
◽ SqlAlchemy?
→ python에서 사용할 수 있는 ORM중 하나

ORM(Object Relational Manager)
객체(Object)와 RDB의 Table 간 데이터를 자동으로 변환해 주는 기술 (또는 그 기술을 구현한 라이브러리)
✔ 엔진생성
from sqlalchemy import create_engine
engine = create_engine("문자열 URL", echo=True, future=True)
# 문자열 URL 예시
# 단, sqlite의 경우, sqlite://<nohostname>/<path> 의 포맷을 따른다.
예) dialect+driver://username:password@host:port/database
→ mysql+pymysql://
→ mysql+aiomysql://위 코드는 엔진을 만드는 방식이다.
실제 연결은 DB에 대해 작업을 수행하라는 요청을 받을때만 연결한다.
✔ 세션 생성 (컨텍스트 매니저 사용)
# Session 클래스를 매번 직접 만들면서 엔진을 바로 넘김
with Session(engine) as session:
db_user = (
session.query(UserSchema)
.filter(UserSchema.id == user_id)
.first()
)
session.delete(db_user)
session.commit()
return {"message": "사용자가 성공적으로 삭제되었습니다."}근데 이상한건 session을 닫는 session.close()가 없다.
파이썬은 컨텍스트 관리자(Context Manager) 라는 기능이 있다.
컨텍스트 관리자(Context Manager)
코드 블록의 실행 전후에 필요한 설정 및 정리 작업을 자동으로 수행할 수 있게 도와주는 개념 (with문과 함께 사용)
즉, with 문이 실행되면 __enter__() 가 작동되어 session 이라는 변수에 세션이 저장된다.
실행을 마치고 나면 __exit__() 가 실행되어 close() 가 실행된다.
def __enter__(self: _S) -> _S:
return self
def __exit__(self, type_: Any, value: Any, traceback: Any) -> None:
self.close()✔ 세션 연결 (yield 사용)
# DB 세션을 생성하고 관리하는 의존성 함수(DI) 정의
def get_db():
session_local = _get_session_local()
db: Session = session_local()
try:
yield db
finally:
db.close()혹은 이렇게 세션을 주는 DI 함수를 만든 후에
def delete_user(user_id: int, db: Session = Depends(get_db)):이런식으로 Depends 함수를 통해 세션을 가져온다.
yield로 세션을 넘겨준 후, delete_user 메소드가 끝나면 finally를 통해 db가 닫힌다.
✔ Session 설정
# Session factory (sessionmaker)를 lazily 초기화
def _get_session_local():
global _SessionLocal
if _SessionLocal is None:
_SessionLocal = sessionmaker(
autocommit=False, # 자동으로 commit 안 한다는 뜻
autoflush=False, # 쿼리 실행 전, 자동으로 flush 하지 않는다는 뜻
bind=get_engine()
)
return _SessionLocal-
autocommit
→ DB 작업 후, 자동으로 커밋할지 여부
→ session.commit()을 호출하여 변경사항을 DB에 확정 -
autoflush
→ 세션에서 수행된 변경사항(객체 추가, 수정 등), DB 쿼리를 실행하기 전에 자동 반영이 되어야 하는가?
→ false면 최근 변경사항이 쿼리 결과에 반영 X
-
bind==engine()
→ 세션을 DB 엔진에 바인딩
즉, flush로 Query를 넣어버려도 commit을 안하면 rollback이 가능하다. (영구적 반영 X)
get_db() 함수에 의해, 트랜잭션이 종료되면 알아서 DB 연결을 커넥션 풀에 반환한다.
(밑에 컨텍스트 매니저랑 비교해서 또 나온다.)
◽ 사용방법
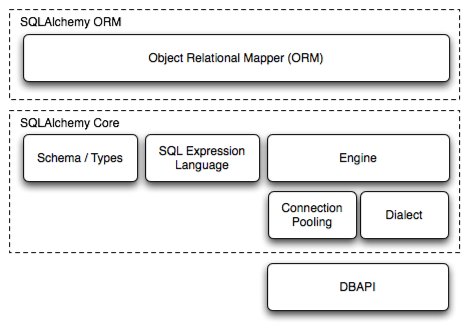
SQLAlchemy를 통해 DB와 상호 작용하는 코드를 작성할 때 Core 방식과 ORM 방식이 있다.
Core 방식은 SQL 문을 보다 직접적인 컨셉으로 활용하여, 성능에 이점이 있는 방법이다.
ORM 방식은 Python 클래스를 데이터 베이스의 테이블에 매핑한 추상화된 방식을 제공하여 더 사용하기 쉽게 만드는 방법이다.
[스텍오버플로우] What is the difference between SQLAlchemy Core and ORM?
✔ Core
→ SQLAlchemy의 기본 레벨, 직접 테이블을 정의하고 SQL처럼 쿼리를 구성한다.
def read_user_core(user_id: int, db: Session = Depends(get_db)):
table = UserSchema.__table__
stmt = (
select(table.c.username, table.c.email)
.where(table.c.id == user_id)
)
result = db.execute(stmt)
row = result.mappings().first()
return {"username": row.username, "email": row.email}복잡한 SQL 문을 직접 짜야하거나, ORM 쓰기 어려운 메타 프로그래밍 상황에 사용된다.
(복잡한 JOIN, 윈도우 함수 자주 사용하는 경우)
즉, ORM이 최적화하기 어려운 매우 성능에 민감한 쿼리의 경우 Core를 통해 직접 SQL을 작성하는 것이 상당한 속도 향상을 가져오는 경우가 많다. 이는 복잡한 조인, 하위 쿼리 또는 분석에 특히 그렇다.
✔ ORM
→ Core 위에서 동작하는 상위 추상화
→ Python 클래스 기반으로 선언하고, 객체처럼 다를 수 있어 유지보수가 쉽다.
→ 트랜잭션 및 연결 풀링에 대한 기본적인 지원
@router.get("/{user_id}", response_model=model.UserResponse)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = (db
.query(UserSchema)
.filter(UserSchema.id == user_id)
.first()
)
return db_user모델 중심 개발이 필요할 때 주로 사용된다.
또한 FastAPI, Pydantic 등 통합이 중요하거나, 협업/대규모 유지보수 환경에 적합하다.
