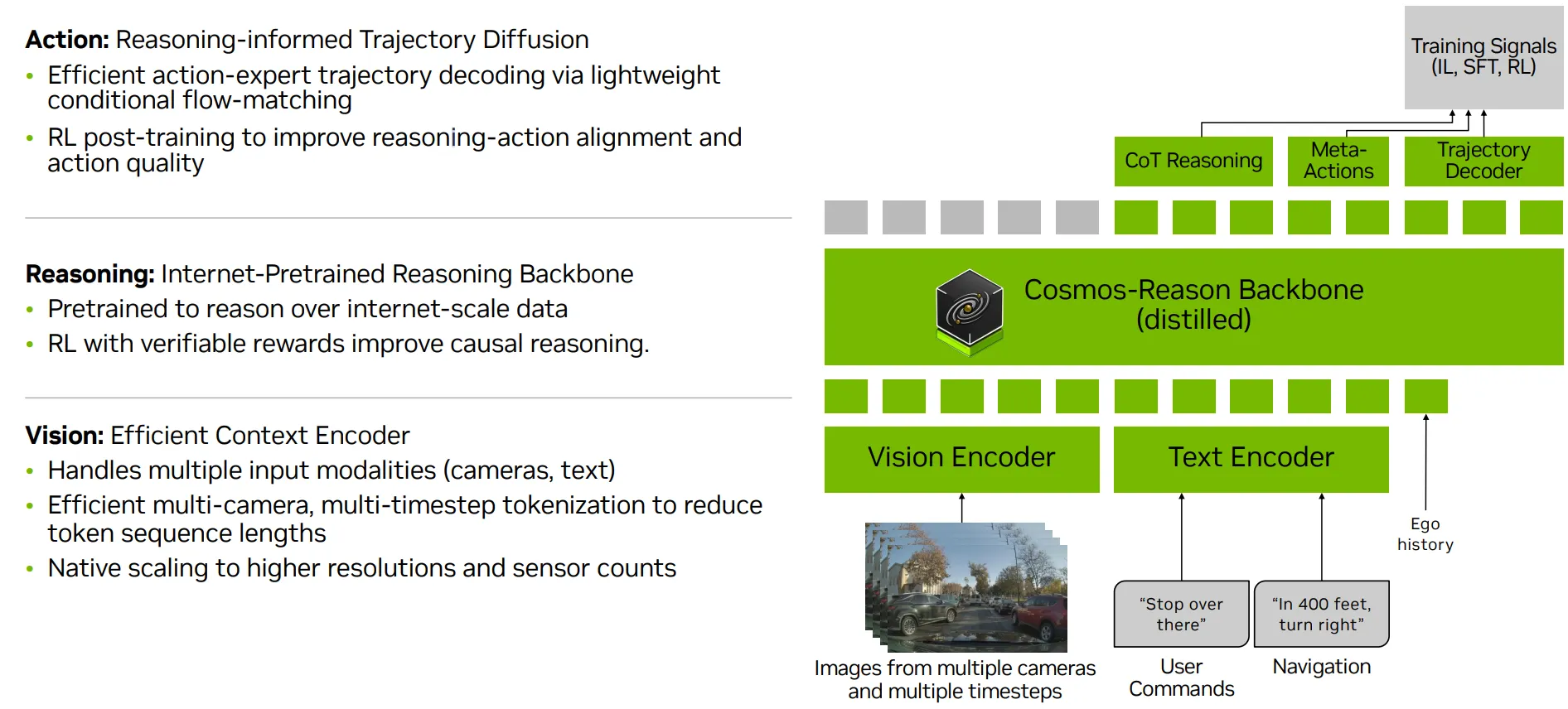 |
|---|
| Alpamayo-R1 아키텍처 개요. 다중 카메라 이미지와 에고-모션(자차 거동 데이터)는 시각적 토큰을 산출하는 비전 인코더에 의해 처리되고, 그것들은 텍스트 입력과 함께 VLM 백본에 입력된다. 모델은 자기회귀적으로 사고 사슬(chain-of-thought) 추론과 이산 경로 토큰을 생성한다. 추론 시, flow matching을 사용하는 행동 전문가 디코더는 추론 결과에 따라 이산 경로 토큰을 연속적이고 운동학적으로 실행 가능한 waypoint로 변환한다. |
- 비전 인코더(Vision Encoder)
- 단일·다중 카메라 및 비디오 토큰화 전략으로 입력 데이터를 압축합니다.
- 사후 토큰 가지치기(Token Pruning) 등의 기법을 추가해 온보드 실시간 추론을 위한 연산 효율을 극대화했습니다.
-
VLM 백본(Backbone): NVIDIA의 Cosmos-Reason
→ 시각 정보 + 텍스트 기반 추론 생성
- 물리적 상식과 주행 시나리오를 사전 학습한 모델로, 주행 환경에 대한 깊은 물리적 이해와 구체화된 추론 능력을 확보했습니다.
- 범용 VLM을 “자율 주행” 환경에 적용하기 위해 실시간성(Latency)과 정밀 제어 능력을 강화하는 최적화 과정을 거쳤습니다.
-
행동 전문가(Action Expert): Diffusion-based action-expert trajectory decoder
→ 실제 주행 가능한 궤적 생성
- 센서 노이즈에 강한 유니사이클 역학(Unicycle Dynamics)과 Flow Matching 기반의 행동 전문가를 결합했습니다.
- 추론된 결과를 바탕으로 물리적으로 실현 가능한 부드러운 다중 모드 궤적을 실시간으로 생성합니다.
2) Chain of Causation(CoC) 데이터셋
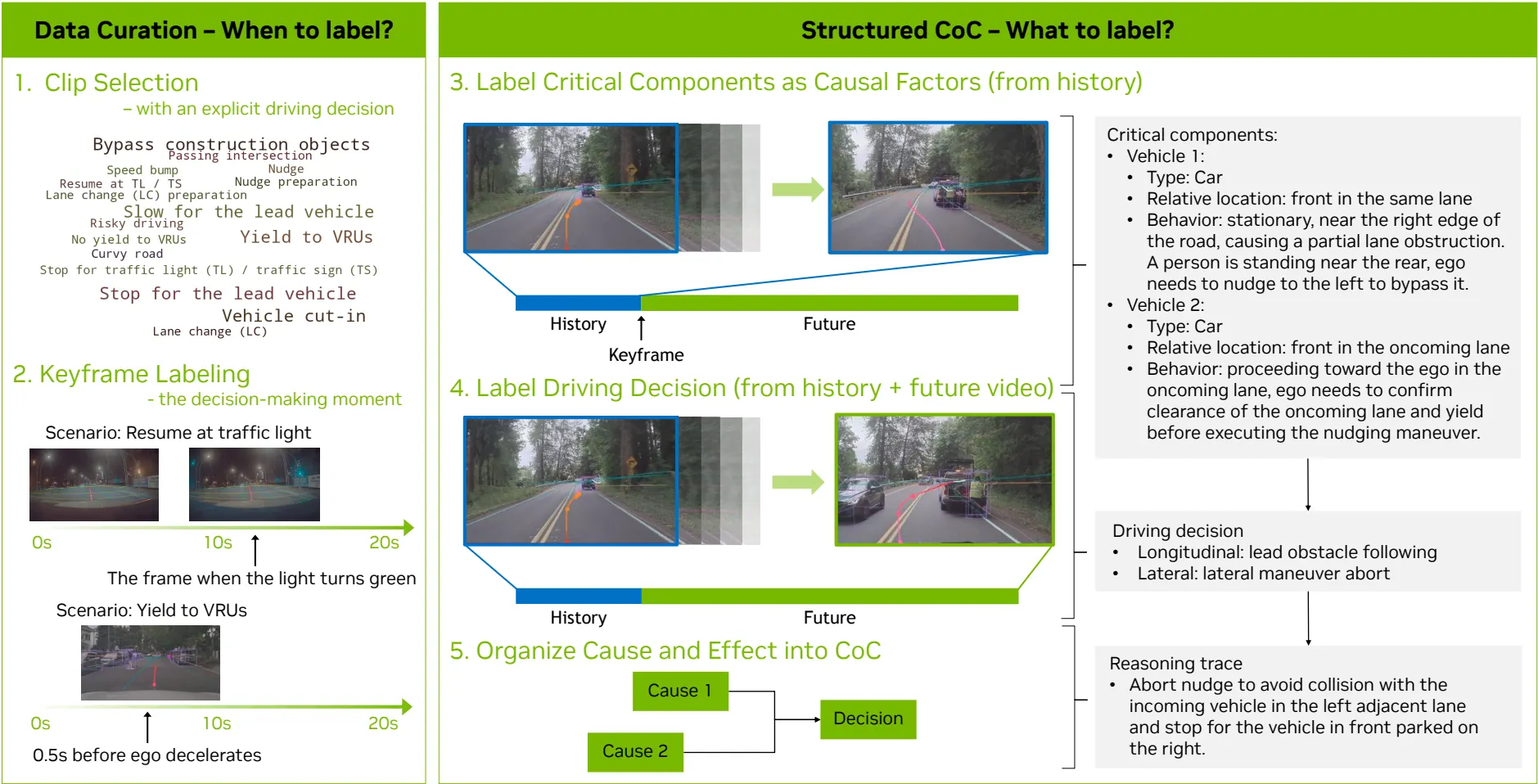 |
|---|
| 제안된 구조화된 CoC 레이블링 파이프라인. (1) 클립 선별, (2) 중요프레임 레이블링, (3-5) 구조화된 CoC 레이블링의 단계로 구성되어 있다. |
- 구조화된 인과 관계 사슬
- 상황 → 이유 → 행동의 인과 관계를 주행 결정, 인과 요인, 최종 추론 텍스트로 구조화했습니다.
- 주행 결정보다 과거에 관측되었으며, 인과적 근거가 분명하고, 주행 결정에 직접적 영향을 준 인과 요인들만 주행 결정과 연결해 추론하도록 했습니다.
- 데이터 큐레이션
- 클립 선별
- 명확한 주행 결정이 포함된 클립을 선별했습니다.
- 주변 환경에 즉각 대응하는 반응적 상황과 미리 대비하는 능동적 상황을 균형 있게 구성하여 데이터의 다양성을 확보했습니다.
- 중요 프레임 레이블링
- 모델이 ‘미래 정보를 미리 아는’ 등의 인과적 혼란을 방지하기 위해 주행 결정이 일어나는 정확한 시점(Keyframe) 또는 시간 범위(Range)를 선정했습니다.
- 클립 선별
- 하이브리드 레이블링 절차
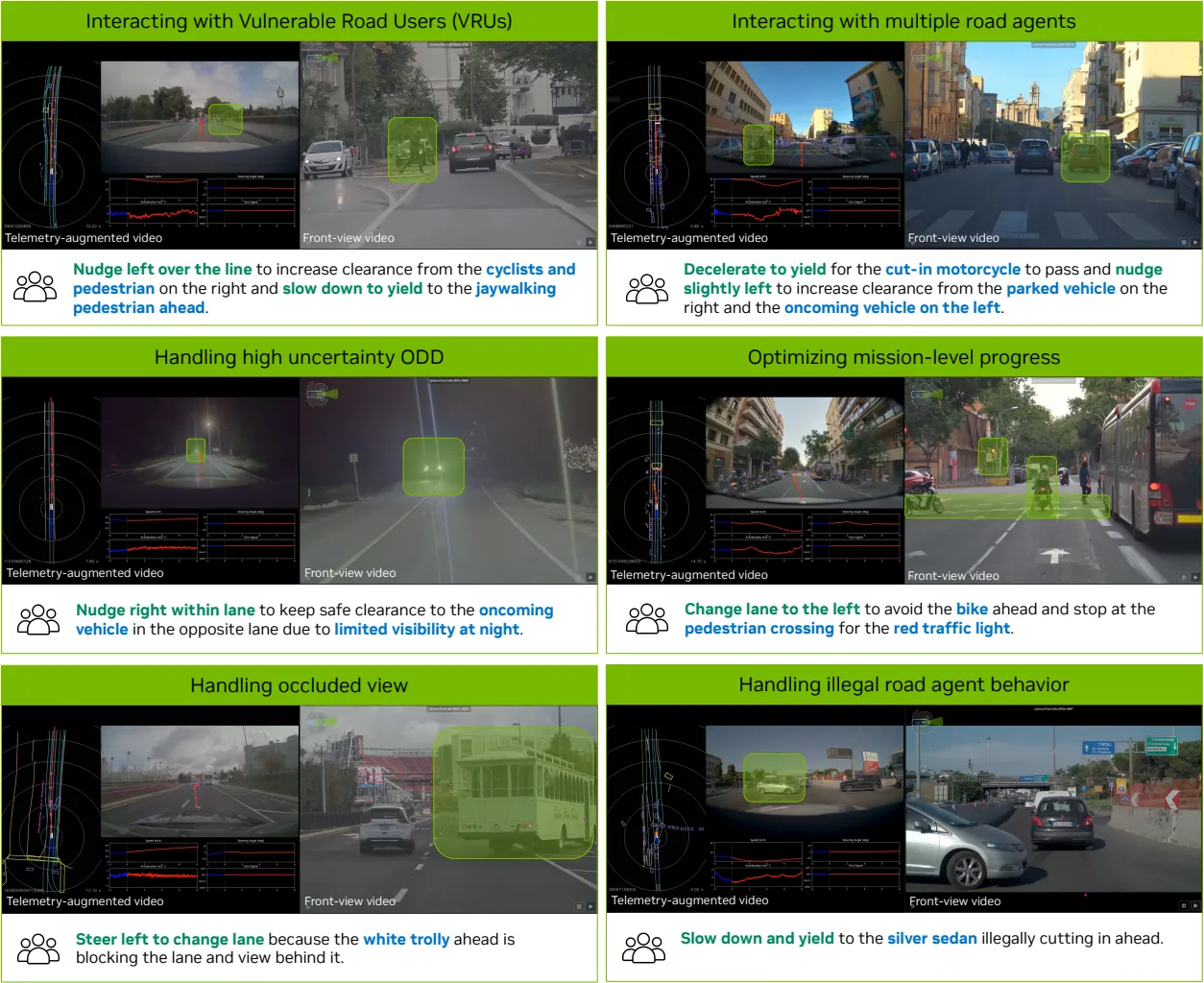 |
|---|
| 주행 결정과 중요 요소(인과 요인)가 CoC로 구조화되고, 상응하도록 강조되어 있는 레이블된 CoC 추론 자취(CoC reasoning traces)의 예시들 |
- 자동 레이블링과 사람의 검수가 결합된 hybrid auto-labeling and human-in-the-loop pipeline을 구축했습니다.
- 텍스트 유사도만 따지는 기존 지표 대신, 주행 결정과 인과관계의 타당성을 True/False 질문으로 평가하는 혁신적인 LLM 기반 평가법을 도입했습니다.
3) Multi-stage 학습 전략
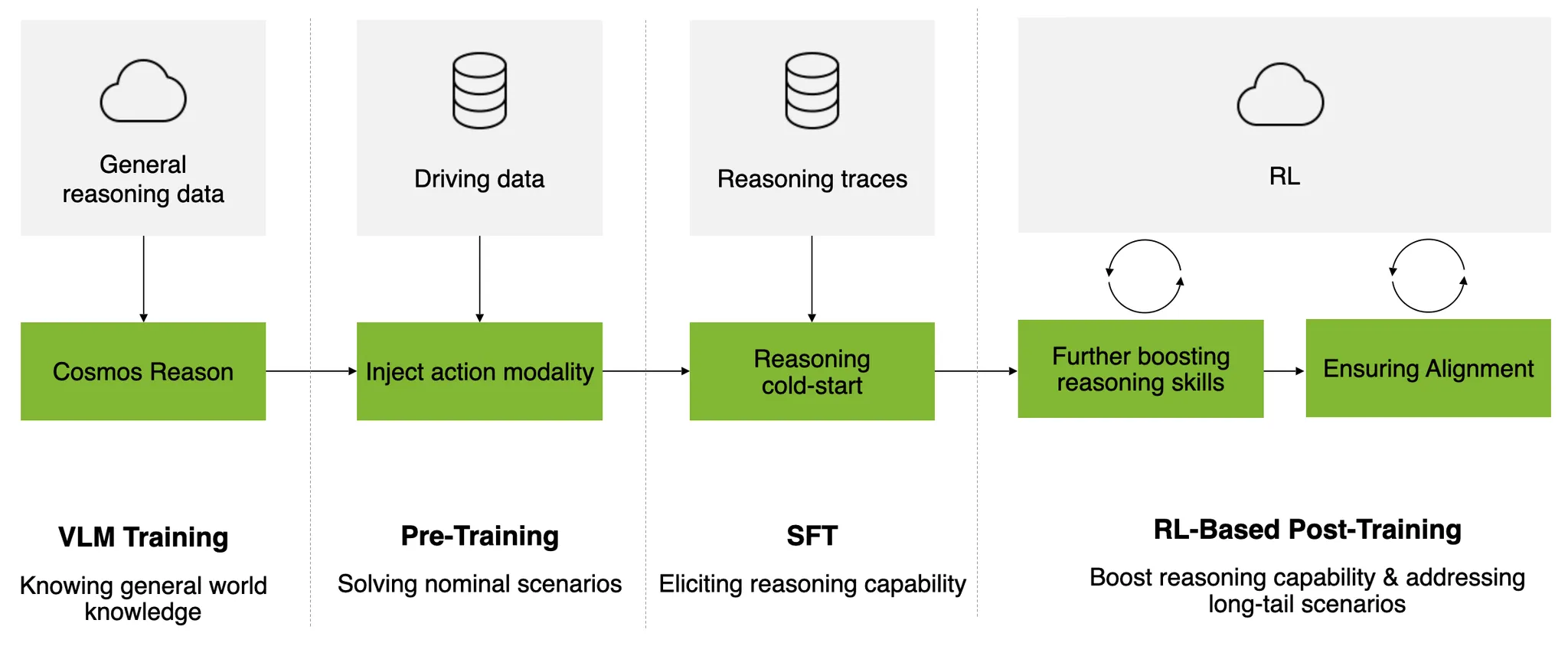 |
|---|
| Alpamayo-R1 모델 훈련 파이프라인 개요. (1) 행동 Modality 투입, (2) 추론 유도, (3) 강화학습 기반 사후 훈련의 주요 세 단계로 이루어져 있다. |
- 행동 모달리티 주입
- VLM이 “가속”, “정지” 같은 운전 결정을 이해할 수 있도록 이산(Discrete) 토큰과 연속적인 Flow-matching 디코더를 결합하여 행동 모달리티를 주입했습니다.
- 이를 통해 모델이 운전 동작을 실제 도로에서의 매끄러운 주행으로 변환하게 됩니다.
- 추론 유도
- 구축된 CoC 데이터셋으로 지도학습 기반 파인 튜닝(Supervised Fine-Tuning, SFT)을 수행하여,
모델이 주행 결정을 한 이유를 관측 정보에 근거해 설명하도록 학습시켰습니다.
- 구축된 CoC 데이터셋으로 지도학습 기반 파인 튜닝(Supervised Fine-Tuning, SFT)을 수행하여,
- 강화학습 기반 사후 훈련
- 지도학습의 한계를 넘어, 생성된 주행 결과를 평가하는 보상 신호를 활용해 추론의 질(reasoning quality)과 행동의 일관성(action consistency)을 동시에 개선했습니다.
 |
|---|
| AR1의 강화학습 기반 사후 훈련 프레임워크 개관. 저자는 모델이 생성한 추론 과정과 예측된 행동을 정렬하기 위해 세 가지 보상 요소들을 최적화했다: 추론의 질 (대형 추론 모델 피드백을 통해), 추론-행동 일관성, 경로의 질. |
- 사후 훈련 알고리즘
- 상대적인 보상을 최적화하는 GRPO 알고리즘을 사용하여 편향된 보상 신호에 빠지지 않고 안정적으로 모델을 정렬했습니다.
- 보상 모델
- 추론의 논리성(LRM 피드백), 추론과 실제 행동의 일치도, 궤적의 물리적 안전성(충돌 및 승차감)을 종합한 보상 체계를 구축했습니다.
- 비용 효과적 훈련을 위한 사후훈련 데이터 큐레이션
- 모델의 예측과 보상 시스템이 충돌하는 '정보 가치가 높은' 샘플을 우선적으로 학습하여 훈련 비용을 줄이고 효율을 높였습니다.
- 사후훈련 인프라구조
- 대규모 분산 학습과 실시간 보상 계산이 가능한 NVIDIA의 Cosmos-RL 프레임워크를 기반으로 인프라를 구축했습니다.
5. 성능 요약
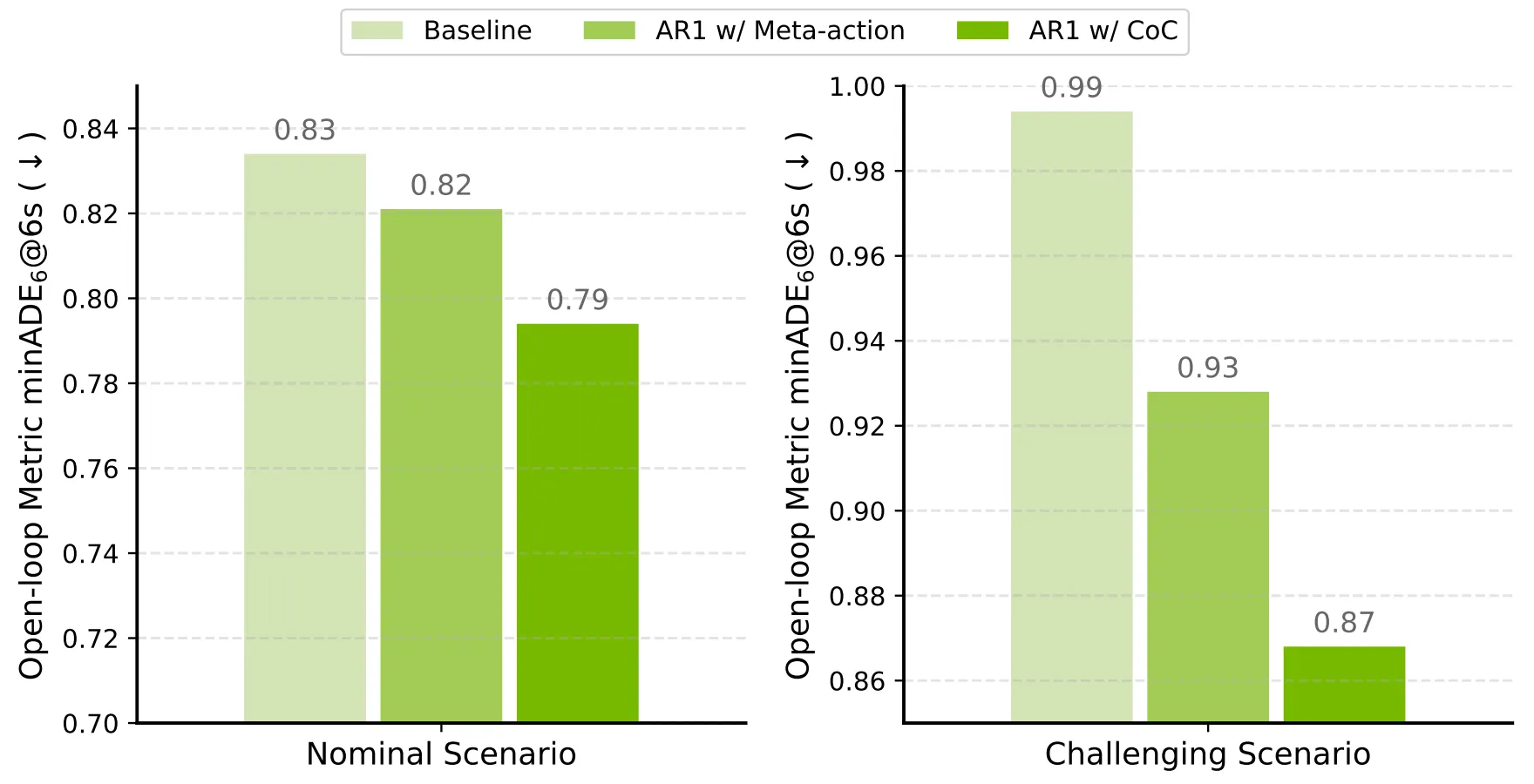 |
|---|
| 경로만 출력하거나 메타행동&경로만 출력하는 모델에 비해, Alpamayo-R1은 일반적인 시나리오와 도전적인 시나리오 모두 발전을 보였다. |
논문에서 보고된 주요 성능 결과는 다음과 같습니다
| 평가 항목 | 성능 결과 및 향상 폭 | 기존 모델 비교 | 비고 |
|---|---|---|---|
| 주행 계획 정확도 | 최대 +12% 향상 | Trajectory-only (경로 전용 모델) | 고난도 시나리오 기준 |
| 근거리 충돌률(Close encounter rate) | 상대적 -35% 감소 | Trajectory-only (경로 전용 모델) | 17% → 11%로 감소 |
| RL 후 추론 품질(Reasoning quality) | +45% 개선 | SFT (지도 학습) 전용 모델 | LRM(거대 추론 모델) critic 기준 |
| RL 후 논리-행동 일관성(Consistency) | +37% 개선 | SFT (지도 학습) 전용 모델 | 추론-행동 일치 점수(0.62→0.85) |
| 추론 지연 시간(Latency) | 약 99 ms | - | RTX 6000 Pro Blackwell 하드웨어, 실차 배포(On-vehicle) 환경 |
이 결과는 롱테일(Long-tail) 상황에서 AR1이 더 안전하고 안정적인 의사결정을 할 수 있음을 보여줍니다.
6. 결론 및 시사점
Alpamayo-R1의 중요한 의미는 다음과 같습니다
- 주행 결정과 정합된 자연어 추론을 함께 생성하는 자율주행 접근법 제시
- 추론과 주행 계획을 공동으로 생성하는 아키텍처 설계
- 희귀·안전 중요 상황에서의 의사결정 성능 개선
- NVIDIA가 이 모델과 데이터셋 일부를 오픈소스로 공개한 만큼, 자율주행 연구 생태계 전반에 영향을 미칠 가능성 제시
End-to-End 프레임워크로의 패러다임 전환이 본격화된 지 그리 오래되지 않았음에도 거기서 더 나아가 추론을 중심에 둔 주행 결정이라는 새로운 방향성을 제시하고 있습니다.
참고자료
- Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
NVIDIA, arXiv:2511.00088 (2025) - https://www.nvidia.com/en-us/solutions/autonomous-vehicles/alpamayo/
- https://blogs.nvidia.co.kr/blog/2026-ces-special-presentation/
- https://blogs.nvidia.co.kr/blog/alpamayo-autonomous-vehicle-development/
- https://developer.nvidia.com/blog/building-autonomous-vehicles-that-reason-with-nvidia-alpamayo/
- https://huggingface.co/nvidia/Alpamayo-R1-10B
- https://github.com/NVlabs/alpamayo
