안녕하세요, KROAD의 원윤재입니다. Kalman Filter를 학습하는데 많은 도움이 됐었던 "칼만 필터는 어렵지 않아 - 김성필" 라는 교재를 리뷰해보려고 합니다.
위 교재는 Kalman Filter 이외에 LPF, 평균, 이동 평균과 같이 기본적인 필터 부터 EKF 까지 쉽게 다루는 교재기 때문에 처음 KF를 접해보시는 분들께 추천드립니다 !
KALMAN FILTER란 ? ( by KALMAN FILTER는 어렵지 않아 )
칼만 필터 개요
책을 정독하지 않고, 추측항법으로 터널 내 차량의 위치를 파악하는 코드를 작성하다가, 칼만필터에서 오차 공분산 행렬에서 값이 너무 튀어 UTM 값이 제대로 나오지 않아 칼만필터를 깊게 공부해보고자 리뷰를 시작했습니다.
루돌프 칼만이 만들어낸 제어 기법인 칼만필터,
복잡한 수식을 하나하나 뜯어보기 보다는 이해할 수 있을 정도로만 해석을 하고자 합니다.
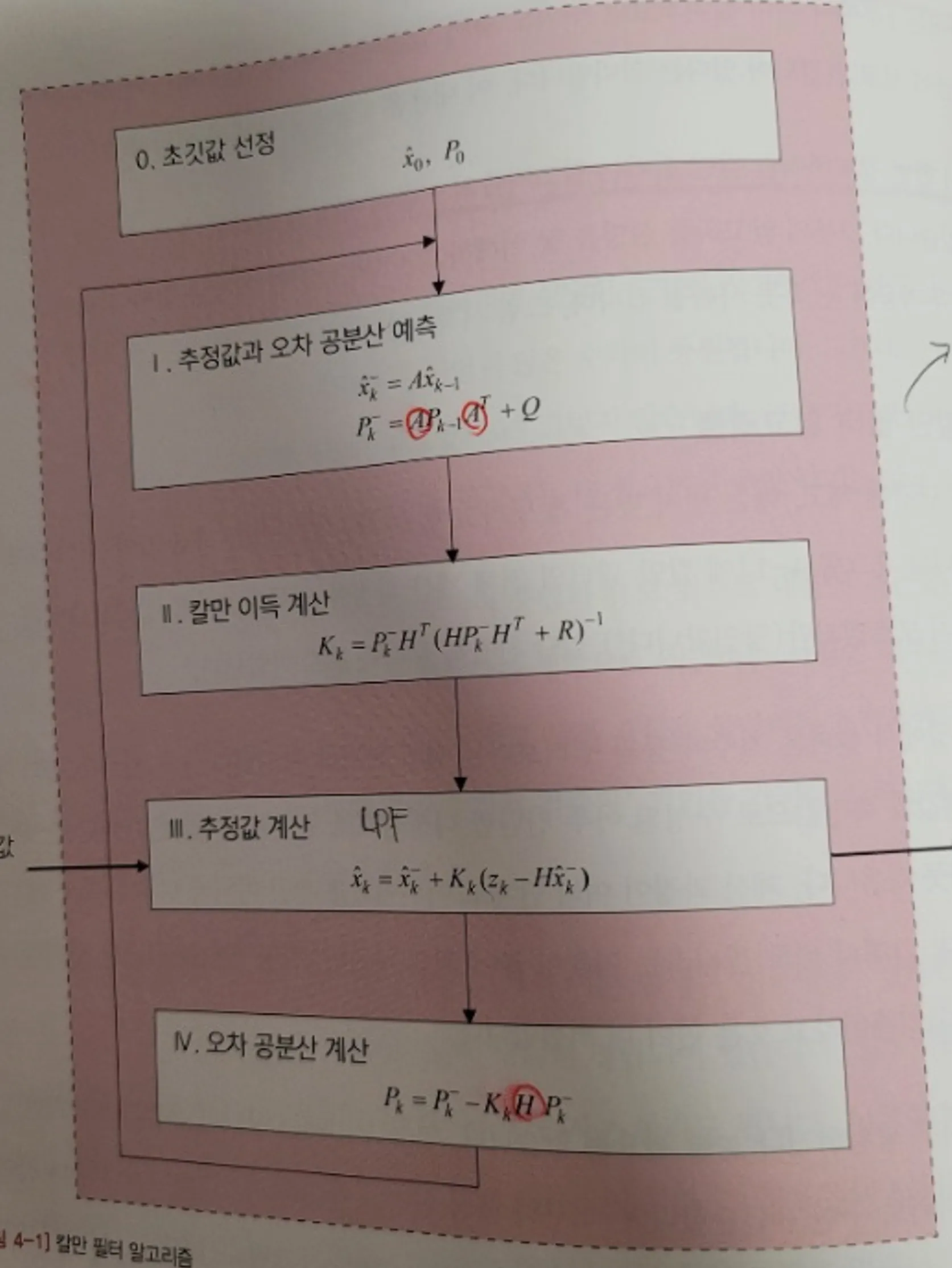
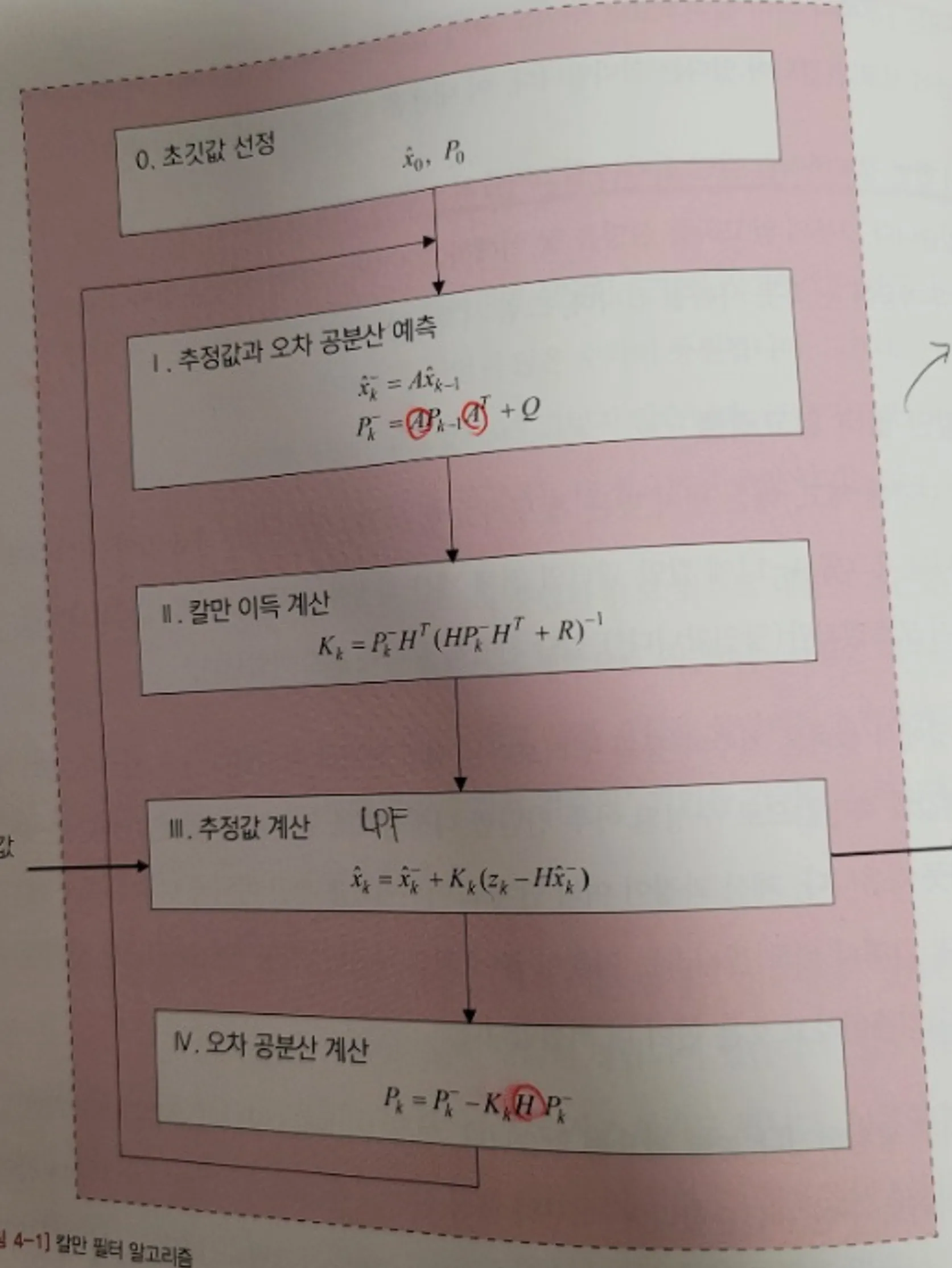 <칼만 필터는 어렵지 않아 , 칼만 필터 알고리즘 > <칼만 필터는 어렵지 않아 , 칼만 필터 알고리즘 > |
|---|
점선으로 표시된 부분이 칼만필터 알고리즘입니다.
출력에 대한 입력이 하나씩인 구조로, 측정값이 입력되면 내부에서 처리한 다음 추정값을 출력합니다.
k는 반복해서 칼만필터 알고리즘 수행이 이루어진 다는 의미의미로 유의 깊게 볼 필요가 없으나, 위첨자 ‘ㅡ’는 이름이 같더라도 전혀 다른 변수를 의미하기에 중요합니다.
* 알파벳 위에 ‘ㅡ’ 는 ‘추정값’ 이라는 의미, K는 현재 스텝, K-1 은 과거 스텝우선, 간단하게 칼만 필터 알고리즘의 흐름을 얘기해보면 다음과 같습니다.
시스템 모델 (A,Q)를 기초로 다음 스텝에서 상태와 오차 공분산이 어떻게 될지 예측
측정값과 예측값의 차이를 보정해서 새로운 추정값 계산, 이 추정값이 최종 결과물
1, 2를 반복
쉽게 말해서,
- 이전 단계에서의 결과값이 다음 스텝에서의 초기값으로 돌아오는 Recursive한 형태
- <예측 과정> OUTPUT : (직전 추정값), (오차 공분산)
- 추정값과 오차공분산 예측 단계에서 직접 구해야하는 값은 오직 “”. 는 이미 정해져 있는 값. 즉, 이전 값에 를 곱해주고 를 더해주는 산술 영역.
- <추정 과정> OUTPUT : (추정값), (오차 공분산)
- 역시 정해진 로 이전 단계에서 구한 값을 계산.
- 이전에 구한 값() 들과 센서로 측정한 값 ()으로 추정값 계산
- 오차 공분산을 구해 다음 스텝의 (1)에서 이 되는 값.
- 기존에 설정한 시스템 모델
본 교재에서는 칼만필터와 1차 LPF와의 유사함을 언급하는데, 중요한 점은 비교적으로 간단합니다.
위 칼만 필터 알고리즘 개략도에서 칼만 이득 계산 부분에서 계산된 칼만 이득 K는 다음 단계의 추정값 계산 과정에서 가중치로 사용되는데, 이 가중치는 알고리즘을 반복할 때 마다 새로 계산된다는 것입니다. 반면, LPF에서의 가중치는 상수 a로, 칼만 필터와는 달리 재조정되지 않습니다.
칼만 필터 추정
위의 칼만 필터 개요에 적은 바와 같이 칼만필터 알고리즘은 크게 5가지 순서를 반복합니다.
- 이전 단계에서의 결과값이 다음 스텝에서의 초기값으로 돌아오는 Recursive한 형태
- <예측 과정> OUTPUT : (직전 추정값), (오차 공분산)
- 추정값과 오차공분산 예측 단계에서 직접 구해야하는 값은 오직 “”. 는 이미 정해져 있는 값. 즉, 이전 값에 를 곱해주고 를 더해주는 산술 영역.
- <추정 과정> OUTPUT : (추정값), (오차 공분산)
- 역시 정해진 로 이전 단계에서 구한 값을 계산해주면 됨.
- 이전에 구한 값() 들과 센서로 측정한 값 ()으로 추정값 계산
- 오차 공분산을 구해 다음 스텝의 (1)에서 이 되는 값.
이 중에 예측과 추정 과정에 대해서 자세히 다뤄보려고 합니다.
추정 과정에서 중요한 부분은, 마지막에 계산을 통해 구해지는 오차 공분산입니다.
마지막 단계는 오차 공분산을 구하는 단계로, 칼만필터 알고리즘의 정확성의 척도를 나타냅니다.
추정 값 가 크면 추정 오차가 크고, 작으면 추정 오차가 작은 것입니다.
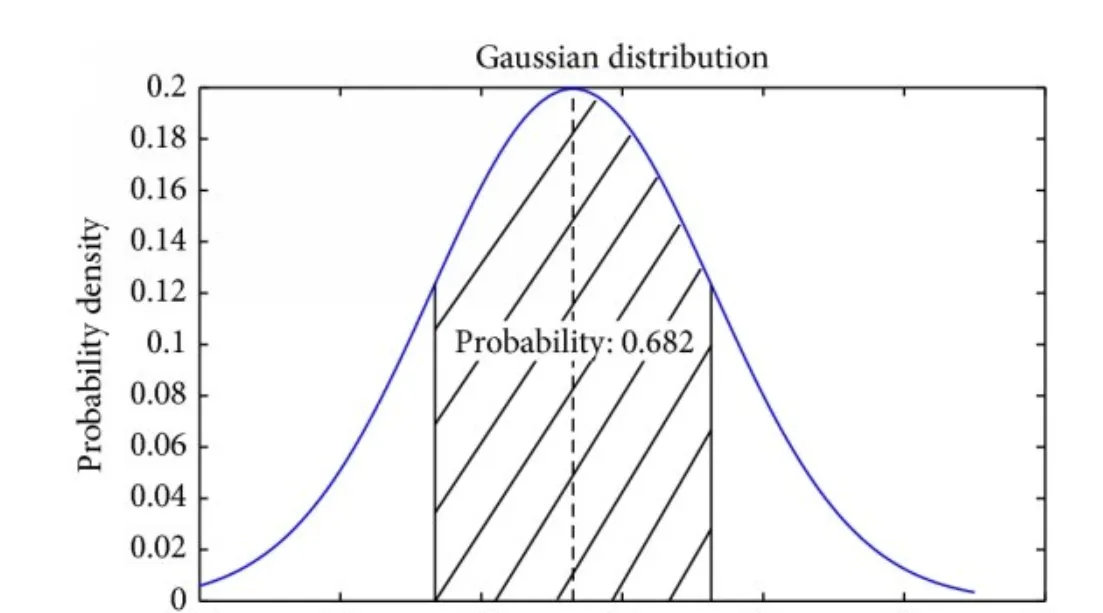
위 수식의 뜻은 가 평균이 이고, 공분산 인 정규 분포를 따른다는 뜻입니다.
 |
|---|
위 그래프의 종 모양의 폭을 가 정하는데, 종 모양의 폭이 좁으면 가 가질 수 있는 값이 대부분 평균 근처에 있다는 뜻이므로 추정 오차가 작게 나타납니다.
칼만 필터 예측
예측이란, 시각이 에서, 로 바뀔 때, 추정값 가 어떻게 바뀌는지를 추측하는 것입니다.
추정값을 예측하는 수식과 오차 공분산을 예측하는 관계식은 다음과 같습니다.
와 는 각각 3단계와 4단계에서 계산한 값입니다. 그리고 와 는 이미 시스템 모델에 정의되어 있습니다. 다른 시스템 모델 변수인 와 은 추정과정에서만, 와 는 예측과정에서만 사용됩니다. 예측값은 위첨자 ‘ㅡ’ 가 붙고, 다음 단계의 값이라는 뜻으로 (+1)이 붙습니다.
이제 칼만 필터에서의 예측과 추정이 어떻게 사용되는지를 보겠습니다.
위 수식은 Low Pass Filter(LPF) 추정값 계산식입니다.
중간에 별도의 단계 없이 새로운 추정값 계산에 직전 추정값 x(-1)을 사용합니다. 즉 k-1 스텝에서 k스텝으로 시간이 이동할 때, 직전 단계의 추정값에 아무런 영향을 주지 않는다는 뜻입니다.
자, 그럼 칼만 필터는 어떤지 한번 보겠습니다.
(1)
칼만 필터 알고리즘 단계 중 3단계에 있는 추정값 계산 단계 식입니다.
직접 추정값 x(-1)은 보이지 않고, 예측값 x(ㅡ)이 존재합니다. 예측값은 첨자 ‘ㅡ’가 존재한다고 했습니다.
그럼 예측값은 뭐로 구하는지 보겠습니다.
예측값은 바로 직전 추정값을 이용해 구하게됩니다.
(2)
(2)번 식을 (1)에 대입합니다.
이제 직전 추정값 이 보입니다.
이처럼 칼만 필터는 1차 LPF(Low Pass Filter)와 달리 추정값을 계산할 때, 직접 추정값을 바로 바로 쓰지 않고, 직전 추정값을 이용한 예측 단계를 한 번 더 거치게 됩니다.
자, 그럼 다시 추정값을 계산하는 (1)식을 들여다 봅니다.
이제 이 추정값 계산 식이 직전 추정값의 예측을 기반으로 이루어진다는 것을 알고 있습니다.
여기서 는 실제 센서를 통해 들어오는 측정값입니다.
는 위에서 보았다 시피, 예측 값으로 계산한 측정값입니다.
그렇다면, 가 의미하는 바는 무엇일까요? 바로 실제 측정값과 예측한 측정값의 차이, 측정값의 예측 오차입니다.
위 글을 토대로 해석하면, ‘칼만필터란, 측정값의 예측 오차로 예측값을 적절히 보정해서 최종 추정값을 계산한다.’라고 할 수 있습니다. 이 때 칼만 이득은, 예측값을 얼마나 보정할지 결정하는 인자가 됩니다.
그런데, 추정값에서 (2)식을 (1)식에 대입한 것을 보면, 시스템 모델링 변수 중에 와 가 필요합니다. 결국 와 를 얼마나 실제 시스템과 가깝게 설계했느냐가 칼만 필터의 성능적인 측면에서 매우 중요하다고 볼 수 있습니다.
시스템 모델링
시스템 모델이란, 우리가 다루는 문제를 수학적으로 표현해 놓은 것입니다.
칼만 필터의 경우 , 다음과 같은 선형 상태 모델을 대상으로 합니다.
(1)
(2)
위 (1), (2) 식의 모델은 잡음이 포함되어 있습니다.
= 상태 변수, (n x 1) 열벡터
= 측정값(센서), (m x 1) 열벡터
= 시스템 행렬 (n x n) 행렬
= 출력 행렬, (m x n) 행렬
= 시스템 잡음, (n x 1) 열벡터
= 측정 잡음, (m x 1) 열벡터
자 그럼, 칼만 필터 알고리즘 수식에서 시스템 모델과 관련이 있는 부분을 찾아봅니다.
첫번째는 , 칼만 필터 개요 토글에 있는 (1) 단계에 있는 추정값 예측식입니다.
이 식은 시스템 모델 수식 (1)에서 유래했습니다.
또다른 부분은 (3)단계에 있는 추정값 계산식입니다.
이 식의 는 시스템 모델 식 (2)와 관련이 있어 보입니다. 두 식을 시스템 모델과 비교했을 때, 잡음 , 가 빠져있을 뿐, 매우 유사해 보입니다.
시스템 모델에서의 잡음 와 는 칼만 필터 알고리즘에서는 공분산 행렬로 사용되고 있습니다.
: (시스템 잡음)의 공분산 행렬, (n x n) 대각 행렬
: (측정 잡음)의 공분산 행렬, (m x m) 대각 행렬
공분산 행렬은 변순의 분산으로 구성된 행렬이다. 예를 들어, 처럼 n개의 잡음이 있고, 각 분산은 시그마라 했을 때 , 다음과 같이 쓸 수 있습니다.
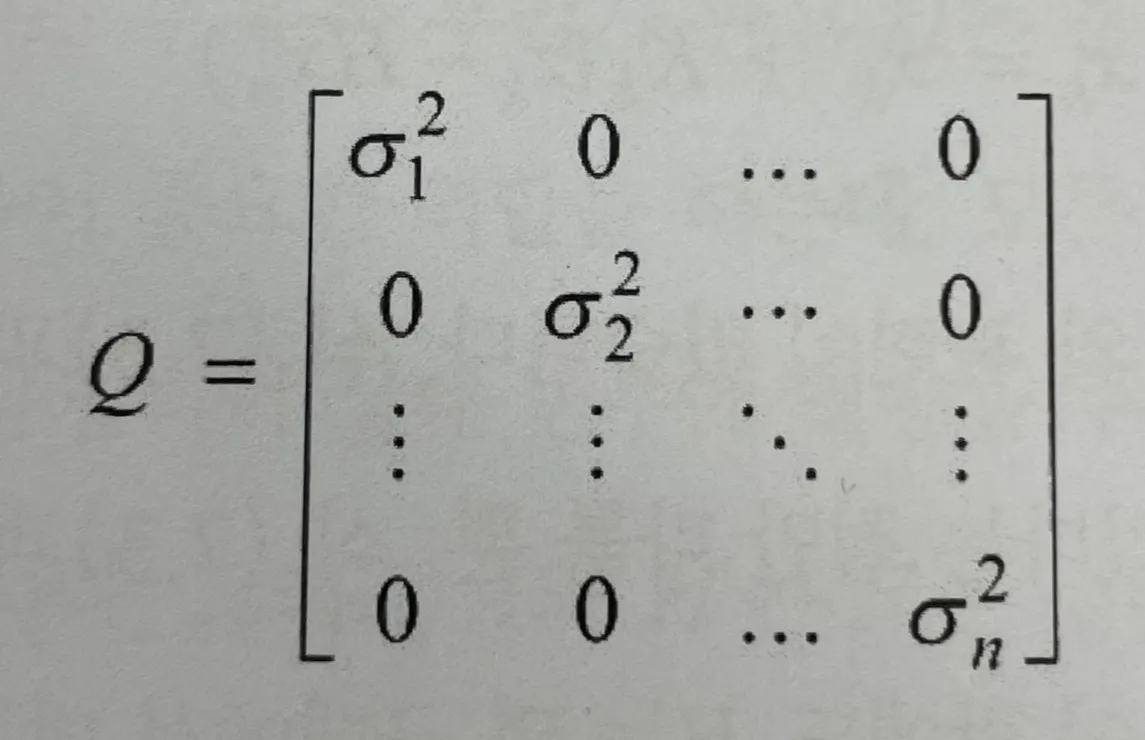
그래서 센서값의 추정값 오차 공분산 행렬 과, 시스템 오차 행렬 를 적절히 조절해가면서 설계를 해야하는데, 어떻게 조절을 하고, 또 와 을 조절했을 때, 칼만필터가 어떻게 달라지는 건지 이해를 해봅시다.
오차 변수 와 을 조절할 때, 칼만 필터가 어떤 물리적 변화를 가지는지 이해 하려면 다시 초반에 언급한 칼만필터 알고리즘의 수식들을 가져와야 합니다.
(2) 칼만 이득 계산 수식을 보면,
뒷부분을 상수라 가정하고 다시 정리를 하면,
은 센서의 오차 공분산 행렬, 즉, 센서의 노이즈입니다.
결국 센서의 노이즈인 이 증가하면, 칼만 이득 는 감소한다. 그럼 칼만 이득이 감소하면 어떤 결과를 불러오는지 보겠습니다.
(3) 추정값 계산
이 수식을 살짝 바꿔보면,
여기서 는 실제 센서를 통해 측정되는 값입니다.
칼만 이득이 감소하면 실세 센서의 측정값 가중치를 낮추고, 이전 추정값의 가중치를 높여주는 꼴입니다.
정리하면,
R(센서의 노이즈) 증가 → 칼만 이득 감소 → 센서의 가중치 감소 && 이전 추정값 가중치 증가
당연한 말입니다. 현재 측정되는 센서의 노이즈가 증가하므로, 센서의 비중을 낮추고, 이전 추정값의 비중을 높여준다는 의미가 됩니다.
그럼 Q(시스템 노이즈)는 어떤 물리적 변화를 가져올까요?
(1) 추정값과 오차 공분산 예측 수식을 보겠습니다.
Q가 증가하면 오차 공분산의 예측값인 가 증가합니다.
위에서 칼만이득 정리한 식을 가져오면,
가 커질수록 칼만이득이 증가합니다.
결국 칼만이득의 증가로, 현재 추정값의 가중치가 작아지고, 센서 추정값의 가중치가 커집니다.
요약하면,
Q(시스템 노이즈)증가 → Kalman gain 증가 → 최종 추정값에 대한 센서의 가중치 증가
이것 역시 당연한 말입니다. 모델과 실제 시스템과의 오차가 클수록, 모델 기반의 추정값의 비중을 작게하고, 실제 센서 추정값의 비중을 올려야 하기 때문입니다.
