from tensorflow.keras.layers import (
Embedding, Dense, Dropout, LayerNormalization, Input,
GlobalAveragePooling1D
)
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import MultiHeadAttentionTransformer는 입력 시퀀스를 순차적으로 처리하지 않고, 전체를 한 번에 병렬로 처리하는 신경망 구조이며, 그 중심에는 Self-Attention이라는 메커니즘이 있다.
Self-Attention은 시퀀스에 포함된 모든 단어가 서로를 직접 참조하면서, 각 단어가 다른 단어를 이해하는 데 얼마나 중요한지를 가중치(Attention Score) 로 계산하는 방법이다.
이 과정에서 Transformer는 단어의 의미를 주변 단어들과의 관계 속에서 다시 표현하며, 단어 간의 거리와 무관하게 장기적인 의존성까지 모두 포착할 수 있다.
즉, Transformer라는 모델은 Self-Attention을 반복적으로 쌓아서 문맥 표현을 만들어내는 구조이고, 이 Self-Attention이 바로 Transformer가 RNN, LSTM보다 더 정확하게 문맥을 이해하고, 병렬 처리로 훨씬 효율적인 모델이도록 만드는 핵심 기술이다.
class TokenAndPositionalEmbedding(tf.keras.layers.Layer):
# Token Embedding
def __init__(self, maxlen, vocab_size, embed_dim):
super().__init__()
self.token_emb = Embedding(vocab_size, embed_dim)
self.pos_emb = Embedding(maxlen, embed_dim)
# Positional Embedding
def call(self, x):
positions = tf.range(start=0, limit=tf.shape(x)[-1], delta=1)
positions = self.pos_emb(positions)
return self.token_emb(x) + positions왜 Positional Embedding이 필요한가?
Transformer는 RNN처럼 단어를 순차적으로(left → right) 처리하지 않는다.
Self-Attention은 문장 전체를 한 번에 병렬 처리하기 때문에, 모델은 입력된 단어들이 문장 안에서 어떤 순서로 등장했는지를 알 수 없다.
즉, Transformer는 기본적으로 단어의 순서 정보를 잃어버리는 구조다.
그래서 “이 단어가 문장에서 몇 번째 위치인가?”를 모델이 학습할 수 있도록
위치 정보(Position Information)를 따로 제공해야 한다.
이 위치 정보를 인코딩하는 구조가 바로 Positional Embedding이다.
Positional Embedding은 한 문장에서 각 단어가 가지는 고유한 위치 정보를
임베딩 벡터 형태로 모델에게 전달한다.
이로써, Transformer가 순서를 기억할 수 있게 된다.
class TransformerBlock(tf.keras.layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super().__init__()
# MultiHeadAttention
self.att = MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim//num_heads)
# Feed Forward Network (FFN)
self.ffn = Sequential([
Dense(ff_dim, activation="relu"),
Dense(embed_dim),
])
self.layernorm1 = LayerNormalization(epsilon=1e-6)
self.layernorm2 = LayerNormalization(epsilon=1e-6)
self.dropout1 = Dropout(rate)
self.dropout2 = Dropout(rate)
def call(self, inputs, training=None):
# Residual Connection + LayerNormalization
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)1. Multi-Head Self-Attention
Self-Attention은 입력 시퀀스의 각 토큰이 문장 안의 모든 다른 토큰과의 관계를 동적으로 계산하도록 하는 메커니즘이다.
각 토큰은 Query(Q), Key(K), Value(V)라는 세 가지 벡터로 변환되며, Query와 Key의 유사도를 통해 다른 토큰이 얼마나 중요한지를 계산하고, 그 가중치를 Value에 반영하여 새로운 표현을 생성한다.
Multi-Head 방식은 이 과정을 여러 개의 head로 병렬 학습하여,
어떤 head는 장거리 의미관계를,
어떤 head는 문법적 구조를,
또 다른 head는 특정 패턴을
각기 다른 관점으로 학습한다.
즉, 토큰 간의 전역 의존성을 여러 시각에서 동시에 캐치하도록 만드는 장치이다.
2. Feed Forward Network (FFN)
Self-Attention이 토큰 간 관계를 학습한다면, FFN은 각 토큰을 독립적으로 비선형 변환하는 역할을 한다.
Transformer의 FFN은 두 개의 선형 변환과 활성화 함수를 포함한 매우 간단한 구조지만, 각 토큰 벡터를 확장 → 압축하는 과정에서 복잡한 비선형 패턴을 학습한다.
중요한 점은 FFN이 시퀀스의 모든 토큰에 동일한 네트워크를 위치별로 독립 적용한다는 것이다.
이를 통해 attention으로 모은 문맥 정보를 다시 한 번 풍부하게 학습할 수 있다.
3. Residual Connection
Residual Connection은 sub-layer의 출력 위에 입력값을 그대로 더해 전달하는 구조이다.
즉,
y=x+F(x)
형태로 값을 전달한다.
이 구조는 두 가지 중요한 효과를 만든다.
-
기울기 소실을 막아 깊은 네트워크에서도 학습이 안정된다.
-
sub-layer가 충분히 학습되지 않았어도 원래 정보가 손실되지 않는다.
Transformer에서는 Self-Attention 뒤, FFN 뒤 두 번 사용되며, 모델 전체의 안정성을 크게 높이는 핵심 요소로 작동한다.
4. Layer Normalization
Layer Normalization(LayerNorm)은 각 토큰 벡터 단위로 평균과 분산을 이용해 정규화하는 방식이다.
BatchNorm과 달리 배치 크기에 영향을 받지 않기 때문에, 시퀀스 모델이나 긴 문장을 처리할 때 훨씬 안정적인 동작을 보인다.
Transformer에서는 residual connection 이후에 항상 LayerNorm을 적용하며, 이를 통해 레이어 출력의 분포를 일정하게 유지하고 학습을 빠르고 안정적으로 진행할 수 있게 한다.
전체 구조 정리
Transformer는
Self-Attention으로 전역 문맥을 읽어들이고
FFN으로 각 토큰을 비선형적으로 다시 가공하며
Residual + LayerNorm으로 깊은 구조를 안정화하여,
시퀀스 정보를 효율적으로 이해하는 모델이다.
MAX_LEN = 25
VOCAB_SIZE = 2000
EMBEDDING_DIM = 64
NUM_HEADS = 2
FF_DIM = 128
DROPOUT_RATE = 0.1
NUM_BLOCKS = 2
EPOCHS = 10
BATCH_SIZE = 32
inputs = Input(shape=(MAX_LEN,))
x = TokenAndPositionalEmbedding(MAX_LEN, VOCAB_SIZE, EMBEDDING_DIM)(inputs)
for _ in range(NUM_BLOCKS):
x = TransformerBlock(EMBEDDING_DIM, NUM_HEADS, FF_DIM, DROPOUT_RATE)(x)
x = GlobalAveragePooling1D()(x)
x = Dropout(0.1)(x)
outputs = Dense(1, activation='sigmoid')(x)
transformer_model = Model(inputs, outputs)transformer_model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
history = transformer_model.fit(
train_X, train_Y,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_split=0.2,
verbose=1
)test_loss, test_acc = transformer_model.evaluate(test_X, test_Y, verbose=0)
print(test_loss, test_acc)example_sentences = [
"이 영화는 정말 재미있고, 스토리도 흥미진진하며 배우들의 연기까지 완벽했다.",
"전체적으로 지루하고 재미가 없었다.",
]
example_seq = vectorize_layer(example_sentences)
pred = transformer_model.predict(example_seq)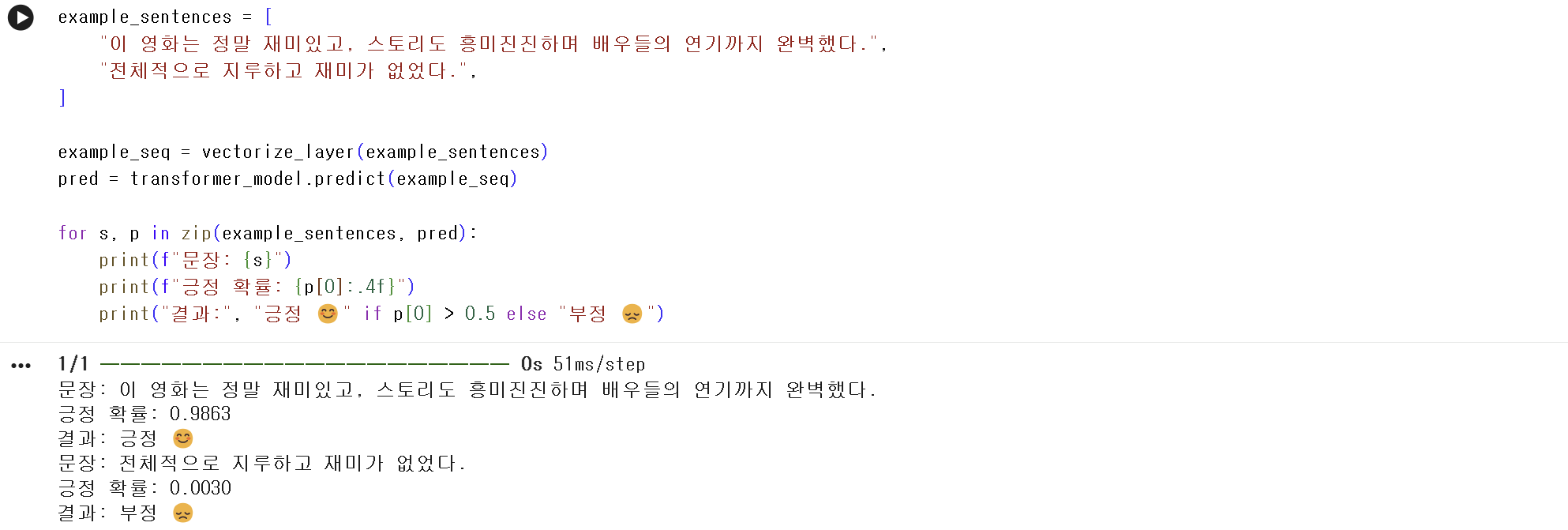
WIL
Transformer 기반 감성 분석 모델을 직접 구성하면서 Self-Attention이 문맥을 이해하는 방식에 대한 구조를 알 수 있었다.
특히 단어를 순차적으로 처리하지 않고 문장 전체를 병렬로 바라보는 구조가 RNN이나 LSTM과 확실히 다른 차이점이라는 것을 깨닫게 되었다.
Positional Embedding을 통해 순서를 인위적으로 모델에 주입하는 과정도 실제 코드를 보며 명확히 이해되었다.
또한, 자세히 몰랐었는데 많이 들어봤던 개념인, Multi-Head Attention, FFN, Residual Connection, LayerNorm이 각각 어떠한 역할을 하는지, 또, transformer기반 모델의 성능을 어떠한 방식으로 높이는지도 확인할 수 있었다.
전체적으로 RNN-LSTM-Transformer 흐름으로 NLP의 발전 과정을 한눈에 볼 수 있는 실습이었다.
