Kafka Connect란?
간략적으로 카프카를 사용한다는 의미를 말하자면 데이터를 publish하는 Producer와 데이터를 subcribe하는 Consumer를 주축하고 그 데이터를 토픽에 집어넣어 사용한다는 의미이다.
하지만 이러한 구성이 많아질수록 Producer와 Consumer를 구축하는데 비용과 시간, 반복작업이 많아질 것이다.이러한 문제를 해결하기 위해 나온 것이 바로 kafka connect이다.
즉, Kafka Connect란 더 간편하게 효율적으로 데이터파이프라인을 구축하는 방법이다.
kafka connect는 Microservice에서 직접 DB에 대한 커넥션과 처리작업을 하지 않고 관련 작업은 Kafka에 일임 하는 역활을 한다. 그렇기 때문에 비용,시간이 단축되는 것이다.
Kafka Connector
커넥터는 데이터를 어디서(source) 복사하는지와, 어디에다(sink) 붙여넣어야 하는지를 정의한다.
카프카 커넥트와 카프카 커넥터의 차이
- 카프카 커넥트 : 프레임워크이다.
- 카프카 커넥터 : 커넥트 안에 들어가는 플러그인의 한 종류이다.
카프카 커넥터는 2가지 종류가 존재한다.
- Source Connector - Source System의 데이터를 카프카 토픽으로 Publish 하는 커넥터. 즉, Producer의 역할을 하는 커넥터
- Sink Connector - 카프카 토픽의 데이터를 Subscribe해서 Target System에 반영하는 커넥터. 즉, Consumer의 역할을 하는 커넥터
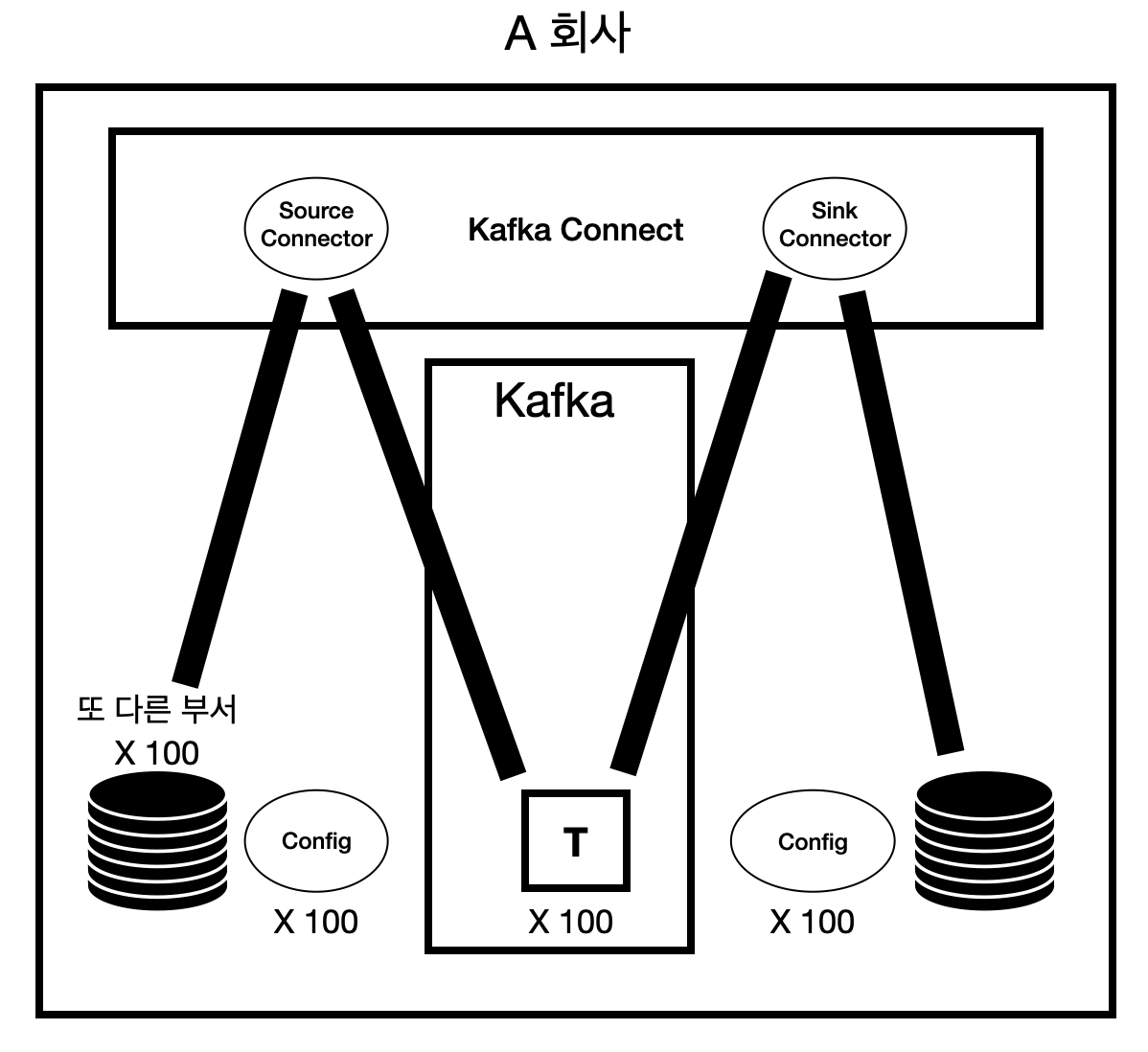
출처: https://bagbokman.tistory.com/8?category=1021620
Kafka connect 실행
Kafka connect를 실행하기 위해서는 zookeeper와 kafka서버가 동작해야 한다.
그리고 connect-distributed 파일을 실행시키면 된다.
아래는 윈도우 사용자의 실행방법이다.(실행 시 bat파일과 설정파일들은 confluent폴더에 들어가 있다.)
ex)./bin/windows/connect-distributed.bat ./etc/kafka/connect-distributed.properties
kafka connect RestAPI 호출
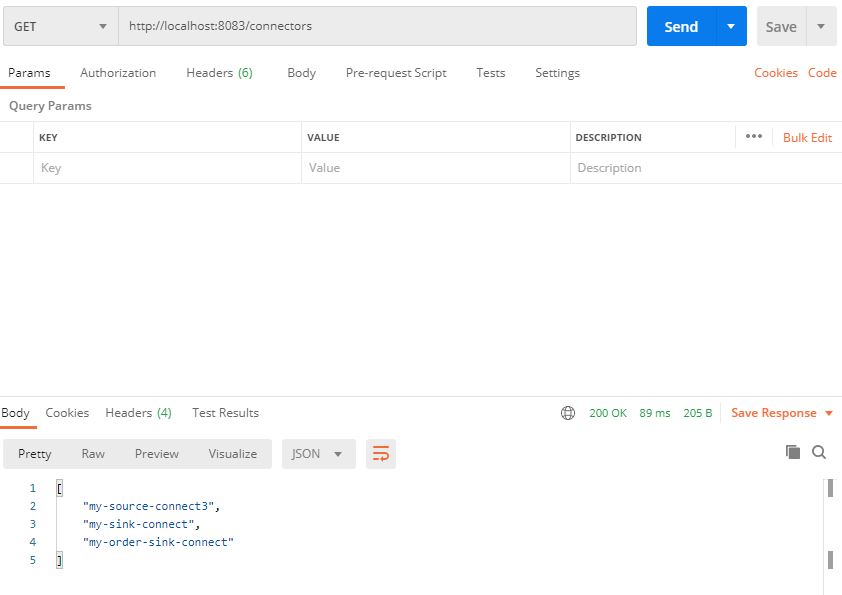
kafka connect의 경우 RestAPI를 사용할 수 있기 때문에 RestAPI를 이용해 커넥터를 관리할 수 있다.
카프카 커넥트의 기본적인 포트번호는 8083이다. 아래는 Postman을 활용한 RestAPI 조회이다.
- GET /connectors – 모든 커넥터를 조회한다.
- GET /connectors/{name} – {name}을 갖는 커넥터의 정보를 조회한다.
- POST /connectors – 커넥터를 생성, Body쪽에는 JSON Object 타입의 커넥터 config정보가 있어야한다.
- GET /connectors/{name}/status – 이 커넥터가 running인지, failed인지 paused 인지 현재 상태를 조회한다.
- DELETE /connectors/{name} – {name}을 갖는 커넥터를 삭제시킨다.
- GET /connector-plugins – 카프카 커넥터 클러스터 내부에 설치된 플러그인들을 조회한다.
커넥터 생성 시 사용될 BODY format
아래는 POST방식으로 SOURCE커넥터를 생성할 때 사용하는 BODY 양식의 예시이다.
{ "name" : "my-first-connect", "config" : { "connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url" : "jdbc:mysql://127.0.0.1:3306/testdb", "connection.user" : "root", "connection.password" : "passwd", "mode": "incrementing", "incrementing.column.name" : "id", "table.whitelist" : "test", "topic.prefix" : "my_connect_", "tasks.max" : "3" } }
- connection.url, connection.user, connection.password : DB에 접속하기 위한 설정 정보이다.
- connection.url 이게 제일 골치아프다.(드라이버를 제대로 확인하기 (mariadb인지 mysql인지 등등))
- table.whitelist속성의 경우 외부 db의 로드할 대상의 테이블을 지정한다.
- topic-prefix의 경우 카프카에 데이터를 넣을때 토픽 명을 결정할 접두어를 지정한다.
sink커넥터를 생성할때 사용할 설정 양식
{ "name":"my-order-sink-connect", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:mariadb://localhost:3306/cloudtest", "connection.user":"root", "connection.password":"passwd", "auto.create":"true", "auto.evolve":"true", "delete.enabled":"false", "tasks.max":"1", "topics":"orders" } }mode
connector에 설정할 수 있는 모드에는 3가지가 있는데, bulk , incrementing , timestamp가 있다.
- bulk : 데이터를 폴링할 때 마다 전체 테이블을 복사
- incrementing : 특정 컬럼의 중가분만 감지되며, 기존 행의 수정과 삭제는 감지되지 않음
- incrementing.column.name : incrementing 모드에서 새 행을 감지하는 데 사용할 컬럼명
- timestamp : timestamp형 컬럼일 경우, 새 행과 수정된 행을 감지함
- timestamp.column.name : timestamp 모드에서 COALESCE SQL 함수를 사용하여 새 행 또는 수정된 행을 감지
- timestamp+incrementing : 위의 두 컬럼을 모두 사용하는 옵션
timestamp와 incrementing을 둘다 사용할 경우 두 컬럼에 대해 아래와 같이 각각 변경감지를 설정할 수 있다.{ "name": "source_tb_iv_member_join", "config": { "connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url" : "jdbc:mysql://localhost:3306/kafka_test", "connection.user" : "root", "connection.password" : "qwer1234", "topic.prefix" : "topic_", "poll.interval.ms" : 2000, "table.whitelist" : "tb_iv_member_join", "mode" : "timestamp+incrementing", "incrementing.column.name":"mem_uno", "timestamp.column.name":"mem_join_date", "topic.creation.default.replication.factor" : 1, "topic.creation.default.partitions" : 1 "validate.non.null":"false" } }※ 기본적으로 JDBC 커넥터는 모든 incrementing 및 timestamp 테이블에 ID/타임스탬프로 사용되는 열에 대해 NOT NULL이 설정되어 있는지 확인한다.
※ 만약 변경감지하는 컬럼에 NOT NULL이 설정되어 있지 않다면"validate.non.null": false라는 설정을 추가해야 한다.(혹은 스키마를 다시 수정하던지)
※ 이러한 설정들에도 불구하고 카프카는 데이터 추가에 대해서만 사용하는 것이 좋다.
(변경감지를 두개 컬럼만이 하게 됨 등등의 문제점 발생) => 따라서 이벤트소싱, CQRS 등을 활용하는 것이 좋다
출처 : https://presentlee.tistory.com/7
source 커넥터 없이 sink 커넥터에 데이터 전송하기
위의 예시처럼 source 커넥터를 사용한다면 source db에 데이터가 insert될때만 토픽에 메시지를 전달하게 된다.(id 컬럼을 변경감지(모니터링)하기 때문에)
이 경우 동일한 서비스를 여러대 실행할 때, 데이터 동기화 문제가 발생할 수 있다.
이를 해결하기 위해서 producer가 직접 sink 커넥터에 연결된 토픽에 직접 메시지를 보내는 방식을 사용할 수 있다.(거기에 공유 db를 사용하면 된다.)메시지 format
직렬화를 어떤것으로 이용하느냐에 따라 (StringSerializer,avro등등) 메시지 양식이 다르다.
우린 문자열 방식의 직렬화를 사용할 것(StringSerializer)이기 때문에 아래의 양식을 따른다.
- schema : 테이블의 구조
- fields : 메시지에 담길 데이터의 정보
- payload : 실제 데이터 값들이 들어가는 곳
위의 사진은 실제로 consumer가 받은 메시지의 내용이다.
메시지 양식은 key:value로 이뤄진 json형식이며, 이래와 같다.{ "schema":{ "type":"struct", "fields":[ {"type":"string","optional":true,"field":"order_id"}, {"type":"string","optional":true,"field":"user_id"}, {"type":"string","optional":true,"field":"product_id"}, {"type":"int32","optional":true,"field":"qty"}, {"type":"int32","optional":true,"field":"unit_price"}, {"type":"int32","optional":true,"field":"total_price"} ], "optional":false,"name":"orders" }, "payload":{ "order_id":"887dfd6a-5bb7-4742-90e8-a793808e93f6", "user_id":"ea45be72-1806-44ae-b528-ebec466d0d61", "product_id":"CATALOG-002", "qty":20,"unit_price":2000, "total_price":40000 } }위와 같은 양식으로 producer에서 메시지를 보낼 수 있다.

