분류
이용하는 정보에 따라
전역 정보
- 라우터들이 네트워크에 대한 모든 것을 알고 있다.
- 링크 상태 알고리즘이 해당된다.
분산된 정보
- 라우터는 오직 물리적으로 연결된 이웃에 대한 정보만 알고 있다.
- 예를 들어 이웃이 누구인지, 이웃으로 가는 링크의 비용, 이웃에게 받은 정보
- 거리 벡터 알고리즘이 해당된다.
네트워크의 특성에 따라
정적 네트워크
- 라우터가 거의 바뀌지 않는다.
동적 네트워크
- 라우터 정보가 자주 바뀐다.
- 예를 들어 모바일 처럼 계속 돌아다닐 수도 있고
- 움직이지 않아도 링크의 비용이 바뀔 수 있다.
링크 상태 알고리즘
- 다익스트라를 사용한다.
- 모든 노드가 네트워크 토폴로지와 링크 비용을 알고 있어야 한다.
- 따라서 링크 비용을 브로드캐스트한다.
- 한 노드로부터 모든 노드까지의 최소 비용을 계산해 포워딩 테이블을 만든다.
- 반복적이다. k번의 반복 이후 k개의 목적지까지의 최소 경로가 정해진다.
그냥 다익스트라 실행시키면 된다.
예시
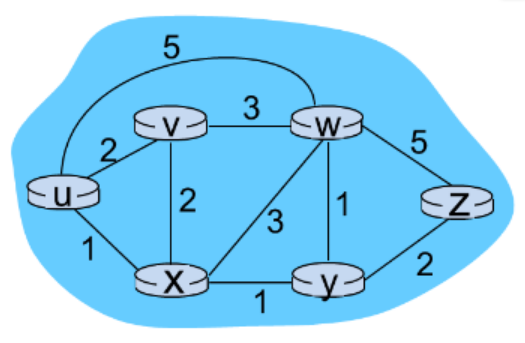
u에서 출발한다고 하면
1. 초기화
- 제일 먼저 u를 방문 처리하고
- u와 인접한 v, x, w 까지의 거리를 갱신한다.
- 인접하지 않은 나머지 노드는 거리를 무한대로 설정한다.
- v, x, w의 부모를 u로 설정한다.
- 반복문 내용
- 현재 출발지로부터 거리가 가장 가까운 노드를 찾고
- 방문 처리한 다음
- 그 노드와 인접한 노드의 거리를 갱신한다.
시간 복잡도
- 최악의 경우 n(n + 1)/2번 비교하니 시간 복잡도는 O(n^2)
- 만약 힙을 이용해서 구현하면 최소 거리 노드를 바로 찾을 수 있으니 O(nlogn)
진동
링크 상태 알고리즘에서는 진동이 발생할 수도 있다.
예시
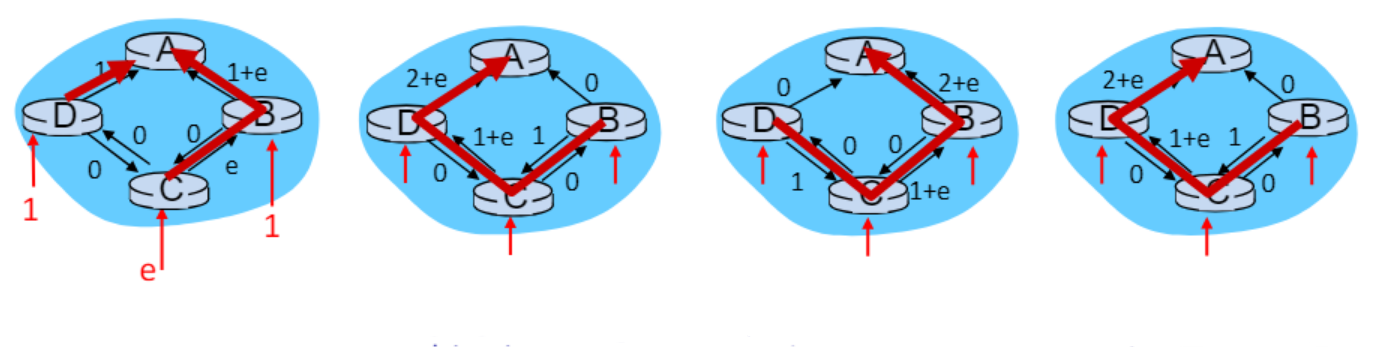
첫번째 그림
- 자신에게 오는 트래픽 양이 비용이다.
- d, c, b에는 각각 1, e, 1 만큼의 트래픽이 들어온다.
- 처음에 c는 d를 거쳐 a로 가는게 최소 비용이므로 d, a로 간다.
- 따라서 트래픽 양인 비용이 c -> d로 갈때는 e, d -> a로 갈 때는 e + 1로 변한다.
- b 입장에서도 c, d를 거쳐 a로 가는게 트래픽이 제일 적다.
-따라서 그렇게 가고 b에서 보내는 트래픽 1이 더해져 두번째 그림과 같아진다.
두번째 그림
- 첫번째 상황과 반대의 상황이 된다.
- 시계 반대방향으로 가는게 트래픽이 적어 모두 시계 반대 방향을 최소 비용 경로로 잡는다.
- 따라서 세번째 그림처럼 된다.
세번째 그림
- 첫번째 상황과 유사하게 시계 방향으로 가는게 최소 비용이다.
- 따라서 네번째 그림처럼 된다.
거리 벡터 알고리즘
- 벨만 포드를 사용한다.
- 는 x에서 y로 가는 최소 비용이다.
- c(x, y)는 이웃한 두 노드 x와 y 사이의 링크 비용이다.
- x에서 y로 갈 때 거리 를 갱신하려면 모든 노드에 대하여 c(x, v) + 의 최소값을 구하면 된다.
- 거리 벡터라는 것은 한 노드에서 다른 노드까지의 최소 거리 정보라고 할 수 있다.
- 최종적으로 모든 노드의 거리 벡터 테이블이 같아진다.
예를 들어
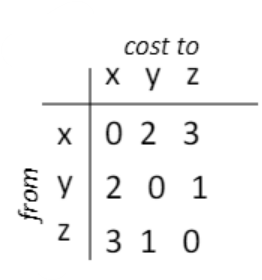
여기서 (0, 2, 3), (2, 0, 1) 이런 한 줄을 말하는 것이다.
-
반복적이고 비동기적이다.
- 이웃의 정보가 바뀌면 새롭게 알고리즘을 돌린다는 것
-
분산적이다.
- 내 정보가 변할 때만 이웃들에게 말한다.
- 이걸 받은 이웃은 알고리즘을 돌리고 변한게 없다면 가만히 있는다.
- 만약 변한게 있다면 또 이웃에게 보내준다.
예시
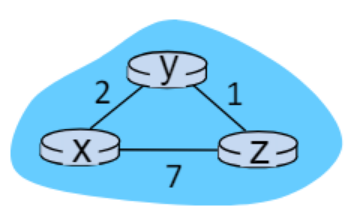
초기 상태
처음에는 자기 자신과 이웃한 노드 즉 자신 링크 정보만 알고 있다.
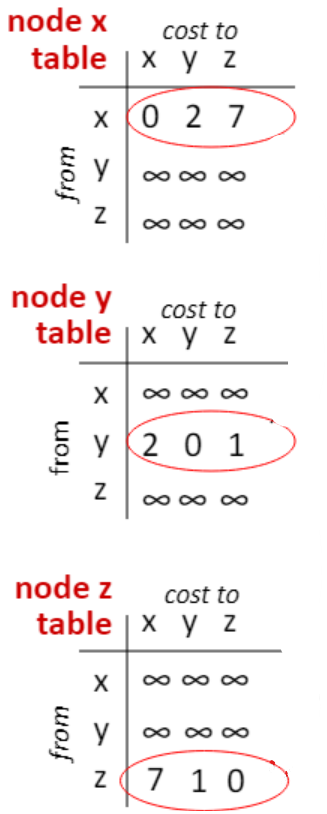
자신의 링크 정보를 다른 노드에게 전달하면 아래와 같이 된다.
링크 정보를 전달한 상태
예를 들어 x는 자신의 링크 정보(= 거리 벡터 = 한줄)을 y와 z에 전달하여 두 노드 테이블의 첫번째 줄이 채워진다.
이제 이 테이블 정보를 이용해서 알고리즘을 돌린다.
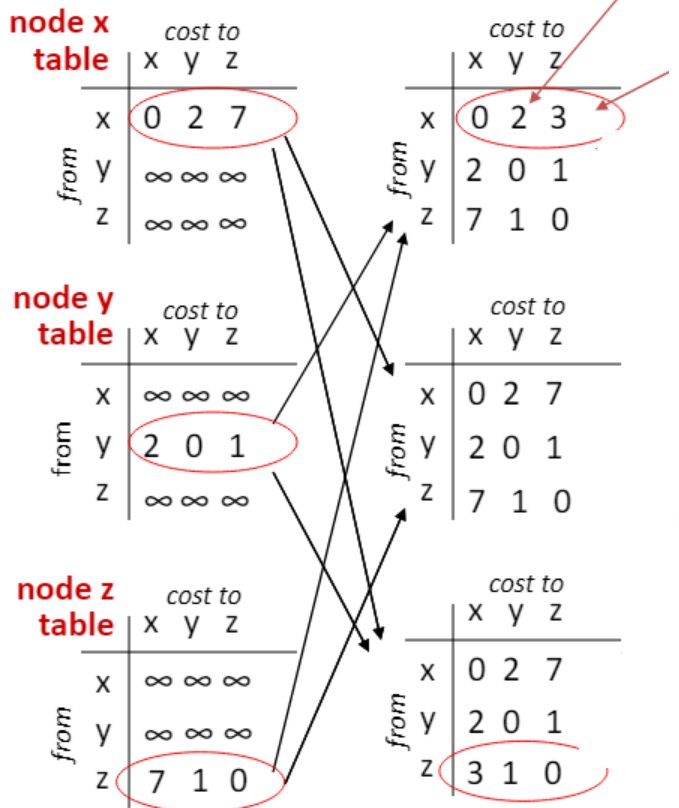
벨만 포드를 통한 거리 갱신
위 그림에서 x를 중심으로 보면 (0, 2, 7)에서 (0, 2, 3)으로 변한 걸 알 수 있다. 이는 다음과 같은 과정을 통해서 일어난 것이다.
- 는 자기 자신이니 당연히 0
- 는
- y를 거쳐가는 경로인 c(x, y) + 와
- z를 거쳐가는 경로인 c(x, z) + 를 비교한다.
- 각각 2와 8이므로 2가 더 작아서 바뀌는 것이 없다.
- 는
- y를 거쳐가는 경로인 c(x, y) + 와
- z를 거쳐가는 경로인 c(x, z) + 를 비교한다.
- 각각 3과 7이므로 3이 더 작아 갱신된다.
변경 내용 전파
- 자신의 내용이 바뀌었으므로 이를 다른 노드에게 전파한다.
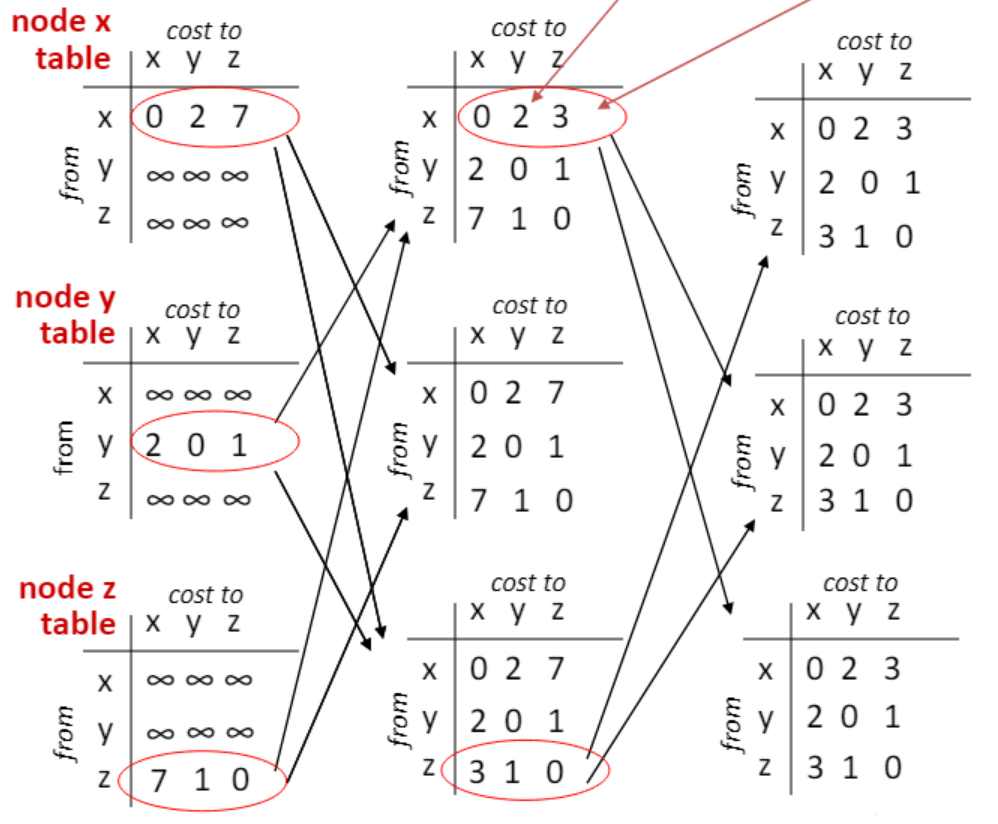
- y는 바뀐 것이 없어 전파하지 않는 것이다.
링크 비용이 변하는 경우
좋은 소식은 빠르게 전파
예를 들어 위 예시에서 c(x, y)가 1로 바뀌면
- y 노드는 이를 감지하고
- 벡터 정보를 바꾸고
- 이웃들에게 알려준다
- z는 이걸 받고 자신의 벡터에서 x까지의 최소 거리를 2로 바꾼다.
- z는 바뀐게 있으니 자신의 이웃들에게 이를 알린다.
- y가 z의 변경 사항을 받고 자신의 테이블에서 z의 벡터를 업데이트한다.
- 이후 바뀐게 없으니 끝난다.
링크의 비용이 감소해서 테이블을 업데이트하는데는 총 2번의 반복을 하면 됐다. 이렇게 거리 벡터 알고리즘에서는 링크 비용이 감소하는 경우 업데이트가 빠르게 일어난다.
나쁜 소식은 느리게 전파
예를 들어 위 예시에서 c(x, y)가 60으로 바뀌면
- 원래 = 4, = 1, = , = 5인데 링크 비용이 바뀐다고 이것들이 바로 바뀌는 것이 아니다.
- y가 링크 비용이 바뀐걸 보고 자신의 벡터를 갱신한다.
- = min{c(y, x) + , c(y, z) + } = min{60 + 0, 1 + 5} 이므로 6이 된다.
따라서 y는 이제 x로 가기 위해 z를 거쳐간다.
-
y가 갱신을 했으니 자신의 벡터를 z에게 알려준다.
-
z는 이걸 받고 알고리즘을 돌린다. 일때 주목할 점은 y에서 x로 가는 최소 경로는 z를 거쳐가는 것이고 길이가 6이다.
- z는 x로 바로 가는 길과 y를 거쳐 가는 길을 비교하고 y를 거쳐가는길이 더 짧아 를 7로 변경한다.
-
z의 벡터가 변경되었으므로 y에게 전파한다. 그럼 같은 과정을 반복하고 를 8로 변경한다.
-
한번의 반복에서 와 가 1씩 늘어나고 있다.
- 이는 결국 가 50이 되어 z에서 x로 직접 가는게 더 빠를 때까지 반복된다. 따라서 알고리즘이 완료되기 위해선 5에서 6이 되고 결국 50까지 되어야 하므로 총 44번의 반복이 일어난다.
이렇게 링크 비용이 커지면 알고리즘을 종료할 때까지 많은 시간이 걸린다. 이를 count to infinity 문제라고도 한다.
poison reverse
count to infinity 문제를 해결하기 위한 방법 중 하나이다.
포이즌 리버스에서 z가 y를 거쳐 x에게 간다면 z는 y에게 z에서 x로는 못 간다고 즉 = 무한대라고 알려준다.
이러면 루프가 발생하지 않아 시간이 크게 줄일 수 있다.
위 예시에 포이즌 리버스를 적용하면
- z는 y를 거쳐서 x에게 가므로 y에게 = 무한대 라고 알려준다.
- 따라서 y는 z에서 x로 가는 방법은 없다고 생각하고 바로 y에서 x로 가는 길의 길이를 갱신한다. 무한대와 비교하니 = 60으로 바로 갱신이된다.
- z는 y의 업데이트 내용을 받고 더이상 x로 가려면 y를 거치지 않아도 된다는 것을 알게 된다. 따라서 자신의 벡터를 업데이트하고 이제 y에게 = 50 이라는 것을 알려준다.
- y는 받은 내용을 바탕으로 = 51 이라고 업데이트 한다.
분석
메세지 복잡도
- 링크 상태 알고리즘
- 모든 노드가 모든 링크 정보를 알아야 하니 각 모드는 자신의 링크 정보를 보낸다. 따라서 O(NE) 개의 메세지가 보내진다.
- 거리 벡터 알고리즘
- 이웃끼리만 메세지를 주고 받으면 되니 적다.
수렴 속도
시간 복잡도를 말하는 것이다. 다만 링크 상태 알고리즘은 진동이 발생할 수 있고 거리 벡터 알고리즘은 count to infinity 문제를 겪을 수 있다.
안정성
- 링크 상태 알고리즘
- 자신의 링크 정보를 네트워크 전체에 전파해야 한다.
- 따라서 잘못된 링크 정보를 전파할 수도 있다.
- 하지만 각 노드는 자신의 라우팅 테이블만 계산한다.
- 따라서 오류가 있어도 어느 정도 버틸 수 있다.
- 거리 벡터 알고리즘
- 노드가 업데이트 후 자신의 벡터를 모든 노드에게 전파한다.
- 잘못 업데이트 되면 잘못도니 정보가 다 퍼지고 이를 이용하여 벡터를 업데이트하니 오류가 계속 전파된다.
