참조자료형
원시자료형과 참조자료형
자바스크립트에서 자료형(type)이란 값(value)의 종류입니다.
각각의 자료형은 고유한 속성과 메서드를 가지고 있습니다. 자료형은 크게 2가지로 나뉠 수 있는데 바로 원시자료형과 참조자료형입니다.
원시자료형 - number/string/boolean/undefined/null과 같은 자료형은 고정된 저장 공간을 차지합니다 이러한 특징을 가진 자료형을 원시자료형이라고 합니다.
참조자료형 - 배열/객체/함수와 같은 자료형은 대량의 데이터를 다루기에 적합하고 이를 참조자료형이라고 합니다.
원시 자료형의 특징
-
원시 자료형은 변수에 할당하면 메모리 공간에 값 자체가 저장됩니다.
-
원시 값을 갖는 변수를 다른 변수에 할당하면 원시 값 자체가 복사되어 전달됩니다.
-
원시 자료형은 변경 불가능한 값이다.
-
한 번 생산된 원시 자료형은 읽기전용(read only)값이다.
참조 자료형의 특징
-
참조 자료형은 변수에 할당하면 메모리 공간에 주소값이 저장된다.
-
참조 값을 갖는 변수를 다른 변수에 할당하면 주소값이 복사되어 전달된다.
-
참조 자료형은 변경이 가능한 값이다.

1.값 자체를 저장 vs 주소값을 저장
원시 자료형을 변수에 할당하면 값 자체가 할당됩니다.
num이라는 변수에 20을 할당하면 20이라는 원시 값 그자체가 공간에 저장됩니다.
참조 자료형을 변수에 할당하면 주소가 할당되는데
num이라는 배열에 [15,20]을 할당하면 15,20 이라는 값이 저장되는게 아닌 그 값을 담고 있는 주소가 할당됩니다.
여기서 값을 담고있는 공간은 힙이라고 부르는데 이곳 힙에 저장되어 있는 값의 주소를 참조 자료형에서 참조하여 값에 접근하는 방식입니다.
2. 값 자체를 복사 vs 주소값을 복사
어떤 변수에 저장되어 있는 원시 자료형을 다른 변수에 할당하면 어떻게 될까요?
let num = 20;
let copiedNum = num;원시 자료형은 값 자체가 복사됩니다. 즉, 변수 num과 변수 copiedNum은 동일하게 20이라는 값을 가집니다.

참조 자료형은 이와는 달리 주소값을 복사합니다.
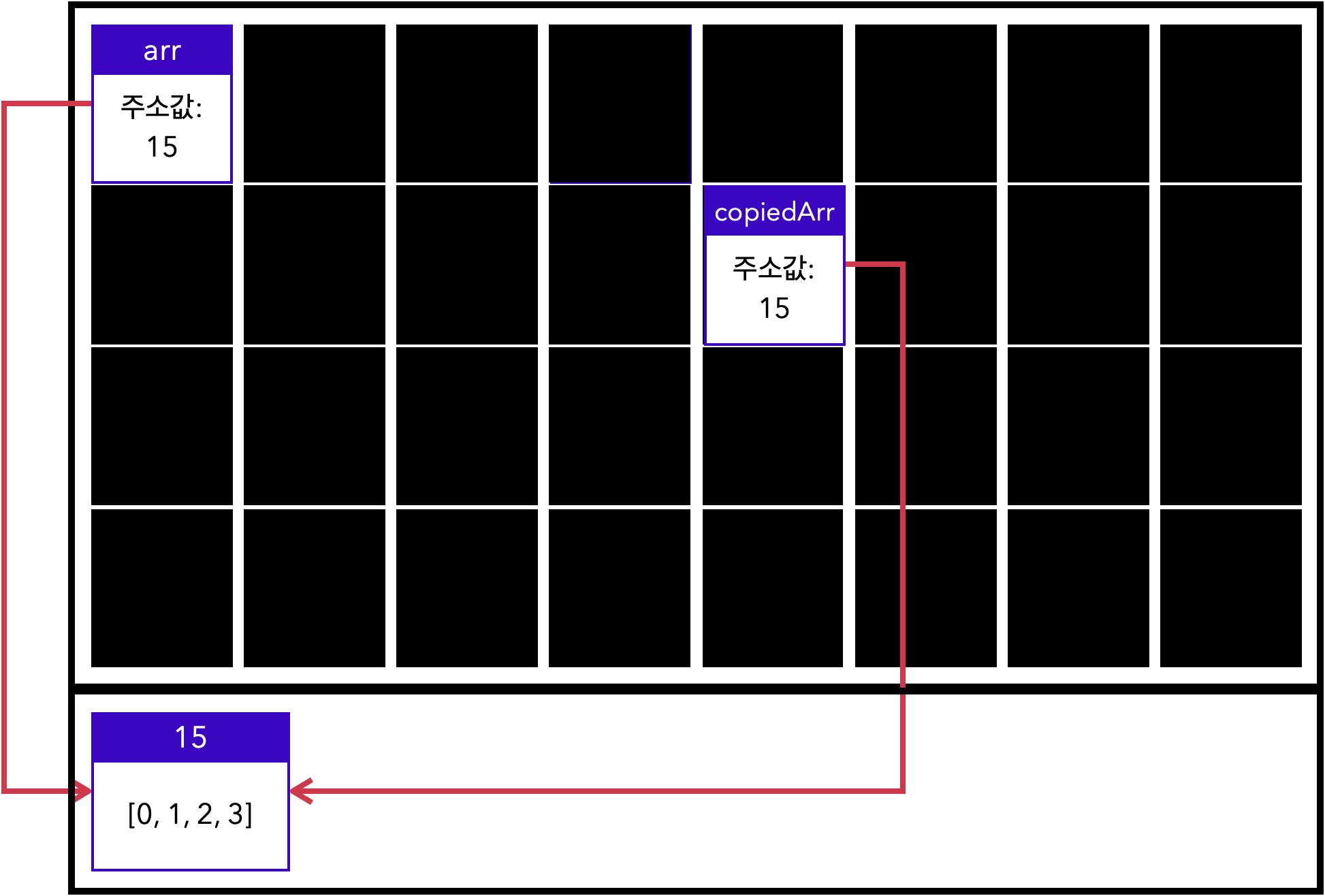
let arr = [0, 1, 2, 3];
let copiedArr = arr;즉 참조 자료형이 할당된 변수를 다른 변수에 할당하면, 이 두 변수는 같은 주소를 가리킵니다.
3. 변경 불가능한 값 vs 변경이 가능한 값
원시자료형
원시 자료형은 원본(num)에 다른 값을 재할당해도 복사본(copiedNum)에 영향을 미치지 않습니다. 반면에 참조 자료형은 원본(arr)을 변경하면 복사본(copiedArr)도 영향을 받는 것을 확인할 수 있었습니다.
값 자체를 복사하는 원시 자료형과는 달리, 참조 자료형을 할당한 변수를 다른 변수에 할당할 경우 같은 주소를 참조하고 있기 때문입니다.
또한 원시 자료형에서 한 번 생성된 원시 값은 변경되지 않습니다.
let num = 20; // 원시 값 선언
num = 30;이렇게 값을 재할당한다면 num이라는 변수가 참조하던 공간에 들어 있던 20이 30으로 변경될 것 같지만, 메모리 내부에서는 이처럼 동작하지 않습니다.
메모리 내부에서는 30이라는 원시 값을 저장하기 위한 새로운 공간을 확보한 뒤, 그 공간에 num이라는 이름을 붙이고 30을 저장합니다

이처럼 변수에 다른 값을 재할당해도 원시 값 자체가 변경된 것이 아니라 새로운 원시 값을 생성하고, 변수가 다른 메모리 공간을 참조합니다. 따라서 원시 자료형은 어떤 상황에서도 불변하는 읽기 전용 데이터입니다. 이는 원시 자료형이 높은 신뢰성을 가질 수 있는 요인이기도 합니다.
남아 있는 값 20은 어떻게 될까요? JavaScript 엔진은 이처럼 사용하지 않는 값을 자동으로 메모리에서 삭제합니다. 이런 기능을 가비지 콜렉터(garbage collector)라고 합니다. 그러나 가비지 콜렉터가 어느 시점에 진행되는지는 예측할 수 없습니다.
참조 자료형
원시 자료형의 경우 값의 크기가 거의 일정하기 때문에 새로운 공간을 확보하여 값을 복사하는 방법이 유용하지만, 크기가 일정하지 않은 참조 자료형의 경우 매번 값을 복사한다면 그만큼 효율성은 떨어질 수밖에 없습니다. 이런 이유로 참조 자료형은 변경이 가능하도록 설계되어 있습니다.
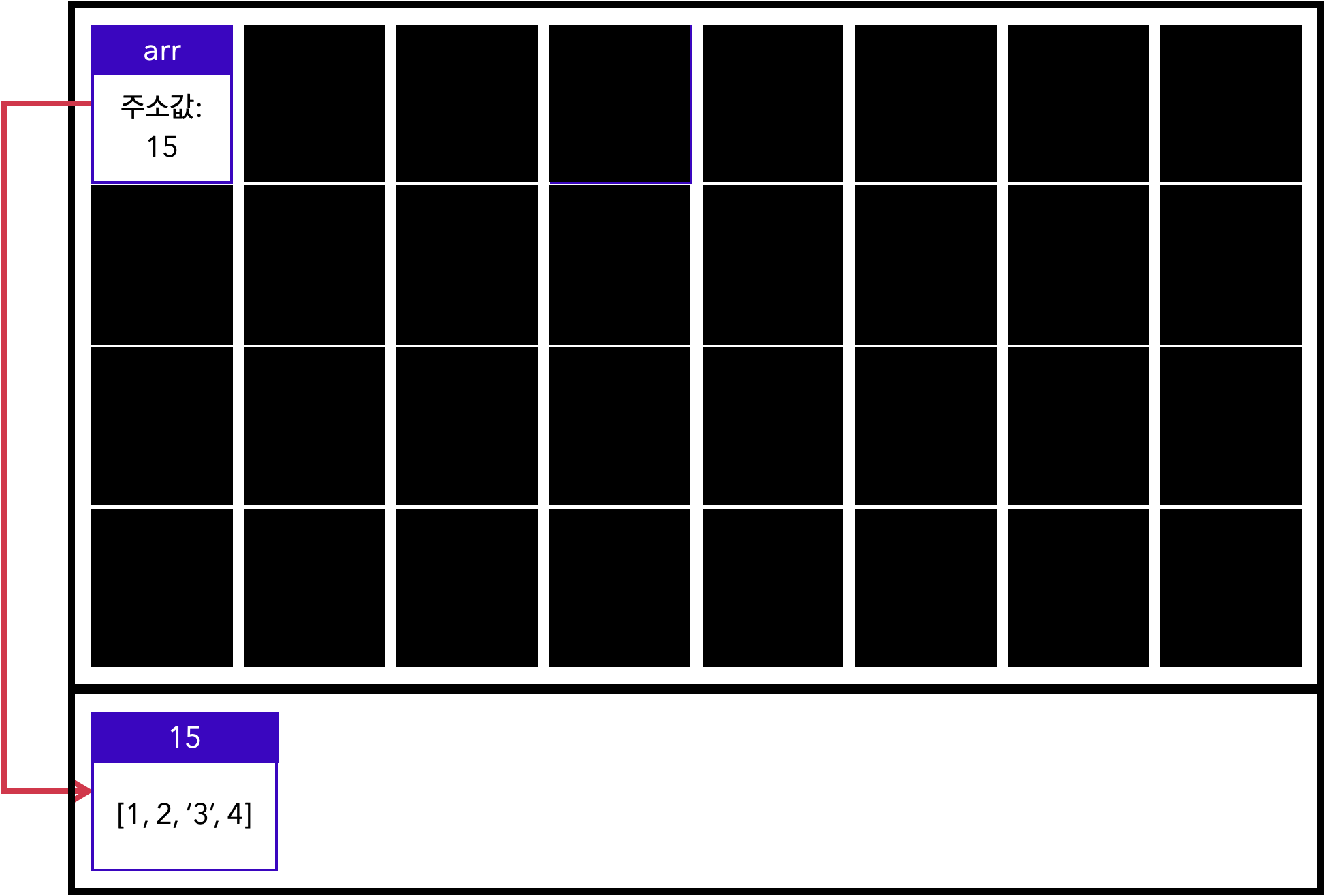
arr[3] = '3';
arr.push(4);
arr.shift();
console.log(arr); // [1, 2, '3', 4]위 코드가 실행되면, 변수가 참조하고 있는 주소에 저장되어 있는 값을 변경합니다.
*하지만 배열과는 달리 인덱스에 직접 다른 문자를 할당하여 값을 변경할 수 없습니다. 문자열도 원시 자료형이기 때문에 값을 변경할 수 없기 때문입니다.
얕은 복사와 깊은 복사
원시 자료형을 할당한 변수를 다른 변수에 할당하면 값 자체의 복사가 일어납니다. 값 자체가 복사된다는 것은 둘 중 하나의 값을 변경해도 다른 하나에는 영향을 미치지 않는다는 것을 의미합니다.
let num = 5;
let copiedNum = num;
console.log(num); // 5
console.log(copiedNum); // 5
console.log(num === copiedNum); // true
copiedNum = 6;
console.log(num); // 5
console.log(copiedNum); // 6
console.log(num === copiedNum); // false반면, 참조 자료형은 임의의 저장공간에 값을 저장하고 그 저장공간을 참조하는 주소를 메모리에 저장하기 때문에 다른 변수에 할당할 경우 값 자체가 아닌 메모리에 저장되어 있는 주소가 복사됩니다.
let arr = [0, 1, 2, 3];
let copiedArr = arr;
console.log(arr); // [0, 1, 2, 3]
console.log(copiedArr); // [0, 1, 2, 3]
console.log(arr === copiedArr) // true따라서 둘 중 하나를 변경하면 해당 변수가 참조하고 있는 주소에 있는 값이 변경되기 때문에 다른 하나에도 영향을 미치게 됩니다.
예를 들어 배열을 할당한 변수 arr를 변수 copiedArr에 할당한 후, copiedArr에 push() 메서드를 사용하여 배열의 요소를 추가하면, 원본 배열인 arr에도 동일하게 요소가 추가됩니다. arr이 참조하고 있던 주소가 copiedArr로 복사되어, 두 변수가 같은 주소를 참조하고 있기 때문입니다.
copiedArr.push(4);
console.log(arr); // [0, 1, 2, 3, 4]
console.log(copiedArr); // [0, 1, 2, 3, 4]
console.log(arr === copiedArr) // true다시 말해, 참조 자료형이 저장된 변수를 다른 변수에 할당할 경우, 두 변수는 같은 주소를 참조하고 있을 뿐 값 자체가 복사되었다고 볼 수 없습니다.
summary
- 원시 자료형이 할당된 변수를 다른 변수에 할당하면 값 자체의 복사가 일어난다. 따라서 원본과 복사본 중 하나를 변경해도 다른 하나에 영향을 미치지 않는다.
- 참조 자료형이 할당된 변수를 다른 변수에 할당하면 주소가 복사되어 원본과 복사본이 같은 주소를 참조한다.
- 참조 자료형의 주소값을 복사한 변수에 요소를 추가하면 같은 주소를 참조하고 있는 원본에도 영향을 미친다.
- 참조 자료형이 저장된 변수를 다른 변수에 할당할 경우, 두 변수는 같은 주소를 참조하고 있을 뿐 값 자체가 복사되었다고 볼 수 없다.
배열 복사하기
배열을 복사하는 방법은 크게 두 가지 방법이 있습니다. 배열 내장 메서드인 slice()를 사용하는 방법과 ES6에서 도입된 spread문법을 사용하는 방법입니다.
slice()
배열 내장 메서드인 slice()를 사용하면 원본 배열을 복사할 수 있습니다.
let arr = [0, 1, 2, 3];
let copiedArr = arr.slice();
console.log(copiedArr); // [0, 1, 2, 3]
console.log(arr === copiedArr); // false새롭게 생성된 배열은 원본 배열과 같은 요소를 갖지만 참조하고 있는 주소는 다릅니다.
주소가 다르기 때문에 복사한 배열에 요소를 추가해도 원본 배열에는 추가되지 않습니다.
copiedArr.push(4);
console.log(copiedArr); // [0, 1, 2, 3, 4]
console.log(arr); // [0, 1, 2, 3]spread syntax
spread syntax는 ES6에서 새롭게 추가된 문법으로, spread라는 단어의 뜻처럼 배열을 펼칠 수 있습니다. 펼치는 방법은 배열이 할당된 변수명 앞에 ...을 붙여주면 됩니다. 배열을 펼치면 배열의 각 요소를 확인할 수 있습니다.
let arr = [0, 1, 2, 3];
console.log(...arr); // 0 1 2 3spread syntax로 배열을 복사하기 위해서 배열을 생성하는 방법을 이해해야 합니다. 만약 같은 요소를 가진 배열을 두 개 만든 후 변수에 각각 할당한다면, 두 변수는 같은 주소를 참조할까요? 참조 자료형이기 때문에 각각 다른 주소를 참조합니다.
let num = [1, 2, 3];
let int = [1, 2, 3];
console.log(num === int) // false그렇다면 새로운 배열 안에 원본 배열을 펼쳐서 전달하면 어떻게 될까요? 원본 배열과 같은 요소를 가지고 있지만 각각 다른 주소를 참조하게 됩니다. 결과적으로 slice() 메서드를 사용한 것과 동일하게 동작합니다
let arr = [0, 1, 2, 3];
let copiedArr = [...arr];
console.log(copiedArr); // [0, 1, 2, 3]
console.log(arr === copiedArr); // false
copiedArr.push(4);
console.log(copiedArr); // [0, 1, 2, 3, 4]
console.log(arr); // [0, 1, 2, 3]객체 복사하기
Object.assign()
객체를 복사하기 위해서는 Object.assign()을 사용합니다.
let obj = { firstName: "coding", lastName: "kim" };
let copiedObj = Object.assign({}, obj);
console.log(copiedObj) // { firstName: "coding", lastName: "kim" }
console.log(obj === copiedObj) // false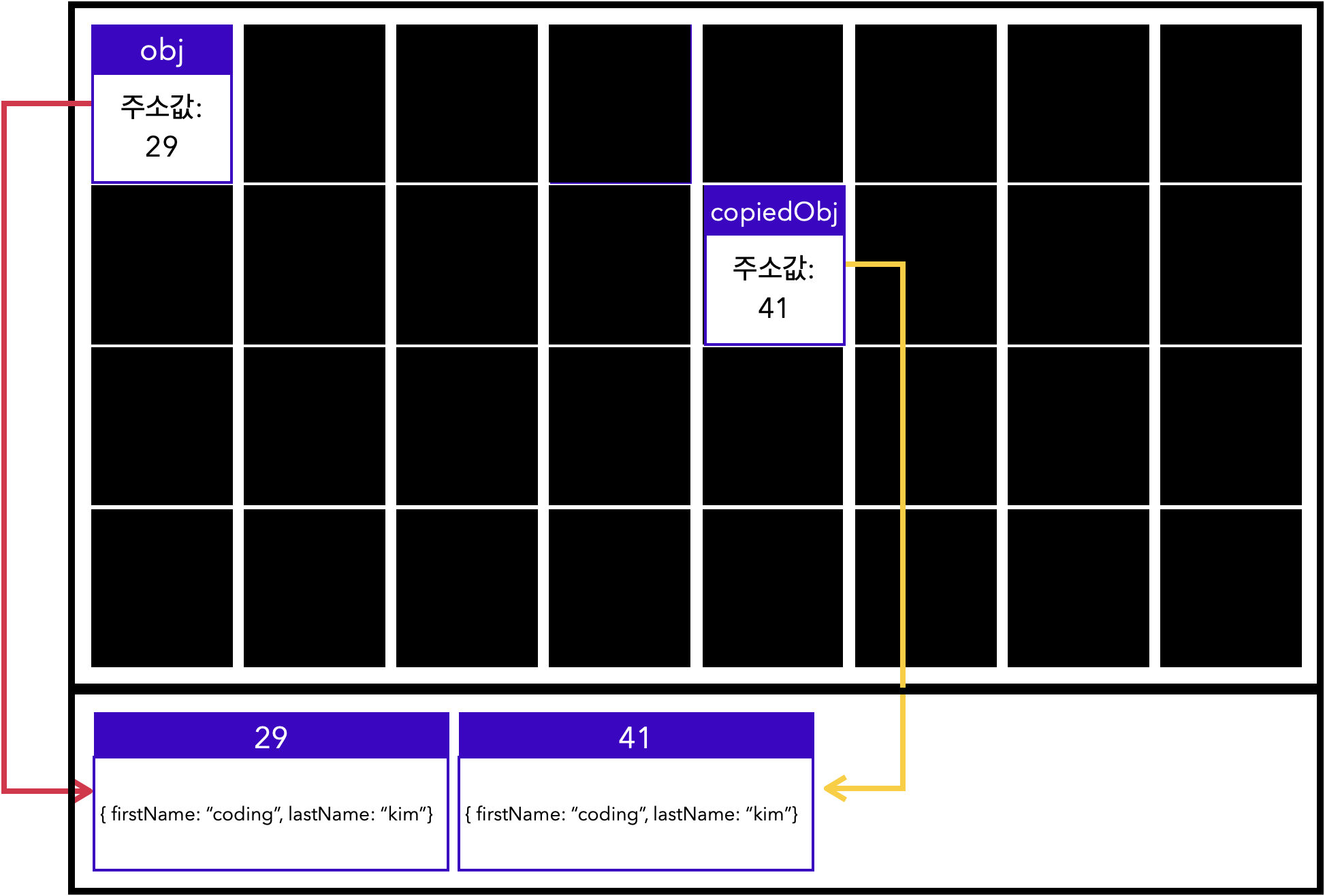
spread syntax
spread syntax는 배열뿐만 아니라 객체를 복사할 때도 사용할 수 있습니다.
let obj = { firstName: "coding", lastName: "kim" };
let copiedObj = {...obj};
console.log(copiedObj) // { firstName: "coding", lastName: "kim" }
console.log(obj === copiedObj) // false그러나 예외의 상황도 있습니다. 참조 자료형 내부에 참조 자료형이 중첩되어 있는 경우, slice(), Object.assign(), spread syntax를 사용해도 참조 자료형 내부에 참조 자료형이 중첩된 구조는 복사할 수 없습니다. 참조 자료형이 몇 단계로 중첩되어 있던지, 위에서 설명한 방법으로는 한 단계까지만 복사할 수 있습니다.
유저의 정보를 담고 있는 객체를 요소로 가지고 있는 배열 users를 slice() 메서드를 사용하여 복사했습니다.
let users = [
{
name: "kimcoding",
age: 26,
job: "student"
},
{
name: "parkhacker",
age: 29,
job: "web designer"
},
];
let copiedUsers = users.slice();
console.log(users === copiedUsers); // falseusers와 copiedUsers를 동치연산자(===)로 확인해 보면 false가 반환됩니다. 위에서 살펴본 바와 같이 각각 다른 주소를 참조하고 있기 때문입니다.
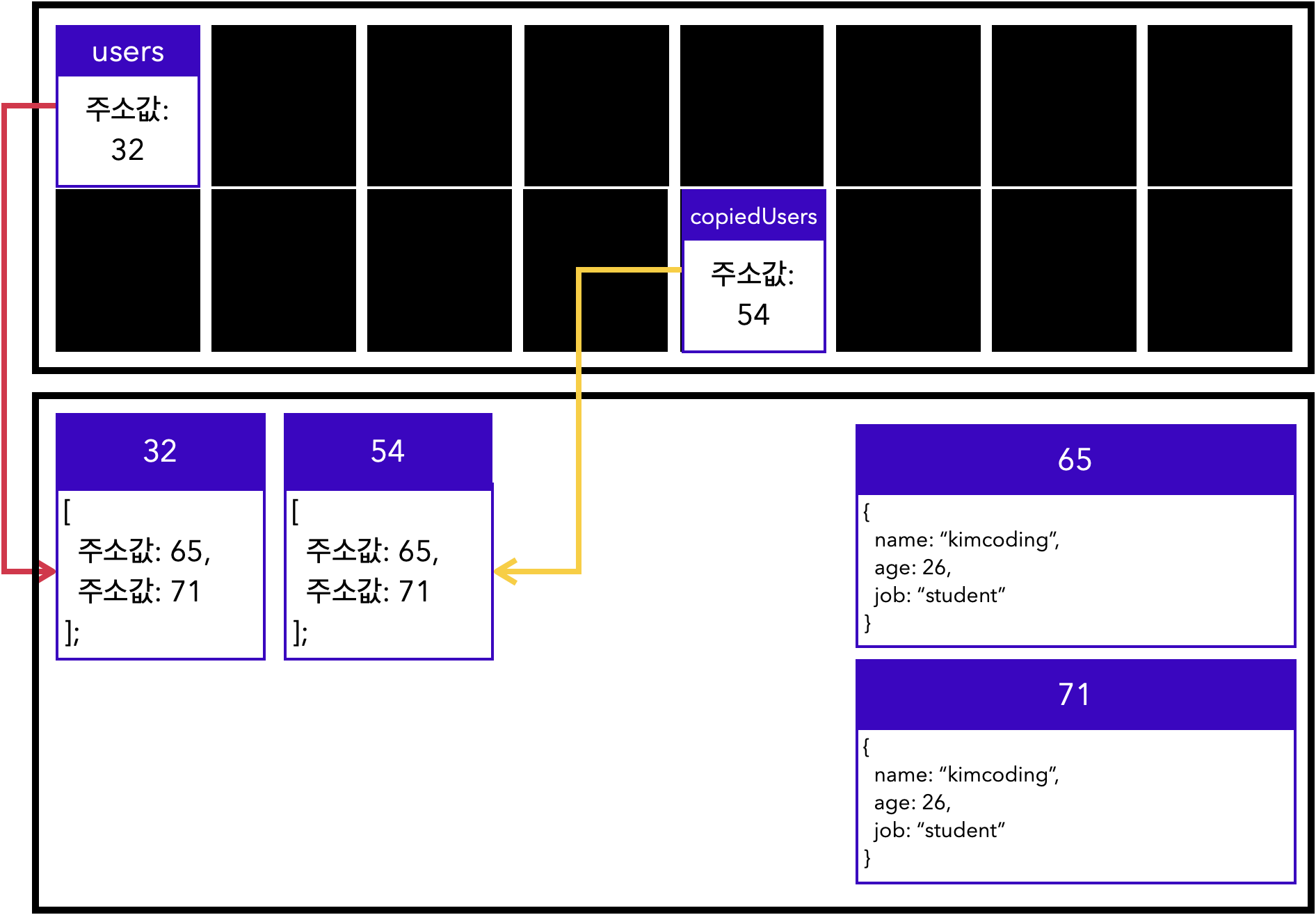
그러나 users와 copiedUsers의 0번째 요소를 각각 비교하면 true가 반환됩니다. users[0]과 copiedUsers[0]는 여전히 같은 주소값을 참조하고 있기 때문입니다.
console.log(users[0] === copiedUsers[0]); // true이처럼 slice(), Object.assign(), spread syntax 등의 방법으로 참조 자료형을 복사하면, 중첩된 구조 중 한 단계까지만 복사합니다. 이것을 얕은 복사(shallow copy)라고 합니다.
깊은복사
반면, 참조 자료형 내부에 중첩되어 있는 모든 참조 자료형을 복사하는 것은 깊은 복사(deep copy)라고 합니다. 그러나 JavaScript 내부적으로는 깊은 복사를 수행할 수 있는 방법이 없습니다.
단, JavaScript의 다른 문법을 응용하면 깊은 복사와 같은 결과물을 만들어 낼 수 있습니다.
JSON.stringify()와 JSON.parse()
JSON.stringify()는 참조 자료형을 문자열 형태로 변환하여 반환하고, JSON.parse()는 문자열의 형태를 객체로 변환하여 반환합니다. 먼저 중첩된 참조 자료형을 JSON.stringify()를 사용하여 문자열의 형태로 변환하고, 반환된 값에 다시 JSON.parse()를 사용하면, 깊은 복사와 같은 결과물을 반환합니다.
onst arr = [1, 2, [3, 4]];
const copiedArr = JSON.parse(JSON.stringify(arr));
console.log(arr); // [1, 2, [3, 4]]
console.log(copiedArr); // [1, 2, [3, 4]]
console.log(arr === copiedArr) // false
console.log(arr[2] === copiedArr[2]) // false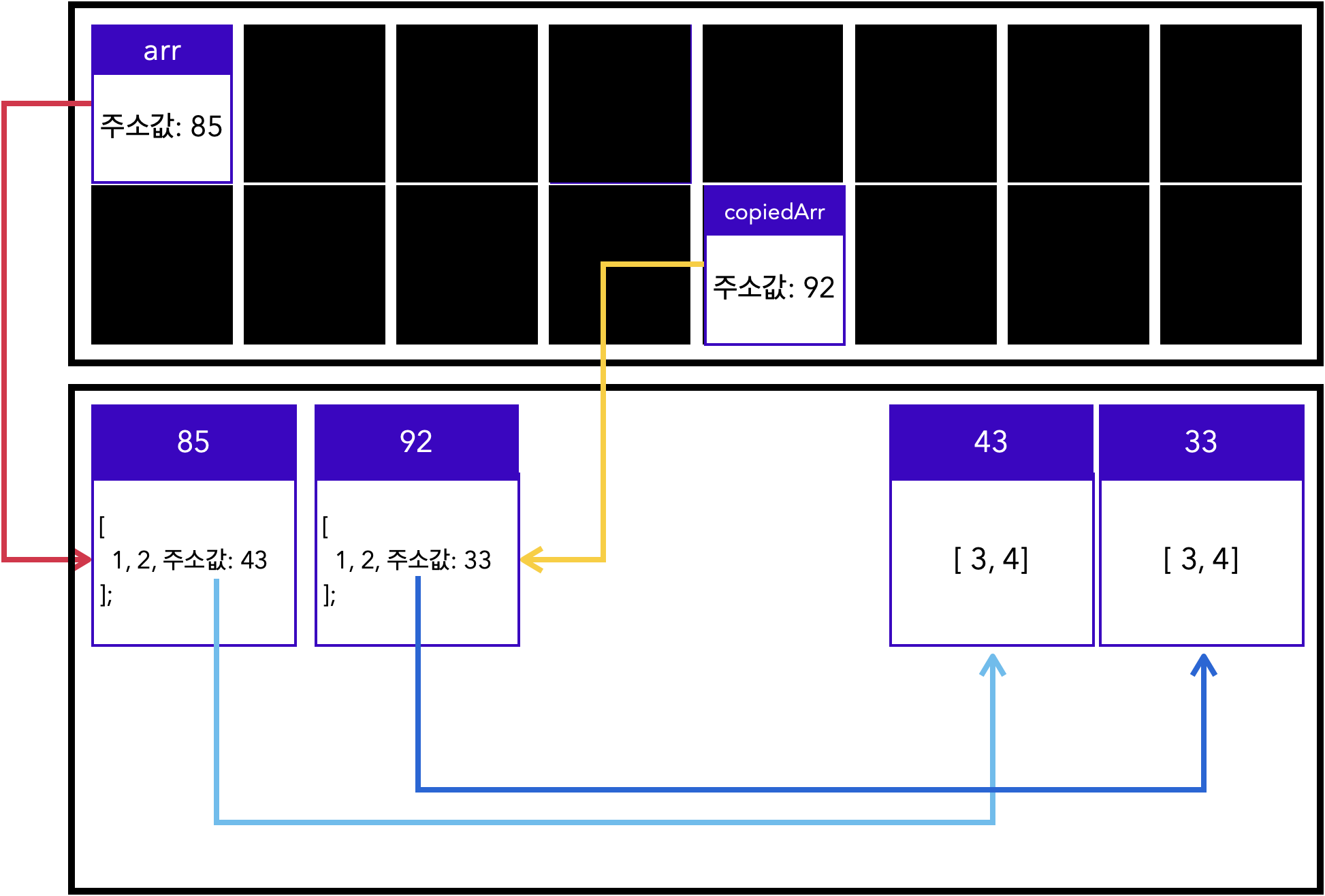
간단하게 깊은 복사를 할 수 있는 것처럼 보이지만, 이 방법 또한 깊은 복사가 되지 않는 예외가 존재합니다. 대표적인 예로 중첩된 참조 자료형 중에 함수가 포함되어 있을 경우 위 방법을 사용하면 함수가 null로 바뀌게 됩니다. 따라서 이 방법 또한 완전한 깊은 복사 방법이라고 보기 어렵습니다.
const arr = [1, 2, [3, function(){ console.log('hello world')}]];
const copiedArr = JSON.parse(JSON.stringify(arr));
console.log(arr); // [1, 2, [3, function(){ console.log('hello world')}]]
console.log(copiedArr); // [1, 2, [3, null]]
console.log(arr === copiedArr) // false
console.log(arr[2] === copiedArr[2]) // false외부 라이브러리 사용
완전한 깊은 복사를 반드시 해야 하는 경우라면, node.js 환경에서 외부 라이브러리인 lodash, 또는 ramda를 설치하면 됩니다.
lodash와 ramda는 각각 방법으로 깊은 복사를 구현해 두었습니다. 다음은 lodash의 cloneDeep을 사용한 깊은 복사의 예시입니다
const lodash = require('lodash');
const arr = [1, 2, [3, 4]];
const copiedArr = lodash.cloneDeep(arr);
console.log(arr); // [1, 2, [3, 4]]
console.log(copiedArr); // [1, 2, [3, 4]]
console.log(arr === copiedArr) // false
console.log(arr[2] === copiedArr[2]) // falsesummary
-
배열의 경우 slice() 메서드 또는 spread syntax 등의 방법으로 복사할 수 있다.
-
객체의 경우 Object.assign() 또는 spread syntax 등의 방법으로 복사할 수 있다.
-
위 방법으로 참조 자료형을 복사할 경우, 중첩된 구조 중 한 단계까지만 복사된다. (얕은 복사)
-
JavaScript 내부적으로는 중첩된 구조 전체를 복사하는 깊은 복사를 구현할 수 없다. 단, 다른 문법을 응용하여 같은 결과물을 만들 수 있다.
-
대표적인 JSON.stringify()와 JSON.parse()를 사용하는 방법이 있지만, 예외의 케이스가 존재한다. (참조 자료형 내부에 함수가 있는 경우)
-
완전한 깊은 복사를 반드시 해야 하는 경우, node.js 환경에서 외부 라이브러리인 lodash, 또는 ramda를 사용하면 된다.
스코프
자바스크립트에서 스코프는 "변수의 유효범위"로 사용됩니다.
let username = 'kimcoding';
if (username) {
let message = `Hello, ${username}!`;
console.log(message); // ?
}
console.log(message); // ?위의 코드에서 예상대는 출력은 무엇인가요?
정답은 Hello, kimcoding!" // ReferenceError 입니다
4번째 줄에서 message를 출력할 때는, 3번째 줄의 username을 바깥 스코프에서 가져왔으므로 정상적으로 출력됩니다.
그러나, 6번째 줄에서는 message라는 변수 자체가 안쪽 스코프에 선언되어 있으므로, 바깥쪽에서는 접근할 수 없습니다
이처럼 변수에 접근할 수 있는 범위가 존재합니다.
중괄호(블록) 안쪽에 변수가 선언되었는가, 바깥쪽에서 선언되었는가가 중요합니다. 이러한 범위를 우리는 스코프라고 부릅니다.
바깥쪽 스코프에서 선언한 변수는 안쪽 스코프에서 사용 가능합니다.
반면에, 안쪽에서 선언한 변수는 바깥쪽 스코프에서는 사용할 수 없습니다.
스코프는 "변수 접근 규칙에 따른 유효 범위" 입니다.
안쪽 스코프에서 바깥쪽 스코프로는 접근할 수 있지만, 반대는 불가능합니다. 이것이 첫번째 규칙입니다.
두번째 규칙은, 스코프는 중첩이 가능하다는 것입니다. 마치 중첩된 울타리와 같습니다.
특히 가장 바깥쪽 스코프는 전역스코프(global scope)
반대는 나머지는 지역스코프(local scope)라 부릅니다.
지역 스코프에서 선언한 변수는 지역 변수, 전역 스코프에서 선언한 변수는 전역 변수입니다.
스코프에서는 지역 변수는 전역 변수보다 더 높은 우선순위를 가집니다.
스코프의 종류
스코프는 두 가지 종류가 있습니다.
1. 블록 스코프(block scope)
- 중괄호를 기준으로 범위가 구분됩니다.
if(true) {
// 블록 스코프
}
for ( let i = 0; i< 10; i++) {
// 블록스코프
}2. 함수 스코프(function scope)
- function 키워드가 등장하는 함수 선언식 및 함수 표현식은 함수 스코프를 만듭니다.
*function getName(user) {
return user.name
}*
let getAge = *function(user) {
return user.age;
}*
*과 * 사이의 있는 범위가 함수 스코프입니다.블록스코프와 var키워드
for(let i =0; i<5; i++) {
console.log(i);
}
console.log('final i:', i);
// var 사용
for(var i =0; i<5; i++) {
console.log(i);
}
console.log('final i:', i);두 코드의 차이점은 무엇일까요?
첫번째 코드에서 console.log 결과는 레퍼런스 오류가 나옵니다. 범위블록에서 벗어났기 때문입니다.
두번째 코드에서는 5가 출력됩니다.
이유는 var코드는 블록 스코프를 무시하기 때문입니다.
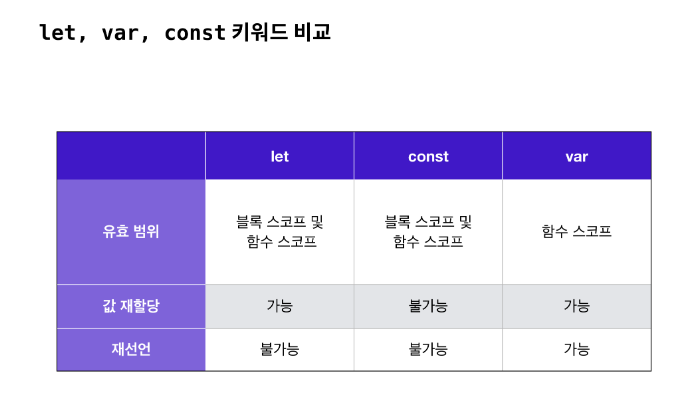
var 키워드와 let 키워드
변수를 정의하는 또다른 키워드 var
1. var 키워드로 정의한 변수는 블록 스코프를 무시하고, 함수 스코프만 따릅니다.
-> 그러나, 모든 블록 스코프를 무시하는 건 아닙니다. 화살표 함수의 블록 스코프는 무시하지 않습니다.
함수 스코프는 함수의 실행부터 종료까지이고, var 선언은 함수 스코프의 최상단에 선언됩니다.
선언 키워드 없는 선언은 최고 스코프에 선언됩니다.
함수 내에서 선언 키워드 없는 선언은, 함수의 실행 전까지 선언되지 않은 것으로 취급합니다.
보통 코드를 작성할 때 블록은 들여쓰기가 적용되고, 그 구분이 시각적으로 분명합니다. 따라서 많은 사람들은 블록 스코프를 기준으로 코드를 작성하고, 생각하기 마련입니다. 그러나 var는 이 규칙을 무시하므로, 코드를 작성하는 사람이 블록 스코프/함수 스코프에 대한 이해가 없으면 코드가 다소 혼란스러울 수 있습니다.
2. var 보다는 let 으로 변수 선언을 하는 것을 권장합니다.
var 키워드보다 let 키워드가 안전한 이유는 또 있습니다.
let 키워드는 재선언을 방지합니다. 실제로 코딩할 때에 변수를 재선언해야 할 필요가 있을까요?
const 키워드
값이 변하지 않는 상수를 정의할 때 쓰는 const
-
let 키워드와 동일하게, 블록 스코프를 따릅니다.
-
값의 변경을 최소화하여 보다 안전한 프로그램을 만들 수 있습니다. 값을 새롭게 할당할 일이 없다면,
const 키워드의 사용이 권장됩니다.
- 값을 재할당하는 경우, TypeError를 냅니다.
변수 선언할 때 주의할 점
windows 객체 (브라우저 only)
var로 선언된 전역 변수 및 전역 함수는 window 객체에 속하게 됩니다.->
브라우저에는 window라는 객체가 존재합니다.- 브라우저 창을 대표하는 객체- 그러나, 브라우저 창과 관계없이 전역 항목도 담고 있음
-> var로 선언된 전역 변수와 전역 함수가 window 객체에 속함
var myName = '김코딩';
console.log(window.myName); // 김코딩
function foo () {
console.log('bae');
}
console.log(foo === window. foo); // 트루 전역 변수는 최소화하세요
-> 전역 변수 : 어디서든 접근 가능한 변수-> 편리한 대신, 다른 함수 혹은 로직에 의해 의도되지 않은 변경이 발생할 수 있음- 부수 효과(side effect) 발생
let, const를 주로 사용하세요
->var는 블록 스코프를 무시하며, 재선언을 해도 에러를 내지 않습니다.
같은 스코프에서 동일한 이름의 변수를 재선언 하는 것은 버그를 유발합니다.
-> 전역 변수를 var로 선언하는 경우 문제가 될 수 있습니다.
- var로 선언한 전역 변수가 window 기능을 덮어씌워서 내장 기능을 사용할 수 없게 만들 수 있습니다.
선언 없는 변수 할당 금지
선언 키워드(var,let,const)없이 변수를 할당하지 마세요
function showAge() {
// age는 전역 변수로 취급됩니다.
age = 90;
console.log(age); // 90
}
showAge();
console.log(age); // 90
console.log(window.age); // 90사실 이런 것은 애초에 브라우저에서 방지해 준다면 더 안전하게 코드를 작성할 수 있을 것입니다. Strict Mode는 브라우저가 보다 엄격하게 작동하도록 만들어줍니다. 앞서 언급한 것처럼 "선언 없는 변수 할당"의 경우도 Strict Mode는 에러로 판단합니다. Strict Mode를 적용하려면, js 파일 상단에 'use strict' 라고 입력하면 됩니다. (따옴표 포함)
클로저
클로저의 정의
= "함수와 함수가 선언된 어휘적(lexical) 환경의 조합을 말한다. 이 환경은 클로저가 생성된 시점의 유효 범위 내에 있는 모든 지역 변수로 구성된다."
여기서 주목할 만한 키워드는 "함수가 선언"된 "어휘적(lexical) 환경"입니다.
특이하게도 자바스크립트는 함수가 호출되는 환경과 별개로 기존에 선언되어 있던 환경, 즉 어휘적 환경을
기준으로 변수를 조회하려고 합니다.
이와 같은 이유로 "외부 함수의 변수에 접근할 수 있는 내부 함수"를 클로저 함수라고 합니다.
클로저는 무엇인가요?
클로저는 함수와 그 함수 주변의 상태의 주소 조합입니다.
클로저는 함수와 그 함수가 접근할 수 있는 변수의 조합입니다.
클로저를 어떻게 구분할 수 있나요?
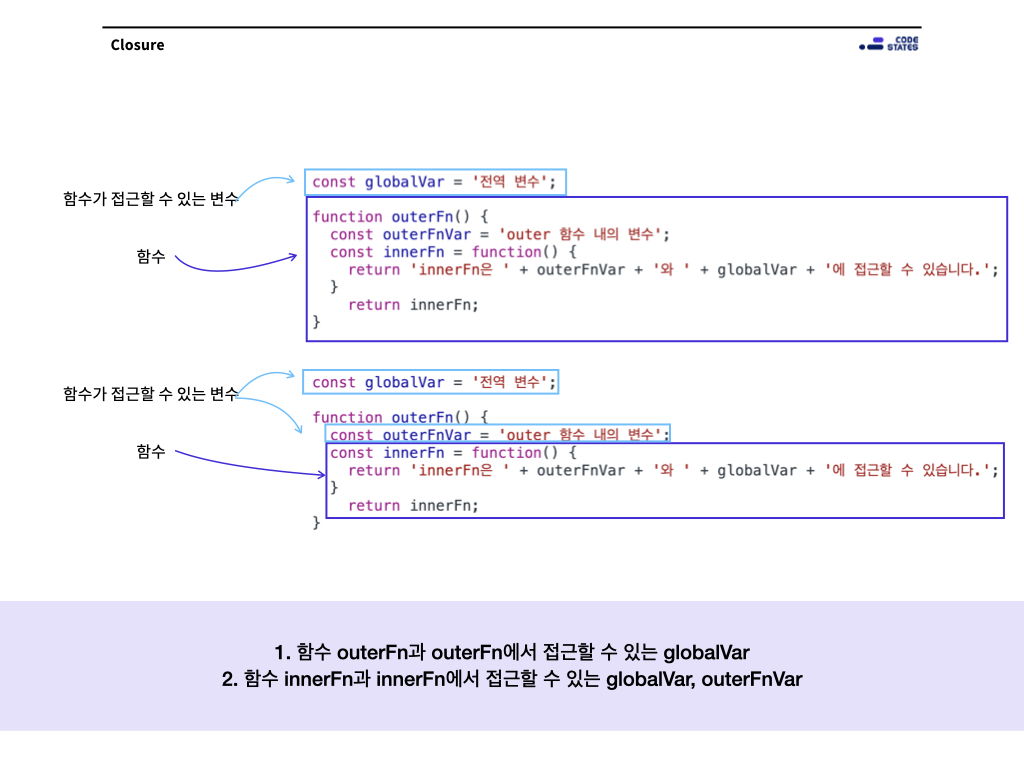
const globalVar = '전역 변수';
function outerFn() {
const outerFnVar = 'outer 함수 내의 변수';
const innerFn = function() {
return 'innerFn은 ' + outerFnVar + '와 ' + globalVar + '에 접근할 수 있습니다.';
}
return innerFn;
}위 코드에 있는 함수부터 찬찬히 살펴보겠습니다.
-
함수 outerFn에서는 변수 globalVar에 접근할 수 있습니다.
-
함수 innerFn에서는 변수 globalVar와 함수 outerFn 내부의 outerFnVar에 접근할 수 있습니다.
즉, 위 코드에서 클로저는 두 조합을 찾을 수 있었습니다.
-
함수 outerFn과 outerFn에서 접근할 수 있는 globalVar
-
함수 innerFn과 innerFn에서 접근할 수 있는 globalVar, outerFnVar
클로저는 왜 중요한가요?
변수의 접근 범위인 스코프와 비슷한 개념인데, 왜 따로 클로저만 구분을 할까요? 클로저의 함수는 어디에서 호출되느냐와 무관하게 선언된 함수 주변 환경에 따라 접근할 수 있는 변수가 정해지기 때문입니다.
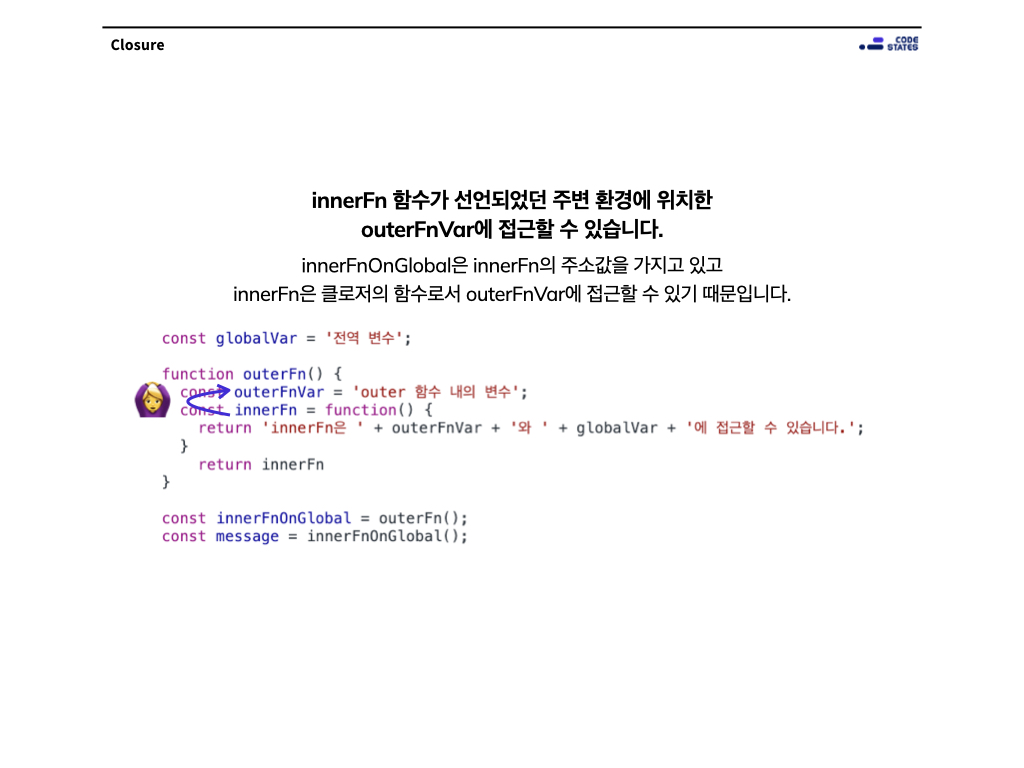
const globalVar = '전역 변수';
function outerFn() {
const outerFnVar = 'outer 함수 내의 변수';
const innerFn = function () {
return (
'innerFn은 ' + outerFnVar + '와 ' + globalVar + '에 접근할 수 있습니다.'
);
};
return innerFn;
}
const innerFnOnGlobal = outerFn();
const message = innerFnOnGlobal();
console.log(message); // ?
innerFnOnGlobal은 outerFn 내부의 innerFn의 주소값을 가집니다. 그다음 줄에서 innerFnOnGlobal을 호출합니다. 이때, innerFnOnGlobal은 innerFn 밖에 있기 때문에 outerFnVar에는 접근하지 못한다고 생각할 수 있는데, 실제 접근할 수 있습니다.

왜 접근할 수 있을까요? innerFn 함수가 최초 선언되었던 환경에서는 outerFnVar에 접근할 수 있기 때문입니다.
innerFnOnGlobal은 innerFn의 주소값을 가지고 있고, innerFn은 클로저로서 outerFnVar에 접근할 수 있기 때문입니다. 이 “환경”을 어휘적 환경(Lexical Environment)라고 합니다.
코드를 직접 실행해 봅시다.
실행 결과, 'innerFn은 outer 함수 내의 변수와 전역 변수에 접근할 수 있습니다.'라는 문자열이 리턴되어 message 변수에 담겨 로그로 출력되었습니다. 만약, 클로저가 JavaScript에 없는 개념이라면, outerFnVar에 접근할 수 없어 에러가 났을 겁니다.

디버거에서도 아래와 같이 클로저이기 때문에 접근할 수 있었던 outerFnVar는 따로 분류하고 있는 모습을 확인할 수 있습니다.
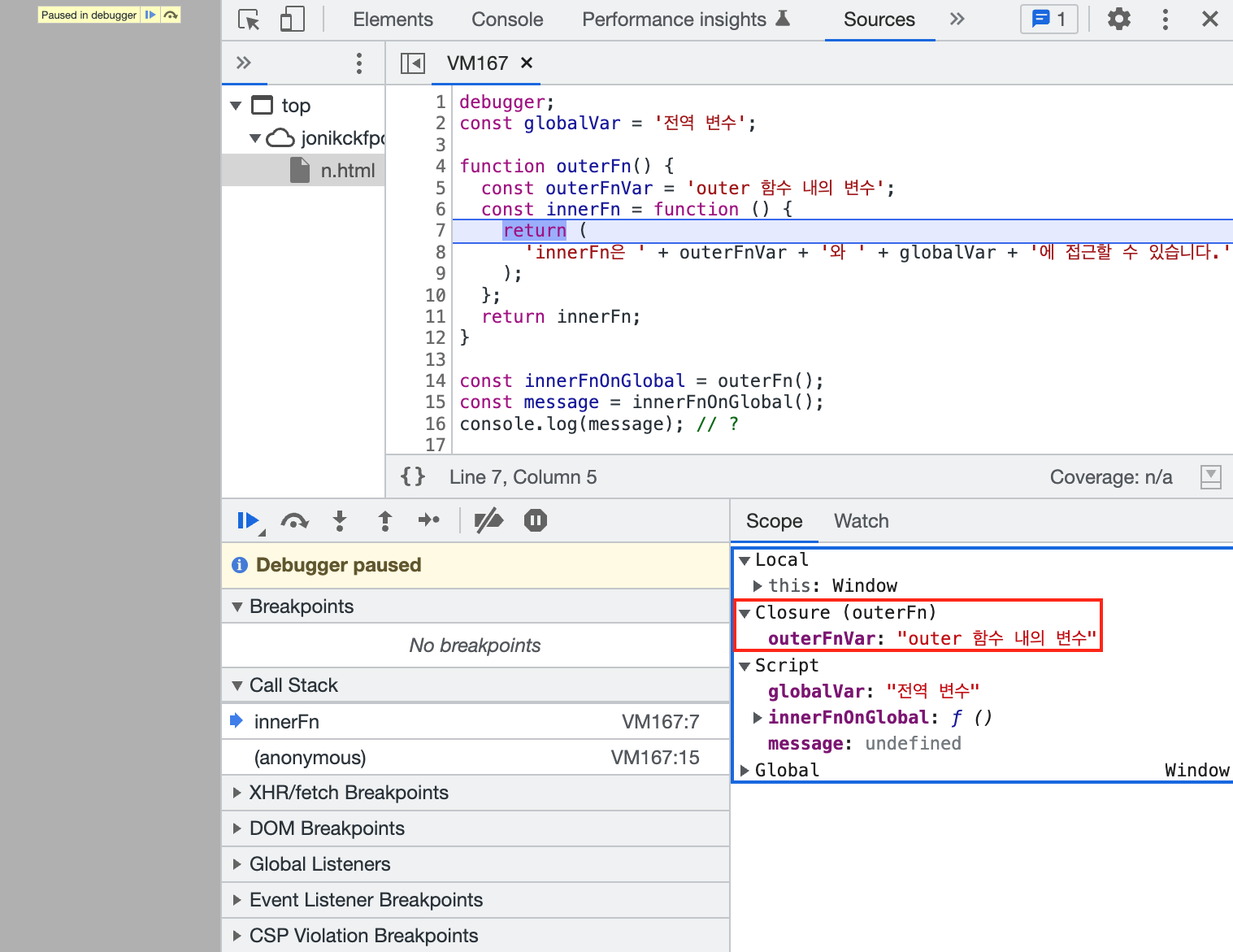
제 클로저를 사용할 때는 outerFn, innerFn처럼 함수가 함수를 리턴하는 패턴을 자주 사용하고, outerFn을 외부 함수, innerFn을 내부 함수라고 통칭합니다. 클로저에 대해 추가 학습 시 “외부 함수의 변수에 접근할 수 있는 내부 함수”등의 표현을 자주 접할 수 있으니 참고 바랍니다.
📝 Summary
클로저는 함수와 그 함수 주변의 상태의 주소 조합이다.
클로저의 함수는 어디에서 호출되느냐와 무관하게 선언된 함수 주변 환경에 따라 접근할 수 있는 변수가 정해진다
클로저 활용
데이터를 보존하는 함수
클로저를 활용하면 클로저의 함수 내에 데이터를 보존해 두고 사용할 수 있습니다.
일반적으로 함수 내부에 선언한 변수에는 접근할 수 없습니다. 매개변수도 마찬가지입니다.
function getFoodRecipe (foodName) {
let ingredient1, ingredient2;
return `${ingredient1} + ${ingredient2} = ${foodName}!`;
}
console.log(ingredient1); // ReferenceError: ingredient1 is not defined (함수 내부에 선언한 변수에 접근 불가)
console.log(foodName); // ReferenceError: foodName is not defined (매개변수에 접근 불가)클로저를 응용하면, 함수 내부에 선언한 변수에 접근할 수 있고, 매개변수에도 접근할 수 있습니다. 기존 함수 내부에서 새로운 함수를 리턴하면 클로저로서 활용할 수 있습니다. 즉, 리턴한 새로운 함수의 클로저에 데이터가 보존됩니다.
데이터를 보존하는 함수를 직접 만들어보겠습니다. 레시피를 제작하는 createFoodRecipe 함수를 만들어봅시다.
아래 코드에서는 getFoodRecipe가 클로저로서 foodName, ingredient1, ingredient2에 접근할 수 있습니다. 이때, createFoodRecipe('하이볼')으로 전달된 문자열 '하이볼'은 recipe 함수 호출 시 계속 재사용할 수 있습니다. createFoodRecipe 가 문자열 ‘하이볼’을 “보존”하고 있기 때문입니다.
function createFoodRecipe (foodName) {
let ingredient1 = '탄산수';
let ingredient2 = '위스키';
const getFoodRecipe = function () {
return `${ingredient1} + ${ingredient2} = ${foodName}!`;
}
return getFoodRecipe;
}
const recipe = createFoodRecipe('하이볼');
recipe(); // '탄산수 + 위스키 = 하이볼!'이를 더 잘 응용하기 위해 getFoodRecipe의 매개변수도 활용할 수 있게 코드를 아래와 같이 변경해 봅시다.
function createFoodRecipe (foodName) {
const getFoodRecipe = function (ingredient1, ingredient2) {
return `${ingredient1} + ${ingredient2} = ${foodName}!`;
}
return getFoodRecipe;
}
const highballRecipe = createFoodRecipe('하이볼');
highballRecipe('콜라', '위스키'); // '콜라 + 위스키 = 하이볼!'
highballRecipe('탄산수', '위스키'); // '탄산수 + 위스키 = 하이볼!'
highballRecipe('토닉워터', '연태고량주'); // '토닉워터 + 연태고량주 = 하이볼!'highballRecipe 함수는 문자열 ‘하이볼’을 보존하고 있어서 전달인자를 추가로 전달할 필요가 없고, 다양한 하이볼 레시피를 하나의 함수로 제작할 수 있었습니다.
커링
커링은 여러 전달인자를 가진 함수를 함수를 연속적으로 리턴하는 함수로 변경하는 행위입니다.
sum 함수는 두 전달인자(10, 20)를 덧셈하는 함수고, currySum은 첫 번째 전달인자 10을 리턴하는 함수로 전달해 줍니다. sum과 currySum이 같은 값을 리턴하기 위해서는 currySum 함수에서 리턴한 함수에 두 번째 전달인자 20을 전달하여 호출하면 됩니다. 이렇게 커링을 활용한 currySum과 같은 함수를 커링 함수라고 부르기도 합니다.
function sum(a, b) {
return a + b;
}
function currySum(a) {
return function(b) {
return a + b;
};
}
console.log(sum(10, 20) === currySum(10)(20)) // true언뜻 봐서는 일반 함수와 커링 함수의 차이가 느껴지지 않지만, 커링은 전체 프로세스의 일정 부분까지만 실행하는 경우 유용합니다. 아래 makePancake 함수는 팬케이크 제작 과정을 커링 함수로 만들었습니다. 팬케이크는 팬케이크 믹스를 만들어두었다가, 나중에 다시 만들 수도 있습니다. 반면, 커링이 적용되지 않은 makePancakeAtOnce 함수는 일부 조리 과정이 생략된 모습을 표현할 수 없습니다.
function makePancake(powder) {
return function (sugar) {
return function (pan) {
return `팬케이크 완성! 재료: ${powder}, ${sugar} 조리도구: ${pan}`;
}
}
}
const addSugar = makePancake('팬케이크가루');
const cookPancake = addSugar('백설탕');
const morningPancake = cookPancake('후라이팬');
// 잠깐 낮잠 자고 일어나서 ...
const lunchPancake = cookPancake('후라이팬');
function makePancakeAtOnce (powder, sugar, pan) {
return `팬케이크 완성! 재료: ${powder}, ${sugar} 조리도구: ${pan}`;
}
const morningPancake = makePancakeAtOnce('팬케이크가루', '백설탕', '후라이팬')
// 잠깐 낮잠 자고 일어나서 만든 팬케이크를 표현할 방법이 없다.이와 같이 커링은 함수의 일부만 호출하거나, 일부 프로세스가 완료된 상태를 저장하기에 용이합니다.
모듈 패턴
JavaScript에 class 키워드가 없던 시절 모듈 패턴을 구현하기 위해서 클로저를 사용했습니다. 모듈은 하나의 기능을 온전히 수행하기 위한 모든 코드를 가지고 있는 코드 모음으로, 하나의 단위로서 역할을 합니다. 모듈은 다른 모듈에 의존적이지 않고 독립적이어야 합니다.
다른 모듈에 의존적이지 않고 독립적이라면 기능 수행을 위한 모든 기능을 갖추고 있어야 하고, 또한 외부 코드 실행을 통해서 모듈의 속성이 훼손받지 않아야 합니다. 모듈의 속성을 꼭 변경해야 할 필요가 있는 경우에는 제한적으로 노출된 인터페이스에 의해 변경되어야 합니다. 이 특징은 클로저와 유사합니다. 자세히 알아보겠습니다.
아래 코드는 계산기의 최소한의 기능을 모듈 패턴으로 구현했습니다. displayValue는 makeCalculator의 코드 블록 외에 다른 곳에서는 접근이 불가능하지만, cal의 메서드는 모두 클로저의 함수로서 displayValue에 접근할 수 있습니다. 이렇게 데이터를 다른 코드 실행으로부터 보호하는 개념을 정보 은닉(information hiding)이라고 합니다. 이는 캡슐화(encapsulation)의 큰 특징이기도 합니다.
function makeCalculator() {
let displayValue = 0;
return {
add: function(num) {
displayValue = displayValue + num;
},
subtract: function(num) {
displayValue = displayValue - num;
},
multiply: function(num) {
displayValue = displayValue * num;
},
divide: function(num) {
displayValue = displayValue / num;
},
reset: function() {
displayValue = 0;
},
display: function() {
return displayValue
}
}
}
const cal = makeCalculator();
cal.display(); // 0
cal.add(1);
cal.display(); // 1
console.log(displayValue) // ReferenceError: displayValue is not defined이와 같이 클로저는 특정 데이터를 다른 코드의 실행으로부터 보호해야 할 때 용이합니다.
Summary
클로저는 주로 데이터를 보존하는 함수, 커링, 모듈 패턴으로 활용한다.
클로저를 이용하면 특정 함수가 데이터를 보존할 수 있다.
커링을 이용하면 함수의 일부만 호출하거나, 일부 프로세스가 완료된 상태를 저장할 수 있다.
모듈 패턴을 이용하면 특정 데이터를 다른 코드의 실행으로부터 보호할 수 있다.
