세그멘테이션
이전 포스트에선 base와 bound를 통한 주소 변환법을 알아보았습니다.
하지만, 이 방법은 스택과 힙 사이의 공간을 낭비한다는 단점이 있어 우리는 새로운 방식을 알아보겠습니다.
세그멘테이션 : base/bound의 일반화
세그멘테이션은 MMU에 하나의 base와 bind가 존재하는 것이 아닌, 세그멘트마다 base와 bind를 사용하는 방법입니다.
세그멘트는 특정길이를 가지는 연속적인 주소 공간으로 코드, 스택, 힙의 세 종류의 세그멘트가 존자합니다.
세그멘테이션을 사용하면, OS는 각 세그멘트를 물리 메모리의 각기 다른 위치에 배치가 가능해지고 사용하지않는 주소 공간이 메모리를 차지하는 것을 막을 수 있습니다.
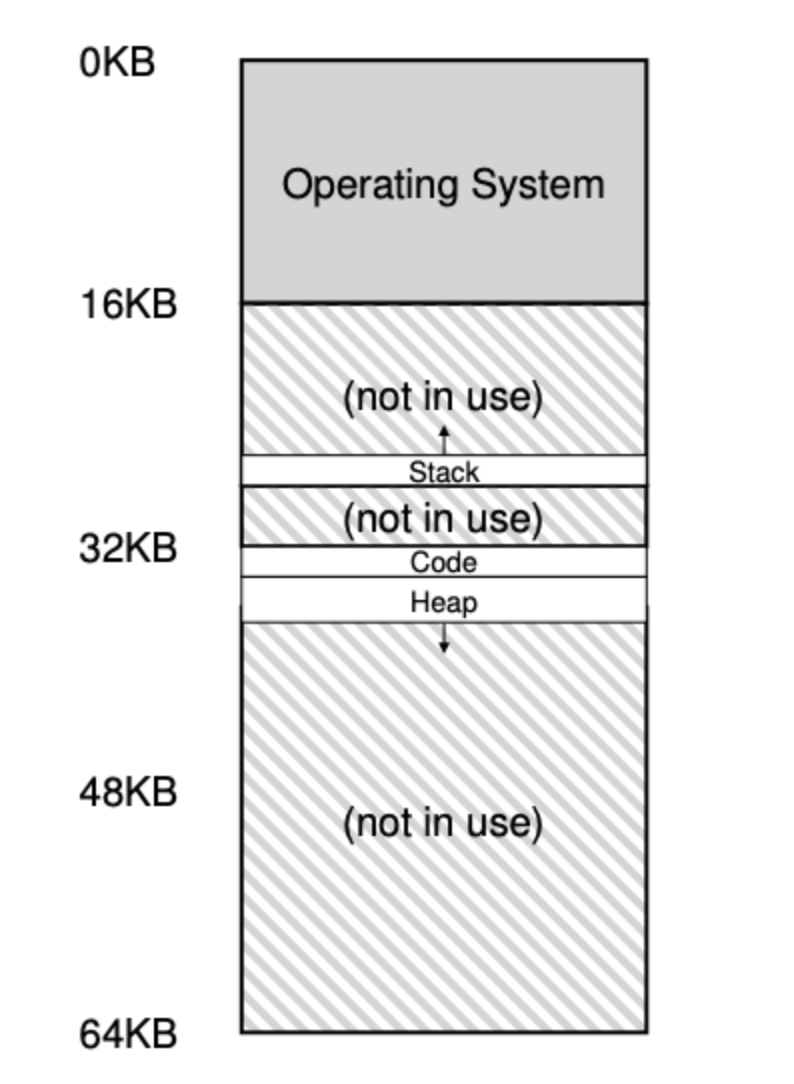
위 그림을 보면, 세그멘트를 사용하여 물리 메모리에 배치한 그림입니다.
그림에서 0부터 16KB까지는 OS를 위한 예약된 공간인 것을 볼 수 있고, 나머지 공간에서 코드, 스택, 힙을 위한 메모리 공간이 할당되어 있는 것을 볼 수 있습니다.
이를 통해, 스택과 힙 사이의 공간이 낭비되지 않는 것을 알 수 있습니다.
위와 같이 세 개의 세그멘트를 할당하기 위해서는 아래 표처럼 각각의 세그멘트 마다 base와 bound가 필요하다는 것을 알 수 있습니다.
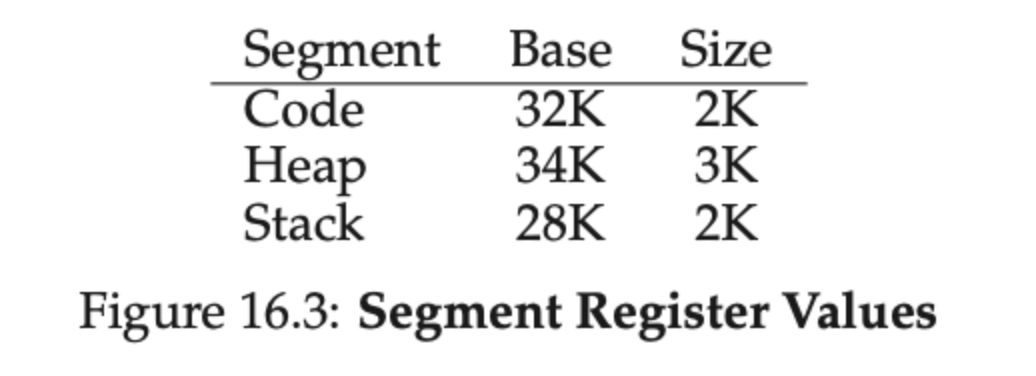
16.2 그림을 보고 16.3의 표를 보면, 각각의 세그멘트 마다 base와 bound가 일치한다는 것을 알 수 있습니다.
이제 이 세그멘트를 이용하여 주소 변환을 해보겠습니다.
만약 가상 주소 100번지를 참조한다고 가정해보겠습니다.
참조가 일어나면 하드웨어는 base 값에 이 세그멘트의 오프셋 ( 지금은 100 ) 을 더해 물리 주소가 100 + 32KB, 즉 32868이 됨을 알 수 있습니다.
그 후, 주소가 범위에 있는지 검사를하고 범위 내에 있을 경우 물리 메모리 주소 32868을 읽게 됩니다.
이번에는 가상주소 4200의 힙을 참고해보겠습니다.
여기서 주의할 점은 세그멘트의 오프셋이 4200이 아닌, 4KB로부터 시작하기 때문에 4200-4096 즉, 104가 됨을 알 수 있습니다.
이 오프셋에 힙의 base인 34KB를 더해 34920이 됨을 알 수 있습니다.
이 때 만약, 각 세그멘트의 범위를 넘어서는 주소를 참조하려고하면 어떻게 될까요?
→ 세그멘트 폴트가 일어나게 됩니다.
세그멘트의 종류
하드웨어는 변환을 위해 세그멘트 레지스터를 사용합니다.
하드웨어는 가상 주소가 어떤 세그멘트를 참조하고, 그 안에서 오프셋은 얼마나 되는지 어떻게 알 수 있을까요?
일반적인 접근 방식으로는, 가상 주소의 최상위 비트 몇 개를 세그멘트 종류를 나타내는데 사용하는 것입니다.
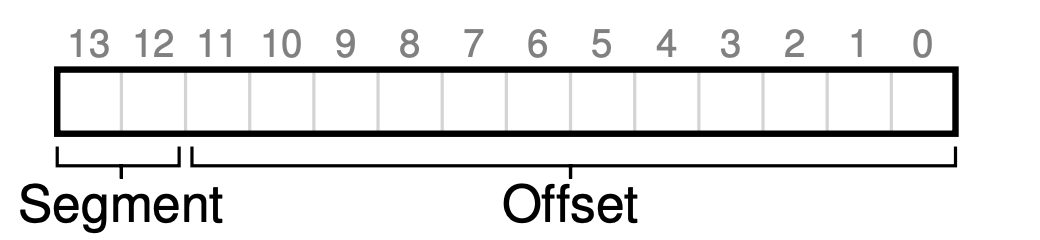
위와 같이 가장 주소 공간 중 최상위 2비트를 세그멘트의 종류, 나머지를 offset으로 하여 세그멘트를 참조하고 오프셋을 계산하게 됩니다.
최상위 2비트가 00이면 코드이며, 01이면 힙을 나타냅니다.
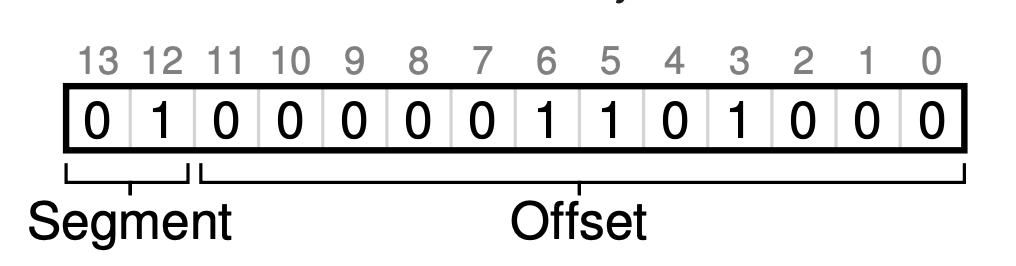
예시를 보겠습니다.
이번에는, 4200의 가상주소를 접근해보겠습니다.
4200을 비트로 나타내면, 위의 그림과 같고 최상위 비트가 01이기때문에 힙임을 알 수 있습니다.
그 후, 나머지 비트를 통해 오프셋의 값이 1101000(2) 즉, 104임을 알 수 있습니다.
이렇게 어떤 세그멘트인지 파악을 했고, 오프셋을 계산을 했으니 세그멘트의 base 값에 오프셋을 더하여 하드웨어는 최종 물리 주소를 계산합니다.
이 방법을 사용하면, bound 검사도 쉬워집니다. 그냥 오프셋의 크기가 bound보다 작은지만 판단하면 됩니다.
아래의 코드는 세그멘트와 오프셋을 찾는 코드입니다.

현재는, 세그멘트의 구분을 위해 2개의 비트를 사용하여 세그멘트의 크기가 최대 4KB이지만 일부 시스템은 최대한 세그멘트를 활요하기 위해 1개의 비트만 사용한다고합니다.
1개를 사용하면 13개의 비트가 남게 되니 8KB를 사용할 수 있게됩니다.
스택
지금까지는 코드와 힙 영역만을 접근하는 법을 알아보았습니다.
스택은 다른 영역과는 달리 반대 방향으로 확장한다는 특징이 존재합니다.

그래서 스택을 사용하게 되면 또 다른 하드웨어의 지원이 필요하게 됩니다.
그것이 Grows Positive이고, 어느 방향으로 확장하는지 파악하게 도움을 주는 레지스터입니다.
이제 예시를 통해, 스택에 해당하는 가상주소를 변환해보겠습니다.
15KB의 가상 주소를 접근해보겠습니다.
이것을 비트로 나타내면 11 1100 0000 0000 (2) 입니다.
하드웨어는 상위 2비트를 통해 스택임을 알 수 있고, 낮은 주소 방향으로 확장한다는 것을 레지스터를 통해 파악합니다.
그리고 나머지 비트를 통해 오프셋이 3KB인것을 알 수 있습니다.
하지만, 음수 오프셋을 구해야하기 때문에 3KB에서 최대 오프셋의 크기를 빼야합니다.
따라서 오프셋은 -1KB가 됩니다.
따라서 우리는 base와 오프셋을 통해 실제 물리 주소가 27KB가 됨을 알 수 있게 됩니다.
공유 지원
세그멘테이션이 발전함에 따라 시스템 설계자들은 공유를 통해 메모리를 절약할 수 있음을 깨달았습니다.
일반적으로 코드를 공유하는 방식을 사용하며, 현재 시스템에서 광범위하게 사용됩니다.
공유를 지원하기 위해서는 하드웨어에 protection bit가 추가로 필요로합니다.
protection bit는 세그멘트를 읽거나 쓸 수 있는지 혹은 세그멘트의 코드를 실행시킬 수 있는지 판단하는 요소입니다.

코드 세그멘트를 읽기 전용으로 설정하게 된다면, 주소 공간이 독립적으로 유지되면서도 여러 프로세스가 주소 공간의 일부를 공유할 수 있습니다.
이를 통해 프로세스는 세그멘트를 공유하지만, 공유하지 않고 자신만의 독립적인 메모리를 사용한다는 환상을 갖게 됩니다.
위와 같은 추가적인 비트를 사용하려면 앞서 언급한 하드웨어 알고리즘도 수정되어야합니다.
가상 주소가 범위 내에 있는지 확인하는 것 외에 특정 액세스가 허용되는지를 확인해야합니다.
만약, 허용된 작업 외에 다른 작업을 시도하면 예외를 발생시키켜서 운영체제가 위반 프로세스를 처리할 수 있게 해야합니다.
소단위 대 대단위 세그멘테이션
우리의 예제는 소수의 코드, 스택, 힙만을 지원하는 시스템에만 초점을 맞추어 왔습니다.
우리는 이 세그멘테이션을 대단위라고 할 수 있습니다.
주소 공간을 비교적 큰 단위의 공간으로 분할했기 때문입니다.
일부 초기 시스템에서는 주소 공간을 작은 크기로 잘게 잘라 소단위의 세그멘테이션을 구현햇습니다.
그런데, 이런 소단위 세그멘테이션은 여러 세그멘트의 정보를 저장할 세그멘트 테이블과 같은 하드웨어가 필요합니다.
이는 조금 더 융퉁성 있게 많은 세그멘트를 손쉽게 생성하고 사용할 수 있게 해주었습니다.
어떤 단위의 세그멘테이션이 좋은지는 상황에 따라 다를 것입니다.
작은 단위는 잘게 잘라 많은 세그멘트가 존재하므로, 관리가 힘들 것이며
큰 단위의 세그멘트는 관리는 편하지만, 단순한 구성으로밖에 이루어질 수 없습니다.
운영체제의 지원
세그멘테이션이 이전에 공부했던 base와 bound만을 사용하는 것에 비해 메모리를 절약할 수 있다는 것은 이제 알 것입니다.
하지만 이러한 도입을 위해서는 몇가지 문제를 해결해야합니다.
-
context switching입니다.
context switching이 일어날 때, OS는 세그멘트의 레지스터를 저장하고 복원해야합니다.
각 프로세스는 자신만의 가상 주소 공간을 갖기 때문에, context switching 시 OS가 적절하게 레지스터를 저장하고 복원해야합니다.
-
세그멘트 크기의 변경입니다.
어떤 프로그램이 malloc과 같은 명령어를 통해 객체를 할당했다고 가정합시다.
만약, 빈 공간이 없다면 새로운 메모리를 할당해야하므로 세그멘트의 크기를 증가시켜야합니다.
OS는 이를 위해 시스템 콜을 통해 새로운 공간을 할당하거나, 메모리가 고갈되었거나 이미 너무 많은 메모리를 사용 중이라면 메모리 할당을 거부해야합니다.
-
미사용중인 물리 메모리의 관리입니다.
OS는 새로운 주소 공간이 생성되면 세그멘트를 위한 비어있는 물리 메모리를 찾아야합니다.
실제 프로세스마다 주소 공간의 크기가 모두 다르기 때문에 세그멘트의 크기도 다 다를 것입니다.
이때 만약 물리 메모리가 작은 빈 공간들로 채워지게 된다면, 새로운 세그멘트를 할당하기도 힘들고 확장도 어려워지게 됩니다.
이러한 문제를 외부 단편화라고 부릅니다.
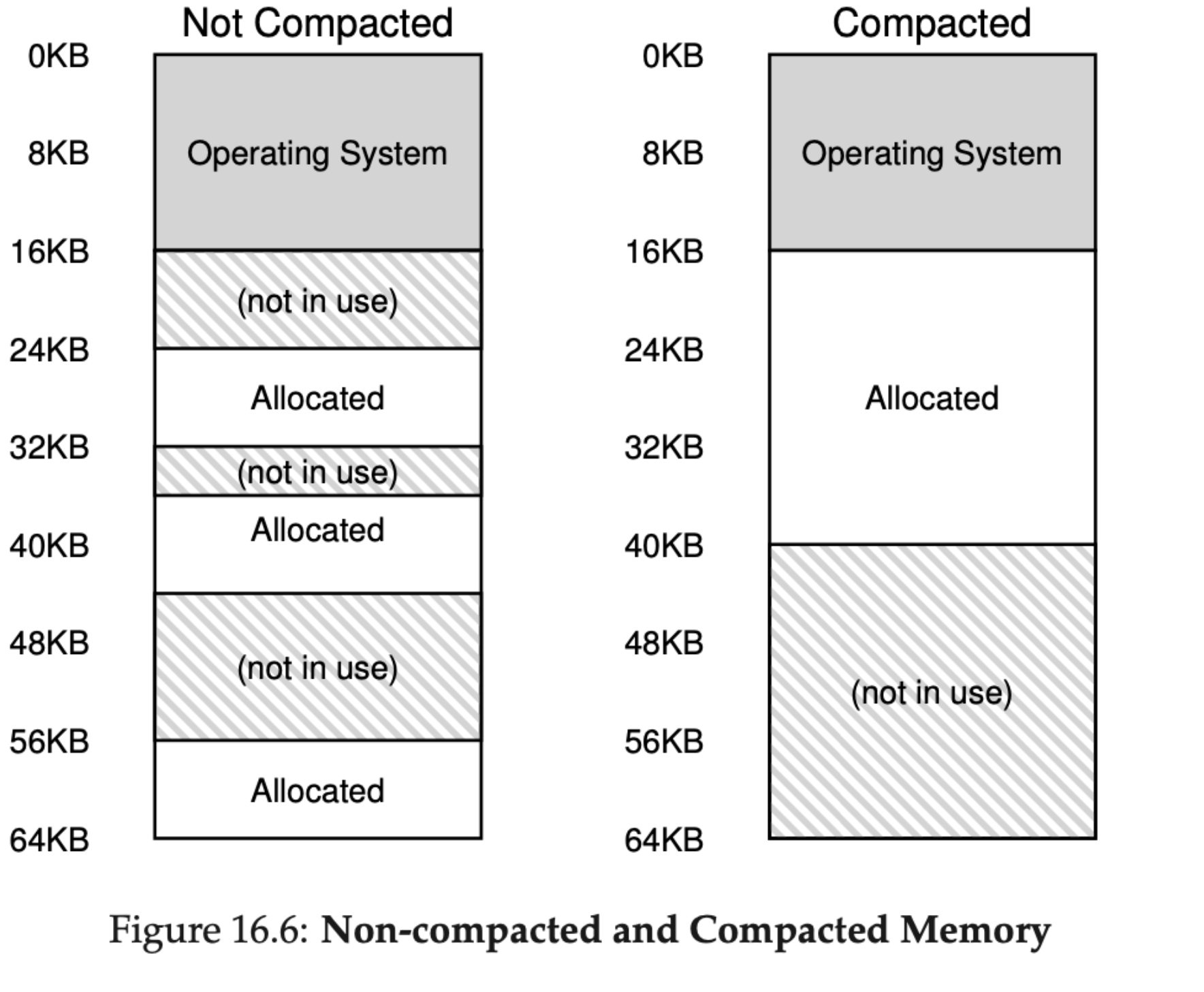
만약 새로운 프로세스가 생성되어 20KB의 세그멘트를 할당하는 예제를 보겠습니다.
왼쪽의 물리 메모리는 24KB의 빈 공간이 존재하지만, 부분 부분 나누어져 있기때문에 20KB의 공간을 할당 할 수 없습니다.
이를 해결하기 위해 OS가 해결하는 방법 중 하나는 물리 메모리를 압축하는 것입니다.
오른쪽 그림과 같이 압축을 진행하면, 현재 실행 중인 프로세스를 중단하고 그들의 데이터를 하나의 연속된 공간에 복사하고, 세그멘트 레지스터가 새로운 물리 메모리 주소를 가리키게 하여 OS가 작업할 새로운 큰공간을 가질 수 있게 됩니다.
하지만, 압축은 또 다른 비용을 발생시키게 된다는 단점이 있습니다.
이 외에도 빈 공간 리스트를 관리하는 알고리즘을 사용하는 것입니다.
하지만, 아무리 알고리즘을 잘 만든다해도 외부단편화는 여전히 존재할 수 밖에 없습니다.
좋은 알고리즘은, 이 외부 단편화를 최소화하는 것이 목표입니다.
요약
세그멘테이션은 많은 문제를 해결하고, 메모리 가상화를 효과적으로 실현시킵니다.
단순한 동적 재배치를 넘어 물리 메모리의 낭비를 제거하고 쉬운 산술연산을 통해 구현도 적합하며 속도도 빠릅니다.
또한 코드 공유를 통해 더 낭비를 줄일 수 있게 됩니다.
하지만, 세그멘트 크기가 다르다는 이유로 인해 외부 단편화가 발생한다는 단점이 있습니다.
또, 세그멘트가 드문 드문 사용되는 주소 공간을 지원할 만큼 충분히 유연하지 못하다는 단점도 있습니다.
이러한 단점을 해결하기위해 우리는 또 다른 방법을 배울 것입니다.
