
TryITon 프로젝트: Virtual Try-on 서비스 최적화
프로젝트 개요
AI 기반 가상 피팅 기능을 도입한 쇼핑몰
여기에서 Vton 서비스 부분을 담당했는데 구현 과정에서 문제점 그리고 해결 방법을 이야기해 보려 한다.
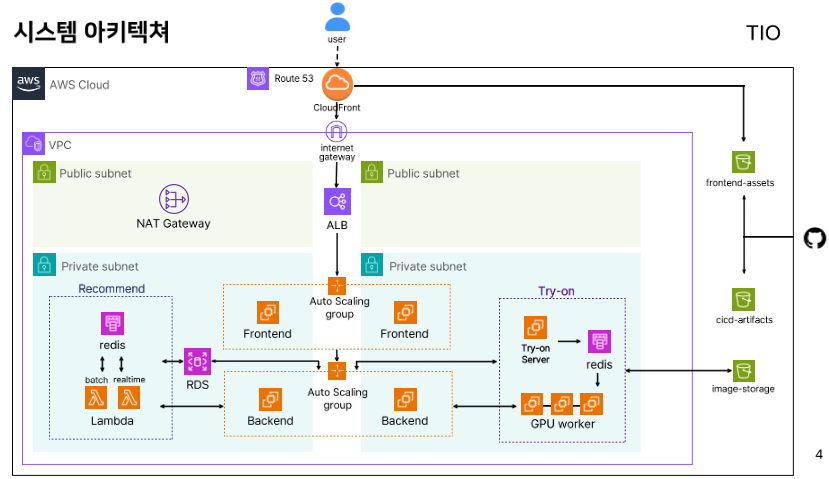
아키텍처
| 컴포넌트 | 기술 |
|---|---|
| 백엔드 프레임워크 | FastAPI |
| AI 모델 | FitDiT |
| 비동기 처리 | Celery |
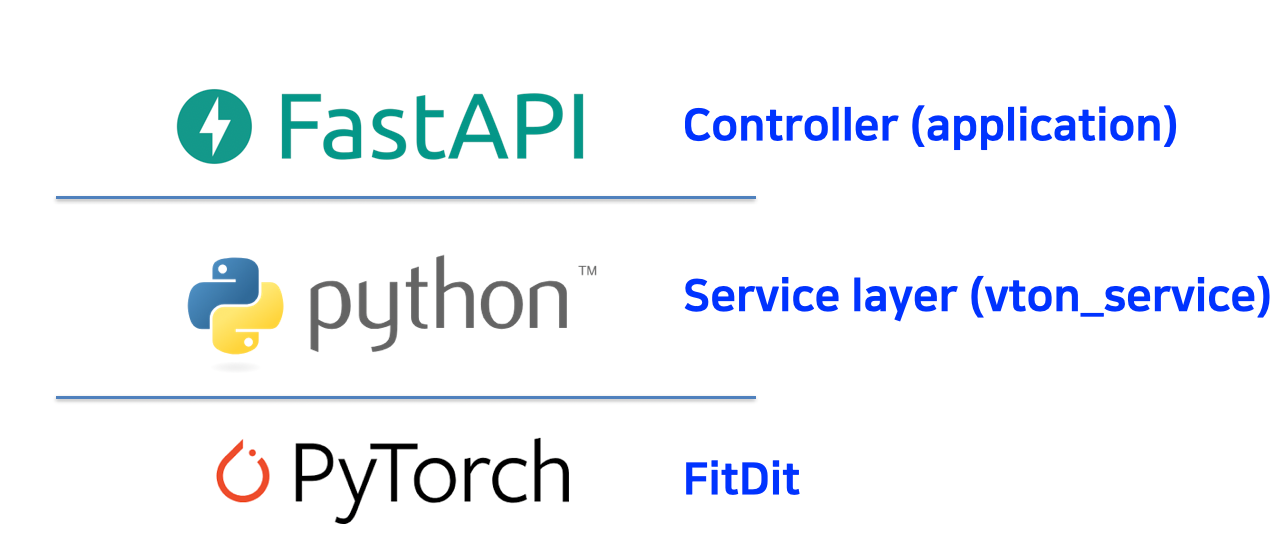
이미지 처리
- AI는 베이징 대학교에서 만든 FitDit 모델을 사용
- 파이토치로 구현된 모델을 사용하기 위해 python 기반의 FastAPI 사용
- 구현된 모델을 안정적으로 만들기 위해 별도의 모듈(vton_service.py)을 설계
문제점
이렇게 구현하면서 몇 가지 문제점이 생겼다.
- 하나의 vton 이미지 생성에 약 8초의 시간이 걸리는데 이를 spring 서버에서 계속 대기하다 보니 7건까지 잘 처리하다가 이후 요청에 대해 timeout이 발생했다.
이러한 동기적 방식의 문제점을 비동기 방식으로 전환하여 해당 문제를 해결하려 한다.
기존 이미지 처리 방식
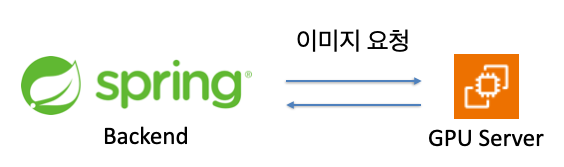
- spring에서 이미지 요청을 보내면 GPU 서버에서 요청을 받아 동기적으로 처리하는 방식
- 이미지 처리가 진행 중일 때 다른 요청이 들어오면 무시될 수 있다.
- 서버 증설을 사용한 분산처리를 기대하기 어렵다.
개선 방식 V1
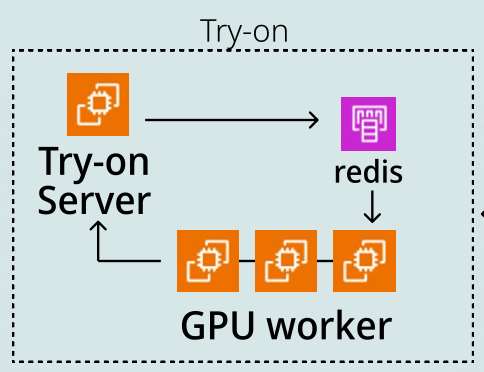
- Spring에서 이미지 요청을 보내면 celery에서 redis에 결과를 저장
- GPU worker가 테스크를 가져와 추론하고 spring 주소로 콜백
문제점
- Spring에서 celery로 vton 이미지를 요청할 때 CompletableFutre로 콜백을 기다린다.
- 이때 콜백 주소로 ALB DNS를 사용하여 AutoScaling 되는 Spring 그룹 중 하나로 콜백 메시지를 보낸다.
- 구조상 콜백 메시지가 vton 이미지 요청을 보낸 Spring Server에 도착하는 것을 보장할 수 없다.
개선 방식 V2
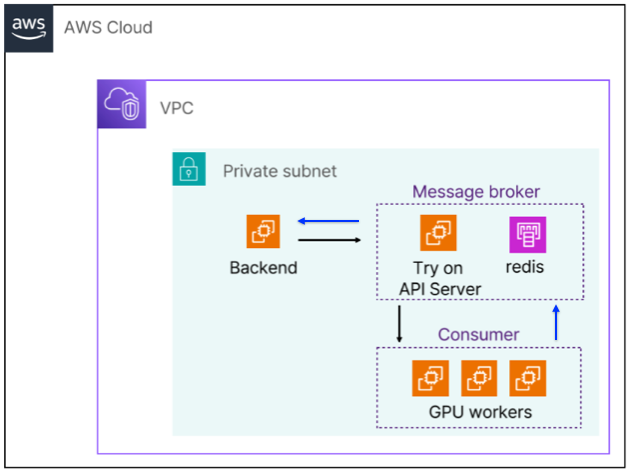
- spring에서 이미지 요청을 보내면 celery에서 redis에 결과 저장
- GPU worker가 테스크를 가져와 추론하고 결과를 반환
- 반환된 결과를 다시 redis에 저장
- spring은 pooling 방식으로 결과를 가져옴
- redis에 vton 결과가 저장되기 때문에 AutoScaling에 관계없이 안정적으로 이미지 결과를 가져올 수 있다.
회고
- 성과: 요청 유실 0%, GPU 서버와 메인 애플리케이션 서버의 완벽한 분리
- 배운 점: 비동기 처리의 중요성, Redis 활용
- 다음 과제:
- Pub/Sub 구조 도입으로 polling 제거
- WebSocket 푸시로 실시간 알림
- 오토스케일링 기반 GPU 워커 관리

공부 내용을 가볍게 적어놓는 블로그.