
API,HTTP,JSON,XML
API 방식은 사내외를 가리지 않고 웹사이트나 다른 팀의 협조 없이도 가장 편리하게 데이터를 수집할 수 있는 방법입니다. 공공 데이터 세트는 API를 사용해 제공하는 경우가 많습니다. 이 절에서는 API 개념과 웹 기반 API를 사용하는 방법을 배웁니다. 또한 CSV 외에 JSON, XML 같은 새로운 데이터 포맷도 소개합니다.
API란
데이터 분석가가 종종 데이터베이스에 직접 접근하기 어려울 때가 있다. 데이터베이스 접근 권한이 엄격히 관리되거나, 민감한 개인 정보가 이썩나, 아예 네트워크가 분리되어 물리적인 접근이 불가할 수도 있다. 이럴 때 인증된 URL만 있으면 언제든지 필요한 데이터에 편리하게 접근할 수 있는 방식이 API다.
API(Application Programming Interface)는 두 프로그램이 서로 대화하기 위한 방법을 정의한 것이다. 예를 들어 우리가 사용하는 윈도우나 맥OS 같은 운영체제는 문서 작성 프로그램이 디스크에 있는 파일을 읽고 쓸 수 있도록 API를 제공한다. 또 기상청에서 제공하는 API를 사용하면 지역별, 실시간 날씨 정보를 얻을 수 있다.
API를 구현하는 방법은 다양하고 각기 장단점이 있다. 애플리케이션 간의 통신을 위해서는 웹 기반의 API가 널리 사용된다. 따라서 이번 학습에서도 웹 기반의 API에 초점을 맞추어 알아보자.
웹 페이지를 전송하기 위한 통신 규약: HTTP
웹사이트는 웹 페이지를 서비스하기 위한 웹 서버 소프트웨어를 사용한다. 대표적인 웹 서버 프로그램으로는 NGINX, Apache 등이 있다. 이런 웹 서버 프로그램은 웹 브라우저와 통신할 때 HTTP란 통신 규약인 프로토콜(protocol)을 사용한다.
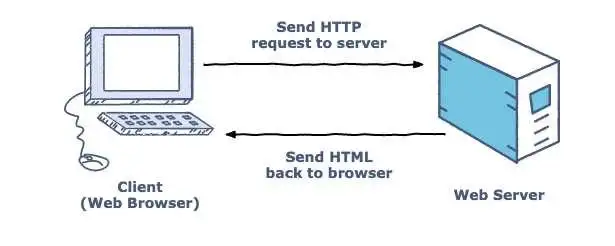
사진 출처
HTTP(Hyper Text Transfer Protocol)는 인터넷에서 웹 페이지를 선송하는 기본 통신 방법이다. 웹 브라우저가 웹 서버에 웹 페이지를 요청하고, 웹 서버는 요청에 맞는 웹 페이지를 웹 브라우저에게 전송하다. 웹 서버는 네이버 같은 웹사이트에서 운영하고, 웹 브라우저는 내 컴퓨터에 설치되어 있다.
데이터 분석가는 이렇게 HTTP 프로토콜을 사용해 API를 만다는 웹 기반 APi를 사용하는 방법을 아는 것이 중요하다.
웹 페이지 문서: HTML
웹 서버와 웹 브라우저 두 소프트웨어 프로그램은 웹 페이지를 구성하는 HTML 데이터를 주고받을 수 있다.
HTML(Hypertext Markup Language)은 웹 브라우저가 화면에 표시할 수 있는 문서의 한 종류이자 웹 페이지를 위한 표준 언어이다. 웹 브라우저 프로그램이 이해할 수 있도록 체계적으로 구성되어 있는 단순한 테스트로, 이와 같은 언어를 마크업(markup) 언어라고 부른다.
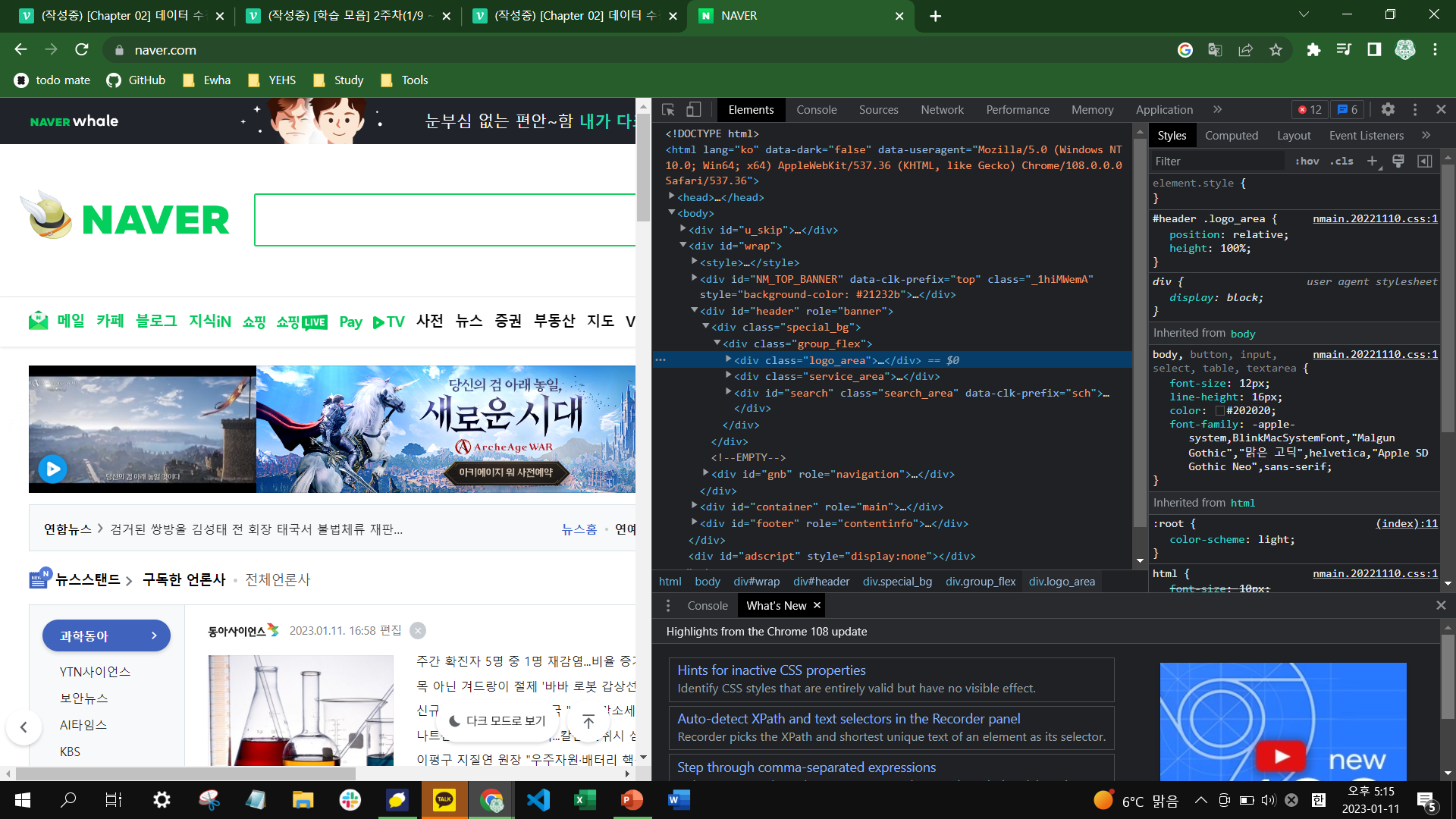
위의 사지은 크롬 브라우저에서 마우스 오른쪽 버튼을 클릭하고 [페이지 소스 보기] 메뉴를 선택함으로 확인한 네이버 랜딩페이지의 HTML 내용이다. <div>와 같은 표시를 태그(tag)라고 부른다.
웹 기반 API는 웹 서버와 웹 브라우저가 대화하는 방식과 비슷하다. HTTP 프로토콜을 사용하지만 HTML을 주고받는 것이 아니라 일반적으로 CSV, JSON, XML 같은 파일을 사용한다. HTML 소스는 구조가 비교적 복잡하기 떄문에 프로그램에 버그가 생길 가능성이 높고 오류를 찾기 어렵기 때문이다.
파이썬에서 JSON 데이터 다루기
JSON은 JavaScript Object Notaion의 약자로, 원래는 자바스크립트 언어를 위해 만들어졌다. 현재 대부분의 프로그래밍 언어는 JSON 형태의 텍스트를 읽고 쓰 수 있다.
JSON은 파이썬의 딕셔너리(Dictionary)와 리스트(List)를 중첩해 놓은 것과 비슷하다. 예를 드어 <혼자 공부하는 데이터 분석>이라는 도서명을 JSON객체로 나타내면 다음과 같이 중괄호를 사용하고 파이썬의 딕셔너리와 비슷하게 키(Key)와 값(Value)을 콜론(:)으로 연결한다.
{"name": "혼자 공부하는 데이터 분석"}키와 값에 문자열을 쓰려면 항상 큰따옴표로 감싸 주어야 한다. 코랩에서 아래 코드를 이용해 JSON 형식으로 파이썬 딕셔너리를 만들어 보자.
d = {"name": "혼자 공부하는 데이터 분석"}
print(d['name'])실행 결과는 다음과 같다.

이처럼 JSON 포맷을 파이썬 딕셔너리와 잘 호환된다. 다만, 웹 기반 API로 데이터를 전달할 때는 파이썬 딕셔너리가 아닌 텍스트로 전달해야 한다.
파이썬 객체를 JSON 문자열로 변환하기: json.dumps() 함수
파이썬의 json 패키지를 사용해 딕셔너리 d를 JSON 형식에 맞는 문자열로 바꿔보자. 먼저 아래 코드와 같이 json 패키지를 임포트하자.
import jsonjson 패키지에서 파이썬 객체를 JSON 형식에 맞는 텍스트로 바꿀 때는 json.dumps() 함수를 사용한다. 아래 코드로 앞에서 만든 딕셔너리 d를 변환해보자.
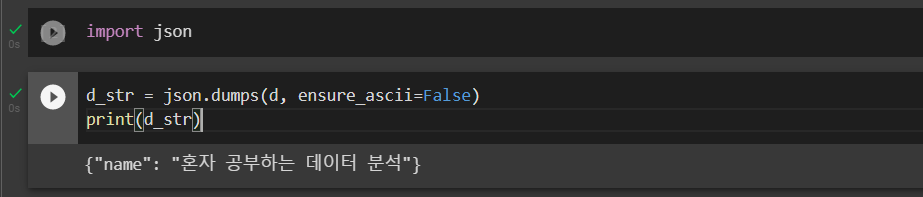
d_str = json.dumps(d, ensure_ascii=False)
print(d_str)실행 결과는 다음과 같다. 중괄호 안에 키와 값이 있는 JSON 형식의 문자열로 잘 변환되었다.
json.dumps() 함수를 사용할 떄 ensure_ascii 매개변수를 False로 지저안 이유는 딕셔너리 d에 한글이 포함되어 있기 때문이다. 기본저긍로 json.dumps() 함수는 아스키 문자 외의 다른 문자를 16진수로 출력하기 때문에 한글이 제대로 보이지 않는다. 그래서 ensure_ascii=False로 원래 지정된 문자를 그대로 출력하도록 한다.
d_str이 문자열 객체인지 아래의 코드를 참고해 파이썬의 type() 함수로 확인해 보자.
print(type(d_str))실행 결과는 다음과 같다. 딕셔너리가 문자열로 제대로 바뀌었다.

웹 기반 API는 전송하려는 파이썬 객체를 json.dumps() 함수를 사용하여 JSON 문자열로 변환하여 전송한다. 그런데 이런 JSON 문자열을 파이썬 프로그램에 사용하려면 다시 파이썬 딕셔너리로 바꾸어야 한다.
JSON 문자열을 파이썬 객체로 변환하기: json.loads() 함수
json.loads() 함수를 사용하면 JSON 문자열을 파이썬 객체로 변환할 수 있다.
🤓 왜 바로 파이썬 객체를 전송하지 않고 문자열로 바꾸어 전송할까?
웹 기반 API가 사용하는 HTTP 프로토콜이 텍스트 기반이기 떄문이다. 웹 브라우저에서 HTML 소스를 봤을 때 텍스트로 출력되었다. 그래서 HTTP 프로토콜로 데이터를 전송하려면 먼저 객체를 텍스트로 변환해야 한다. 이렇게 프로그램 상의 객체를 저장하거나 읽을 수 있는 형태로 변환하는 것을 직렬화(serialization)라고 한다. 반대로 직렬화된 정보를 다시 프로그램에서 실행 가능한 객체로 변환하는 것을 역직렬화(deserialization)라고 한다.
아래 코드를 통해 json.loads() 함수로 d_str 문자열을 파이썬 딕셔너리로 바꾸어 보자. 딕셔너리로 잘 변환되었는지 확인하기 위해 d2에서 name 항목도 출력해보자. 추가로 d2 타임도 확인해 보자.
d2 = json.loads(d_str)
print(d2['name'])
print(type(d2))실행 결과는 다음과 같다. 예상과 같이 문자열이 json.loads() 함수를 통해서 파이썬 딕셔너리로 바뀌었다.

이처럼 웹 기반 API에서 전달되는 데이터가 JSON 문자열이라면 혼공분석은 json.loads() 함수를 사용해 파이썬 객체로 변환한 다음 분석 프로그램에 사용하면 되겠다.
json.loads() 함수에 JSON 문자열을 직접 전달하여 더 복잡한 구조를 아래 코드로 전달해 보자.
d3 = json.loads('{"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022}')
print(d3['name'])
print(d3['author'])
print(d3['year'])실행 결과는 다음과 같다. 여러 개의 항목을 가진 JSON 문자열을 json.loads() 함수에 성공적으로 딕셔너리를 변경했다.

작가가 여러 명인 경우에는 어떻게 할까? 아래 코드와 같이 JSON은 대괄호 안에 여러 항목을 나열하여 배열을 표현할 수 있다. 마치 파이썬의 리스트와 비슷하다.
d3 = json.loads('{"name": "혼자 공부하는 데이터 분석", "author": ["박해선","홍길동"], "year": 2022}')
print(d3['author'][1])실행 결과는 다음과 같다.

여러 개의 도서를 포함한 구조를 작성해보자. JSON 객체를 대괄호 안에 나열하면 JSON 배열을 나태날 수 있다. 이때, 아래 코드와 같이 문자열이 길기 때문에 파이썬 세겹따옴표를 사용해 여러 줄에 걸친 문자열을 만들어보자.
d4_str = """
[
{"name": "혼자 공부하는 데이터 분석", "author": ["박해선"], "year": 2022},
{"name": "혼자 공부하는 머신러닝+딥러닝", "author": ["박해선"], "year": 2020}
]
"""
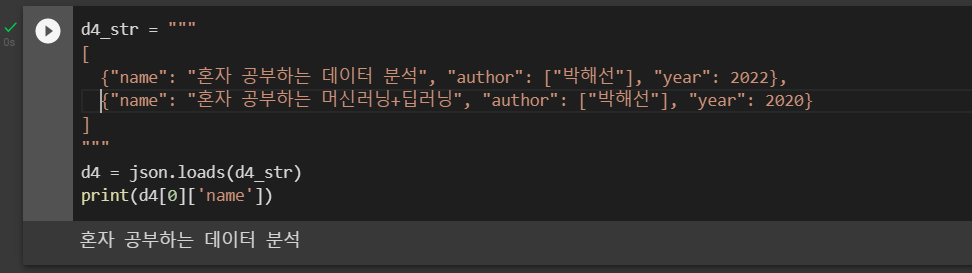
d4 = json.loads(d4_str)
print(d4[0]['name'])실행 결과는 다음과 같다.
JSON 문자열을 데이터프레임으로 변환하기: read_json() 함수
JSON 문자열을 데이터프레임으로 바꾸어 보자. 판다스는 JSON 문자열을 읽어서 데이터프레임으로 변환하는 read_json() 함수를 제공한다. 아래 코드로 앞에서 만든 d4_str 문자열을 판다스 데이터프레임으로 변환해보자.
import pandas as pd
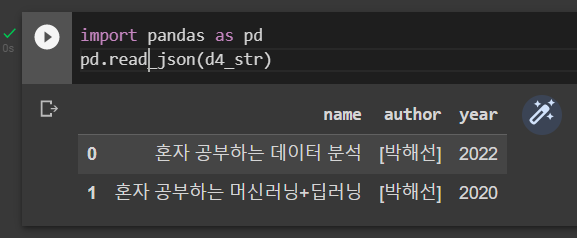
pd.read_json(d4_str)실행 결과는 다음과 같다. JSON 객체 두 개가 데이터프레임의 각 행에 잘 매핑(Mapping) 되었다.
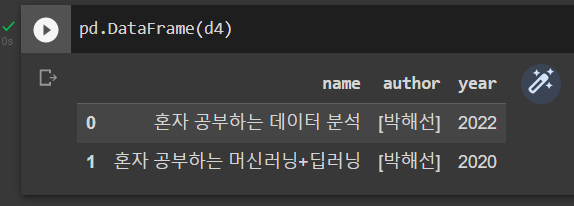
JSON을 데이터프레임으로 바꾸는 또 다른 방법은 JSON 문자열을 파이썬 객체로 만든 다음 DataFrame 클래스를 사용하는 것이다. 아래 코드로 앞에서 d4_str을 파이썬 객체로 변환한 d4를 사용해 데이터프레임을 만들어보자.
pd.DataFrame(d4)실행 결과는 다음과 같다.
파이썬에서 XML 데이터 다루기
XML은 eXtensible Markup Language의 약자이다. HTML은 웹 페이지를 표현하는 데는 뛰어나지만, 구조적이지 못하기 떄문에 프로그램 간의 약속대로 전송하는 API에서는 적합하지 않다. 때문에 XML이 고안되었다.
XML은 엘리먼트(element)들이 계층 구조를 이루면서 정보를 표현한다. 엘리먼트는 시작 태그와 종료 태그로 감싼다. 태그는 '<' 기호로 시작해서 '>' 기호로 끝나며 태그 이름은 영문자와 숫자를 사용한다. 이때 시작 태그와 종료 태그의 이름은 같아야 한다. 단, 종료 태그에는 이름 앞에 '/'가 붙는다. 태그 이름은 특수 문자와 공백 문자를 포함할 수 없고 '-', ','와 숫자로 시작할 수 없다.
아래 예시를 보자.
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book><book> 엘리먼트가 세 개의 하위 엘리먼트를 가지고 있다. 이때 <book> 엘리먼트를 부모 엘리먼트(parent element) 혹은 부모 노트(parent node)라고 부른다. <name>, <author>, <year> 엘리먼트는 <book> 엘리먼트의 자식 엘리먼트(child element)이다.
🤓 태그 이름을 정하는 규칙?
태그 이름은 안에 담긴 정보가 잘 드러나도록 정하는 것이 좋다. 이것은 마치 데이터프레임의 열 이름이나 파이썬의 변수 이름을 정하는 것과 비슷하다. 또 동일한 자식 엘리먼트를 여러 개 포함하는 부모 엘리먼트는 복수형으로 사용하는 것이 이해하기 쉽다. 예를 들어<book>엘리먼트를 여러 개 포함하는 부모 엘리먼트의 태그 이름은<books>라고 정한다.
XML 문자열을 파이썬 객체로 변환하기: fromstring() 함수
XML을 파이썬의 세겹따옴표로 문자열로 만든 다음, 파이썬에서 제공하는 xml 패키지를 사용해 읽어 보자. 먼저 아래 코드와 같이 XML 문자열을 x_str 변수에 저장한다.
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
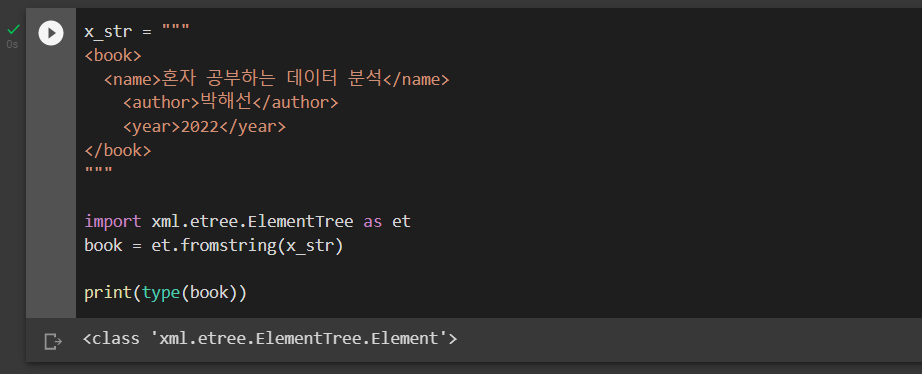
"""파이썬에서 기본으로 제공되는 xml 패키지는 XML 문서를 읽고 쓸 수 있는 간편한 API를 제공한다. 여기서는 아래 코드와 같이 xml.etree.ElementTree 모듈의 fromstring() 함수를 사용해 x_str 문자열을 XML로 변환해 보자.
import xml.etree.ElementTree as et
book = et.fromstring(x_str)json 패키지는 JSON 문자열을 파이썬 객체로 변환하지만, fromstring() 함수가 반환하는 객체는 단순한 파이썬 객체가 아니라 ElementTree 모듈 아래에 정의된 Element 클래스의 객체이다. 아래 코드로 type() 함수로 fromstring() 함수가 어떤 객체를 반환하는지 book 변수의 타입을 확인해 보자.
print(type(book))실행 결과는 다음과 같다.
또한 book 객체는 x_str에서 가장 먼저 등장하는 부모 엘리먼트인 <book>에 해당한다. 아래 코드와 같이 book 객체의 tag 속성을 출력하면 엘리먼트 이름을 쉽게 확인할 수 있다.
print(book.tag)실행 결과는 다음과 같다.

자식 엘리먼트 확인하기: findtext() 메서드
위 XML 문서에서 도서명, 저자, 발행 연도를 추출하기 위해서는 <book> 엘리먼트의 자식 엘리먼트를 구한 다음, 각각의 자식 엘리먼트에 담긴 텍스트를 읽어야 자식 엘리먼트를 구하는 코드는 아래와 같다.
book_childs = list(book)
print(book_childs)실행 결과는 다음에서 볼 수 있듯이 book_childs에 순서대로 도서명, 저자, 발행 연도 엘리먼트가 담겨 있다.

이제 아래의 코드로 각 항목들을 name, author, year 변수에 할당하고 text 속성으로 엘리먼트에 있는 텍스트를 출력하자.
name, author, year = book_childs
print(name.text)
print(author.text)
print(year.text)아래와 같이 결과가 잘 출력되었다.

그러나 XML은 자식 엘리먼트 순서가 항상 일정하다는 것을 보장하지 않는다. 이를 해결하기 위해서 findtext() 메서드를 사용하면 된다. 다음 코드와 같이 해당하는 자식 엘리먼트를 탐색하여 자동으로 텍스트를 변환할 수 있다.
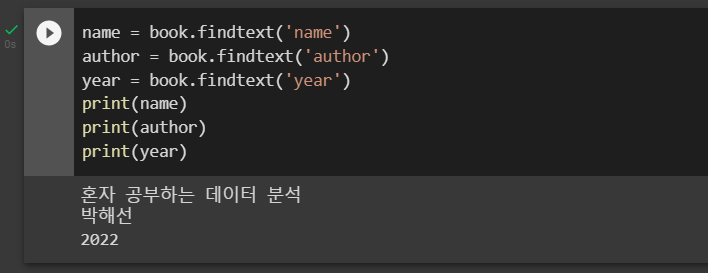
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)실행 결과는 다음과 같다.
여러 개의 자식 엘리먼트 확인하기: findall() 메서드와 for 문
아래 코드와 같은 조금 더 복잡한 XML 문서를 만들어 보자.
x2_str = """
<books>
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
<book>
<name>혼자 공부하는 머신러닝+딥러닝</name>
<author>박해선</author>
<year>2020</year>
</book>
</books>
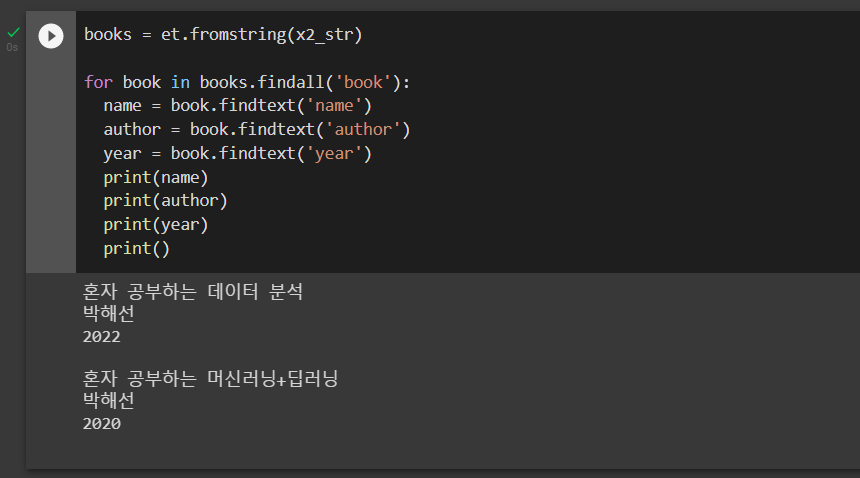
"""동일한 이름을 가진 여러 개의 자식 엘리먼트를 찾을 때는 findall() 메서드와 for 문을 함께 사용하면 편리하다. 다음 코드는 findall() 메서드가 반환하는 자식 엘리먼트 <book>에서 name, author, year를 찾아 출력한다.
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
print()실행 결과는 다음과 같다.
🤓 JSON처럼 XML을 바로 판다스로 바꾸는 방법?
판다스read_json()함수를 사용하면 JSON 문자열을 판다스 데이터프레임으로 변환할 수 있다. XML도 비슷하게read_xml()함수를 사용하면 XML을 데이터프레임으로 변환해 준다.
API로 20대가 가장 좋아하는 도서 찾기
만약 우리가 20대의 선호 도서를 예상 선호 도서 목록과 비교할 일이 생겼다고 해보자. 판매 데이터에는 구매자의 나이가 들어 있지 않은데 어떻게 해결할 수 있을까? 도서관 정보나루 사이트에서 나이별로 대출 데이터를 조회할 수 있다.
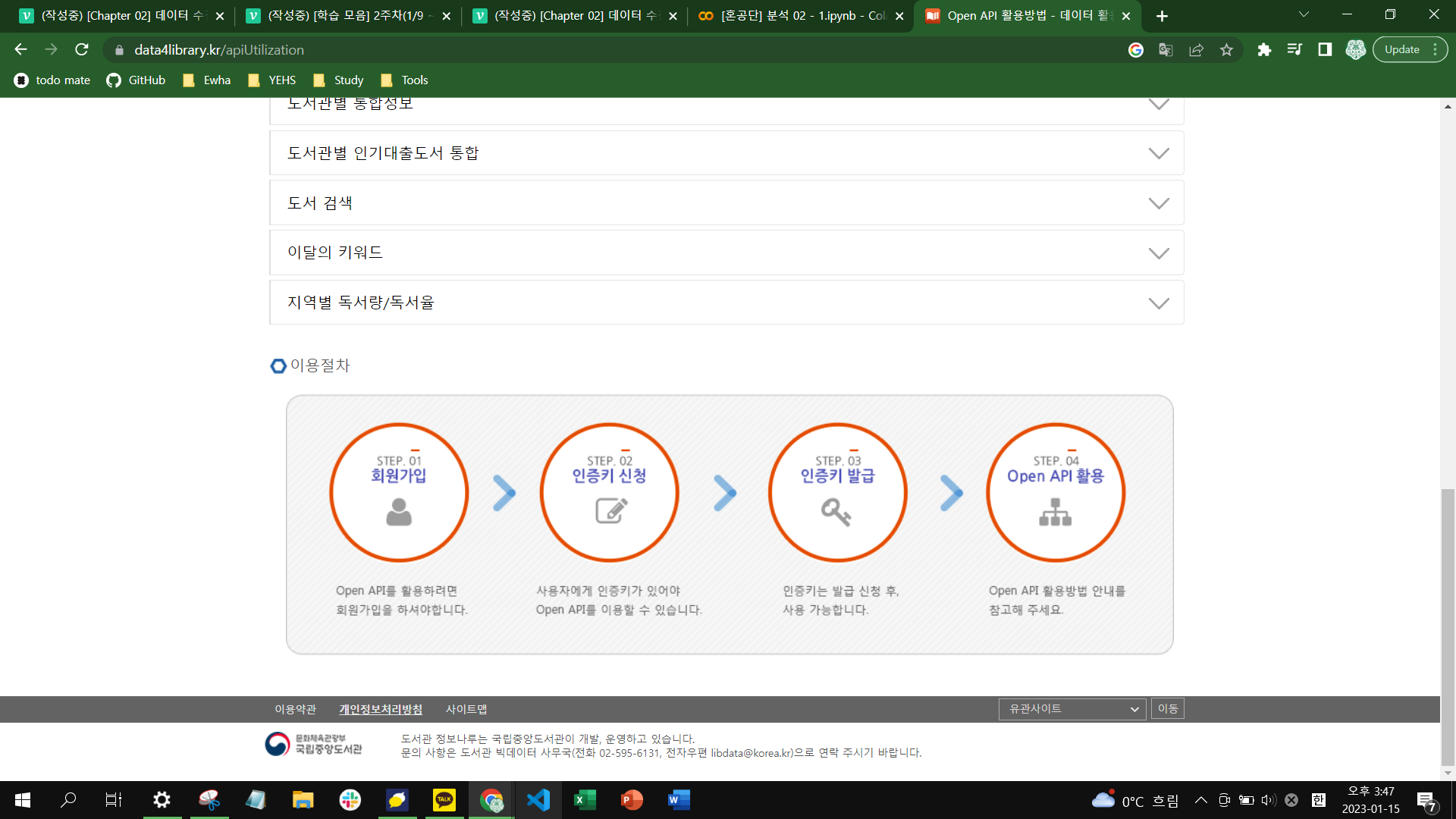
위의 화면과 같이 도서관 정보나루에 접속 후, 메인 페이지 메뉴에 [데이터 활용] 탭을 클랙한 후 메뉴 아래에 [Open API 활용방법] 탭을 클릭하자. 화면 하단 즈음에 [이용절차] 항목에 따라 회원가입 후 인증키를 발급받아 API를 사용할 수 있음을 알 수 있다. 우선, 버튼을 클릭하여 API 이용 신청을 하자.
다음, 페이지 상대에 있는 [API매뉴얼다운로드] 버튼을 클릭해서 해당 자료를 다운받자.

문서를 읽어보면 알 수 있듯이 해당 API는 연령별 데이터를 제공하고 있다. 즉, 활용에 적합한 데이터라는 것이다.
API를 호출하는 URL 작성하기
도서관 정보나루 공개 API를 사용하려면 호출 URL이 필요하다. API 매뉴얼을 보면 아래와 같이 URL 형식이 예시로 나와있다.

우리는 이 정보에서 호출 URL이 HTTP 프로토콜을 사용함을 알 수 있다. 데이터 조회에 필요한 것은 다음과 같다.
- 호출 URL: http://data4library.kr/api/loanItemSrch
- 파라미터
- format: 지정하지 않으면 XML 문서로 변환, 여기서는 json으로 지정하여 JSON 문서로 받음
- startDt: 검색 시작 일자
- endDt: 검색 종료 일자
- age: 연령대
- authKey: 인증키
파라미터 값은 = 문자로 연결하고 파라미터 사이는 &로 연결한다. 호출 URL과 파라미터는 ? 문자로 연결한다. 이러한 방식을 HTTP GET 방식이라고 한다.
🤓 HTTP GET 방식?
웹 브라우저가 웹 서버에 요청을 할 떄 URL로 파라미터 값이나 데이터를 전달하는 방식을 의미한다.?문자 뒤에 연결된 파라미터와 값들은 쿼리 스트링(query string)이라고 한다.
하지만 웹 브라우저와 웹 서버 모두 URL 길이에 제한을 두고 있기 때문에 무한정 길게 쓸 수 없기 때문에 이런 경우 HTTP POST 방식을 사용한다. 이 방식은 URL 뒤에 파라미터나 데이터를 붙이지 않는다. HTTP 프로토콜 안에 있는 별도의 공간에 데이터를 실어 보내기 때문에 길이 제약엇ㅂ이 보낼 수 있기 때문에 POST 방식은 URL만 봐서는 어떤 데이터를 전달했는지 알 수 없다는 차이가 있다.
API 인증키 발급하기
호출 URL을 사용하려면 API 인증키가 필요하다.
우선, 도서관 정보나루 사이트 오른쪽 상단에 있는 [마이페이지]를 클릭한다.
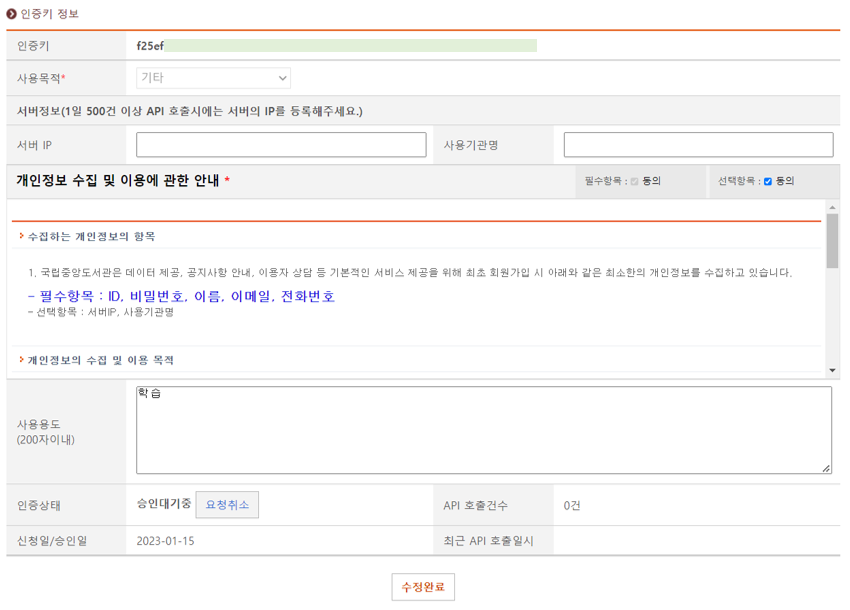
다음, 위의 화면에서 [개인정보 수집 및 이용에 관한 안내]의 [선택항목 : 동의]fmf cpzmgkrh, [사용목적]에서 '목적'을 선택한다. 그 다음 [인증키]의 [인증키발급] 버튼을 클릭하면 인증키 발급이 신청된다. 인증키 발급 신청 후 인증상태 항목이 '승인완료(사용중)'이 되어야 API가 활성화된다.
이후에 http://data4library.kr/api/loanItemSrch?format=json&startDt=2021-04-01&endDt=2021-04-30&age=20&authKey= 뒤에 위 사진에서 초록색으로 뒷쪽을 가린 인증키를 추가하면 호출 URL이 완성된다. 이 주소를 웹 브라우저 주소 표시줄에 넣고 접속하면 원하는 정보를 확인할 수 있게 된다.
파이썬으로 API 호출하기: requests 패키지
(인증키 승인 이후 내용 추가 예정)
정리
4가지 키워드로 정리하는 핵심 포인트
- API: 프로그램 간 데이터를 전달하기 위해 정한 규칙으로, 수동으로 데이터를 받는 방법은 매주, 매일 반복되는 작업에는 적절하지 않은으로 공개 API가 제공된다면 사용하여 데이터 수집 과정을 자동할 수 있음
- HTTP: 웹 페이지, 이미지 등을 받아 웹 브라우저에 나타내는 등 웹에서 데이터를 주고받기 위한 프로토콜로, 웹 브라우저로 접속하는 인터넷 URL 주소는 모두 http 혹은 보안이 강화된 https로 시작
- JSON: 근래에 아주 많이 사용하는 데이터 전달 포맷으로, 자바스크립트뿐만 아니라 웹 기반 API에서도 널리 대중화되어 있으며 HTML이나 XML보다 사람이 읽기 편하고 간단하게 파이썬 객체로 변환할 수 있다는 장점이 있음
- XML: 사람이 이해하기 쉬운 구조적인 포맷을 제공하며, 파이썬에서는 기본으로 제공되는 xml 패키지를 사용하여 XML 문서에 있는 엘리먼트를 탐색할 수 있고, 판다스의 경우
read_xml()함수를 사용하여 데이터프레임으로 바꿀 수 있음
표로 정리하는 핵심 함수와 메서드
| 함수/메서드 | 기능 |
|---|---|
| json.dumps() | 파이썬 객체를 JSON 문자열로 변환 |
| json.loads() | JSON 문자열을 파이썬 객체로 변환 |
| pandas.read_json() | JSON 문자열을 판다스 시리즈나 데이터프레임으로 변환 |
| xml.etree.ElementTree.fromstring() | XML 문자열을 분석하여 xml.etree.ElementTree.Element 클래스 객체를 반환 |
| xml.etree.ElementTree.Element.findtext() | 지저안 태그 이름과 맞는 첫 번째 자식 엘리먼트의 텍스트를 반환 |
| xml.etree.ElementTree.Element.findall() | 지정된 태그 이름과 맞는 모든 자식 엘리먼트를 반환 |
| requests.get() | HTTP GET 방식으로 URL을 호출하고 requests.Response 객체를 반환 |
| requests.Response.json() | 응답받은 JSON 문자열을 파이썬 객체로 변환하여 반환 |
