
❓ 일단 이게 뭘까?
인덱스 (index)
추가적인 쓰기 작업, 저장 공간을 활용하여 DB 테이블의 검색 속도를 향상시키기 위한 자료구조
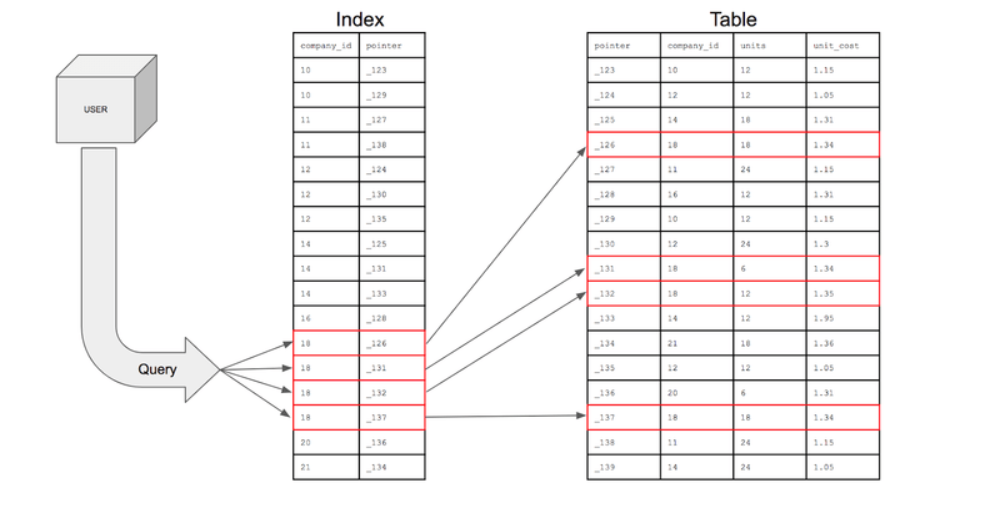
보통 우리는 책의 맨 첫번째 페이지에 "목차"라는 페이지가 존재한다.
우린 이 "목차"라는 것을 보고, "아! 이 페이지에 이 내용이 있구나" 라고 인지한다.
근데... 이 "목차"라는 것이 존재하지 않으면?
우린 책을 다 한번씩 읽어보면서 내가 원하는 내용을 찾아야된다.
인덱스가 DB의 "목차"같은 역할을 담당한다.
🔨 인덱스 관리
책은 한번 출판하면, 다시 구매하지 않는 이상 내용이 변하지 않는다.
근데, DB는 데이터가 자주 바뀐다.
즉, index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다.
INSERT, UPDATE, DELETE 가 수행된다면...
INSERT: 인덱스에 새로운 데이터 추가UPDATE: 기존의 인덱스를 사용하지 않음 처리 -> 갱신된 데이터에 대해 인덱스 변경DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
이러한 작업들을 수행해야 된다.
물론 이에 따른 '오버헤드'가 발생된다.
장점
- 데이터 조회 속도 상승 (항상 그런 것은 아님)
- 쿼리의 부하가 줄어들어 시스템의 성능이 향상!
단점
- 약 10%에 해당하는 추가 저장공간 필요
- 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생
이 두번째 단점이 핵심이다.
데이터의 변경(Insert, Update, Delete)작업이 빈번하게 발생하면,
인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
인덱스를 사용하기 좋을 때?
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 규모가 작지 않은 테이블
- 데이터의 중복도가 낮은 컬럼
💾 저장 방식
클러스터형 인덱스 (Clustered Index)
데이터 행의 원래 순서대로 저장되어 있는 인덱스를 의미
데이터가 저장 순서 그대로 되어 있기 때문에,
클러스터 인덱스는 각 테이블당, 단 하나만 가질 수 있다.
행 데이터를 지정한 열에 맞춰 자동으로 정렬한다.
'사전'하고 비슷하다고 생각하면 된다.
(ㄱ, ㄴ, ㄷ, ㄹ.... 이런 순으로)
보조형 인덱스 (Secondary Index)
실제 데이터의 위치와는 별개로 저장되는 인덱스
인덱스의 기준이 되는 컬럼을 기준으로, 실제 데이터와는 다른 별도의 순서를 가진다.
그래서 여러개의 보조형 인덱스 테이블를 가질 수 있다.
"보조형 인덱스"는 일반 책의 목차하고 비슷하다고 생각하면 된다.
뭐... 목차를 ㄱ, ㄴ, ㄷ 순으로 배치하지는 않지 않는가?
📦 구조 (Structure)
해시 테이블(Hash Table)
(Key, Value)로 데이터를 저장하는 자료구조
Key값을 이용해 고유한 index를 생성하여, 그 index에 저장된 값을 꺼내오는 구조이다.
시간복잡도는 O(1)이며 매우 빠른 검색을 지원한다.
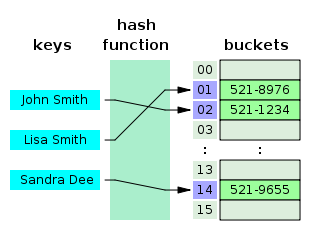
다만...
SELECT *
FROM user
WHERE NAME = "민수";like, = (등호) 이러한 연산에만 특화되어 있다.
그림의 "hash function"을 사용하게 되면 "hash value"가 나온다.
이 해시값은 key 값이 조금만 달라져도 엄청 달라진 값이 나오게 된다.
부등호 연산(>, <)등 이러한 연산은 해시 테이블에 적합하지 않는다.
그래서 index 테이블은 주로 B+Tree로 사용된다고 한다.
B+Tree
B-Tree에서 검색 성능을 한층 개선한 자료구조
일단 이진 탐색 트리는 알고 있다고 가정하자.
1. B-Tree
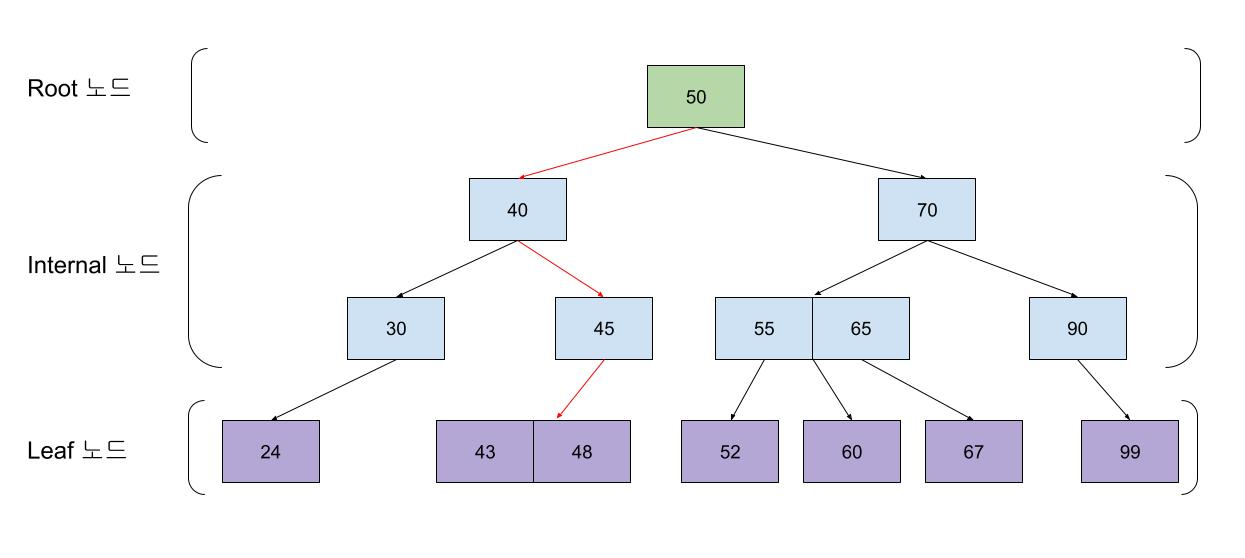
B-Tree는 이진탐색트리를 업그레이드한 자료구조로, RDB의 Index에서 자주 사용되는 자료 구조이다.
기존 자식이 최대 두개밖에 안되던 이진탐색트리에 비해, B-Tree는 2개 이상도 가능하다.
균형이진트리의 특징을 가지고 있기 때문에, 당연히 균형도 계속 유지된다. (레벨차이가 최대 1레벨)
따라서 O(logN)의 검색 성능을 보여준다.
다만 B-Tree는 탐색을 위해, 노드를 찾아서 이동해야 한다는 단점을 가지고 있다.
이 점을 보완한 구조가 B+Tree 구조다.
2. B+Tree
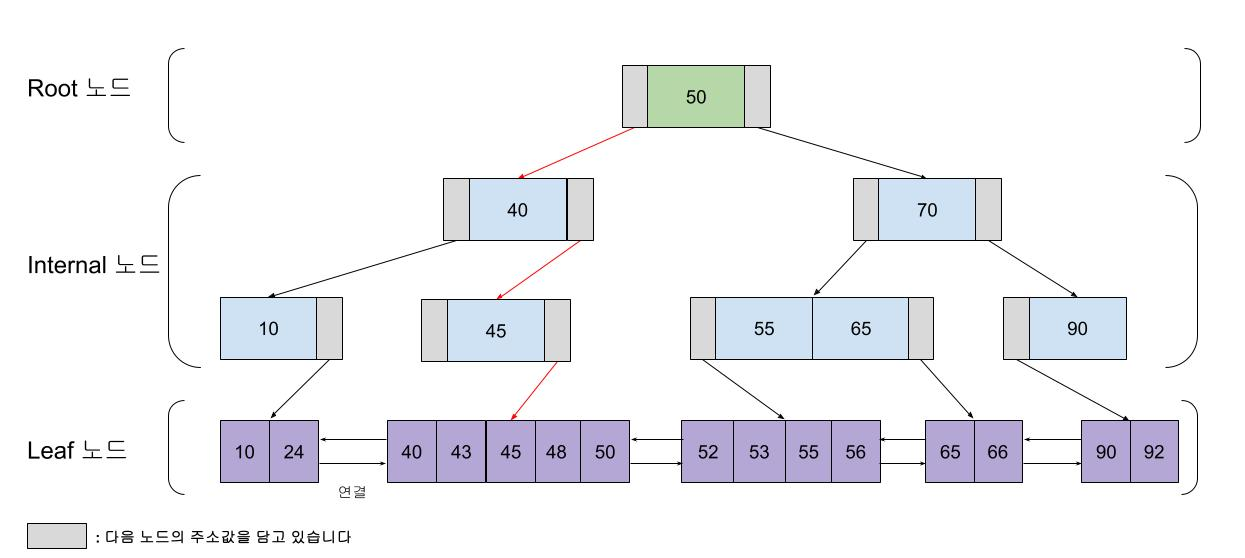
InnoDB엔진에서 Index를 관리할 때 B+Tree를 사용한다.
B-Tree보다 검색 연산이 빠르고, 범위 검색에 유용하다.
예를 들면, A 이상 B 이하의 범위 검색을 한다고 가정하자.
B-Tree 혹은 이진탐색트리는 일단 A의 위치를 한번 탐색하고, 마찬가지로 B의 위치를 또 탐색을 해야해서 총 2번을 탐색하게 된다.
그림을 보면, B+Tree는 Leaf 노드가 서로 연결되어 있다.
A를 한번 탐색 후, 오른쪽으로 탐색하게 되면 B가 탐색이 되면서, 루트부터 다시 탐색할 필요가 사라진다.
게다가 B+Tree는 Leaf노드에만 실제 데이터가 저장이 되어 있다고 한다.
즉 메모리 측면에서도 B-Tree보다 효율적이다.
3. 그럼 무조건 B+Tree가 좋은가?
Leaf 노드들끼리 연결되어 있는 것이 B+Tree의 특징이다.
즉, 어딘가에는 저 연결된 노드 정보들이 저장이 되어 있어야 한다.
그래서 데이터의 생성, 수정, 삭제 시에는 저 연결되어 있는 노드 정보들이 변동이 되기 때문에 B-Tree가 조금 더 유리하다고 한다.
4. B Tree를 선택하는 이유?
앞서 말했다시피, 탐색 속도는 O(logN)으로 보장하고 있다.
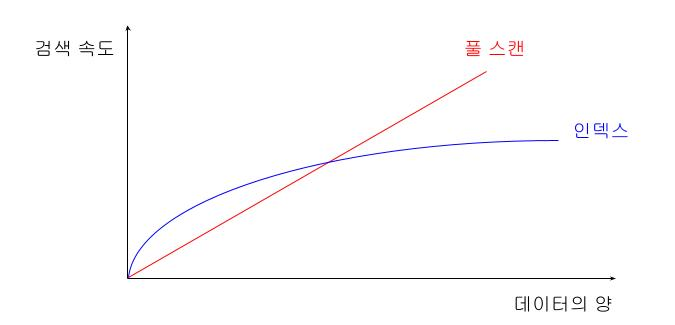
물론 우리가 가상의 프로젝트를 진행하면, 데이터가 얼마 없어서 사실 풀스캔을 해도 빠르게 탐색이 된다.
바로 밑에 100만개의 더미 데이터로 실습을 하는 과정을 남겨놨다.
나도 이정도의 데이터를 처음 봤는데, 단순하게 전체 조회만 해도 몇초의 시간이 소요되는게 보인다.

(사실인지 아닌지는 정확하게 모른다...)
우리가 자주 사용하는 카카오톡 사용자도 1000만명이 가뿐하게 넘는다.
이렇게 많은 사용자 데이터를 풀스캔을 하게 되면...? 엄청나게 큰 시간이 소요된다.
log의 특징은, N이 커지더라도 어느정도의 수치를 보장해준다.
즉, 빅데이터를 관리하기에는 O(logN)을 보장하는 B Tree가 적합한 것이다.
그래서 Index는 B Tree를 통해, 빠른 속도의 데이터 조회기능을 제공한다.
🧪 실험
조건
1. 총 데이터는 1,000,000개
2. Index 적용 테이블, 그냥 테이블 두개를 비교
3. "같은 쿼리를 날렸을 때, 얼마나 차이가 나는가?"를 ms 단위로 비교
4. 실제랑 비슷한 환경을 위해, MariaDB와 Spring Boot는 다른 컴퓨터에서 진행 (외부IP)
5. API는 스웨거로 진행
6. MySQL은 B+Tree 구조로 클러스터형 인덱스를 사용
MariaDB: 11.8.2, Ubuntu CLI
SpringBoot: 3.5.0, MacOS
더미 데이터 예시
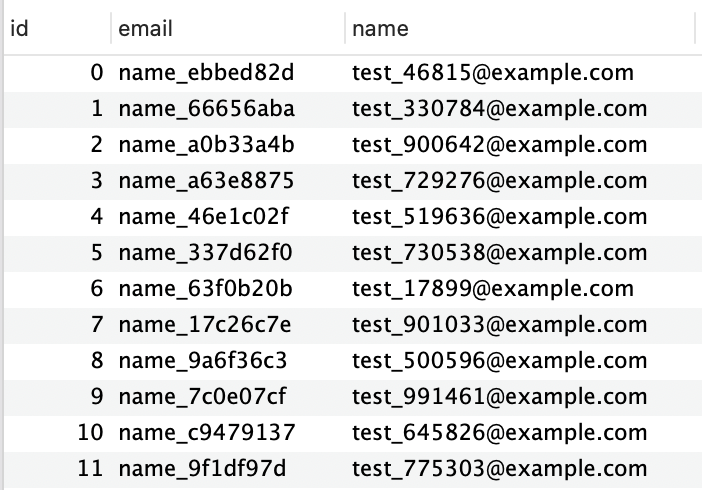
테이블(Entity)
// User.java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private String email;
}// UserIndexVer.java
@Entity
@Table(indexes = { @Index(name = "idx_email", columnList = "email") })
public class UserIndexVer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private String email;
}테이블은 PK인 id, name, email로 컬럼이 구성되어 있다.
Index는 email를 기준으로 만들었다.
조회 성능 (특정 값을 찾기)
public ResponseEntity<?> getUserByEmail(String email) {
long start = System.currentTimeMillis();
noIndexRepository.findByEmail(email);
long end = System.currentTimeMillis();
// System.out.println("조회 시간: " + (end - start) + "ms");
return ResponseEntity.ok().body("조회 시간: " + (end - start) + "ms");
}인덱스 없이 조회 결과,
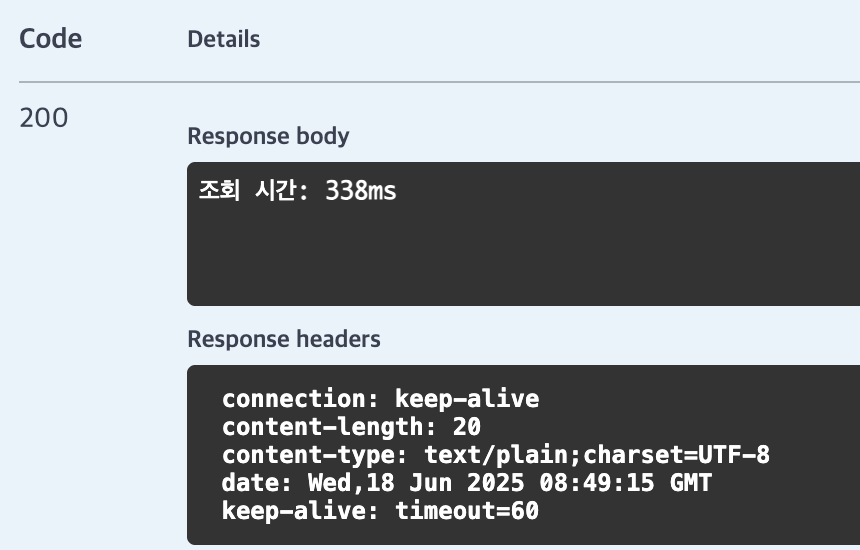
약 338ms (0.338초)가 나왔다.
인덱스를 사용하면...
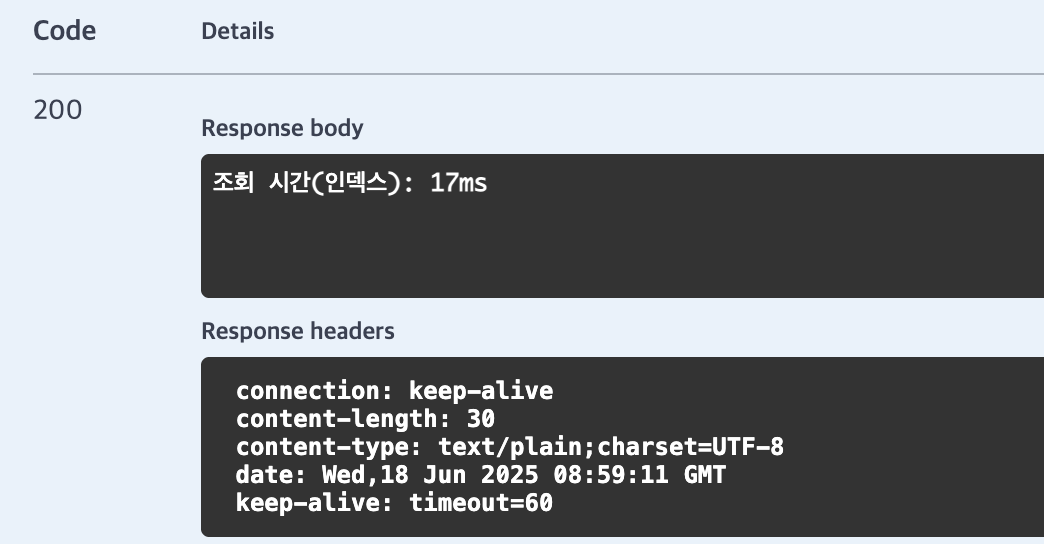
와... 17ms (0.017초)가 나왔다.
약 20배를 줄였다.
물론 어디서 어떻게 쓰이냐에 따라 다르겠지만,
육안으로 확인하니 나도 처음에 "이정도로 줄일 수 있다고?" 라고 하면서 신기했다.
결과
조회 성능은 엄청나게 증가한 것을 볼 수 있다.
다만 데이터 수정 시, index Table(B+Tree)를 수정해야 한다.
또한 데이터를 입력하면 입력할수록, 당연하게 index의 크기는 커진다.
즉 위에서 말했다시피,
데이터 수정/입력이 적고, 조회가 잦은 테이블에 사용하기 적합하다.
