스케쥴링 : 비례 배분
이번 포스트에서는 비례 배분 스케줄러(Propotional Share) 혹은 공정 배분 스케줄러(Fair Share)라고 불리는 스케줄러에 대해 배우겠습니다.
이 스케줄러는 반환 시간이나 응답 시간을 최적화하는 대신 스케줄러가 각 작업에게 CPU의 일정한 비율을 보장하는 것이 목적입니다.
비례 배분 스케줄러의 가장 좋은 예시는 추첨 스케줄러(Lottery Share)입니다.
기본 개념 : 추첨권이 당신의 지분이다.
추첨권이라는 기본적인 개념은 추첨 스케줄러의 근간을 이룹니다.
추첨권은 경품권의 개념과 유사하며, 특정 자원에 대한 프로세스에게 할당될 지분을 나타냅니다.
프로세스가 소유한 티켓 개수와 전체 티켓간의 비율이 그 프로세스의 지분입니다.
예를 들어, A와 B 두 프로세스가 있을 때 A는 75장 B는 25장의 추첨권을 가지고 있다.
A에게 75%의 CPU를 B에게 25%의 CPU를 할당하는 것이 이 스케줄러의 목적입니다.
이 목적을 달성하기 위해 스케줄러는 간단한 방식을 채용합니다.
- 스케줄러는 추첨권의 총 개수를 파악합니다. ( 예를 들어 100개 )
- 스케줄러는 추첨권을 뽑습니다.
- 추첨권은 0부터 99까지 있으며, A가 0~74, B가 75~99까지 가지고 있습니다.
- 뽑힌 추첨권 값에 따라 다음에 실행될 프로세스가 결정됩니다.
예시 ) 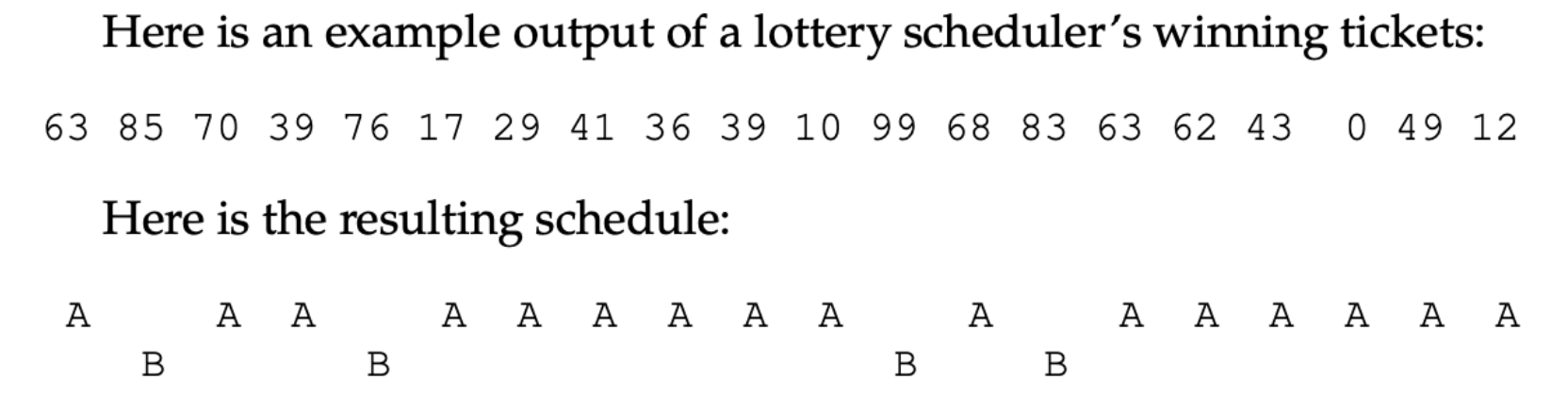
현재, 예시에서 볼 수 있듯이 무작위성으로 추첨을하기 때문에 원하는 비율을 정확히는 보장하지 않습니다.
80:20의 비율로 실행하게 되었지만, 두 작업의 시간이 길어질수록 결국 추첨권의 지분의 비율로 수렴하게 됩니다.
추첨 기법
추첨권을 다루는 방법은 여러가지가 있습니다.
먼저, 추첨권 화폐(Ticket Currency)의 개념을 알아보겠습니다.
이 개념은 사용자가 추첨권을 자신의 화폐 가치로 추첨권을 자유롭게 할당할 수 있도록 허용합니다. 시스템은 자동적으로 화폐가치를 변환합니다.
예를 들어, 사용자 A와 B가 각각 100개의 추첨권을 받았다고 합시다.
A는 A1과 A2 두 작업을 실행중이며, 자신이 정한 화폐로 각각 500장의 추첨권을 할당하였습니다.
B는 하나의 작업을 실행 중이고 자신의 기준 화폐 10장 중에 10장을 할당하였습니다.
시스템이 만약 이대로 스케줄링을 하게 되면 500:500:10으로 스케줄을 하기 때문에 공정하지 못하게 됩니다.
따라서, 각각의 사용자가 가지고 있는 화폐를 전체 기준이 되는 화폐 단위로 변경하여 추첨을 진행합니다.

이렇게 변환하게 되면 50:50:100 의 비율로 추첨 스케줄이 되며 공정한 스케줄이 되었다고 할 수 있습니다.
다른 유용한 기법으로는 추첨권 양도(Ticket Transfer)가 있습니다.
양도를 통하여 프로세스는 일시적으로 추첨권을 다른 프로세스에게 넘겨줄 수 있습니다.
이 기능은 클라이언트-서버 환경에서 특히 유용합니다.
클라이언트 프로세스는 서버에게 메세지를 보내 자신을 대신해 특정 작업을 해달라고 요청합니다.
작업이 빨리 완료될 수 있도록, 클라이언트는 서버에게 추첨권을 양도하고 서버가 자신의 요청을 수행하는 동안 서버의 성능을 극대화하려고합니다.
요청을 완수하면, 서버는 클라이언트에게 추첨권을 돌려주고 원래와 같은 상황이됩니다.
마지막으로 추첨권 팽창(Ticket Inflation)도 좋은 방법입니다.
이 기법에서는 프로세스가 자신의 티켓을 일시적으로 늘리거나 줄일 수 있습니다.
서로 신뢰하지않는 프로세스들이 상호 경쟁하는 상황에서는 의미가 없습니다.
하지만, 신뢰하는 상황에서는 유용하게 사용됩니다.
어떤 프로세스가 많은 CPU 시간이 필요하다면, 시스템에게 이를 알리는 방법을 통해 다른 프로세스들과 통신하지 않고 혼자 추첨권의 가치를 상향조정하게 됩니다.
구현
추첨 스케줄링의 장점은 구현이 간단하다는 것입니다.
필요한 것은 난수 발생기와 프로세스들의 집합을 표현한는 자료 구조 ( ex, 리스트 ) 그리고 추첨권의 개수 뿐입니다.


위의 그림과 같이 3개의 프로세스들이 있고 각 프로세스는 티켓을 가지고 있습니다.
총 티켓수는 400입니다.
먼저 세 작업 중 어떤 작업을 스케줄링할지 정하기 위해 400 이하의 무작위 한 숫자를 하나 고릅니다.
만약 300이 선택되었다고 하면, 리스트를 순회하며 카운터 값을 통해 당첨자를 찾아냅니다.
리스트를 순회할 때는 각 노드 ( 프로세스 )의 티켓값을 더하면서 체크하는데, 티켓 값의 합이 랜덤으로 정해진 값 ( 여기서는 300 )보다 크게 되면 그곳에서 break를 하게 되고 ( 여기서는 C ) 그 프로세스를 실행하게 됩니다.
일반적으로, 리스트를 티켓 번호를 기준으로 내림차순으로 정렬하여 효율적으로 과정을 수행할 수 있게됩니다.
예제
추첨 스케줄링의 동작을 이해하기 위해, CPU를 공유하는 두 개의 작업의 수행시간을 살펴보겠습니다.
각 프로세스는 같은 개수의 추첨권 100개를 가지고 있으며, 동일한 실행 시간을 가집니다.
우리는 두 작업을 거의 동시에 종료시키고 싶습니다.
그러나 스케줄링의 무작위성 때문에, 동시에 종료되지 않을 수 있습니다.
이 차이를 계산해보기위해 불공정 지표인 U를 정의하겠습니다.
U는 첫번째 작업이 종료된 시간을 두 번째 작업이 종료된 시간으로 나눈 값입니다.
현재 작업은 같은 작업 시간을 가지고 있으므로, 0.5에 가까울수록 불공정하며 1에 가까울수록 공정하다는 것을 알 수 있습니다.
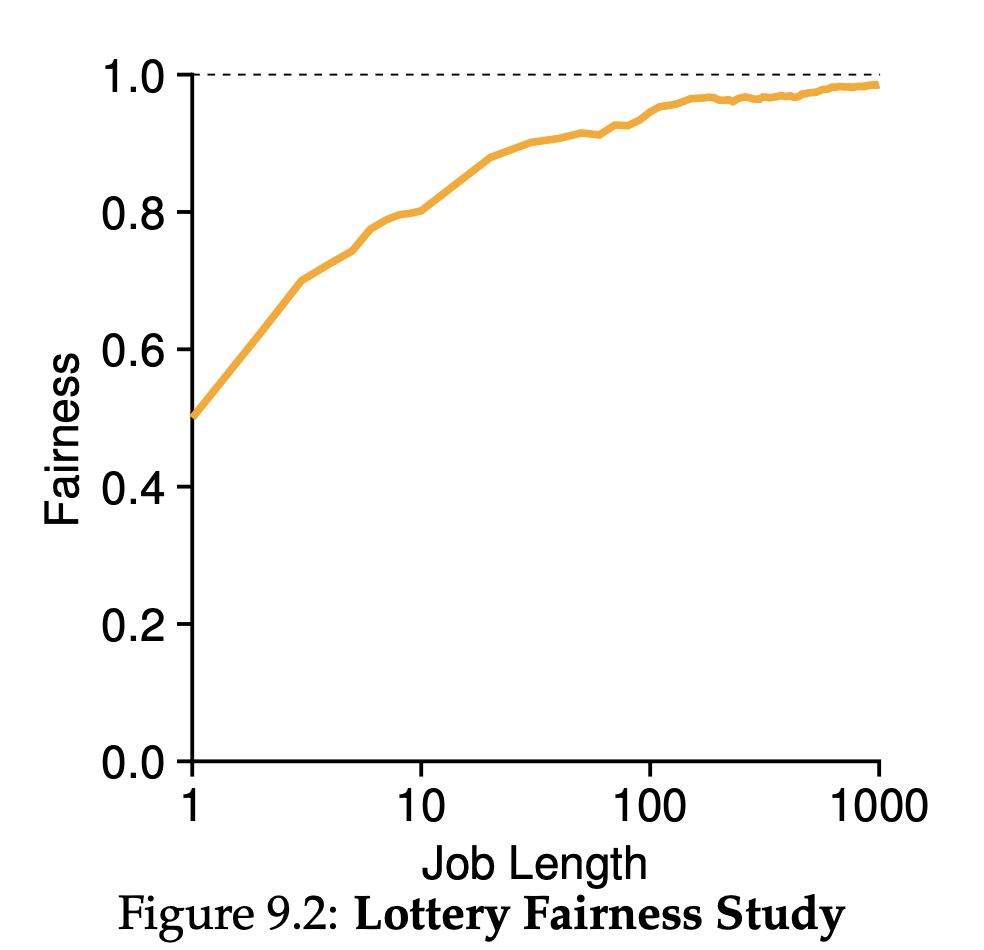
위 그림에서 간단하게 불공정 지표와 작업 시간의 관계를 볼 수 있습니다.
두 작업의 수행시간을 1에서 100까지 동일하게 증가시켰으며, 작업시간이 증가함에 따라 공정한 스케줄러가 되고있다는 것을 알 수있습니다.
역으로, 작업시간이 짧을 때는 불공정 정도가 심각하게 좋지않다는 것을 알 수 있습니다.
따라서 작업시간이 충분히 길어야 추첨 스케줄러가 원하는 결과에 가까워진다는 것을 알 수 있습니다.
추첨권 배분 방식
우리는 아직 추첨권을 작업에게 어떻게 몇 개씩 나누어 줄지에 대한 얘기를 하지 않았습니다.
이 방식은 어려운 문제이며, 한가지 접근 방식은 사용자가 가장 잘안다고 가정하여 사용자가 티켓을 나누어주는 것입니다.
하지만 이것은 해결책이 되지 못합니다.
왜 결정론적 방법을 사용하지 않는가
우리는 무작위성 스케줄러를 만들면 간단하게 만들 수 있지만, 공정하지 못한 상황이 나타날 수 있다는 것을 알아보았습니다.
이 때문에 결정론적 공정 배분 스케줄러인 보폭 스케줄링(Stride Scheduling)이 나타나게 되었습니다.
이 스케줄러는 시스템의 각 작업은 보폭을 가지고 있다고 가정합니다.
보폭은 자신이 가지고 있는 추첨권 수에 반비례하는 값입니다.
예를 들어, A,B,C 작업이 각각 100,50,250개의 추첨권을 가지고 있다면 보폭은 100, 200, 40이 됩니다.
이 보폭은 프로세스가 실행될 때마다 pass라는 값을 보폭만큼 증가시켜, 얼마나 CPU를 사용하였는지 추적합니다.
스케줄러는 보폭과 pass 값을 사용하여 어느 프로세스를 실행시킬지 결정합니다.
- 가장 작은 pass 값을 가진 프로세스를 선택하여 실행합니다.
- 프로세스를 실행시킬 때마다 pass 값을 보폭만큼 증가시킵니다.

아래 예시를 통해 자세히 살펴보겠습니다.
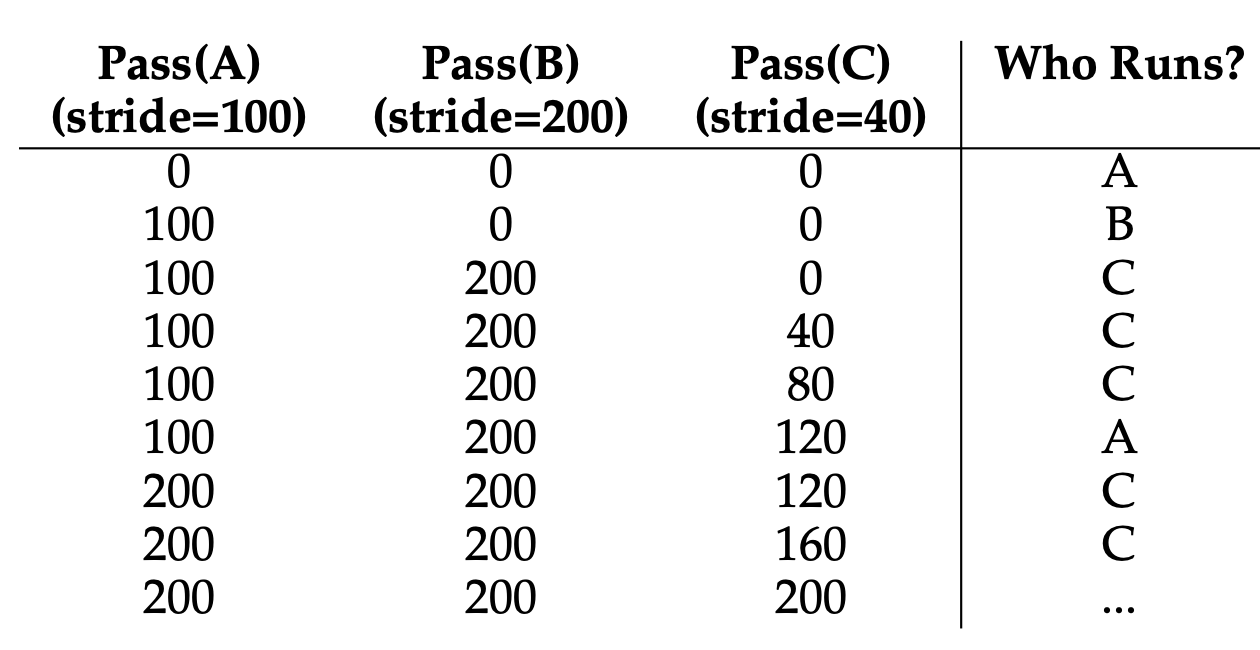
위 표를 보면 A,B,C 프로세스가 존재하며 각각의 보폭은 100,200,40 입니다.
처음 pass 값은 모두 0으로 같기 때문에 아무 프로세스나 실행될 수 있습니다.
- A를 선택했다고 가정하면, A가 실행되고 pass가 100이 됩니다.
- 그 후 B가 실행되며 pass가 200이 됩니다.
- C가 실행되며 pass가 40이 됩니다.
- 다시 가장 작은 pass를 가진 C가 두 번 연속 실행되며 120이 됩니다.
- 그 후 A가 실행되서 100이 됩니다.
- 다시 C가 실행됩니다
- 위 과정을 계속 반복합니다.
표에 나타나있는 실행 횟수를 계산하면 A는 2번 B는 1번 C는 5번으로 각각의 추첨권의 개수 100,50,250의 비율과 일치합니다.
그런데, 그렇다면 왜 보폭 스케줄링을 안쓰고 스케줄링을 사용하는걸까요?
추첨 스케줄링은 보폭 스케줄링과 달리 상태정보가 필요없습니다.
위 보폭 스케줄링 도중 새로운 작업이 시스템에 도착했다고 가정해봅시다.
그렇다면 그 작업의 pass는 0이 될 것이며, CPU를 독점하게 될 것입니다.
하지만, 추첨 스케줄링은 이와 달리 pass라는 상태를 유지할 필요가 없고 새 프로세스를 추가할 때 새로운 프로세스가 가진 추첨권의 개수, 전체 추첨권의 개수만 갱신하면 됩니다.
이러한 이유로 추첨 스케줄링은 새 프로세스를 쉽게 추가할 수 있습니다.
리눅스 CFS
현재 리눅스는 기존과는 다른 방식으로 공정 배분 스케줄링을 구현하였습니다
이른바 Completely Fair Scheduler ( CFS, 완전 공정 스케줄러 )입니다.
효율성을 위해, CFS는 최적의 내부 설계와 자료구조를 사용하여 스케줄링 결정을 매우 신속히 사용합니다.
하지만, 이러한 노력에도 불구하고 스케줄러가 CPU 사용량의 5%를 사용한다고 합니다.
이렇기 때문에 효율적인 스케줄러(오버헤드가 적은 스케줄러)는 아주 중요합니다.
기본 연산
CFS는 모든 프로세스들에게 균등하게 CPU를 분배하는 것을 목표로합니다.
이 목표를 달성하기위해 virtual runtime이라는 간단한 counting 기반 테크닉을 사용합니다.
프로세스가 실행되면, 스케줄러는 해당 프로세서의 vruntime의 값을 누적시킵니다.
기본적인 경우, 각 프로세스의 vruntime은 실제 시간과 같은 속도로 증가합니다.
스케줄링시 CFS는 가장 낮은 vruntime을 가진 프로세스를 다음에 실행할 프로세스로 정합니다.
스케줄러가 어느 시점에서 다른 프로세스로 전환을 하게될까요?
CFS가 자주 실행되면 많은 context switching이 일어나 시스템 성능에 악영향을 미칠 수 있습니다.
드물게 일어나면, 시스템 성능은 향상되지만 공정성이 악화될 것입니다.
CFS는 이를 해결하기 위해, 다양한 통제 변수를 활용합니다.
sched_latency: CFS는 어느 프로세스가 전환되기 전에 이 값을 사용하여 다음 프로세스를 얼마나 실행할 지 정합니다. 보통 48ms이며, CFS는 이 값을 현재 실행 중인 프로세스의 개수로 나눠서 프로세스의 타임 슬라이스를 정합니다.
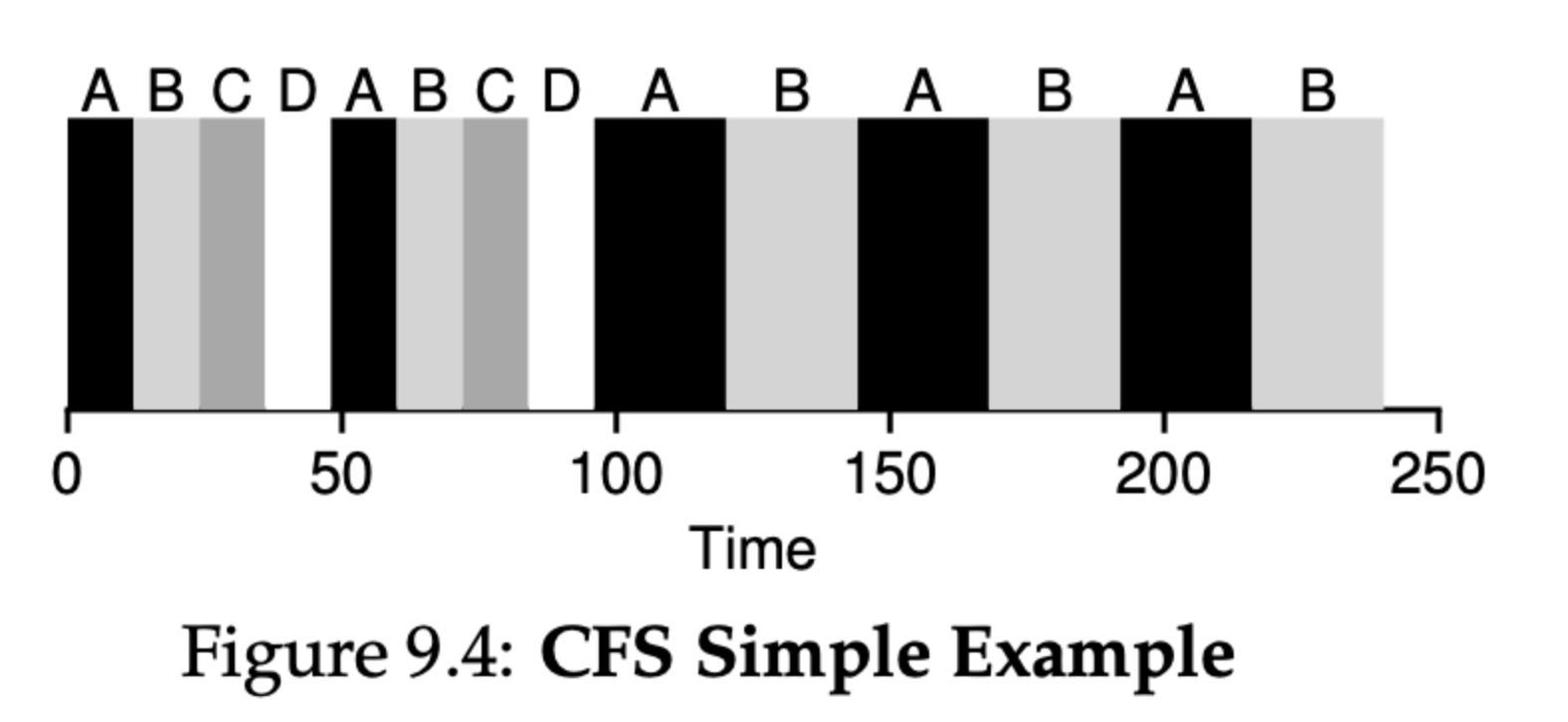
예를 들어, 현재 A,B,C,D 작업이 존재한다고 하겠습니다.
처음에는 48ms를 4개로 나누어 12ms 씩 실행하다가 C,D가 종료된 후 두 개의 프로세스가 각각 24ms씩 나누어서 실행하는 것을 볼 수 있습니다.
그런데 만약 너무 많은 프로세스들이 실행중이면 어떨까요?
너무 많은 context switching이 일어날텐데..
이 문제를 해결하기 위해 CFS는 최소 타임 슬라이스, min_granularity 라는 변수를 사용합니다.
보통 6ms 이며, 각 프로세스에게 할당 된 타임 슬라이스가 이 값 이하가 되지않도록 하여 스케줄링에 너무 많은 시간을 소비하지 않도록합니다.
예를 들어 10개의 작업이 있을 때 min_graularity에 의해 4.8ms가 아닌 6ms 씩 실행되어 sched_latency를 보장하기는 어려워지지만, 공정한 스케줄링이 간으하게 됩니다.
CFS는 주기적으로 발생하는 타이머 인터럽트에 의해 작동합니다.
즉, CFS는 특정 시간 간격으로만 스케줄링 결정을 내릴 수 있습니다.
타이머 인터럽트는 매 1ms로 매우 짧은 간격으로 발생하여 CFS는 현재 작업의 타임 슬라이스 소진 여부를 판단합니다.
가중치(Niceness)
CFS는 사용자나 관리자가 프로세스의 우선 순위를 조정하여 다른 프로세스들 보다 더 많은 CPU 시간을 할당 받을 수 있게 합니다.
티켓이 안닌 프로세스의 nice 레벨이라는 고전적 UNIX 메커니즘을 사용합니다
기본 값으로 0을 가지며, -20부터 19까지 가능합니다.
양수 값이면, 낮은 우선순위이고 음수 값이면 높은 우선순위입니다.
이 nice 값은 실제 가중치와 대응시켜 놓았고 프로세스의 실제 타임 슬라이스를 계산하는데 사용됩니다.
Red Black Tree의 활용
CFS의 핵심은 알고리즘의 효율성이다.
효율적 알고리즘을 이용하여, 실행할 프로세스를 신속히 선정하는 것이 매우 중요하다.
여기서는 레드 블랙 트리를 사용함으로써 효율성 문제를 해결하였다.
이 레드 블랙트리는 균형 트리이기 때문에 탐색 연산에서 O(logN)의 복잡도를 유지할 수 있다.
CFS가 모든 프로세스를 레드 블랙 트리에 저장하지는 않는다.
실행중이거나 실행가능한 프로세스는 트리에 저장하고, sleep 상태인 프로세스는 다른 곳에 보관된다.
I/O와 sleep 프로세스 다루기
A와 B 두 프로세스가 있다고 가정하자.
A는 계속 실행하고 있으며, B는 장시간 ( 10초 ) 동안 sleep 중이였다고 가정하자.
B가 깨어나면, B의 vruntime은 다른 프로세스보다 10초 뒤처저 있을 것입니다.
그렇기에, 다음 10초동안 B가 CPU를 10초동안 독점하게 되고 A는 기아상태에 빠지게 될 것입니다.
이를 해결하기 위해, CFS는 작업이 sleep에서부터 깨어날 때 vruntime을 적절하게 재설정한다. ( 구체적으로 트리에서 가장 작은 값으로 재설정 )
이렇게 하면, 큰 오버헤드 없이 CFS는 기아현상을 방지할 수 있다.
요약
이번 포스트에서는 비례 배분 스케줄링을 소개하고, 추첨권 스케줄링, 보폭 스케줄링, 그리고 리눅스의 CFS를 알아봤습니다.
이 챕터에서는 무작위성을 이용한 스케줄러와 결정론적 방법을 사용하는 스케줄러를 알아보았고
마지막을 알아본 스케줄러만이 실제로 사용중인 스케줄러였습니다.
CFS는 동적 타임슬라이스와 가중치를 가진 RR기법의 스케줄러 같지만, 그 외에도 확장성과 성능을 보장합니다.
CFS는 현재 가장 많이 사용하고 있는 공정성 배분 스케줄러입니다.
