1.어떤 문제를 풀고 싶은가?
최근 AI의 기술, 특히 거대 언어 모델(LLM)과 비전-언어 모델(VLM)의 발전은 눈부시다. 단순히 글을 쓰고 그림을 그리는 이것을 넘어, 이제 로봇의 뇌가 되어 물리적인 세계와 상호작용하는 단계에 이르렀다. Mobility VLA 논문은 이 VLM 기술을 로봇 내비게이션에 접목해, 기존의 한계를 뛰어넘는 연구를 진행했다.
기존 로봇 내비게이션의 한계
지금까지의 로봇 내비게이션 연구(ObjectGoal Navigation, Vision-Language Navigation 등)는 꽤 발전해서, "소파로 가"또는 "부엌에 있는 테이블로 가줘"와 같은 명시적인 언어 명령을 잘 수행한다. 하지만 현실 세계에서 우리가 로봇에게 내릴 명령은 항상 이렇게 간단명료하지 않다.
우리가 사무실에서 플라스틱 통을 들고 로봇에게 이렇게 물어본다.
"이거 어디다 반납해야 해요?"
이 질문에 답하기 위해 로봇은 단순히 "플라스틱 통"이나 "반납"이라는 단어만 알아서는 안 된다.
- 이거가 무엇인지 눈으로 보고(Vision) 이해해야 한다.
- 반ㄴ바해야 하는 곳이 어디인지 (예: 재활용품을 모아두는 선반) 주변 환경과 상황에 대한 상식적인 추론을 해야 한다.
이처럼 사람의 진짜 의도와 맥락을 파악하는 것은 기존 로봇 내비게이션의 큰 숙제이다.
새로운 문제 정의: MINT의 등장
MINT(Multimodal Instruction Navigation with demonstration Tours)라는 새롭고 현실적인 문제 상황을 정의한다.
MINT의 핵심 아이디어는 두 가지이다.
1. 멀티모달(Multimodal) 명령: 사용자의 텍스트(언어)뿐만 아니라, 사용자가 보여주는 이미지(시각) 정보까지 함께 이해하여 목표를 설정한다.
2. 사전 답사 영상(Demonstration Tour): 로봇이 환경에 대한 사전 지식이 없더라도 사용자가 스마트폰 등으로 미리 한번 쭉 둘러보며 찍어둔 비디오 영상을 보고, 로봇 스스로 공간의 구조와 특징을 학습하게 한다.
즉, "MINT는 처음 가보는 공간이라도, 사람이 미리 찍어둔 영상을 보고 자리를 익힌 다음, 이미지와 텍스트로 된 복합적인 명령을 이해해서 목표 지점까지 이동하는" 매우 실용적인 과제를 푸는 것을 목표로 한다. 이 논문은 바로 이 어려운 MINT 문제를 해결하기 위한 Mobility VLA라는 시스템을 제안한다.
2.Mobility VLA 아키텍처
Mobility는 복잡한 MINT 문제를 해결하기위해 계층적 정책(Hierarchical Policy)를 채택했다.
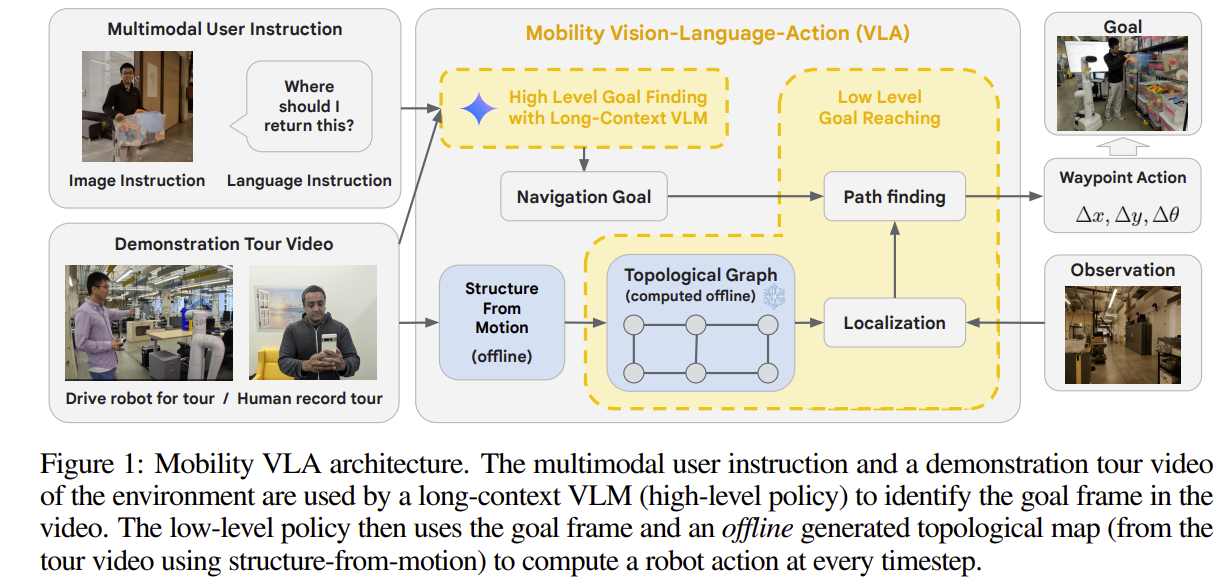
Mobility VLA는 문제를 두 단계로 나누어 푼다. 마치 사람처럼, 뇌가 어디로 갈지 큰 그림을 그리고, 몸이 어떻게 갈지 세부적인 움직임을 실행한다.
상위 정책 (High-Level Policy)
- 역할: "어디로 가야 하는가?"를 결정한다.
- 도구: Long-Context VLM (e.g., Gemini 1.5 Pro)
상위 정책은 시스템의 '뇌' 역할을 담당한다. 사용자가 "이건 어디다 반납해요?"라고 말하며 플라스틱 통을 보여주면, 이 VLM은 사전 답사 영상(Demonstration Tour Video)전체와 사용자의 멀티모달 명령(이미지+텍스트)을 입력으로 받는다.
그리고 VLM은 엄청난 양의 정보를 바탕으로 상식적인 추론을 시작한다.
'음, 사용자가 플라스틱 통을 들고 잇네. 이걸 반납할 만한 장소는 영상 속의... 아, 저기 재활용품을 모아두는 선반이 있었지!'
이런 추론 과정을 거쳐, VLM은 답사 영상의 수많은 프레임 중에서 "목표 지점은 바로 여기!"라고 최종 결정을 내린다. 그리고 그 결정의 결과로 딱 하나의 정보, 목표 프레임의 번호(Goal Frame Index)를 하위 정책에게 전달한다.
하위 정책 (Low-Level Policy)
- 역할: "목표 지점까지 어떻게 갈 것인가?"를 실행
- 도구: 위상 지도(Topological Graph) + 고전적인 경로 탐색 알고리즘
상위 정책으로부터 목표 프레임 번호를 전달받은 하위 정책은 이제 몸이자 운전사가 되어 직접 움직인다. VLM처럼 복잡한 추론은 하지 않지만, 대신 안정적이고 효율적으로 길을 찾는 데 집중한다.
-
위치 파악(Localization): 현재 로봇의 카메라에 보이는 풍경을 바탕으로, 미리 만들어 둔 위상 지도에서 어디에 위치하고 있는지 파악한다.
-
경로 계획(Path Finding): 현재 위치부터 뇌가 알려준 목표 지점까지 가는 최단 경로를 계산한다.
-
실행(Excution): 계산된 경로를 따라 충돌 없이 안전하게 로봇을 움직인다.
이처럼 Mobility VLA는 VLM의 유연한 추론 능력과 고전적인 로보틱스 알고리즘의 안정성이라는 두 마리 토끼를 모두 잡은 아키텍처이다. 이는 복잡한 현실 세계의 문제를 해결하는 핵심 열쇠이다.
3.Mobility VLA 핵심 기술
Part 1: 오프라인 준비 - 지도
로봇이 사용자의 명령을 받기 전에, 먼저 주변 환경에 대한 지도를 만들어야 한다. Mobility VLA는 이 과정을 매우 효율적으로 처리한다.
1단계: Demonstration Tour (사전 답사)
모든 것은 비디오 하나로 시작된다. 사용자가 스마트폰을 들고 집이나 사무실을 한번 쭉 둘러보며 영상을 찍거나, 로봇을 원격으로 조종하며 주변 환경을 녹화한다. 이 영상이 바로 로봇이 세상을 배우는 첫 번째 교과서가 된다.
2단계: Topological Graph(위성 지도) 생성
이제 이 비디오를 로봇이 길을 찾는 데 사용할 수 있는 지도로 만들어야 한다.
-
SfM (Structure-form-Motion)으로 3D 공간 복원
Mobility VLA는 COLMAP이라는 유명한 오픈소스 SfM 도구를 사용한다. SfM은 이름 그대로 '움직임으로부터 구조를 파악하는' 기술이다.- 동작 원리: 비디오 속의 여러 2D 이미지 프레임들을 분석해서, 각 이미지를 찍을 때의 카메라 위치와 자세 (6-DoF Pose)를 3D 공간상에 역으로 추정한다. 동시에, 이미지들에서 공통적으로 보이는 특징점들(feature points)을 연결하여 3D 포인트 클라우드 형태의 3차원 지도를 만들어낸다.
- 결과: 이 과정을 거치면, "1번 프레임은 저기서 저쪽을 보며 찍었고, 2번 프레임은 여기서 이쪽을 보며 찍었구나" 하는 정보와 함께 공간의 3D 구조를 얻게 된다.
-
그래프 구성
3D 정보가 준비되면, 이를 그래프(Graph) 자료 구조로 변환한다.-
노드 (Node/Vertex): 비디오의 각 프레임 하나하나가 지도의 '지점'을 나타내는 노드가 된다.
-
엣지 (Edge): 두 노드(프레임)가 특정 조건을 만족하면, 두 지점 사이에 '길이 있다'는 의미의 엣지로 연결한다. 논문에서는 "두 프레임의 실제 거리가 2m 이내이고, 서로 전방 90도 안에 위치할 때" 엣지를 연결했다고 한다.
이렇게 완성된 지도가 위상 지도(Topological Graph)이다. 지하철 노선도처럼 각 지역(역)과 그 연결 관계(선로)를 표현한 것으로, 로봇이 다닐 수 있는 길의 네트워크를 나타낸다.
-
Part 2: 온라인 실행 - VLM의 추론
- 입력 (Prompt): VLM에게 질문하기
VLM의 성능은 어떤 질문(프롬프트)을 하느냐에 따라 크게 달라진다. Mobility VLA는 매우 정교하게 프롬프트를 설계했다. 논문에 나온 예시를 보면 다음과 같은 정보가 포함된다.
- 역할 부여: "너는 건물 안에서 작동하는 로봇이야..."
- 과제 설명: "...사용자의 명령에 가장 적합한 프레임을 답사 영상에서 찾아야 해."
- 맥락 정보(context)
사전 답사 영상의 모든 프레임 이미지들
사용자가 들고 있는 물건 등을 찍은 현재 이미지
* 사용자의 음성을 텍스트로 변환한 내용 ("이거 어디다 반납해야 해?")
이처럼 VLM에게 충분한 정보와 명확한 역할을 부여함으로써, 단순한 키워드 매칭을 넘어선 상식적인 추론을 유도한다.
- 출력 (Goal Frame Index): 복잡한 추론을 단 하나의 숫자로
모든 정보를 입력받은 VLM은 추론 끝에 하나의 결과물만 내놓는다. 목표 지점에 해당하는 프레임의 번호(정수 g)이다. 예시 -> "222번 프레임으로 가!"
"오른쪽으로 30도 돌고, 1.5미터 앞으로 가"와 같은 복잡하고 연속적인 제어 명령 대신 "수많은 선택지 중 정답 하나만 골라줘" 라는 검색(Search) 또는 분류(Classification) 문제로 바꾼다. 이렇게 하면 VLM은 자신이 가장 잘하는 추론에만 집중할 수 있다.
하위 정책: "어떻게 갈까?"
목표 프레임 번호(g)를 전달받은 하위 정책이 임무를 수행한다.
- 위치 파악 (Localization)
먼저 로봇은 "내가 지금 어디에 있지?"를 알아야 한다.
- 동작 원리: 현재 로봇의 카메라에 보이는 이미지(O)를 미리 만들어 둔 위상 지도(G)의 프레임들과 비교한다. 이미지 특징점을 기반으로 가장 유사한 노드를 찾아내 "나는 지금 N번 노드 근처에 있다"고 자신의 위치를 파악한다. 이 과정에서는 3D 포인터와 2D 이미지 간의 대응 관계를 이용해 카메라의 정확한 자세를 추정하는 PnP(Perspective-n-Point)와 같은 고전 컴퓨터 비전 알고리즘이 핵시적인 역할을 한다.
-
경로 탐색 (Path Finding)
현재 위치 노드(v_s)와 VLM이 알려준 목표 노드(v_g)를 알았으니, 이제 길을 찾을 차례이다. 여기서는 다익스트라(Dijstra) 알고리즘을 사용해 위상 지도 위에서 두 노드 간의 최단 경로를 빠ꇸ고 정확하게 계산한다. -
액션 생성 (Action Generation)
최단 경로가 계산되면, 로봇은 경로상의 바로 다음 노드로 움직이기 위한 명령을 생성한다. 현재 로봇의 위치와 자세를 기준으로 다음 노드까지의 상대적인 이동량 (Δx,Δy,Δθ)을 계산하여 모터 제어기로 전달한다. 이 과정을 목표 지점에 도달할 때 가지 반복한다.
4.실험 결과 분석
Mobility VLA의 성능과 왜 이런 설계가 탁월했는지 증명한다.
Long-Context VLM의 추론 능력
Mobility VLA의 뇌가 얼마나 똑똑한지 알아보기 위해, 연구팀은 다른 접근 방식들과 성능을 비교했다.
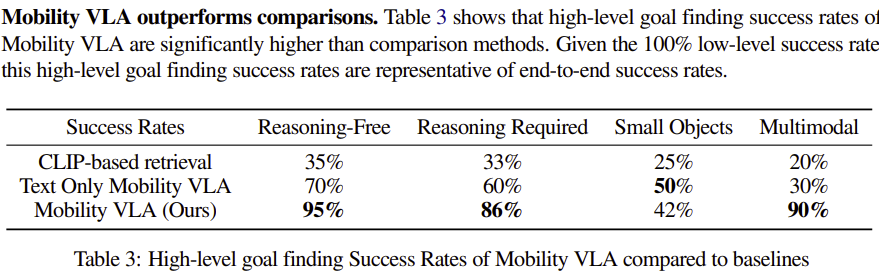
- CLIP 기반 검색: 이미지와 텍스트의 '의미적 유사도'를 계산해 가장 비슷한 프레임을 찾는 방식이다.
- Text-Only VLA: 답사 영상을 VLM으로 캡션을 달아 텍스트로 바꾸고, LLM이 이 텍스트만 보고 목표를 찾는 방식이다.
- Mobility VLA (Ours): 답사 영상 전체를 이미지 그대로 Long-Context VLM에 입력하는 방식이다.
결과는 놀라웠다. 특히, 복잡한 추론이 필요한 'Reasoning-Required'와 'Multimodal' 명령에서 Mobility VLA가 다른 방법들을 압도했습니다.
-
CLIP의 한계: CLIP은 "초록색 소파"처럼 명확한 대상은 잘 찾지만, "좀 조용한 곳으로 가고 싶어"와 같은 추상적인 의도는 파악하지 못한다. 이는 시각적 유사성에만 의존하기 때문이다.
-
Text-Only의 한계: "이것 좀 치워줘"라는 명령에서, 이미지를 보지 않으면 '이것'이 무엇인지 알 수 없다. 텍스트 캡션은 원본 이미지의 풍부한 시각 정보를 손실시키기 때문에 멀티모달 명령에 취약하다.
결론적으로, 답사 영상 전체를 이미지 그대로 보고, 사용자의 이미지와 텍스트를 동시에 이해할 수 있는 Long-Context VLM의 능력이 복잡한 현실 세계의 문제를 푸는 데 필수적이다.
예시: "이거 더 마시고 싶어"
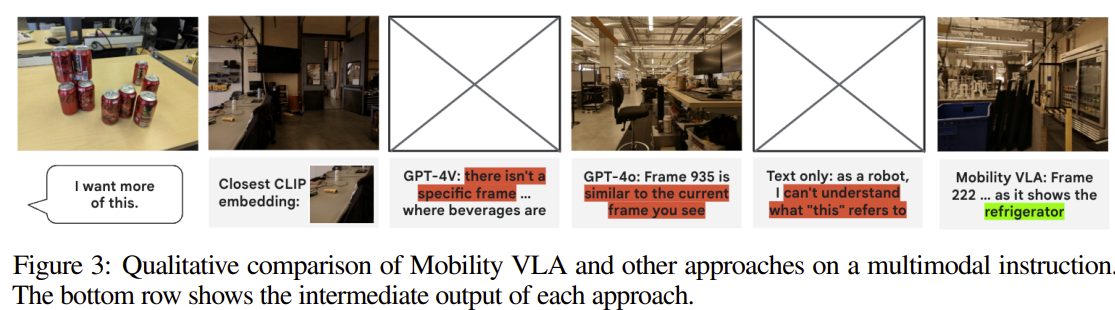
이 예시는 Long-Context VLM의 위력을 가장 극적으로 보여준다.
- CLIP: 콜라 캔 이미지와 가장 시각적으로 비슷한 물병이 있는 다른 책상을 찾았다. -> 겉모습만 본다.
- GPT-4o: 사용자가 현재 있는 책상과 비슷한 다른 책상을 찾았다. -> 장소의 유사성에만 집중했다.
- Text-Only: 이미지를 보지 못했기 때문에 '이거'가 뭘 말하는지 모르겠어요라고 되물었다.
- Mobility VLA (Gemini 1.5 Pro): 사용자가 콜라를 더 원한다 -> 콜라가 있을 만한 곳은? -> 냉장고! 라는 완벽한 상식 추론을 해내고, 영상 속 냉장고가 있는 프레임을 정확히 찾아냈다.
이것이 바로 단순한 패턴 매칭을 넘어선 의도 파악 능력이다.
위상 지도(Topological Graph)는 왜 필수적이었을까?
"VLM이 이렇게 똑똑하다면 , 그냥 VLM한테 직접 로봇을 조종하게 하면 안 될까?"라는 의문이 들 수 있다. 연구팀은 이 가설을 검증하기 위해, VLM이 직접 '전진', '좌회전', '우회전' 같은 움직임 명령(Waypoint Action)을 생성하도록 실험했다.
결과는 성공률 0%였다.

VLM은 왜 길을 찾지 못했을까?
- 체화(Embodiment)의 부재: VLM은 인터넷의 방대한 텍스트와 이미지로 학습했지만, 실제 물리 세계에서 움직여 본 경험이 없다. 따라서 1미터 전진이라는 명령이 실제 공간에서 어떤 결과를 낳는지, 벽에 부딪히지 않으려면 어떻게 해야 하는지에 대한 직관적인 이해가 부족하다.
- VLM의 강점과 약점: VLM은 무엇을 할지(What) 결정하는 고차원적인 의미 추론에는 강하지만, 어떻게(How) 할지를 결정하는 세밀하고 연속적인 제어에는 약하다.
이 실험 결과는 Mobility VLA의 계층적 구조가 왜 좋은 설계였는지 보여준다.
- VLM(뇌): 가장 잘하는 의미 이해와 추론에만 집중해서 "목표는 냉장고야!"라는 고수준의 결정을 내린다.
- 위상 지도 (몸/운전사): 가장 잘하는 안정적인 경로 탐색과 실행에만 집중해서 목표까지 안전하고 효율적으로 이동한다.
결론적으로, 최신 AI 모델의 놀라운 능력을 최대한 활용하되, 그 명확한 한계는 고전적이지만 신뢰도 높은 로보틱스 기술로 보완하는 것이 Mobility VLA가 성공할 수 있었던 핵심 비결이다.
