Confluent Hub 다운로드
Confluent Hub를 이용해 jdbc-connector를 리눅스에 다운을 받을 것이다.
wget http://client.hub.confluent.io/confluent-hub-client-latest.tar.gz
Confluent Hub를 사용하기 위해서 위 명령어를 사용해 다운을 받자.
그리고tar -xvf confluent-hub-client-latest.tar.gz이 명령어로 압축을 풀어준 뒤
환경변수 설정을 통해 설치를 완료한다.
환경변수 설정은 /etc 안에 bashrc 파일의 맨 아래에 2줄을 추가하면 된다.export CONFLUENT_HOME='/root/confluent' export PATH=$PATH:$CONFLUENT_HOME/bin이후
confluent-hub를 입력할 경우 2가지 오류가 발생할 것이다.
java: not found
ec2에 자바가 설치가 안된 것으로
yum install java-1.8.0-openjdk-devel.x86_64
위의 명령을 통해 자바를 다운 받자
Unable to detect Confluent Platform installation. Specify --component-dir and --worker-configs explicitly.
이것은 component와 worker.properties를 지정안해주어서 발생하는 문제로 Confluent가 설치된 폴더에 component와 config, config안에 worker.properties를 생성해준다.
mkdir ./component
mkdir ./config
vi worker.properties(비어있는 파일)
이후confluent-hub install confluentinc/kafka-connect-jdbc:latest --component-dir /경로/confluent/component --worker-configs /경로/confluent/config/worker.properties
위 명령어를 이용해 jdbc커넥터를 다운받아준다.
다운받은 jdbc커넥터는 component폴더 안에 kafka-connect 폴더 안에 lib에 위치하게 된다.
mysql connector 다운
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.27.tar.gz
위 명령어를 사용해 다운을 받고,tar -xvf mysql-connector-java-8.0.27.tar.gz
압축을 푼 뒤 /경로/confluent/component/confluentinc-kafka-connect-jdbc/lib에 다운받은 connector를 넣어준다.
cp mysql-connector-java-8.0.27/mysql-connector-java-8.0.27.jar /경로/confluent/component/confluentinc-kafka-connect-jdbc/lib
카프카 커넥트의 도커 컴포즈파일 생성
version: '3' services: connector: image: confluentinc/cp-kafka-connect:7.0.1 ports: - 8083:8083 environment: CONNECT_BOOTSTRAP_SERVERS: broker:29092 CONNECT_REST_PORT: 8083 CONNECT_GROUP_ID: "quickstart-avro" CONNECT_CONFIG_STORAGE_TOPIC: "quickstart-avro-config" CONNECT_OFFSET_STORAGE_TOPIC: "quickstart-avro-offsets" CONNECT_STATUS_STORAGE_TOPIC: "quickstart-avro-status" CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_REST_ADVERTISED_HOST_NAME: "localhost" CONNECT_LOG4J_ROOT_LOGLEVEL: DEBUG CONNECT_PLUGIN_PATH: "/usr/share/java,/etc/kafka-connect/jars" volumes: - /경로/confluent/component/confluentinc-kafka-connect-jdbc/lib:/etc/kafka-connect/jars
connector확인
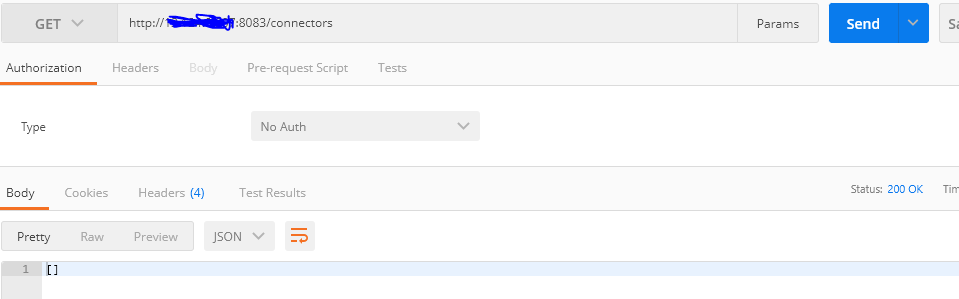
postman을 활용하여 connector가 제대로 실행되었는지 확인해보자
현재 아무런 connector가 없으니 빈값이 나오는 것이 정상이다.
카프카 서버에서 토픽을 살펴보면 3개의 토픽이 새로 생성된 것을 알 수 있을 것이다.

connector 생성
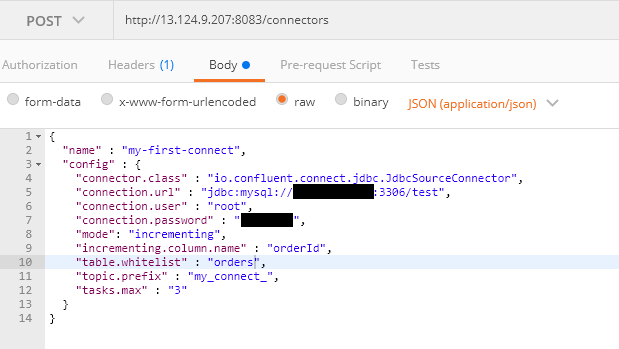
source 커넥터 생성
{ "name" : "my-first-connect", "config" : { "connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url" : "jdbc:mysql://호스트이름:3306/사용할 데이터베이스", "connection.user" : "root", "connection.password" : "passwd", "mode": "incrementing", "incrementing.column.name" : "id", "table.whitelist" : "test", "topic.prefix" : "my_connect_", "tasks.max" : "3" } }
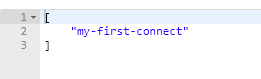
위의 post메서드를 보낼 경우 아래와 같이 connector가 생성된 것을 볼 수 있다.
또한 connector의 상태를 확인할 수도 있다.

sink connector
{ "name":"my-order-sink-connect", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:mysql://13.124.9.207:3306/orderservice", "connection.user":"root", "connection.password":"It12345!", "auto.create":"false", "auto.evolve":"false", "delete.enabled":"false", "tasks.max":"1", "topics":"my_connect_order_product", "table.name.format":"orderservice.order_product", "pk.mode":"record_value", "pk.fields":"order_id", "insert.mode":"upsert" } }table.name.format : 테이블 지정하기(db명.table명)
insert.mode : insert,upsert,update모드가 있는데, insert와 update 모두 지원하는 upsert를 할 경우 반드시 pk.mode와 pk.fields를 명시해주어야 한다.
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00007f5dbbe00000, 262144, 0) failed; error='메모리를 할당할 수 없습니다' (errno=12) 에러
카프카를 실행시키기 위해서는 적어도 ram 1G는 필요하다. 하지만 내가 빌린 aws의 free티어의 경우 메모리가 1G가 되지 못했다.
그래서 swap을 사용하여 ram의 용량을 추가하였다.
위의 사진은 swap을 사용하기 전 나의 메모리 상태이다.
swap공간을 사용해보자swap공간 사용하기
swap공간을 사용하기 위해 swapfile을 생성해야 한다.
$ touch /var/spool/swap/swapfile
$ dd if=/dev/zero of=/var/spool/swap/swapfile count=2048000 bs=1024
위의 명령어를 이용해 2G의 용량을 할당하였다.
이후 해당 파일을 SWAP으로 등록하는 과정이 필요한데 아래의 명령이 그것이다.
$ mkswap /var/spool/swap/swapfile
$ swapon /var/spool/swap/swapfile
마지막으로 파일시스템 테이블에 해당 SWAP파일을 등록해야 한다.
vi /etc/fstab
위 명령어를 입력하고 마지막 줄에 아래 한줄을 추가해주면 된다.
/var/spool/swap/swapfile none swap defaults 0 0
출처 https://n1tjrgns.tistory.com/276

log오류
위 그림처럼 log4j 오류가 날 경우 kafka connect의 이미지 버전을 6.1.4로 낮추면 해결 가능하다.
image: confluentinc/cp-kafka-connect:7.0.1대신
image: confluentinc/cp-kafka-connect:6.1.4

오류 [main] WARN org.apache.kafka.clients.ClientUtils - Couldn't resolve server broker:29092 from bootstrap.servers as DNS resolution failed for broker
29092포트의 호스트이름이 잘못된 오류이다.
환경변수 설정시
CONNECT_BOOTSTRAP_SERVERS는 카프카 서버를 지정하는 것이다.
그러므로 앞에서 카프카 서버의 컨테이너 명을 정확히 입력하고 카프카 포트번호 또한 정확히 입력해야 한다.
Docker no space left on device 에러
docker system prune --all --force --volumes
위 명령어로 공간을 확보하면 된다.
카프카 커넥트 mysql접속 오류
같은 ec2에서 설치하거나 다른 ec2의 경우 bind-address와 같이 외부 접속을 허용하는 설정을 해주어야 한다.
우리는 rds를 이용해 해당 문제를 해결함
메시지 양식
bigint => int64
primary key => optional :false
foreign key => optional : false
이후 다른 record들은 모두 optional : true로 설정
아래는 예시
또한 schema,payload,field로 메시지를 보내야지 productpayload라든지 이런 이름을 사용하면 싱크커넥트가 동작하지 않는다.{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"field":"order_product_id"},{"type":"string","optional":true,"field":"order_product_date"},{"type":"string","optional":true,"field":"order_product_main_img"},{"type":"string","optional":true,"field":"order_product_name"},{"type":"int32","optional":true,"field":"order_product_price"},{"type":"int32","optional":true,"field":"order_product_qty"},{"type":"string","optional":true,"field":"order_product_status"},{"type":"int64","optional":true,"field":"product_id"},{"type":"int64","optional":true,"field":"seller_id"},{"type":"int64","optional":true,"field":"orders_id"}],"optional":false,"name":"order_product"},"payload":{"order_product_id":1,"order_product_date":"saddsa","order_product_main_img":"dsadsa","order_product_name":"dsasda","order_product_price":1000,"order_product_qty":10,"order_product_status":"dsadsa","product_id":1,"seller_id":1,"orders_id":1}}결론
메시지양식인 kafka~~Dto를 만들때, 아래와 같이 schema와 payload는 꼭 바꾸지말고 써야 한다.
public class KafkaOrderProductDto implements Serializable { private Schema schema; private OrderProductPayload payload; }
메시지 보관 기간
kafka컨테이너에
/etc/kafka/server.properties이 부분을 보면 카프카 서버의 설정 파일을 확인할 수 있다.
보관 기간에 대한 옵션은 아래와 같이 4가지로 볼 수 있다.
보관주기 옵션 항목
log.retention.bytes : byte 단위 기준으로 데이터 보관
log.retention.ms : 초 단위 기준으로 데이터 보관
log.retention.minutes : 분 단위 기준으로 데이터 보관
log.retention.hours : 시간 단위 기준으로 데이터 보관, 해당 옵션이 168으로 기본으로 적용되어 있음
기본값은 168시간 = 7일이며 이 값을 바꾸고 싶다면,/etc/kafka/server.properties이 파일을 열어서 아래 부분의 값을 변경하면 된다.# The minimum age of a log file to be eligible for deletion due to age log.retention.hours=168
kafka 설정 시 재시도 안되는 현상
kafkaListenerContainerFactory.getContainerProperties().setPollTimeout(3000);
kafkaListenerContainerFactory.getContainerProperties().setSyncCommits(true);
파티션 생성법
kafka-topics --create --bootstrap-server broker:9092 --topic payment-order --partitions 2 --replication-factor 1
kafka-topics --create --bootstrap-server broker:9092 --topic product-order --partitions 2 --replication-factor 1
