혼잡 제어
쓰루풋이 적당히 높은 인풋에 머무는 것이 목표
그러기 위해 계속 왔다갔다 한다.
상황별 정체 시나리오
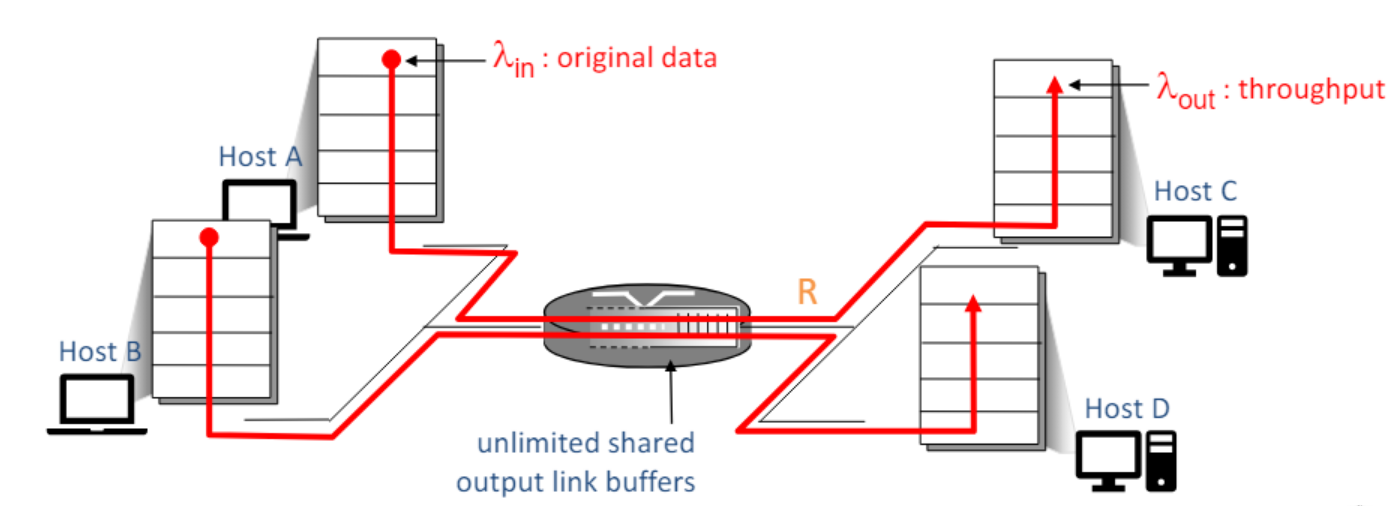
마지막 시나리오를 제외하곤 두 개의 호스트에서 보내고 하나의 라우터를 거친다.
버퍼 크기 무한, 재전송 x
람다in : 데이터 보내는 속도
람다out : 쓰루풋
가장 이상적인 상황이니 람다in이 증가하면 쓰루풋이 증가하고 어느 순간 R/2이 된다. 이보다 빠르게 보낼 수는 없고 R/2보다 빠르게 보내기 시작하면 큐잉이되고 점점 딜레이가 증가한다. R/2에 가까워질 수록 딜레이가 엄청나게 증가한다.
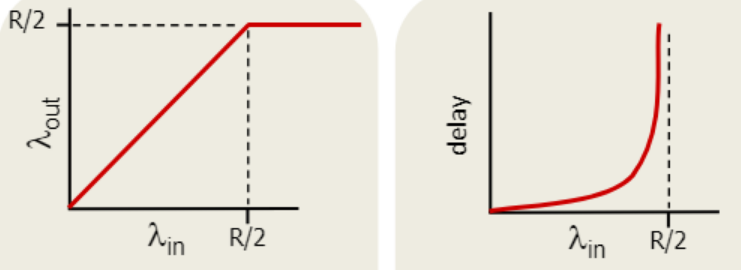
버퍼 크기에 제한
람다in : 전과 같이 보내는 속도
람다in' : 버퍼 크기에 제한이 생기면서 발생하는 재전송량을 포함시킨 것
tcp는 신뢰성이 있으니 람다in과 람다out은 같다. 따라서 람다in'은 람다out보다 크다.
전송자가 버퍼에 공간이 있을 때만 보냄
따라서 로스가 없어
로스가 없으니 보낸 만큼 도착해서 다음과 같이 생김
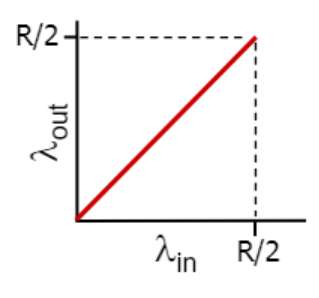
큐에서 큐 로스가 일어나고 로스가 날 때만 재전송
로스가 날 때만 재전송 즉 없는 것만 정확히 재전송하니 중복 패킷이 없다.
람다in'이 증가하면 람다out도 증가하다 어느 순간부터 꺾일 것이다.
왜냐면 보내는 양이 많아지니 큐로스가 나고 큐 로스가 나니 도착하는 양은 작아질 것이다.
이 순간부터는 람다인 - 람다아웃에 해당하는 것이 재전송에 쓰이는 대역폭이다. 많이 보낼 수록 재전송 양도 많아지니 이 영역의 넓이도 점점 커진다.
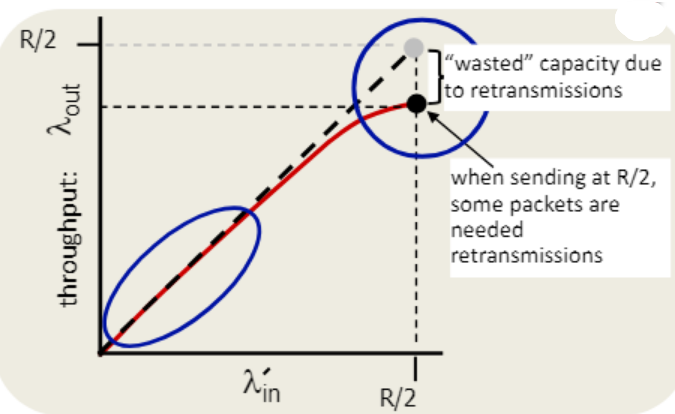
중복 패킷까지 고려
람다인 - 람다아웃에 로스 뿐만 아니라 재전송까지 들어가 이전 상황보다 더 커진다.
여러 라우터
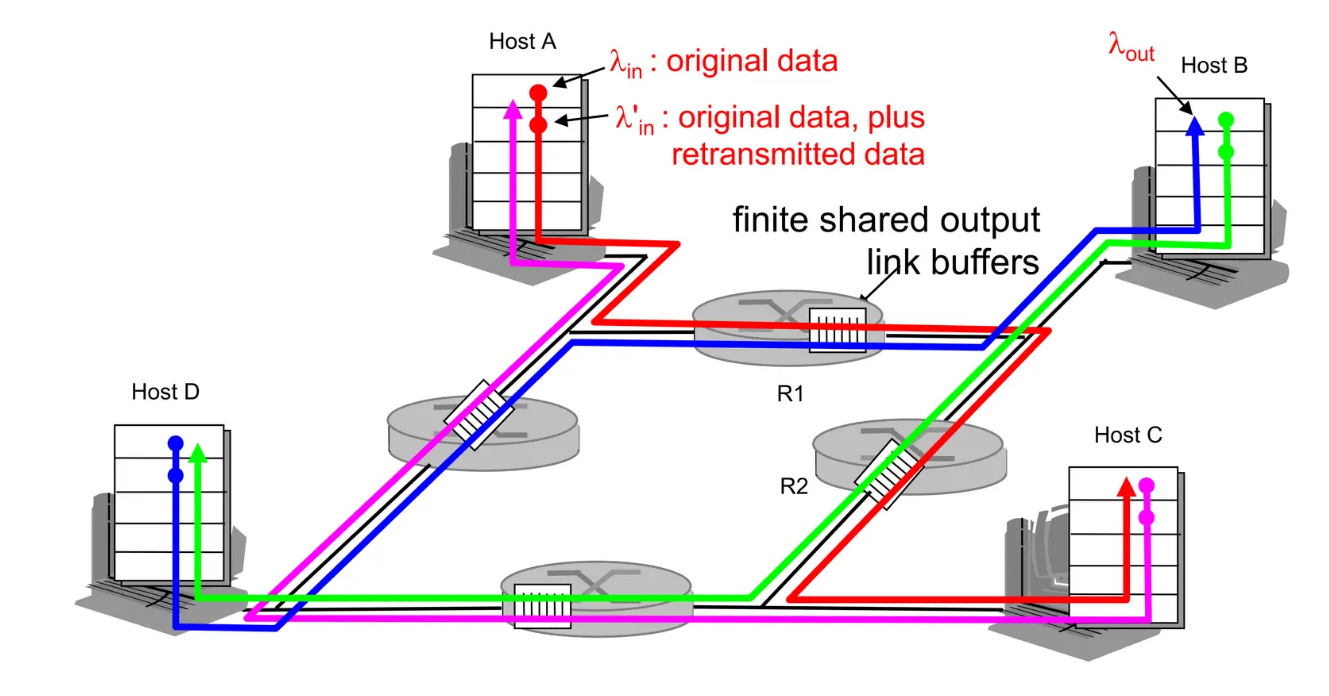
이전과 달리 여러 라우터가 있을 때 한 호스트에서 전송량을 늘릴 때
마지막 라우터에 로스가 나는 경우 거의 모든 대역폭을 이용하고도 실패해서 낭비가 심하다.
다른 쪽에서는 한 쪽에서 너무 많이 보내니 자원을 이용하지 못하고 계속 로스가 나면서 자신의 람다out이 뚝 떨어지게 된다.
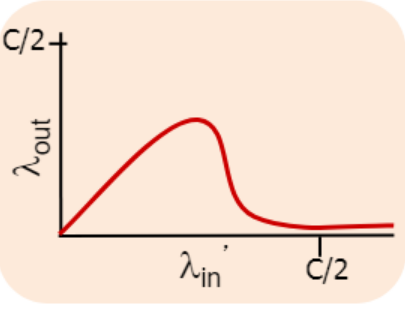
이렇게 람다in'이 늘면서 람다out이 떨어지는 것을 정체 충돌이라 한다. 모든 호스트가 서로 늘리려고 하면 대역폭을 다 쓰면서 전달이 안 되니 모든 호스트의 그래프가 위와 같아진다.
중요 키워드 및 개념
슬로우 스타트
전송 비율이 지수적으로 증가하는 tcp의 상태
비율이 지수적으로 증가하니 처음에는 느리게 증가하지만 나중에는 빠르게 증가한다.
congestion avoidence
aimd라는 방법을 사용해서 보내는 비율을 조절하는 상태
aimd
증가는 additive하게 감소는 multiplicative 하게
congestion avoidence에서 전송량을 적절히 조절하는 방법
cwnd
- tcp 전송자의 윈도우 크기
- tcp는 파이프라인 프로토콜이라 윈도우가 있다.
ssthresh(slow-start threshold)
마지막 정체가 발견되었을 때의 cwnd의 절반
- 이 전송량 전까지는 문제가 없다는 것을 의미한다.
mss
- 최대 세그먼트 크기
전송자에서 일어날 수 있는 일
- 애크 받음 : tcp 입장에서 아주 좋은 일
- 타암 아웃 : 매우 나쁜 일
- 3개의 중복 애크 : 약간 나쁜 일
전송자의 윈도우
-
전송자는 윈도우 크기를 동적으로 조절하여 혼잡을 제어한다.
-
혼잡을 제어하기 위해선 다음을 만족해야 한다.
마지막으로 보낸 바이트 - 마지막으로 응답받은 바이트 <= min(cwnd, rwnd) -
전송량은 rtt동안 보낸 양 즉 cwnd / rtt
tcp에서는 rtt를 조절할 수는 없으니 윈도우 크기인 cwnd를 조절한다.
슬로우 스타트
- tcp는 첫번째 로스가 일어나기 전까지 지수적으로 증가한다.
- 슬로우 스타트에선 매 rtt마다 cwnd가 두배씩 늘어난다.
- 타임아웃이 발생하지 않아도 초기에 설정한 ssthresh를 넘어가면 끝난다.
실제로는 각각의 애크가 올 때마다 cwnd를 증가시킨다.
예시

-
하나의 세그먼트를 보내고 하나의 애크를 받으면 cwnd를 증가시킴
그럼 첫 rtt에 cwnd가 1에서 2가 된다. 그리고 응답을 받았으니 윈도우 오른쪽으로 움직인다. -
두번째 rtt에서 cwnd가 2가 되었고 윈도우 크기가 2이니 2개 보낸다. 첫번째 애크가 오면 3이 되고 두번째 애크가 오면 4가 된다. 그래서 두번째 rtt 후 cwnd가 2에서 4가 된다.
-
세번째 rtt에서 윈도우 크기가 4인데 아직 두개밖에 안 보냈으니 두개 또 보낸다. 두개 보내고 애크 2개 받으면 6되고 2개 늘어나서 또 두개 보내고 결국 애크를 다 받으면 cwnd가 8이 된다.
이렇게 숲을 보면 매 rtt마다 cwnd가 두 배가 되는 것처럼 보인다.
정체 탐지
- tcp는 로스를 정체라고 생각한다.
- tcp에서는 로스를 다음과 같이 두 방법으로 추론한다.
타임 아웃
- 타임아웃이 발생하는 것은 매우 나쁘다고 생각한다.
- 따라서 처음 상태인 슬로우 스타트로 돌아간다.
- 타임 아웃이 발생하면 cwnd를 초기값으로 설정하고 다시 지수적으로 증가한다.
- 단 ssthresh를 설정하여 이를 넘어가면 이때부터는 지수적으로 증가하지 않고 선형적으로 증가하면 정체를 생각하며 천천히 증가한다.
ssthresh는 타임아웃이 발생한 cwnd의 절반으로 설정한다. 이 전까지는 슬로우 스타트를 하며 지수적으로 증가하고 이 후에는 천천히 선형적으로 증가한다.
절반을 하는 이유는 슬로우 스타트에서는 rtt마다 2배가 늘고 이전 cwnd는 문제가 생기지 않은 cwnd이므로 문제가 없던 곳으로 돌아가기 위해서 그런 것이다.
3 중복 애크
- cwnd를 절반으로 줄여 바로 이전에 괜찮았던 상태로 간다.
- 중복 애크는 크게 나쁜 상황이 아니기 때문에 처음으로 돌아가는 게 아니다.
- 즉 슬로우 스타트로 가는 것이 아니라 congestion avoidence 상태로 간다.
- 이후 aimd 매커니즘을 통해 선형적으로 늘어난다.
AIMD
매 rtt 마다 1mss를 증가시키고 로스가 나면 cwnd를 절반으로 줄인다.
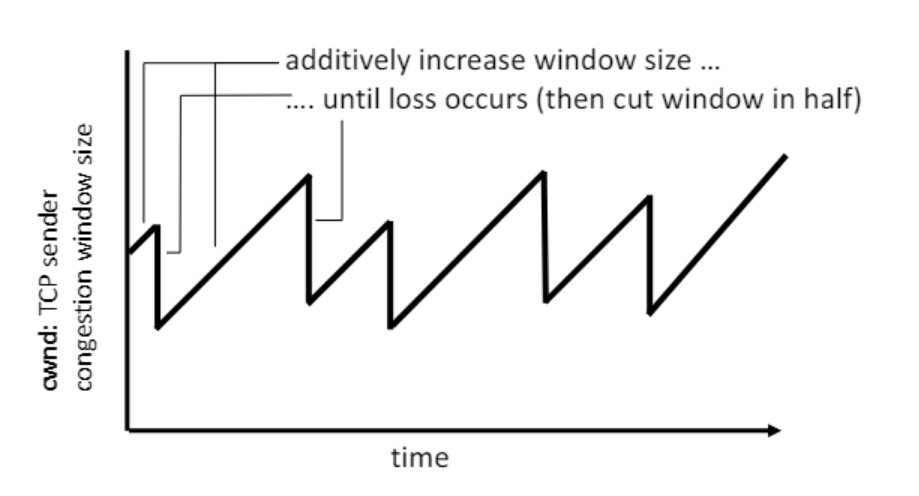
- 매 애크마다 mss * mss/cwnd 만큼 증가한다.
- 이를 이용하면 전송률이 선형적으로 천천히 증가할 것이다.
TCP 유한 상태 머신
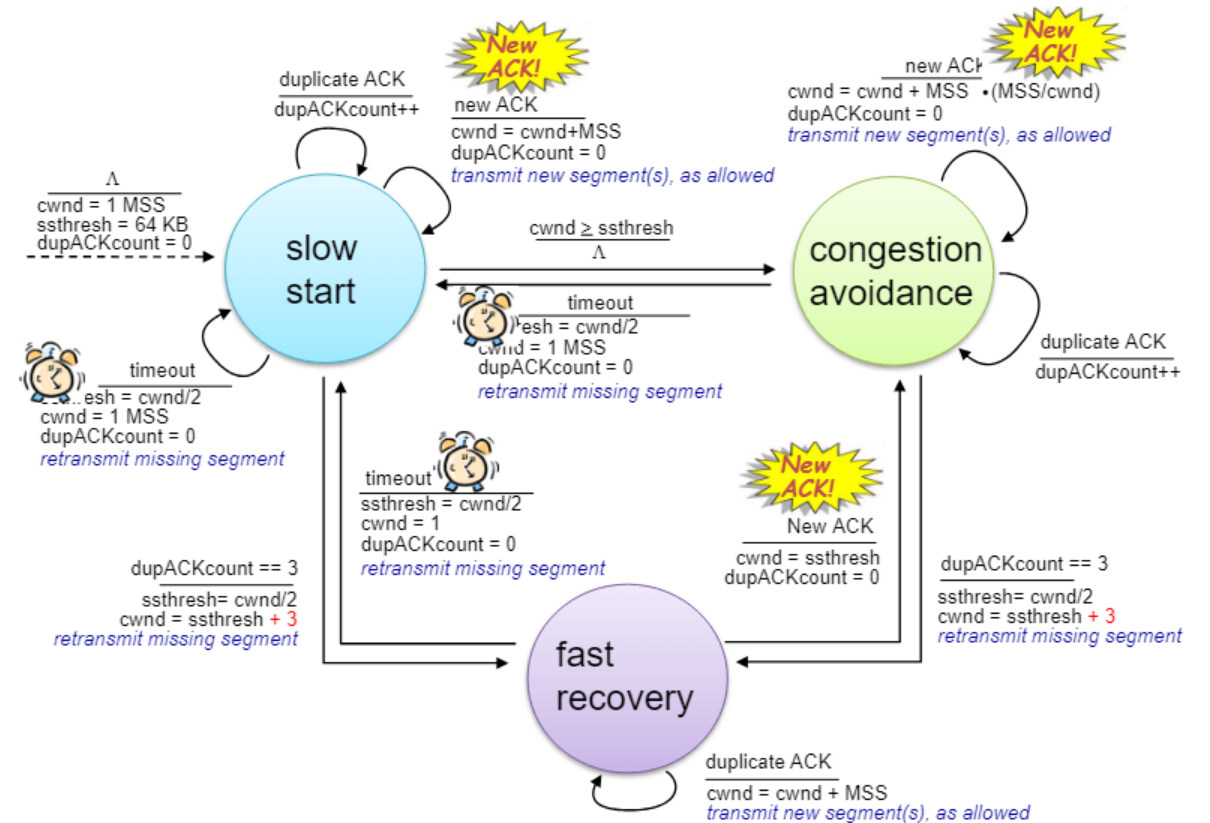
슬로우 스타트
초기화
- cwnd를 1mss로 설정하는 등 초기화 작업을 한다.
새로운 애크가 오면
- cwnd를 1 올리고 dupAck를 0으로 한고 슬로우 스타트를 계속 진행한다.
- 가능하다면 새로운 세그먼트를 보낸다.
중복 애크가 오면
- 중복 애크 카운트를 일 올린다.
- 새로운 애크를 받은 건 아니니 cwnd를 늘리지는 않는다.
타임 아웃이 발생하면
- ssthresh를 현재의 절반으로 설정하고
- cwnd를 1로 하고 중복 애크 카운트를 0으로 하고 재전송한다.
- 즉 처음부터 다시 슬로우 스타트를 한다.
cwnd가 ssthresh를 넘으면
- congestion avoidence 상태로 간다.
중복된 애크를 3개를 받으면
- ssthresh를 현재의 절반으로 하고
- cwnd를 절반으로 줄이고 3 늘린다.
- 3 늘리는 이유는 사용한 윈도우중 3개는 중복 애크를 받는데 사용하였다. 따라서 + 3을 안 하면 멈춰있을 것이다.
- 이후 로스가 난 세그먼트를 재전송하고
- fast recovery 상태로 간다.
congestion avoidence
새로운 애크가 오면
- cwnd를 mss * mss/cwnd 만큼 증가시키고
- 중복 애크 카운트를 0으로 하고
- 가능하다면 새로운 세그먼트를 보낸다.
중복 애크가 오면
- 중복 애크 카운트를 하나 올린다.
중복 애크가 3개 오면
- ssthresh를 현재의 절반으로 한 다음
- cwnd를 절반으로 줄이고 3 늘린다.
- 로스난 세그먼트를 재전송한다.
타임 아웃이 발생하면
- ssthresh를 현재의 절반으로 한 다음
- cwnd를 1로 하고
- 중복 애크 카운트를 0으로 하고
- 로스난 세그먼트를 재전송한다.
fast recovery
중복 애크가 오면
- cwnd를 1 올린다.
tcp는 애크가 안 오면 타임아웃이 발생할 때까지 아무것도 안 한다. 즉 멈춰있지 않으려면 애크를 보내는 것이 중요하고 애크를 받으려면 뭘 보내야 한다. 그래서 1mss만큼 올려 애크를 받아서 멈춰있는 상태를 피하는 것이다.
새로운 애크를 받으면
- cwnd를 ssthresh로 하여 로스가 난 때의 바로 절반으로 간다.
- 중복 애크 카운트를 0으로 한다.
타임 아웃이 발생하면
- ssthresh 를 현재 cwnd의 절반으로 하고
- cwnd를 1
- 중복 애크 카운트를 0으로 하여 맨 처음 상태로 돌아간다.
- 로스가 난 패킷을 재전송한다.
tcp의 쓰루풋
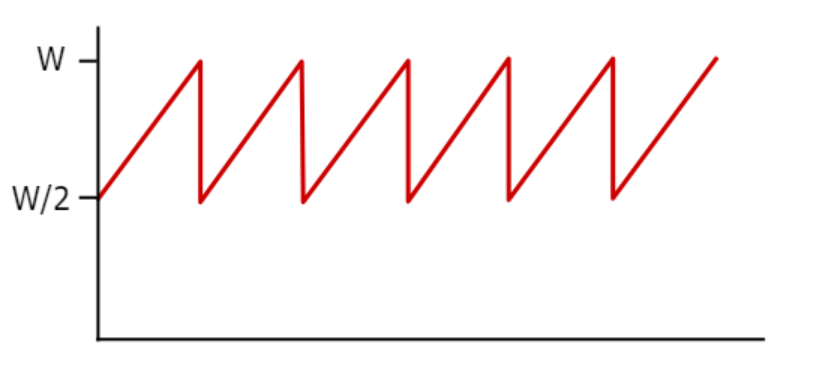
-
w를 로스가 발생했을 때 윈도우의 크기라 하면 tcp 전송자의 전송량은 w와 w/2를 왔다 갔다 한다.
-
따라서 rtt당 평균 3/4w 만큼 보내므로 평균적인 쓰루풋은
3w/4rtt bytes/sec가 된다.
TCP 큐빅
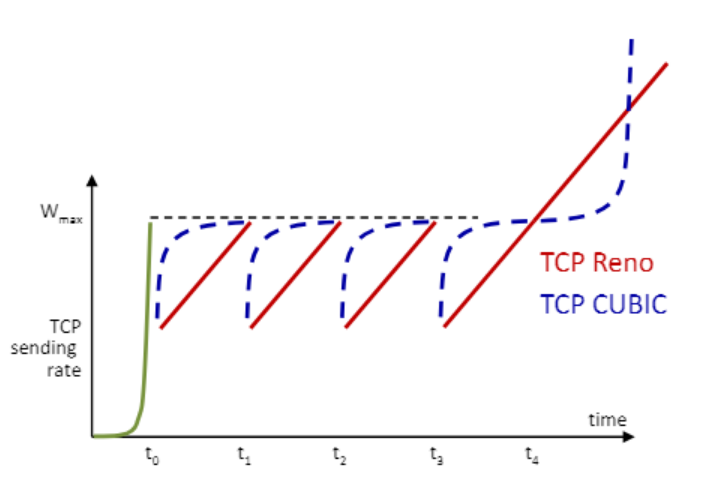
- 로스가 일어난 지점까지 선형적이 아니고 빠르게 올라간다.
- 만약 로스가 일어난 지점까지 갔는데 정체가 없어져 더 빠르게 보낼 수 있으면 아래로 볼록하게 즉 지수적으로 가는 것과 비슷하게 빠르게 전송률을 올릴 수 있다.
딜레이 기반 tcp 혼잡 제어
- 네트워크가 널널할 때 rtt를 측정한다
- 이건 당연히 가장 빠른 rtt 중 하나일 것이다. 이를 이용해 최대 쓰루풋을 계산한다.
- 이후 rtt를 측정하고 쓰루풋을 계산해 최대치와 비교한다.
- 최대치보다 현재치가 매우 작으면 정체가 있다고 생각하여 cwnd를 줄인다.
- 비슷하면 아직 널널하다 생각하여 cwnd를 올릴 수 있다.
tcp fairness
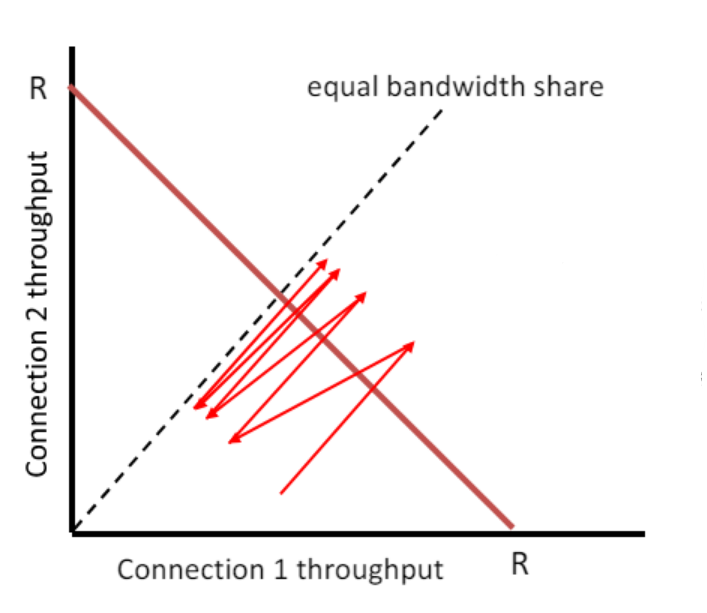
-
tcp가 만약 공평하다면 두 커넥션이 있을 때 쓰루풋이 동일하여 가운데에 있어야 한다.
-
만약 1이 먼저 연결되고 2가 나중에 연결되어 2가 느린 상태일 때면 1쪽에 치우친 상태이다.
-
이후 선형적을 증가하다 최대치를 넘어가면 로스가 난다. 따라서 양쪽의 전송률을 모두 절반으로 줄인다. 그럼 그림과 같이 왼쪽 아래로 이동한다.
-
이를 반복하면 결국 한 가운데로 오게 되고 따라서 aimd는 공정하다.
병렬 tcp 연결
- tcp 세션이 같은 병목 링크를 공유하면 커넥션 마다 공평하게 분배가 될 것이다.
- 이때 한 응용이 여러 tcp 커넥션을 병렬적으로 만들면 더 많은 커넥션을 연결하였으므로 더 많은 전송률을 갖을 것이다.
- 따라서 병렬로 커넥션을 연결할 때는 이를 고려해야 한다.
ECN
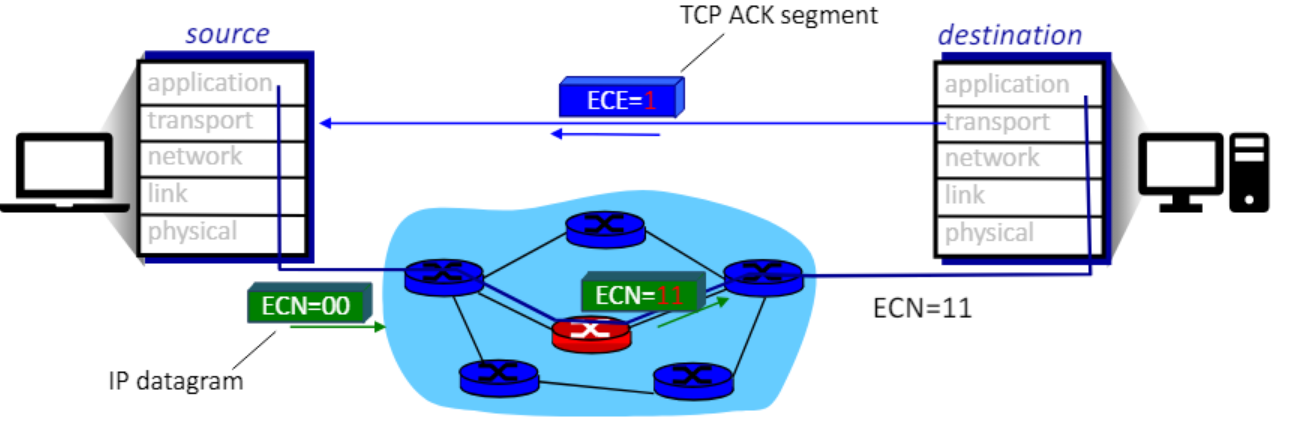
- tcp는 타임아웃이나 중복 애크를 통해 로스를 예측할 뿐이다.
- 또 타임 아웃이 있을 때까지 기다려야 하니 느릴수도 있다.
- 그래서 네트워크 즉 큐가 꽉 찬 라우터가 정체가 있다고 알려주는 것이다.
- ip 헤더에는 ecn이라는 비트가 있다.
- 라우터가 자신으 큐가 꽉 차면 ecn을 11로 설정하여 보낸다.
- 수신자는 이를 보고 네트워크에 정체가 있다는 걸 알고 ece를 1로 해서 보낸다.
- 따라서 헤더를 보고 전송자는 정체를 알 수 있다.
하지만 라우터가 이 기능을 제공하지 않을 수도 있고 종단 간 법칙에 어긋난다. 또 혼잡 제어를 ip가 하지만 원래는 전송 계층에서 하는게 맞다. 그래서 계층 구조에 조금 어긋난다.
