기획
우리의 목표는
학교 현장에서 실제로 ‘안전하게’ 사용할 수 있는 AI를 만드는 것이다.
기획코스때 가장 많이 받았던 피드백은
“성능이 좋은 AI는 이미 많은데, 이러한 AI와의 차이점이 무엇인가요?" 라는 질문이였다.

그래서 우리는 당진시 50대 교사분께 직접 여쭈어보았다.
첫번째 질문은,
교사일을 하시면서 AI를 사용하시나요?
였다.
이에 대한 답변으로는
수업 자료를 만들고, 가정통신문을 작성하고, 간단한 문서를 정리하는 데 AI는 이미 훌륭한 도구를 자주 사용하신 다는 답변을 받았다.
두번째 질문으로는
교사일을 하시면서 AI 사용을 제약받은 경험이 있나요?
라는 질문이였다.
이에 대한 답변으로는
생활기록부, 학생 상담 기록, 학부모 민원 대응 문서처럼
개인정보와 법령이 얽힌 문서들은 여전히 “AI 사용 금지 구역”이라는 답변을 받았다.
이러한 인터뷰에서 우리는 "AI를 사용할 수 있는 영역" 과 "AI를 사용이 제약되는 영역" 간의 단절이라는 문제를 의식했다.
그래서 우리의 목표는
‘모든 걸 다 해주는 AI’가 아니라,
‘학교에서 써도 괜찮은 AI’를 만들자는 목표를 세웠다.
이를 위해서는 로컬에서 돌아가는 경량 AI를 만드는 것이 해결책이였다.
이 프로젝트의 핵심 키워드는 세 가지였다.
-
외부 통신 없이 로컬 환경에서 동작
-
법령 판단 근거를 명확히 제시
-
최신 법령 변화에 유연하게 대응
따라서, 우리의 프로젝트는 교사가 “이 문서는 AI에 넣어도 된다”고 확신할 수 있다면 성공한 것이다.
파이프라인


“데이터를 전부를 파인튜닝할 모델에 학습시키면 되지 않을까?”
하지만 조사해보니 법에는 성격 차이가 있었다.
-
자주 바뀌지 않는 법리 (행정법의 일반 원칙 등)
-
자주 바뀌는 지침·시행규칙
모든 것을 모델에 학습시키면
법이 개정될 때마다 모델을 다시 학습해야 하는 문제가 생긴다.
그래서 역할을 나눴다.
-
잘 바뀌지 않는 법리 → Fine-tuning
-
자주 바뀌는 법령·지침 → RAG(검색 증강 생성)
모델은 가볍게 유지하면서도
답변은 항상 최신 상태를 유지할 수 있는 구조를 선택했다.
데이터 전처리
이번 프로젝트에서 가장 많은 시간을 쏟은 단계는 데이터 전처리였다.
AIHub의 행정법 데이터를 다운받으면,
위 그림과 같이 원천데이터와 라벨링 데이터로 나뉘어져 있었다.
처음에는 라벨링 데이터만 사용하여 GPT-4o-mini를 ‘가공 도구’로 사용하여, 전처리를 했었었다. 즉, 데이터 가공 에이전트로 사용했다.
2만개의 데이터를 전처리하고 나서 보니, 결론만 있고 왜 그런 결론이 나왔는지가 빠져 있었으며, 어떤 근거를 찾아 어떻게 사고해야 하는지의 '사고의 사슬(Chain of Thought)' 이식 구조에 맞춰져 있지 않았다.
이 데이터를 그대로 학습시키면, AI는 “답을 외우는 모델”이 될 수밖에 없었다고 판단을 하여, 다시 처음으로 돌아갔다.
여기서 GPT-4o-mini를 사용한 이유는 GPT-OSS를 사용하려고 시도해보았었는데, 이 모델을 다운을 받으면 코랩 용량이 부족하여, 데이터 전처리를 코랩환경에서 할 수가 없었다. 따라서 우리는 GPT-4o-mini를 사용했다.
GPT-4o-mini에게 원천데이터와 라벨링 데이터를 합쳐놓은 json 파일을 [판단 근거 → 상세 설명 → 최종 결론] 이러한 형태로 데이터를 바꿔놓게끔 시켰다.

데이터 형식을 보면, 원천데이터는 csv 파일 형태로, 참고서 같은 역할을 한다면, 라벨링 데이터는 json파일 형태로, 문제지 같은 역할을 한다. 우리는 GPT-4o-mini에게 라벨링 데이터(=정답지)를 보고 원천데이터(=참고서)를 참고해서, 역으로 추론하되, 데이터 형식을 [판단 근거 → 상세 설명 → 최종 결론]로 맞춰달라고 명령을 내린것이다.

위 코드가 GPT-4o-mini에게 넣어준 프롬프트이다.
이렇게 해서 모델에게 ‘정답’이 아니라 사고하는 방식을 학습시킬 수 있었다.
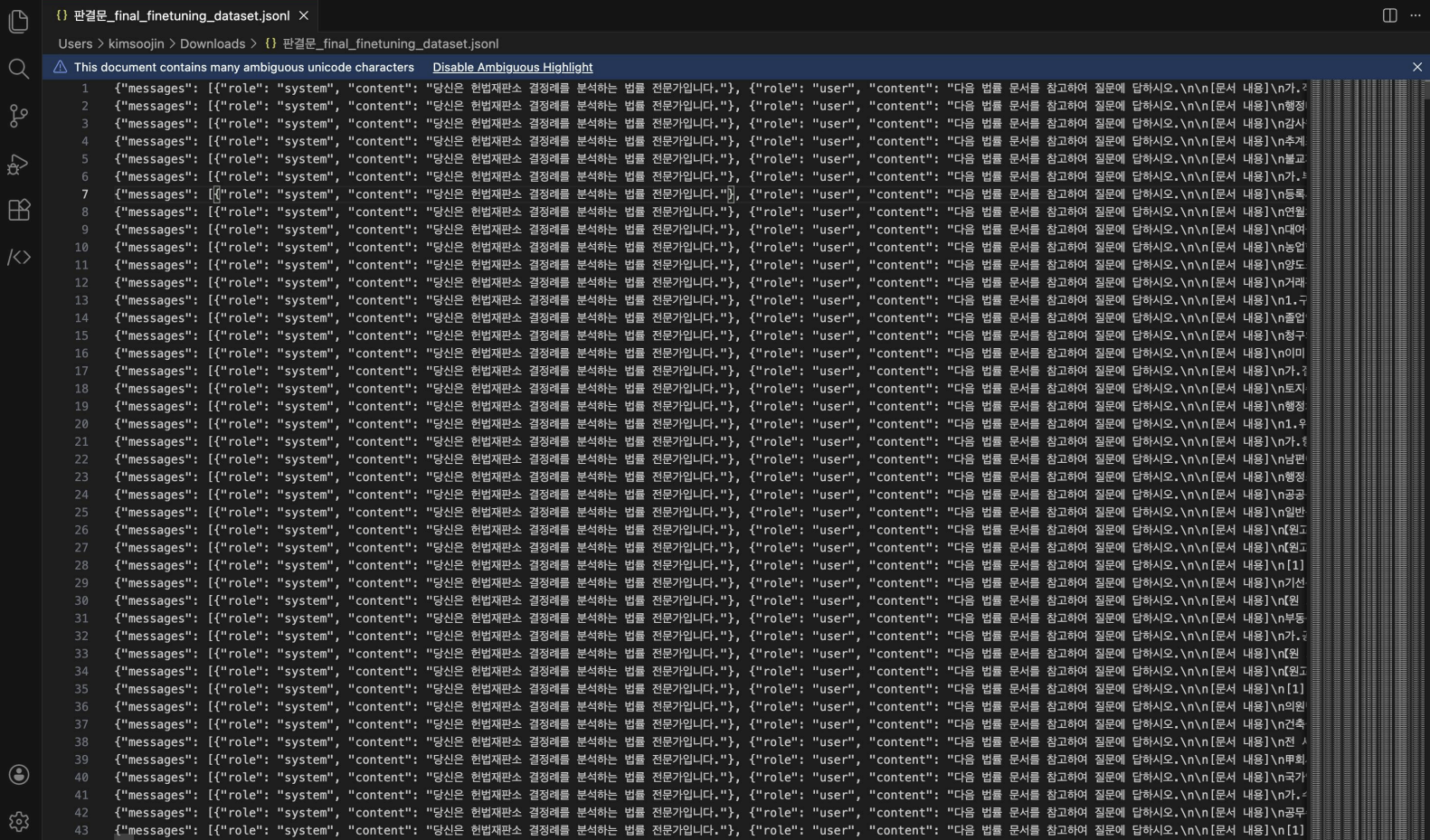
결과적으로 약 2만 개의 학습 최적화 데이터셋을 구축했다.
모델링
베이스 모델로는 Qwen 2.5 3B-Instruct를 선택했다.
한국어 법률 데이터에 적합한 문장 이해력, 3B 파라미터로 로컬 환경에서도 현실적인 성능 때문에, 이 모델을 선택했다.
우선 허깅페이스에서 코랩으로 모델을 불어왔다.

잘 불러왔는지 질문을 해보았는데 잘 대답하는 모습을 볼 수 있었다.
학습 과정에서는 LoRA로 필요한 부분만 학습하고, Gradient Accumulation으로 제한된 GPU 자원을 효율적으로 사용했다.
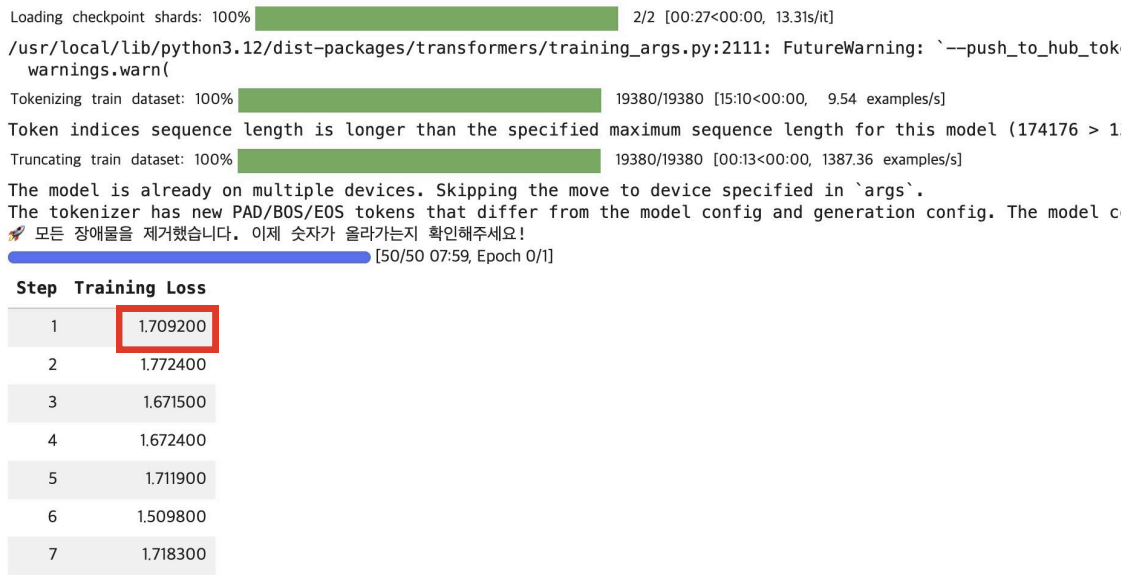
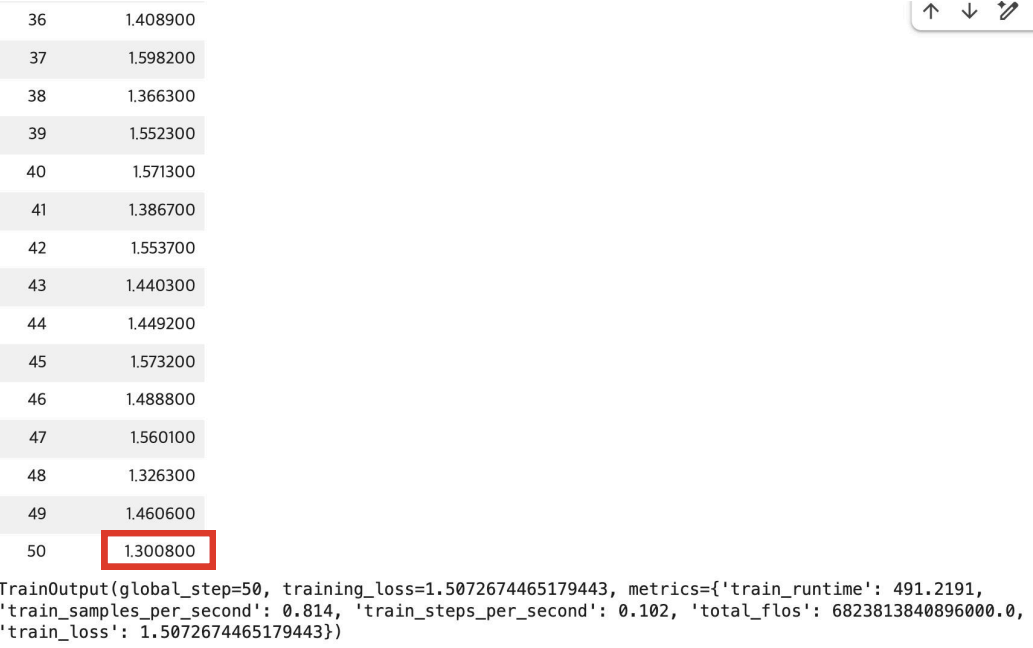
보면, 짧게 학습했지만, Loss가 1.7에서 1.3으로 안정적으로 감소했다.
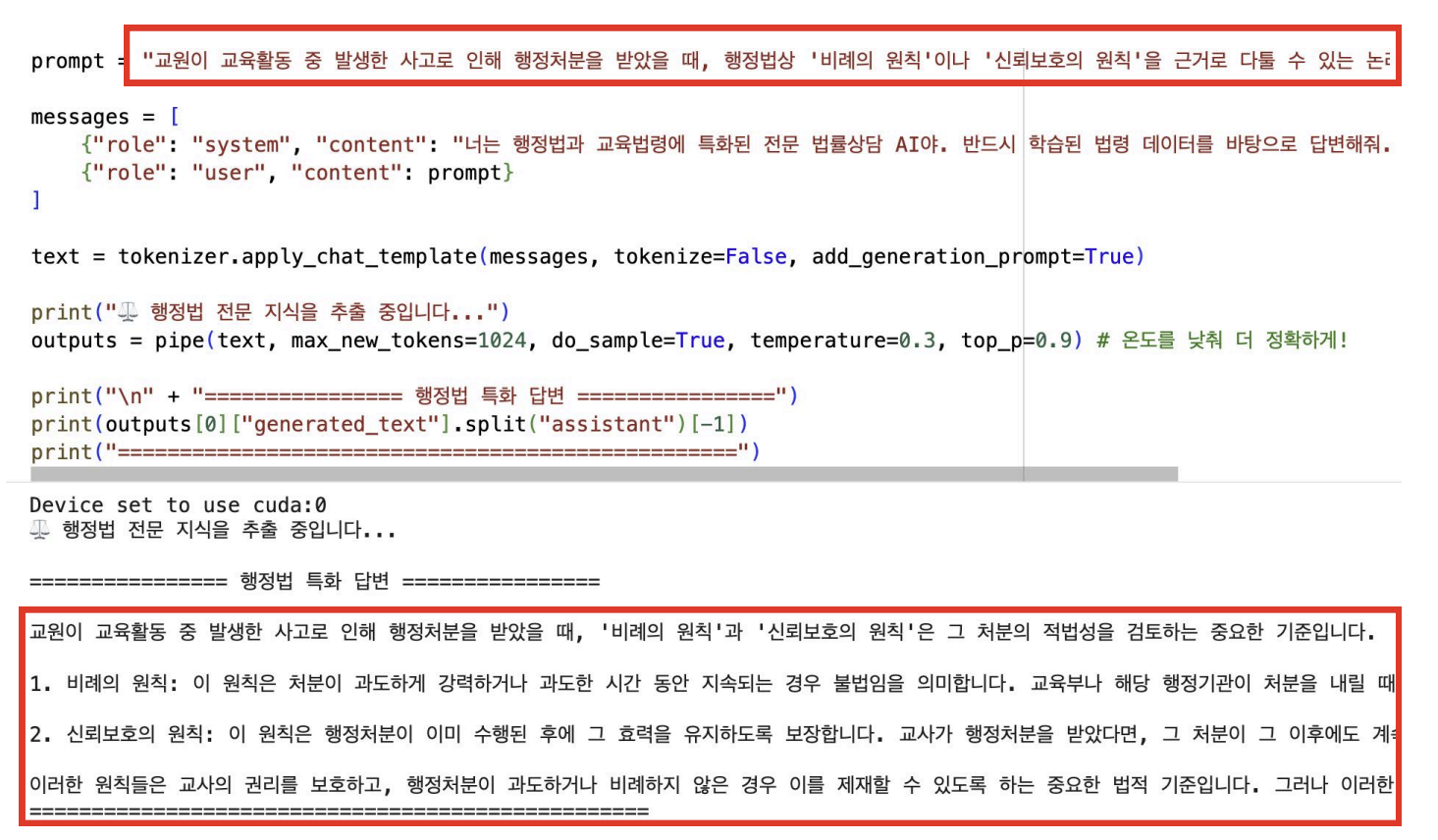
훈련이 완료된 모델에게 행정법의 기본 원칙에 대해서 물어봤는데, 논리적으로 또 전문적으로 답변하는 모습을 확인할 수 있었다.
앞으로의 계획
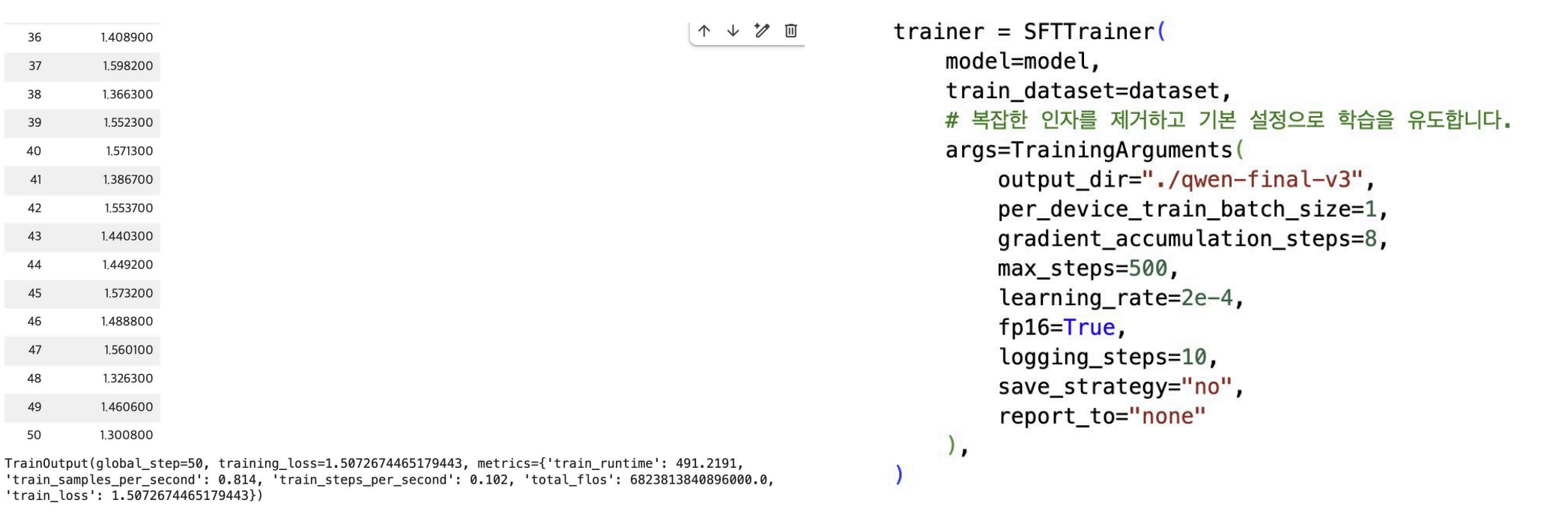
앞으로의 계획은 max_steps를 500으로 늘려서 학습을 시키는 것이다.
그러고 나서 파인튜닝 완료한 모델을

자주 바뀌는 법과 결합하여 최종 우리 모델을 만드는 것이 목표이다.
