
공개 데이터 세트,CSV,판다스,데이터프레임,시리즈
데이터 분석으로 비즈니스 문제를 어떻게 해결하는지 알아보기 위해 가상의 예를 소개합니다. 문제에 맞는 데이터를 구하고 코랩에서 판다스 데이터프레임으로 CSV 파일을 읽고 쓰는 방법에 대해 배웁니다.
도서 데이터 찾기
혼공출판사에서 출간한 도서는 많지만, 시중에 판매되는 전체 도서에 비하여 매우 적다. 또 혼공출판사에는 혼공출판사의 판매 데이터만 있기 때문에 어떤 도서가 인기가 많은지 분석하기에는 데이터가 부족하다. 이렇게 문제에 맞는 데이가 없는 상황에는 딱 맞는 데이터는 아니더라도 어느 정도 비슷한 데이터를 찾을 수 없는지 생각해 봐야 한다.
국대 대표적인 데이터 포털인 공공데이터포털 홈페이지에 접속하여 '도서 판매 데이터'를 검색해보자. 원하는 판매 데이터는 없지만 검색 결과에 도서관 데이터가 있다.
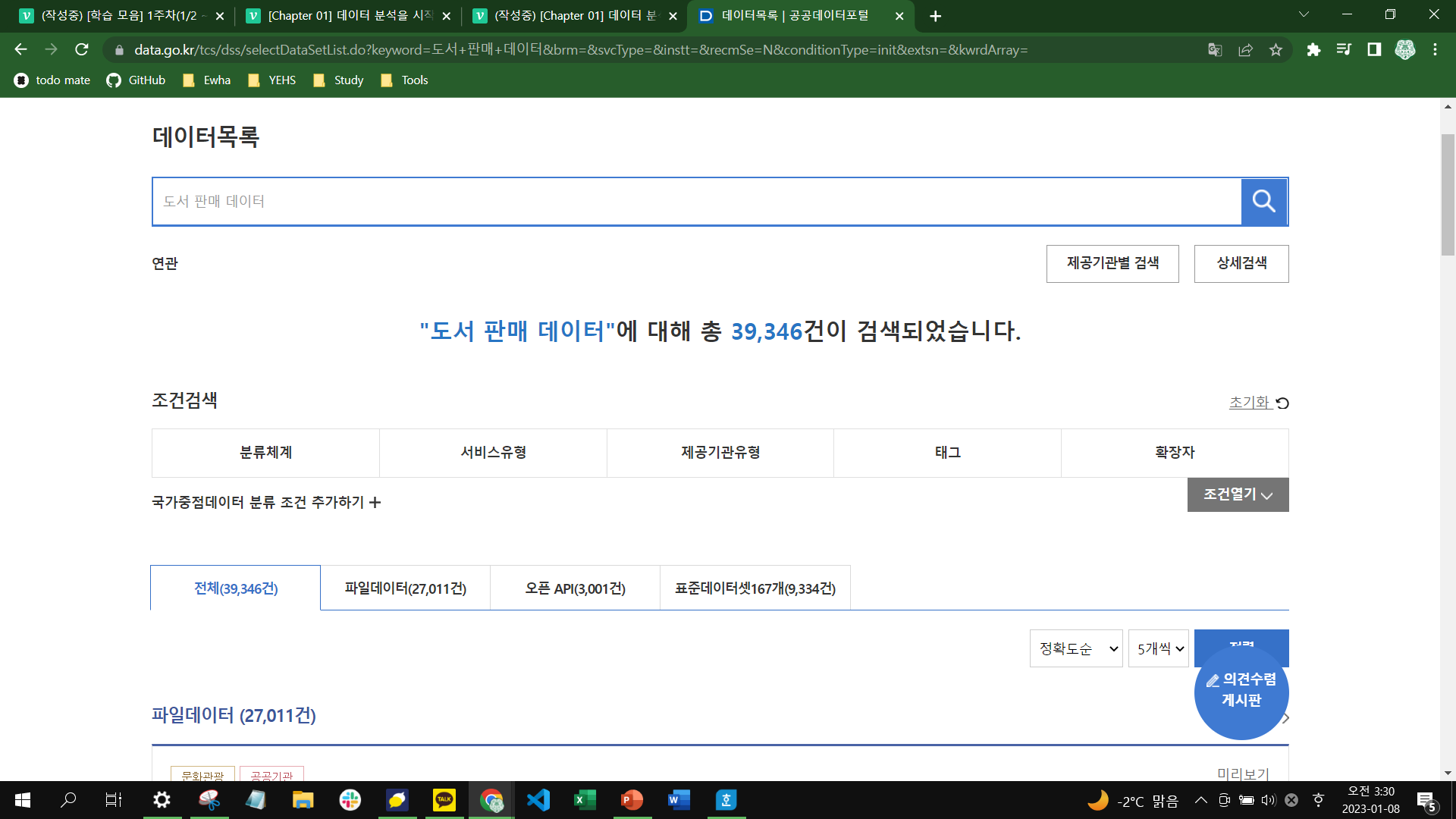
이것을 보고 우리는 도서관에서 대출이 많이 된 도서라면 인기가 높은 도서일 것이라는 생각을 할 수 있다. 검색 방향을 도서 판매 데이터에서 [도서관 대출 데이터]로 바꾸어 네이버에 검색하자.
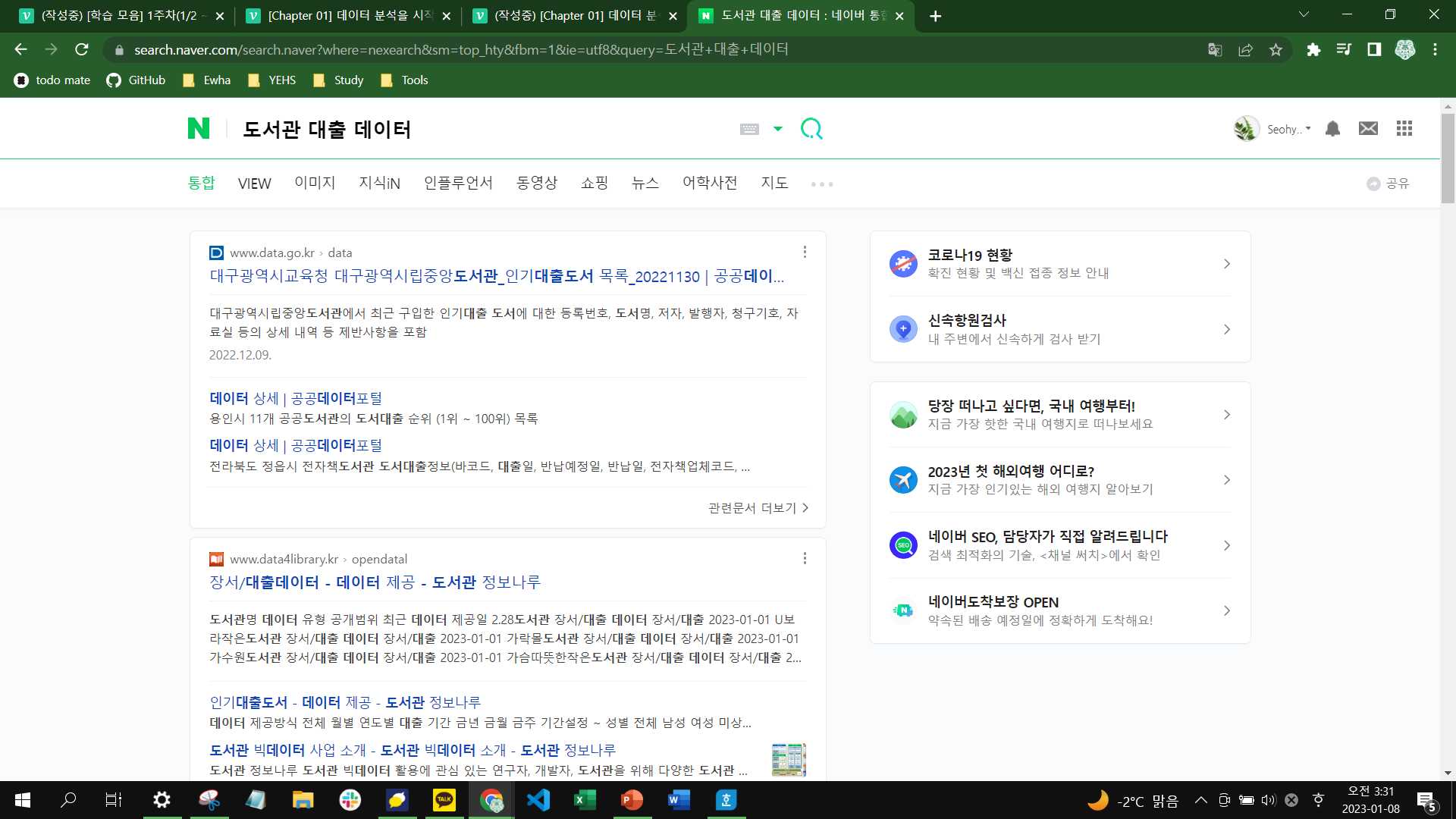
위의 사진과 같이 검색 결과에서 '도서관 정보나루'라는 사이트를 확인할 수 있다. 도서관 정보나루는 공공 도서관에서 발생하는 다양한 데이터를 제공하는 서비스로 국립중앙도서관이 운영하고 있다. 정보나루 홈페이지에서 도서관별 대출 데이터를 찾아보자.
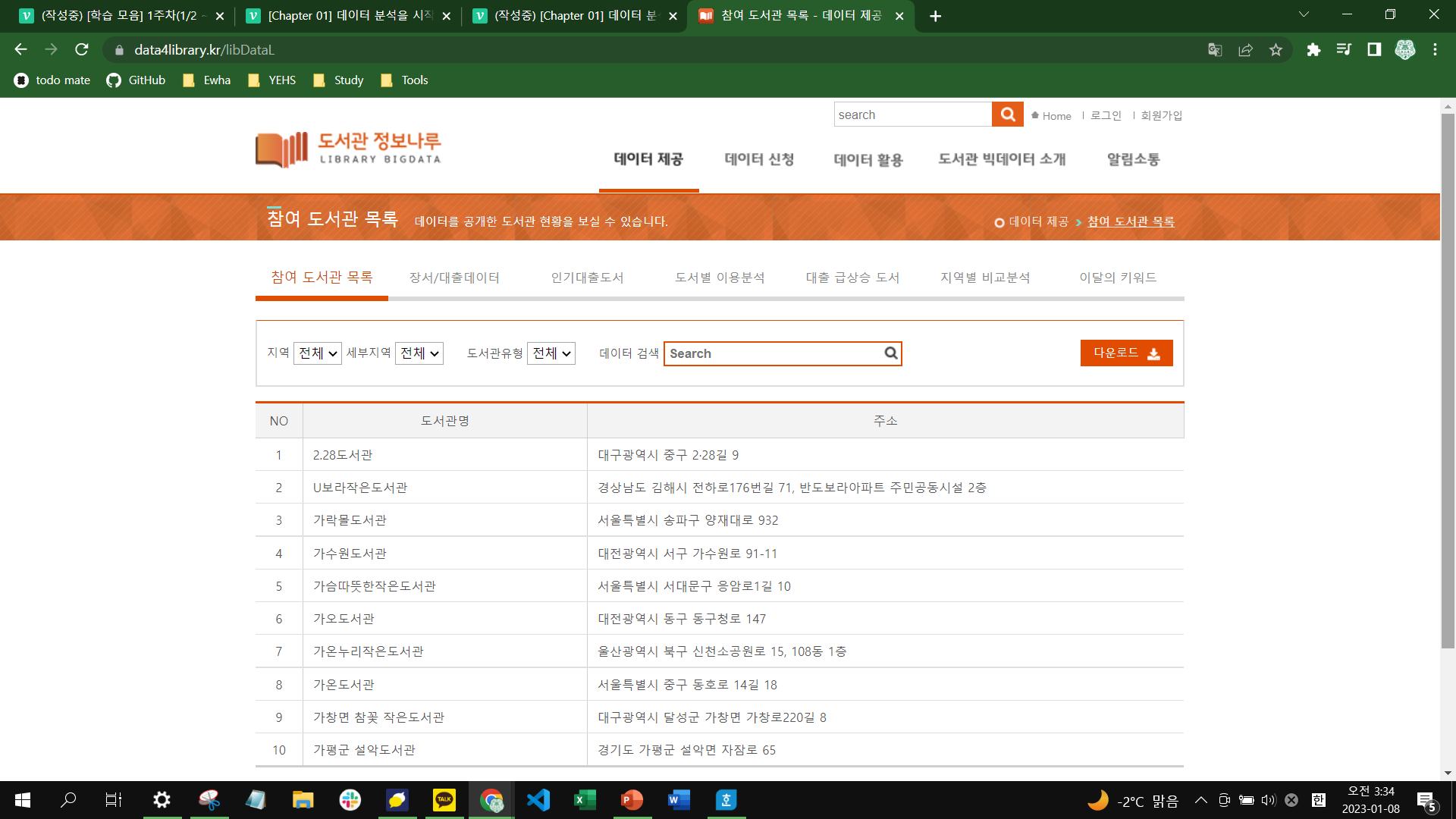
도서관 정보나루 웹사이트에 접속해서 상단 메뉴에 있는 [데이터 제공]을 클릭하면 위와 같이 도서관별로 대출 데이터를 확인할 수 있다. 우선, 많은 도서관 중에 보유 도서가 많은 남산도서관의 대출 데이터를 살펴보면 충분하다는 판단으로 데이터 검색을 해보자.
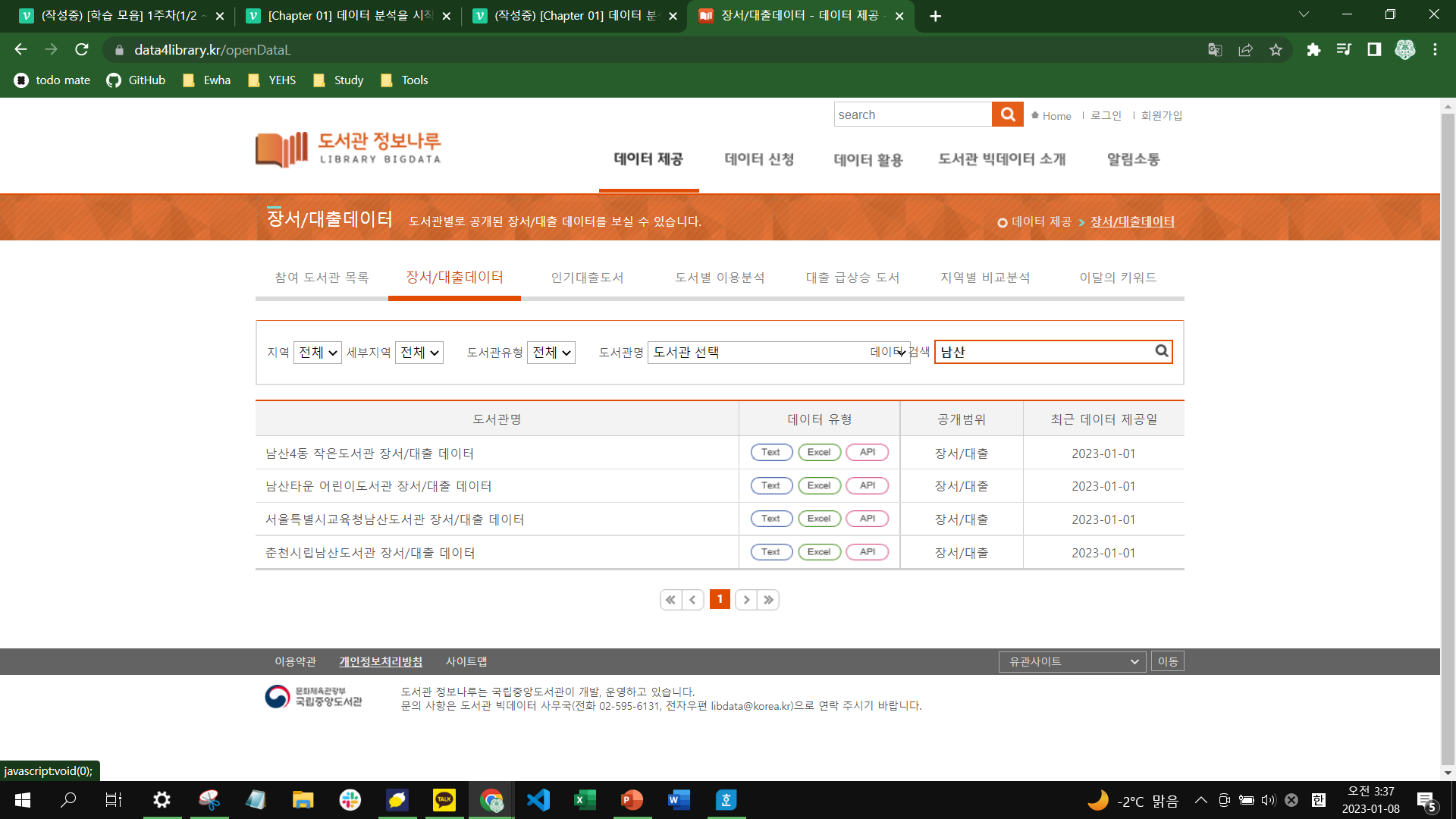
[장서/대출데이터] 탭의 [데이터 검색]란에 [남산]을 입력하여 데이터를 검색하여 나오는 위와 같은 결과 중에서 [서울특별시교육청남산도서관 장서/대출 데이터]를 클릭하여 남산도서관 데이터를 확인해보자.
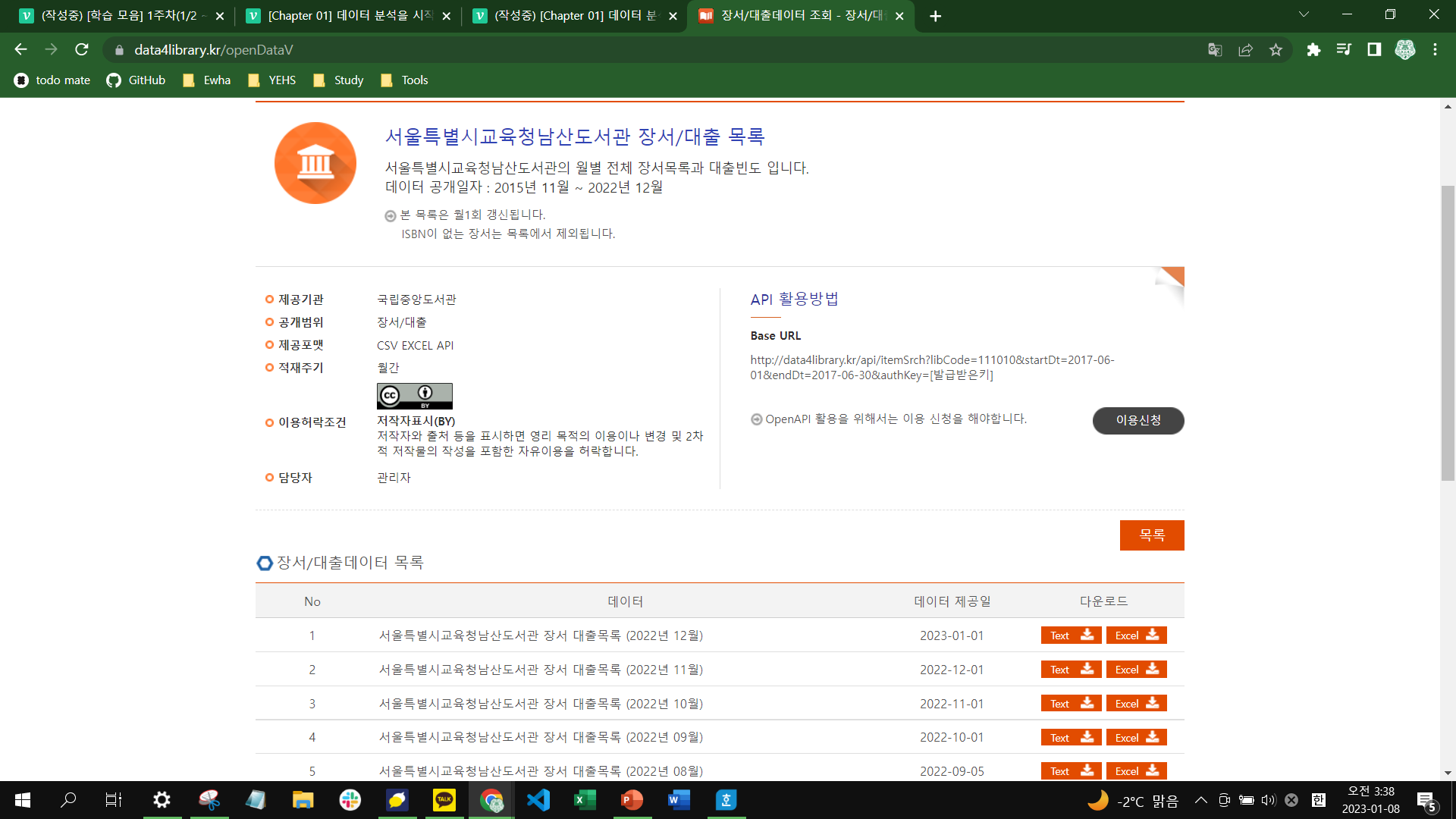
[제공포맷] 항목을 보면 도서 대출 데이터는 CSV, 엑셀, API로 제공된다. 그 아래 [적재주기] 항목을 보면 매월 데이터가 제공되는 것을 알 수 있다. 데이터 목록에도 매월 데이터가 추가된 것을 볼 수 있다. 현재 학습하는 시점의 최신 버전인 '서울특별시교육청남산도서관 장서 대출목록 (2022년 12월)'의 Text 버튼, Excel 버튼을 클릭하여 CSV와 엑셀 파일을 다운로드 하자.
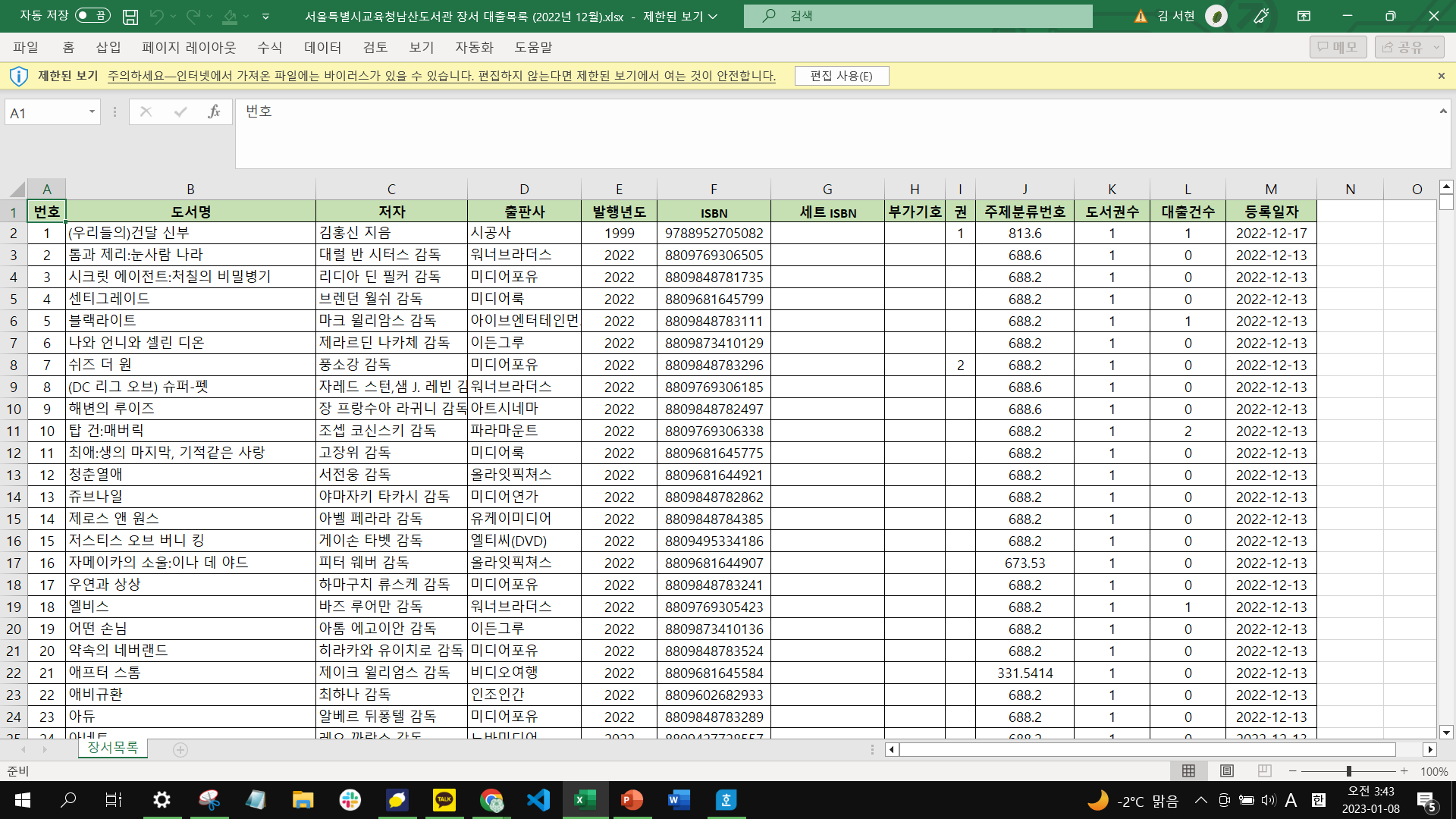
먼저 엑셀 파일을 열어보면 위와 같은 데이터를 확인할 수 있다. 도서명, 저자, 출판사와 같은 정보가 있다. 총 13개의 열이 있고 L 열에 대출건수가 있다.
코랩에서 데이터 확인하기
CSV(Comma Seperated Values) 파일은 콤마로 구분된 텍스트 파일이다. 한 줄이 하나의 레코드(Record)이며 레코드는 콤마로 구분된 여러 필드(Fiels)로 구성된다. 데이터는 엑셀처럼 표 형태여야 하기 때문에 레코드에 있는 필드 개수는 모두 동일하다.
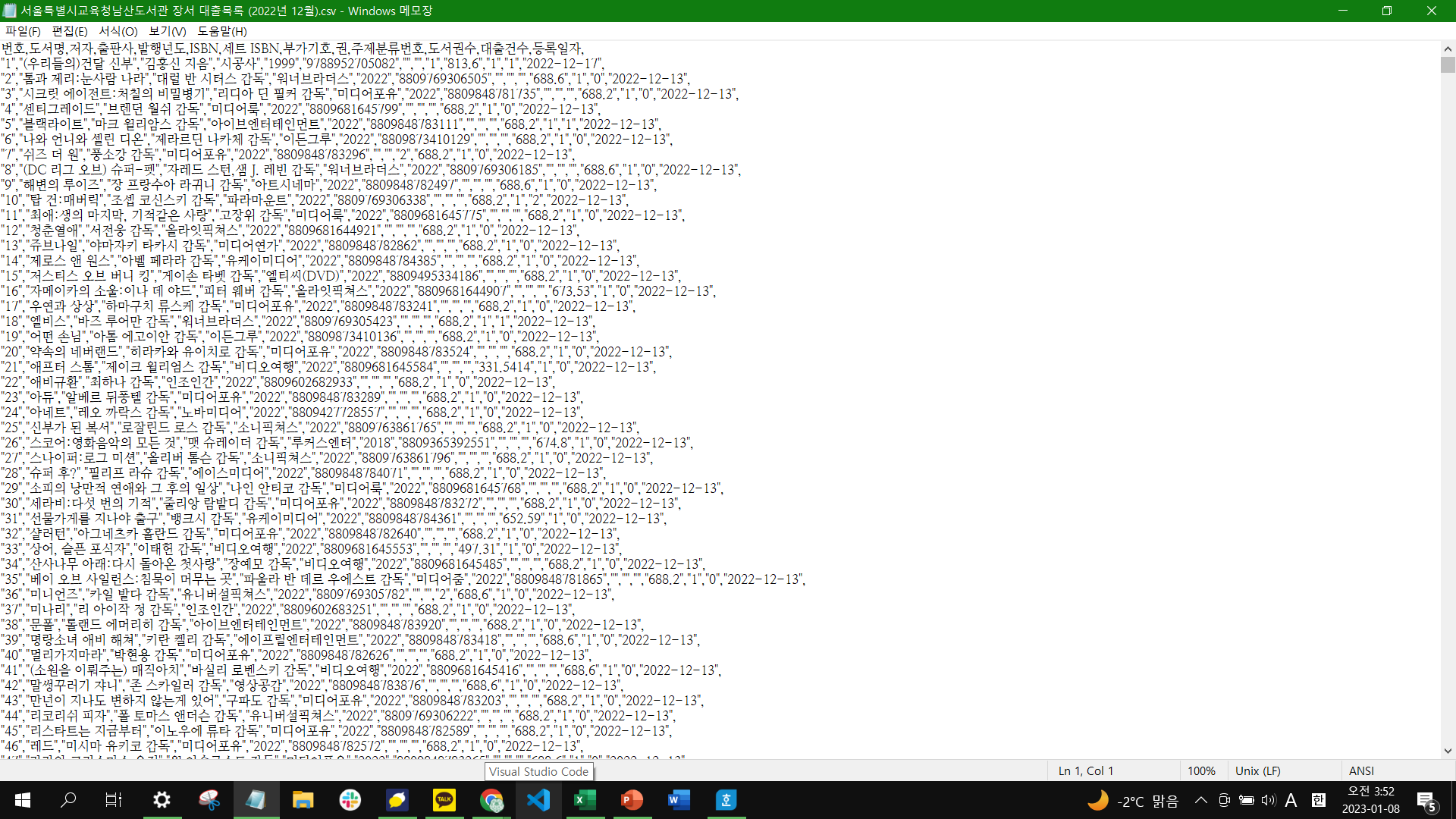
CSV 파일은 메모장 또는 엑셀 프로그램으로 열어볼 수 있다. 메모장으로 앞서 엑셀 화면에서 보앗던 표가 CSV 파일에는 위와 같이 저장되어 있음을 확인할 수 있다.
엑셀에서 보았던 행은 CSV 파일에서 한줄로, 열은 콤마로 구분된다. CSV 파일은 보기에 불편하지만 파이썬 같은 프로그래밍 언어에서는 오히려 사용하기 더 편리하다.
코랩에서 데이터 다운로드하기: dgown 패키지
gdown 패키지는 구글 드라이브를 포함하여 웹에서 대용량 파일을 다운로드할 수 있는 패키지이다. 코랩에 이미 설치되어 있기 때문에 편리하게 사용할 수 있다. 예시는 다음 코드와 같다.
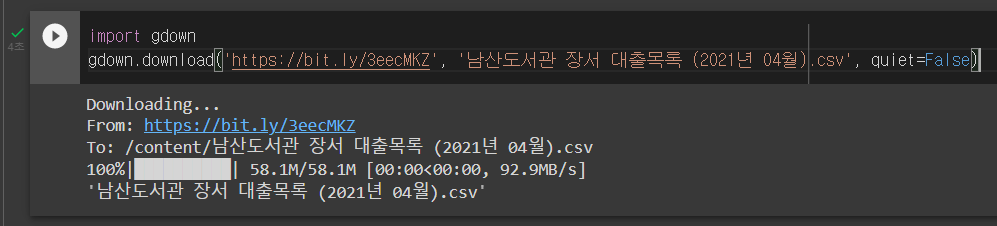
import gdown
gdown.download('https://bit.ly/3eecMKZ', '남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)실행 결과는 다음과 같다.
이 방식을 사용하면 다운로드 코드가 노트북에 저장되기 때문에 노트북을 다시 열 때 이 코드 셀을 실행해 주기만 하면 CSV 파일이 자동으로 준비된다.
내 컴퓨터 파일을 업로드하기
위 코드는 구글 드라이브에 올려져 있는 책의 실습 파일을 다운로드 받기 때문에 최근 날짜 데이터가 아니다. 이전에 다운받은 최신 데이터를 코랩에 업로드 하자.
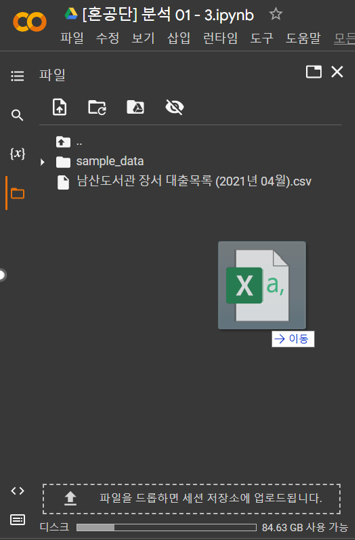
코랩에 파일을 업로드하려면 위와 같이 목차 창의 왼쪽에 위치한 파일 아이콘을 클릭하여 파일 창을 연 다음 내 컴퓨터에 있는 CSV 파일을 마우스로 드래그하여 파일 창 안에 놓는다. 또는 파일 창 안에 있는 파일 업로드 아이콘을 클릭해도 된다.
코랩은 일정 시간 동안 사용하지 않으면 자동으로 런타임과 연결이 끊어진다. 이때 업로드한 파일도 함께 삭제된다. 따라서 나중에 코랩에서 이 파일을 사용하려면 다시 업로드해야 한다.
파이썬으로 CSV 파일 출력하기
CSV 파일은 텍스트 파일이므로 파이썬의 open() 함수로 읽을 수 있다. 아래의 코드를 통해 with문으로 파일을 연 다음 readline() 메서드로 파일에서 한 줄을 읽어서 출력해보자.
with open('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv') as f:
print(f.readline())실행 결과는 다음과 같이 에러가 난다.
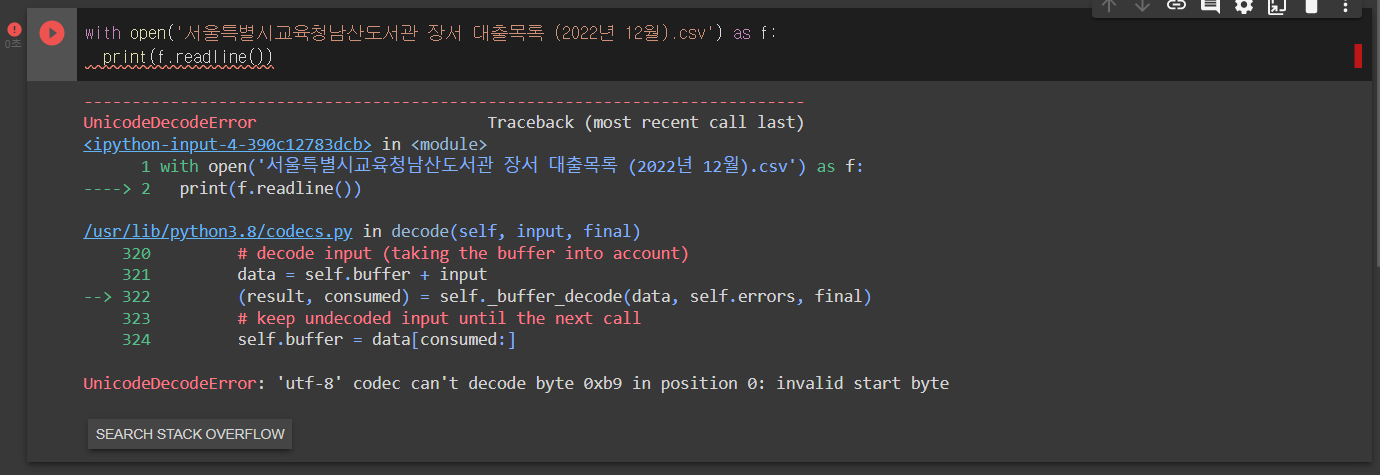
코드 내용을 보면 'UTF-8' 코덱이 0xb9 바이트를 읽지 못하고 있음을 알 수 있다. 파이썬의 open() 함수는 기본적으로 텍스트 파일인 UTF-8 형식으로 저장되어 있다고 가정한다. 하지만 한글 텍스트는 여전히 완성형 인코딩인 EUC-KR을 사용하는 일이 잦다.
❓ 인코딩이란
인코딩(Encoding) 혹은 문자 인코딩은 문자를 컴퓨터가 이해할 수 있는 0과 1의 이진 형태로 바꾸는 것을 말한다. UTF-8은 전 세계 모든 문자를 컴퓨터에 표현하기 위해 만들어진 유니코드를 인코딩하는 방식 중의 하나로 최대 4바이트까지 사용한다. EUC-KR은 한글을 위한 완성형 인코딩 중 하나로 2바이트를 사용한다.
현재 데이터의 인코딩 형식을 확인해보자.
파일 인코딩 형식 확인하기: chardet.detect() 함수
파이썬에서 chardet 패키지의 chardet.detect() 함수를 사용하면 문자 인코딩 방식을 알아낼 수 있다.
우선 open() 함수로 텍스트 파일을 열 때 mode 매개변수를 바이너리 읽기 보드인 'rb'로 지정한다. 바이너리 모드로 지정하면 문자 인코딩 형식에 상관없이 파일을 열 수 있으므로 오류가 발생하지 않기 때문이다. 단, 텍스트 파일을 바이너리 모드로 읽으면 모든 글자를 1바이트로 인식하기 떄문에 한글과 같은 유니코드 문자를 화면에 올바르게 출력할 수는 없다.
참고로 open() 함수 mode 매개변수의 기본값은 텍스트 읽기 모드인 'r'이다.
chardet.detect() 함수에 데이터를 넣어 어떤 인코딩을 사용하는지 출력하자.
코드를 작성하면 다음과 같다.
import chardet
with open('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))실행 결과는 다음과 같다. 예상대로 EUC-KR 인코딩을 사용하고 있음을 알 수 있다.

그렇다면 EUC-KR 인코딩 파일을 오류없이 출력하려면 어떻게 해야 할까?
인코딩 형식 지정하기
open() 함수로 파일을 읽을 때 encoding 매개변수로 인코딩 형식을 'EUC-KR'로 지정하면 된다. 아래와 같은 코드로 다시 실행해보자.
with open('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv', encoding='EUC-KR') as f:
print(f.readline())
print(f.readline())실행 결과는 다음과 같이 올바르게 출력된다.

CSV 파일은 판다스 같은 도구로 읽는 것이 조금 더 편리하지만 아주 큰 파일을 열 때는 오랜 시간이 걸리므로 open() 함수와 readline() 메서드로 처음 몇 줄을 출력해 보는 것이 빠른 방법일 수 있다.
❓ 파일명이 한글인데 인식을 못하는 경우
한글을 유니코드로 표현할 때 글자 단위로 저장하는 것을 NFC 방식(e.g 혼공), 자음과 모음을 따로 저장하는 방식을 NFD 방식(e.g ㅎㅗㄴㄱㅗㅇ)이라고 한다.
윈도우와 리눅스는 전자의 방식을 사용하지만 맥OS는 후자의 방식을 사용한다. 만약 맥OS 사용자에게 파일을 받았거나 NFD 방식의 이름이라고 의심된다면 다음 코드를 통해 NFC 방식의 이름으로 바꿀 수 있다.import os import glob import unicodedata for filename in glob.glob('*.csv'): nfc_filename = unicodedata.normalize('NFC', filename) os.rename(filename, nfc_filename)
데이터프레임 다루기: 판다스
데이터프레임과 시리즈
판다스는 CSV 파일을 읽어 데이터프레임(DataFrame)이라는 행과 열로 구성된 데이터 구조인 표 형식 데이터로 저장한다.
판다스에는 데이터프레임 외에 시리즈(Series)라는 데이터 구조도 있다. 프로그래밍 언어에서 배열은 같은 종류의 데이터가 순서대로 나열된 데이터 구조를 말한다. 배열은 나열된 축이 하나인 경우 1차원 내열, 축이 2개인 경우 2차원 배열이라고 한다. 시리즈는 1차원 배열, 데이터프레임은 2차원 배열과 비슷한다.
시리즈에 담긴 데이터는 모두 동일한 종류(정수, 문자열 등), 데이터프레임에 담긴 데이터는 같은 열에 대해서는 같은 종류여야 한다. 열마다는 다른 데이터 타입을 사용할 수 있다.
CSV 파일을 데이터프레임으로 읽기: read_csv() 함수
판다스에서 CSV 파일을 읽을 때는 read_csv() 함수를 사용한다. read_csv() 함수를 호출하려면 판다스를 임포트해야 한다. as 키워드로 임포트할 패키지를 아래 코드와 같이 줄일 수 있다. 보통 판다스는 pd로 줄인다.
import pandas as pd
df = pd.read_csv('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv', encoding='EUC-KR')실행 결과는 다음과 같이 에러가 발생한다.

판다스는 CSV 파일을 읽을 때 '도서명'과 '대출건수' 같은 열에 어떤 종류의 데이터가 저장되어 있는지 자동으로 파악한다. 가령 '도서명'은 문자열로 인식하고 '대출건수'는 정수로 인식하는 것이다. 그런데 메모리를 효율적으로 사용하기 위해 CSV 파일을 조금씩 나우어 읽는데 데이터 타입이 달라지면 경고가 발생한다.
해당 파일에서는 'ISBN', '세트 ISBN', '주제분류번호'에 해당하는 5, 6, 9 열 때문에 오류가 발생했다. 해결 방법은 low_memory 매개변수를 False로 지정하여 파일을 나누어 읽지 않고 한 번에 읽는 것이다.
import pandas as pd
df = pd.read_csv('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv', encoding='EUC-KR', low_memory=False)실행 결과는 다음과 같이 정상적으로 코드 실행이 완료된다.

low_memory 매개변수를 False로 지정하면 경고는 발생하지 않지만, CSV 파일을 한 번에 모두 읽기 때문에 많은 메모리를 사용한다. CSV 파일이 아주 큰 경우 메모리 부족 오류가 발생할 수 있다. low_memory 매개변수를 사용하지 않는 다른 방법은 열의 데이터 타입을 아래 코드와 같이 dtype 매개변수로 지정하는 것이다.
df = pd.read_csv('서울특별시교육청남산도서관 장서 대출목록 (2022년 12월).csv', encoding='EUC-KR', dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호': str})데이터가 제대로 가져왔는지 확인해 보려면 아래 코드와 같이 head() 메서드를 사용하면 데이터프레임의 처음 다섯 개 행을 확인할 수 있다.
df.head()실행 결과는 다음과 같다.
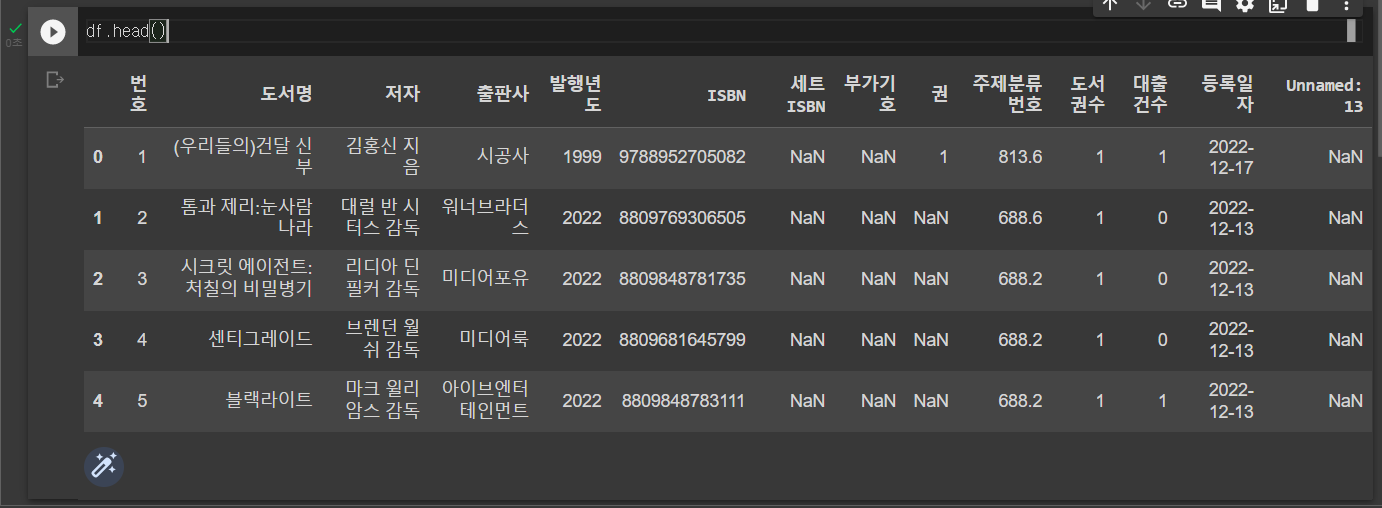
판다스는 데이터프레임을 표 형식으로 행과 열을 맞추어 출력한다.
첫 번째 열은 데이터프레임의 인덱스(index)다. 판다스는 행마다 0부터 시작하는 인덱스 번호를 자동으로 붙여준다. 그리고 CSV의 첫 번째 행은 열 이름으로 인식한다.
CSV 파일의 첫 행이 열 이름이 아니라면 read_csv() 함수를 호출할 때 header 매개변수를 None으로 지정해서 데이터 첫 행에 열 이름이 없다는 것을 알리고, names 매개변수에 열 이름 리스트를 따로 전달해준다. 이때 names 매개변수에 전달하는 열 이름에 중복된 이름이 있어서는 안된다.
위 실행 결과의 마지막 열에 원래 CSV 파일에는 없던 'Unnamed: 13' 열이 생겼다. 이 열은 CSV 각 라인의 끝에 콤마가 있었기 떄문이다. 판다스는 이 콤마를 보고 마지막에 하나의 열이 더 있다고 판단한 것이다. 처리 방법은 추후에 알아보자.
데이터프레임을 CSV 파일로 저장하기: to_csv() 메서드
판다스의 데이터 프레임을 CSV로 저장할 떄는 to_csv() 메서드를 사용한다. to_csv() 메서드는 기본적으로 UTF-8 형식으로 저장하기 때문에 나중에 open() 함수로 파일의 내용을 읽을 때 따로 encoding 매개변수를 사용하지 않아도 된다.
다음과 같이 to_csv() 메서드로 데이터프레임을 ns_202104.csv 파일로 저장한다.
df.to_csv('ns_202104.csv')실행 결과는 다음과 같다. 파일 창의 디렉터리에 ns_202104.csv 파일이 생성되어 있다는 것을 확인할 수 있다.
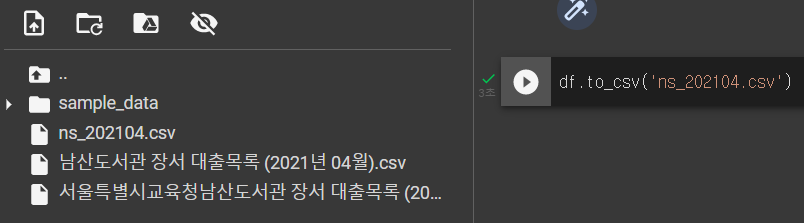
저장한 CSV 파일을 다시 open() 함수로 확인해 보자.
with open(`ns_202104.csv`) as f:
for i in range(3):
print(f.readline())실행 결과는 다음과 같다. print() 함수가 자동으로 줄바꿈 문자(\n)를 출력해서 CSV 파일의 라인 끝에 있는 줄바꿈 문자와 중복되어 한 줄씩 건너뛰어 출력됐다.

이것을 해결하기 위해 코드를 다음과 같이 수정하자.
with open(`ns_202104.csv`) as f:
for i in range(3):
print(f.readline(), end='')실행 결과에서 볼 수 있듯이 다음과 같이 출력할 수 있다.

그런데 앞서 출력했던 CSV 파일 결과와 다르게 CSV 파일 맨 왼쪽에 데이터프레임에 있던 행 인덱스가 함께 저장됐다. 데이터프레임으로 읽어보자.
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()실행 결과를 보면 인덱스가 다시 생성되면서 'Unnamed: 0'이라는 첫 번쨰 열과 중복된다.
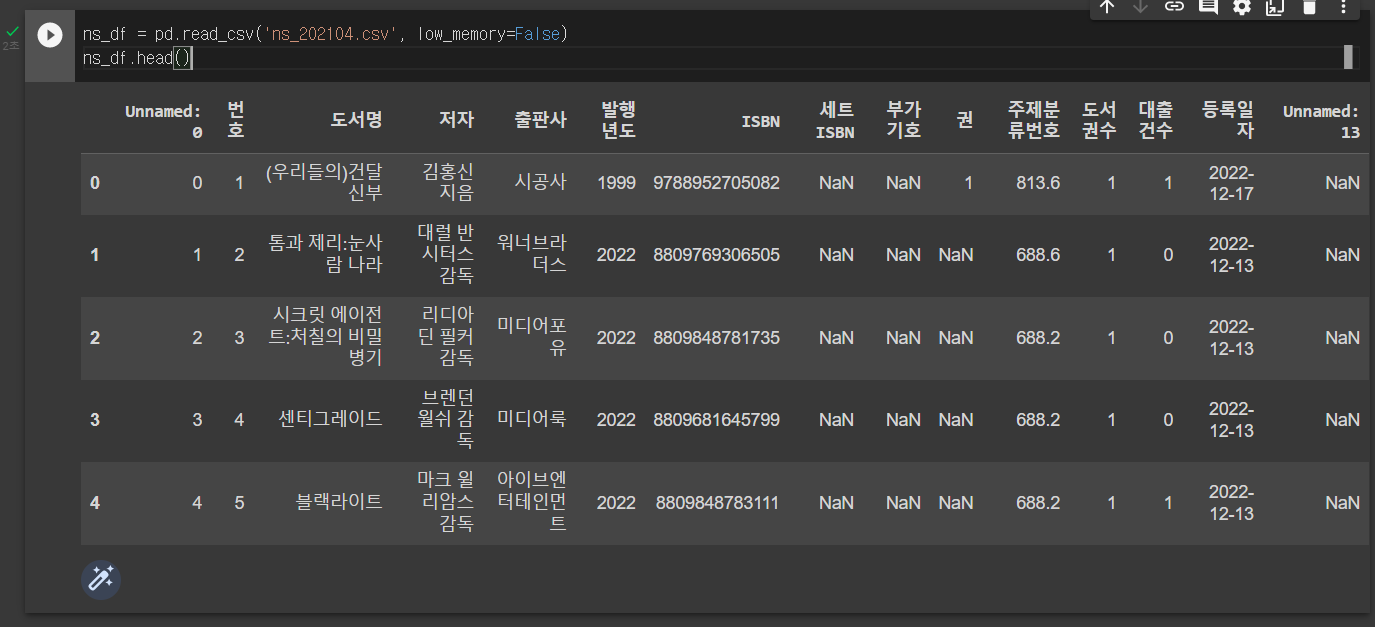
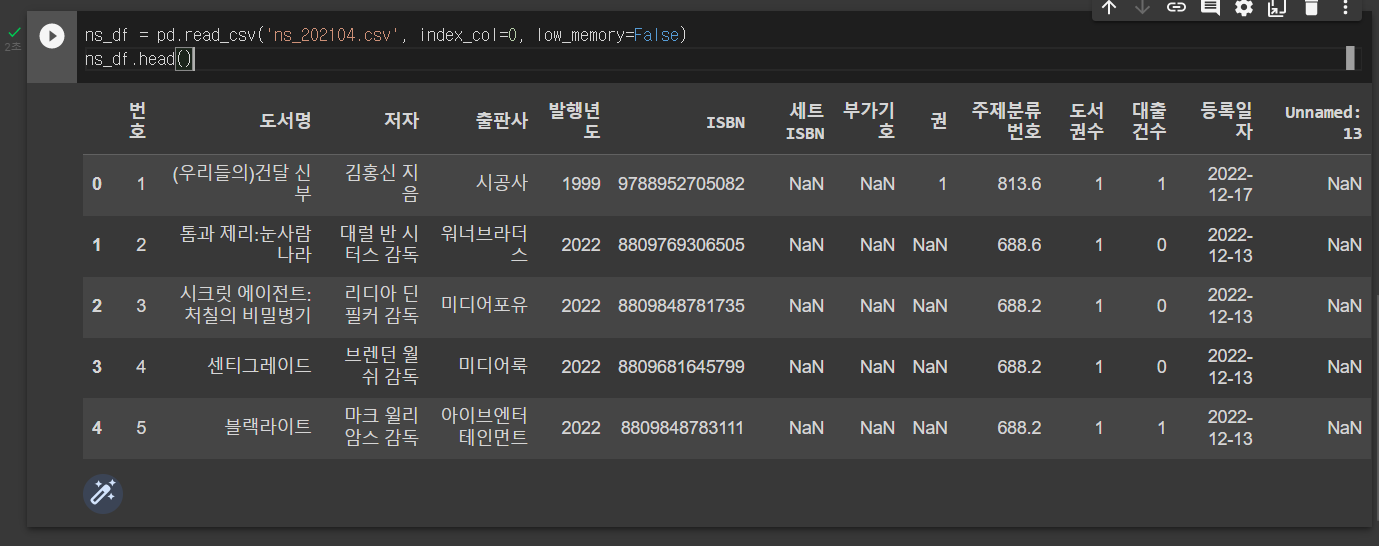
CSV 파일에 인덱스가 이미 있다는 것을 알려 주려면 index_col 매개변수를 사용한다. 'ns_202104.csv' 파일에는 첫 번째 열에 인덱스가 있으므로 0으로 지정한다.
ns_df = pd.read_csv('ns_202104.csv', index_col=0, low_memory=False)
ns_df.head()아래 실행 결과를 보면 'ns_202104.csv' 파일의 첫 번째 열이 데이터프레임의 인덱스로 지정된 것을 알 수 있다.
또 다른 방법은 처음부터 데이터프레임을 CSV 파일로 저장할 때 인덱스를 빼고 저장하는 것이다. 다음처럼 to_csv() 메서드에 index 매개변수를 False로 지정한다.
df.to_csv('ns_202104.csv', index=False)🤓 데이터프레임을 엑셀로 저장하려면?
다음과 같이 코드를 작성하면 된다.ns_df.to_excel('ns_202104.xlsx', index=False)판다스는 엑셀 파일을 만들기 위해 기본적으로
openpyxl패키지를 사용한다. 그런데 이 패키지로 한글 데이터를 쓰면 오류가 발생할 수 있기 때문에xlsxwriter패키지를 사용하는게 좋다. 다음과 같이pip명령어로 해당 패키지를 설치한 후 engine을 지정하면 된다.!pip install xlsxwriter ns_df.to_excel('ns_202104.xlsx', index=False, engine='xlsxwriter')
좀 더 알아보기
공개 데이터 세트 대표 사이트와 유명 포럼
국내 사이트
해외 사이트
온라인 포럼
정리
5가지 키워드로 정리하는 핵심 포인트
- 공개 데이터 세트: 기업이나 정부 등이 무료로 공개하는 데이터 세트로, 누구나 저작권에 상관없이 다운로드하여 데이터 분석이나 제품 개발에 활용할 수 있음
- CSV: 콤마로 구분된 텍스트 파일로, 한 줄이 하나의 레코드이며, 레코드는 콤마로 구분된 여러 필드 혹은 열로 구성되는데 데이터가 엑셀처럼 표 형태를 가져야 하기 떄문에 레코드에 이쓴ㄴ 필드 개수는 모두 동일해야 함
- 판다스: 표 형식 데이터를 위한 편리한 도구를 다양하게 제공하는 강력한 데이터 분석 패키지로, CSV나 엑셀 파일을 읽거나 쓸 수 있으며 데이터 분석을 위한 많은 기능을 제공함
- 데이터프레임: 판다스의 핵심 데이터 구조로 행과 열로 구성되며 CSV 파일이나 엑셀 파일로부터 만들 수 있음
- 시리즈: 1차원 배열과 흡사한 판다스 객체로, 한 종류의 데이터만 포함할 수 있음
표로 정리하는 핵심 함수와 메서드
| 함수/메서드 | 기능 |
|---|---|
| pandas.read_csv() | CSV 파일을 읽어 데이터프레임을 만듦 |
| DataFrame.head() | 데이터프레임에서 처음 다섯 개의 행을 반환 |
| DataFrame.to_csv() | 데이터프레임을 CSV 파일로 저장 |
