
리소스?
우리가 자주 사용하는 리소스라는건 무엇을 의미할까요?
프로세스가 동작하기 위해 사용되는 자원들 <= 이 친구 말고, 어플리케이션에서 특정 데이터들을 지칭하는 추상적인 개념으로써의 리소스를 생각해 보았습니다.
마이크로소프트에서 정의해준 리소스 정의를 읽어보면 비로소 정의를 내릴 수 있습니다. 리소스 엔티티 라고 부르고 있네요, 엔티티라는 단어와 함께 사용하니 더 의미가 와닿는 것 같습니다.
docs.microsoft/resource-entities
대부분의 개발자들에게 "정의로 부터 단어를 찾는 행위"는 일상입니다. 소위 네이밍 이라고 부르는 행위입니다.
저는 역으로 "단어로 부터 정의를 찾는 행위도 되게 유의미한 것 같습니다. 예를 들면 위에 올린 마이크로소프트의 글을 읽어보는것과 같이 말입니다!!
어떤 개발자가 고심해서 붙여준 이름의 의미를 자세히 분석하는 것은 제게 도메인을 이해하는데에 여러 도움을 주었습니다.
갑자기 리소스 이야기는 왜 한 것인가
Resource Entity 는 같은 종류의 엔티티들과 Group을 만들 수 있다. 그리고 group의 정의에 따라 순서가 존재할 수도있고, 순서가존재하지 않을 수 있다 - microsoft docs
어플리케이션의 데이터를 바라볼때, 다시말해 리소스 엔티티를 정의내릴 때, ordering 은 가장 먼저 생각해야 하는 요소 중에 하나입니다. 예를들면 피드를 최신순으로, 좋아요순으로 정렬하는 것은 데이터베이스 영역의 인덱스라는 녀석이 도움을 줍니다.
하지만 나만의 플레이리스트 목록을 만든다면? 트랙들은 내 입맛에 맞게 자유로이 순서가 바뀌어야합니다.
이러한 유저 인터렉션한 데이터들의 순서를 기술적으로 어떻게 구현해나갈지는 명백히 의사결정의 영역입니다. 어떠한 방법이 있을까요?
각 리소스들에게 1, 2, 3, 4, 5, 6 넘버링을 해주자

직관적인 방법입니다. 그 누구와 협업을 하더라도 단번에 예측할 수 있습니다. (예측 가능한 로직을 만든다는 것은 엄청난 장점입니다)
하지만 다음과같은 문제에 직면합니다.
사용자가 E를 A과 B사이의 순서로 바꾸고싶다면?

5와 1 사이에 있던 4개의 리소스를 수정해야합니다. 데이터가 천개라면? 유저가 화면을 드래그하는 손끝 한번에 데이터 1000개가 동시에 업데이트 되어야하는 조금은 무서운 어플리케이션이 되겠습니다.
또한 API 스펙을 정하는 것도 어려워집니다. 하나의 순서를 옮기고 싶은데 다른 데이터들도 수정해주어야합니다. 순서변경 API 를 이용하는 클라이언트 입장에서는 당황스러울것입니다. 백엔드를 담당하는 입장에서, 요구조건이 단순하기에 단순한 명세를 만들어주고 싶습니다.
요구조건을 정리하면 아래와 같습니다.
- 하나의 순서를 바꿀 때 하나의 리소스만 업데이트 하기
- 예측가능한 명세를 사용하기
를 만족하는 Lexorank 는 아주 유용한 모듈입니다.
LexoRank는 Jira에서 공개한 ordering rank 로직입니다 Jira/Lexorank
순서를 숫자가 아닌 문자열을 이용하여 표시해주는것입니다.
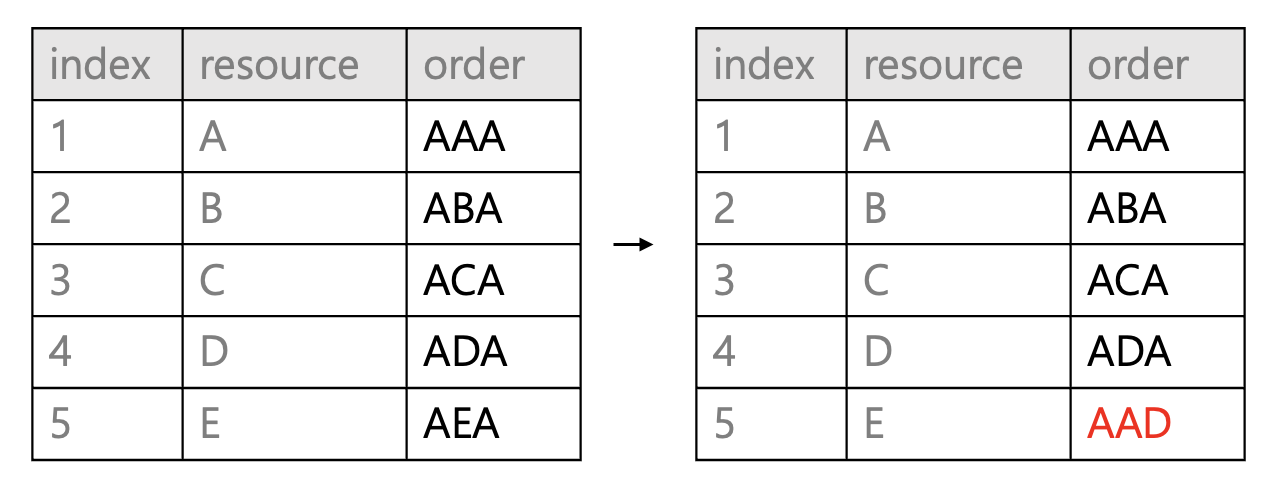
order 1과 2사이로 수정을 할때 1.5로 업데이트를 한다면 하나의 업데이트로 요구조건을 만족할 수 있는데 예측하기 어려운 값이 추가된다거나, 요청이 잦아지면 소수점이 길어지며 부동소수점 문제도 생길 수 있습니다만, 문자열은 그렇지 않습니다.
INT type의 1과 2 사이에는 간격이 없지만, AAA 와 AAB 사이에는 AAAA ~ AAAZ 까지 무한개입니다.
( AAAA 와 AAAB 사이에는 AAAAA ~ AAAAZ 가 있겠습니다 )
아무튼 LexoRank는 이러한 아이디어에 착안하여 다음과 같은 문자열을 사용합니다.
(예시) 0|bbc7ca, 0|zzzzz1, 0|1234hh, 0|000000
맨앞에 "0"은 버킷이라는 속성인데, 순서가 매우 많이 바뀌어 간격이 좁아졌을때 리밸런싱을 위한 용도로 사용됩니다. 이러한 방식으로 무궁무진한 문자열을 만들 수 있습니다.
극단적인 예시를 들어봅시다.
- 노래1 0|cccccca
- 노래2 0|ccccccb
... - 노래2038342029 0|zzxghz4
2038342029번째 노래를 노래1과 노래2 사이로 수정하고싶을때, 단지 그 데이터의 rank 를 0|ccccccab 로 업데이트 해주면 쉽게 이동이 가능합니다.
(이후 새로 리스트를 받을때는 데이터베이스의 인덱스의 도움을 받으면 되겠습니다.)
순서변경 API 에 이 lexorank 를 드러내도 좋습니다.
클라이언트 단에서도 리스트의 랭크들을 가지고 있으면,
PUT sounds/2038342029 -d { rank: 0|ccccccab }
위와같은 간단한 로직으로 완성이 됩니다. DB CPU 효율 뿐만 아니라, API 가 단순해지고 유연해지는것을 확인할 수 있습니다.
장점을 정리하면 다음과 같습니다.
- 하나의 데이터만 업데이트 해도 된다,
- 데이터가 예측가능한 형태이다.
- stateless 한 랭크를 이용할 수 있다. (간격이 좁아져도 쉽게 리밸런싱이 가능하기 때문)
자세한 사용법은 공식문서에서 상세히 설명해주고있습니다. 이러한 아이디어가 있구나 정도가 글에 잘 나타났으면 좋겠습니다!!
어떠한 기능을 Stateless 하고 Idempotent 한 기능들을 만드는건 가장 이상적인 형태인 것 같습니다.
물론 무조건 두 특성을 지켜야하는것은 아니지만, 유연성과 단순성은 모두가 지향하는 바가 아닐까 싶습니다.
