Week1에서 학습된 vectorize_layer를 test에 적용
test_text_X = [
row.split('\t')[1]
for row in test_text.split('\n')[1:]
if row.count('\t') > 0
]
# Week1에서 학습된 vectorize_layer
test_X = vectorize_layer(test_text_X)
print("test_X shape:", test_X.shape)
print("test_Y shape:", test_Y.shape)하이퍼파라미터(Hyperparameter)
하이퍼파라미터는 모델 학습 전에 사람이 직접 설정하는 값이다. 모델의 구조나 학습 방식에 큰 영향을 미치는 요소이며, 학습 중에 자동으로 조정되는 가중치(weight) 와는 다르다.
하이퍼파라미터 설정은 모델의 성능을 결정한다.
하이퍼파라미터 설정
VOCAB_SIZE = 2000
EMBEDDING_DIM = 128
MAX_LEN = 25
EPOCHS = 10
BATCH_SIZE = 32주요 하이퍼파라미터 역할
VOCAB_SIZE 는 모델이 인식할 수 있는 단어의 총 개수를 의미한다.
예를 들어 10,000으로 설정하면, 전체 단어 중 상위 1만 개 단어만 사용한다.
EMBEDDING_DIM 은 단어를 벡터로 표현할 때의 차원 수를 의미한다.
차원이 높을수록 단어 간 의미를 더 세밀하게 표현할 수 있지만, 연산량이 증가한다.
MAX_LEN 은 입력 문장의 최대 길이를 의미한다.
문장이 이보다 길면 자르고, 짧으면 0으로 패딩하여 길이를 맞춘다.
EPOCHS 는 전체 학습 데이터를 몇 번 반복해서 학습할지를 의미한다.
학습을 여러 번 반복할수록 모델은 데이터를 더 잘 학습하지만, 과적합이 발생할 위험도 커진다.
BATCH_SIZE 는 한 번에 학습에 사용하는 데이터의 개수를 의미한다.
값이 크면 학습이 빠르지만 세밀한 조정이 어렵고, 작으면 느리지만 세밀하게 학습할 수 있다.
EPOCHS와 과적합(Overfitting)
EPOCHS를 늘린다고 해서 무조건 성능이 좋아지는 것은 아니다.
처음에는 반복 학습을 통해 손실이 줄고 정확도가 올라가지만,
일정 시점 이후에는 훈련 데이터에만 과도하게 맞춰져 새로운 데이터에 대한 성능이 오히려 떨어지는 과적합이 발생한다.
과적합을 방지하기 위해서는 조기 종료(EarlyStopping), Dropout, 정규화(Regularization), 데이터 증강(Data Augmentation) 등의 기법을 사용할 수 있다.
기본 신경망 모델 구성
model = tf.keras.Sequential([
tf.keras.layers.Embedding(VOCAB_SIZE, EMBEDDING_DIM, input_shape=(MAX_LEN,)),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()Embedding이란
Embedding은 단어를 벡터(숫자 배열)로 변환하는 과정이다.
자연어는 텍스트 형태이므로, 이를 모델이 이해할 수 있도록 수치 형태로 바꿔주는 것이다.
이때 단어 간의 의미적 유사도를 반영할 수 있다는 점에서 기존의 단순한 one-hot 인코딩보다 우수하다. (one-hot-encoding이란? 하나의 값만 1이고 나머지는 모두 0인 벡터로 표현하는 방식이다.)
예를 들어,
“좋아요”라는 단어는 [0.12, -0.54, 0.33, ...]과 같은 실수 벡터로 표현된다.
이 벡터들은 학습을 통해 자동으로 조정되며, 단어 간 의미적 관계를 반영하게 된다.
Pooling이란
Pooling은 특징 맵(feature map)에서 중요한 정보를 추출해 크기를 줄이는 과정이다. 주로 CNN이나 RNN 모델의 중간 단계에서 사용된다.
Pooling에는 여러 종류가 있다.
-
Max Pooling은 영역 내의 가장 큰 값을 선택하여 특징의 존재 여부를 강조한다.
-
Average Pooling은 영역 내의 평균값을 취해 전체적인 경향을 반영한다.
Pooling은 연산량을 줄이고 과적합을 방지하는 데에도 도움을 준다.
선형함수와 비선형함수
선형함수는 입력과 출력이 비례 관계를 가지는 함수이며, 수식으로는 y = ax + b 형태이다.
이 함수만으로는 복잡한 데이터의 패턴을 표현할 수 없다는 한계가 있다.
→ 예를 들어, 입력이 2배가 되면 출력도 항상 2배가 되는 구조이다.
반면, 비선형함수는 입력과 출력이 비례하지 않으며, 복잡한 관계를 학습할 수 있다.
이러한 비선형함수는 신경망에서 활성화 함수(Activation Function) 로 사용된다.
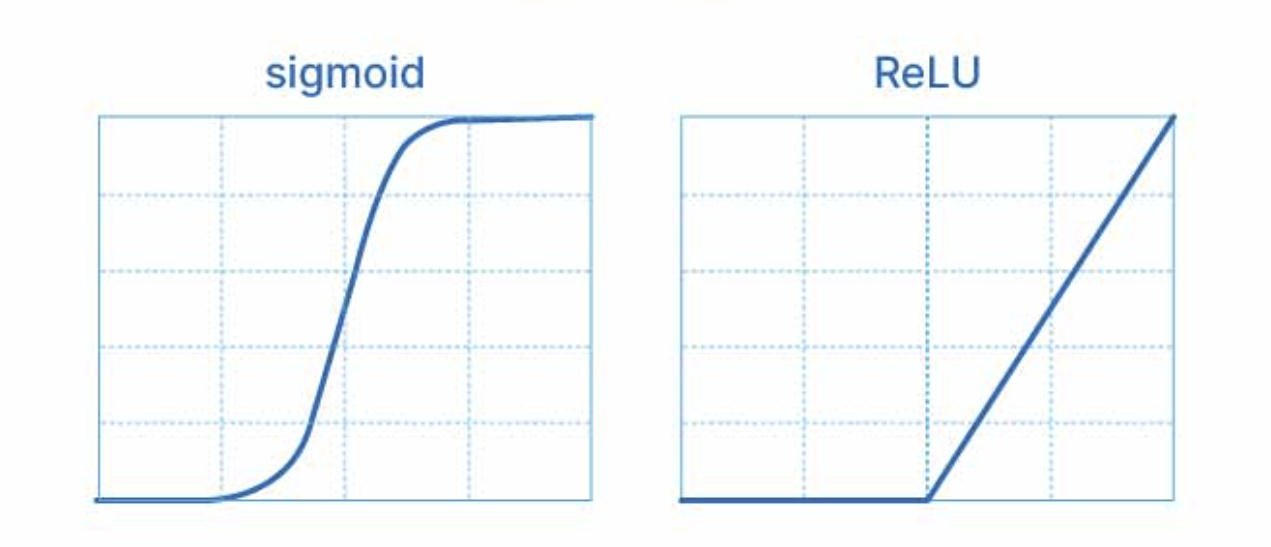
활성화 함수로는 ReLU 함수와 Sigmoid 함수가 있다.
ReLU 함수는 입력이 0보다 작으면 0, 크면 그대로 출력하는 함수이다.
계산이 빠르고 학습 효율이 높아 널리 사용된다.
수식은 ReLU(x) = max(0, x) 이다.
Sigmoid 함수는 입력 값을 0과 1 사이로 압축하며,
주로 확률을 표현하거나 이진 분류 문제의 출력층에서 사용된다.
수식은 Sigmoid(x) = 1 / (1 + e^-x) 이다.
Dense Layer의 역할 -> Dense Layer 기반 신경망 동작 방식
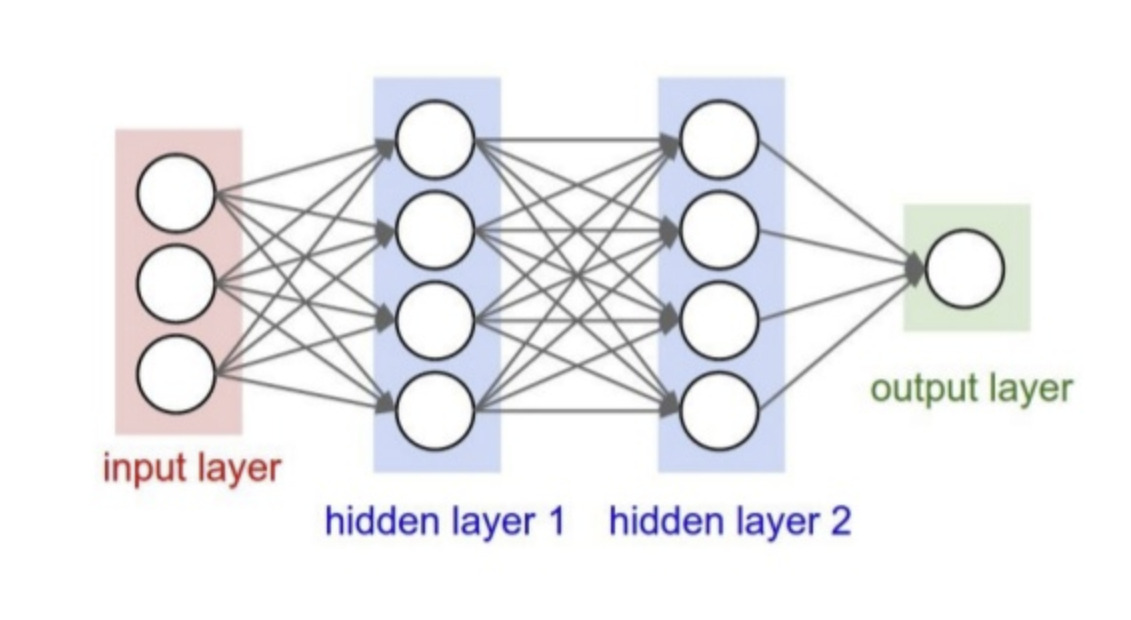
그림을 먼저 살펴보면, 가장 왼쪽에는 세 개의 노드로 구성된 input layer가 위치해 있다. 이 입력층은 모델에 처음 들어오는 값들을 나타내며, 각 노드는 하나의 입력 특성을 의미한다. 입력층의 노드들은 각각 선으로 이어져 있는데, 이 선 하나하나가 바로 가중치(weight)를 의미한다.
입력층 오른쪽에는 파란색으로 표시된 hidden layer 1이 있다. 이 층은 Dense Layer, 즉 완전 연결층을 보여주는 전형적인 형태이다. 입력층의 세 개 노드에서 hidden layer 1에 있는 모든 노드로 선이 서로 교차하며 이어져 있다. 이 말은 입력층의 모든 값이 hidden layer의 모든 뉴런에 영향을 준다는 뜻이다.
Hidden layer 1의 각 노드는 입력층에서 전달된 값들을 모두 받아들인다. 각 입력 값은 고유한 가중치와 곱해지고, 다시 모두 더해진 뒤 여기에 바이어스(bias)가 더해진다. 이렇게 계산된 합은 활성화 함수(ReLU나 sigmoid 등)를 통과해 정제된 결과를 만들어내며, 이 값이 다음 층으로 전달된다.
첫 번째 hidden layer 오른쪽에는 또 하나의 파란색 영역인 hidden layer 2가 있다. 여기에서도 동일한 구조가 반복된다. Hidden layer 1의 모든 노드에서 hidden layer 2의 모든 노드로 연결된 선들이 보이는데, 이는 첫 번째 hidden layer에서 얻은 특징들을 다시 조합하여 더 복잡한 패턴을 학습하는 단계이다. 신경망이 깊어질수록 모델은 더 추상적이고 의미 있는 특징들을 학습할 수 있게 된다.
그림의 가장 오른쪽에는 초록색 상자로 표시된 output layer가 있다. 이 층은 모델이 최종적으로 내놓는 예측값을 나타내며, hidden layer 2에서 나온 정보들이 모두 이 출력 노드에 모인다. 출력층의 활성화 함수가 무엇인지에 따라 의미는 달라지는데, 그림처럼 출력 노드가 1개라면 보통 이진 분류(sigmoid)에 사용된다.
모델 학습 준비
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])겉으로 보기엔 단순하지만, 사실 이 세 줄은 모델이 어떻게 학습할지를 결정하는 굉장히 중요한 설정이다.
Optimizer(최적화 함수)
Optimizer는 모델이 학습하면서 가중치를 어떻게 수정할지를 결정하는 알고리즘이다.
adam은 대표적으로 많이 사용하는 옵티마이저로, 학습을 빠르고 안정적으로 진행하도록 돕는다.
과거 기울기 흐름을 참고하고, 파라미터마다 다른 학습률을 적용해 효율적으로 손실을 줄인다.
Loss Function(손실 함수)
Loss Function은 예측값과 실제 정답의 차이를 계산해주는 함수이다.
모델이 얼마나 틀렸는지를 수치로 표현하며, 이 손실 값을 기준으로 Optimizer가 가중치를 조정한다.
binary_crossentropy는 두 개 클래스로 나누는 이진 분류에서 사용하는 대표적인 손실 함수로, 예측 확률이 정답과 가까울수록 손실이 작아지고 멀어질수록 손실이 커진다.
Metrics(평가지표)
Metrics는 모델의 성능을 확인하기 위한 지표이다.
학습 과정에서는 loss만으로는 성능을 직관적으로 판단하기 어렵기 때문에 metrics를 함께 사용한다.
accuracy는 전체 데이터 중 정답을 맞힌 비율로, 이진 분류에서 가장 단순하고 널리 쓰이는 평가 기준이다.
모델 학습 및 감정 예측
history = model.fit(
train_X, train_Y,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_split=0.2,
verbose=1
)test_loss, test_acc = model.evaluate(test_X, test_Y, verbose=0)
print(f"Test Loss: {test_loss:.4f}, Test Accuracy: {test_acc:.4f}")example_sentences = [
"이 영화 진짜 재미있어요",
"완전 지루하고 별로였음",
"배우 연기는 좋았지만 스토리가 아쉬웠다"
]
example_seq = vectorize_layer(example_sentences)
pred = model.predict(example_seq)
for s, p in zip(example_sentences, pred):
print(f"문장: {s}")
print(f"긍정 확률: {p[0]:.4f}")
print("결과:", "긍정 😊" if p[0] > 0.5 else "부정 😞")# OUT
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 87ms/step
문장: 이 영화 진짜 재미있어요
긍정 확률: 0.9838
결과: 긍정 😊
문장: 완전 지루하고 별로였음
긍정 확률: 0.0155
결과: 부정 😞
문장: 배우 연기는 좋았지만 스토리가 아쉬웠다
긍정 확률: 0.0161
결과: 부정 😞예측 결과를 보면, 모델은 긍정·부정이 뚜렷한 문장에서는 정확하게 감정을 구분하고 있다. 다만 긍정과 부정 표현이 함께 들어 있는 문장은 문장 구조보다는 특정 단어의 영향을 더 크게 받아 판단하는 모습을 보인다.
10 Epoch vs 30 Epoch 학습 비교 및 과적합 시각화
# Epoch 수를 30으로 늘려 다시 학습해봅니다.
history_overfit = model.fit(
train_X, train_Y,
epochs=30,
batch_size=BATCH_SIZE,
validation_split=0.2,
verbose=1
)
# 과적합 여부를 Loss/Accuracy 곡선으로 시각화
plt.figure(figsize=(12, 5))
# (1) Loss 비교
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Train Loss (10 Epoch)')
plt.plot(history.history['val_loss'], label='Val Loss (10 Epoch)')
plt.plot(history_overfit.history['loss'], label='Train Loss (30 Epoch)', linestyle='--')
plt.plot(history_overfit.history['val_loss'], label='Val Loss (30 Epoch)', linestyle='--')
plt.title('Loss Comparison (10 vs 30 Epochs)')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# (2) Accuracy 비교
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Train Acc (10 Epoch)')
plt.plot(history.history['val_accuracy'], label='Val Acc (10 Epoch)')
plt.plot(history_overfit.history['accuracy'], label='Train Acc (30 Epoch)', linestyle='--')
plt.plot(history_overfit.history['val_accuracy'], label='Val Acc (30 Epoch)', linestyle='--')
plt.title('Accuracy Comparison (10 vs 30 Epochs)')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()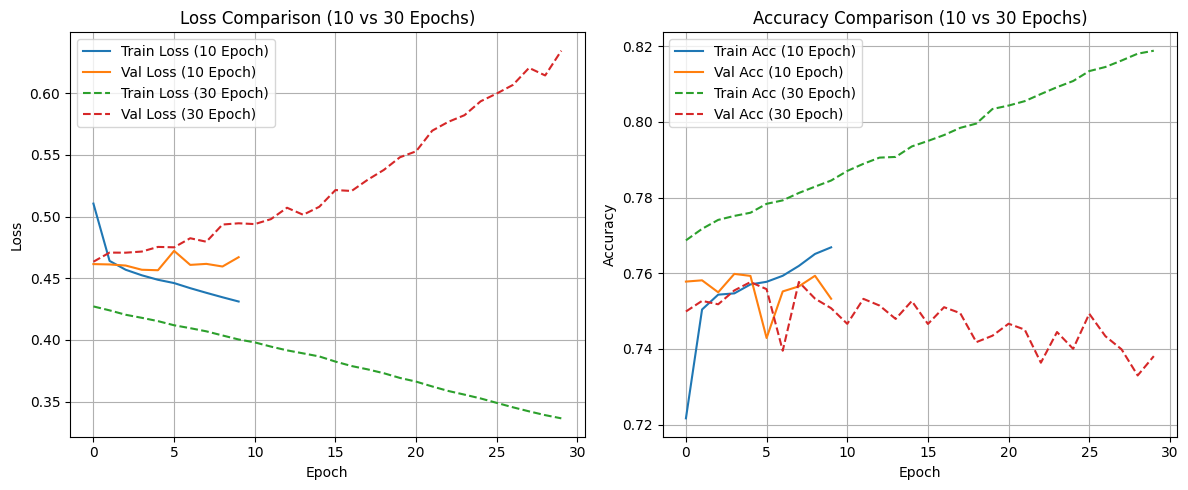
Loss Comparison 그래프 해석
파란색 실선 (Train Loss 10 Epoch)
→ 학습 데이터에 대한 손실이 점차 감소하며 안정적으로 학습되고 있다.
주황색 실선 (Val Loss 10 Epoch)
→ 검증 데이터에 대한 손실도 함께 감소하며, 10 epoch 내에서는 과적합이 거의 없다.
→ 즉, 학습 데이터와 검증 데이터 모두에서 손실이 비슷한 수준으로 낮다.
초록색 점선 (Train Loss 30 Epoch)
→ epoch이 늘어나면서 학습 데이터에 대한 손실이 계속 감소한다.
→ 모델이 훈련 데이터를 점점 더 “완벽하게” 외우고 있다는 의미이다.
빨간색 점선 (Val Loss 30 Epoch)
→ 반대로 검증 데이터 손실은 점점 증가한다.
→ 이는 모델이 훈련 데이터에만 과도하게 맞춰져 일반화 성능이 떨어지는 과적합 현상을 보여준다.
결론:
10 epoch에서는 훈련과 검증 손실이 비슷한 수준이지만,
30 epoch에서는 훈련 손실이 계속 줄어드는 반면 검증 손실은 오히려 증가한다.
즉, EPOCHS를 너무 늘리면 과적합이 발생한다는 것을 확인할 수 있다.
Accuracy Comparison 그래프 해석
파란색 실선 (Train Accuracy 10 Epoch)
→ 학습 정확도가 점차 상승하고 있다.
주황색 실선 (Val Accuracy 10 Epoch)
→ 검증 정확도도 함께 상승하며, 큰 차이가 없다.
→ 학습이 적절히 이루어지고 있음(일반화 잘 됨)을 의미한다.
초록색 점선 (Train Accuracy 30 Epoch)
→ epoch이 늘어날수록 훈련 정확도는 꾸준히 증가한다.
→ 거의 완벽하게 훈련 데이터를 학습하고 있다.
빨간색 점선 (Val Accuracy 30 Epoch)
→ 반대로 검증 정확도는 오히려 점점 하락하고 있다.
→ 훈련 데이터에는 강하게 적합했지만, 새로운 데이터에는 성능이 떨어진다.
결론:
훈련 정확도(Train Acc)는 높아지지만, 검증 정확도(Val Acc)는 감소하는 현상은 전형적인 과적합(Overfitting) 의 특징이다.
즉, 학습을 오래 시킬수록 훈련 데이터에는 잘 맞지만,
새로운 데이터에 대한 예측력은 오히려 떨어지게 된다.
WIL
이번 학습을 통해 단순히 모델을 돌리는 것이 아니라, 그 내부에서 어떤 원리로 학습이 이루어지는지를 이해하는 것이 얼마나 중요한지 깨닫게 되었다.
특히 선형함수만으로는 아무리 층을 쌓아도 복잡한 패턴을 표현할 수 없다는 점이 인상 깊었다. 비선형 활성화함수가 신경망에 생명력을 불어넣는 역할을 한다는 것이 확실히 이해되었다.
또한, 하이퍼파라미터가 단순한 설정값이 아니라
모델의 학습 효율과 성능을 결정짓는 핵심 변수임을 알게 되었다.
앞으로는 모델을 구성할 때 단순히 기본값을 사용하는 것이 아니라,
데이터의 특성과 목적에 맞게 하이퍼파라미터를 조정해야 한다는 점을 명확히 알게 되었다.
이번 학습을 통해 이론적인 개념뿐만 아니라, 모델이 왜 그렇게 설계되어야 하는지에 대한 이해 기반의 학습을 할 수 있었다는 점이 인상적이였다.
