대규모 서버에서 사용하는 분산 아키텍쳐
분산처리의 목적은 다양하다. MSA와 같은 확장성 있고 클린한 형태의 설계를 위한 네트워크 분산형 서버를 위하는 경우도 있고, 빅데이터 기반의 데이터마이닝을 효과적으로 처리하기 위해 분산 설계를 이용하기도 한다.

Collection of Independent computers that appears users to its users as a single coherent system
여기서 핵심은 "독립된" 컴퓨터들의 집합을, "단일의" 컴퓨터처럼 이용한다는 개념이다.
컴퓨터들은 각각의 고유한 OS를 지닌다. (목적에 따라 다를것이다. 서버면 linux... 아니면 OOO 와 같은 미들웨어와 통합된 버전의 운영체제일 수도 있다.)
이러한 컴퓨터들을 단일한 컴퓨터처럼 이용하기 위해서, 각각의 자원을 어떻게 공유할지가 쟁점이다. (즉, 분산처리는 OS와 밀접하게 연관되어있다.) 자원에 접근하는 권한 도 중요할 것이다. (당연한 얘기지만 권한없이 접근하면 해킹이다.)
분산 아키텍쳐에서의 Coupling
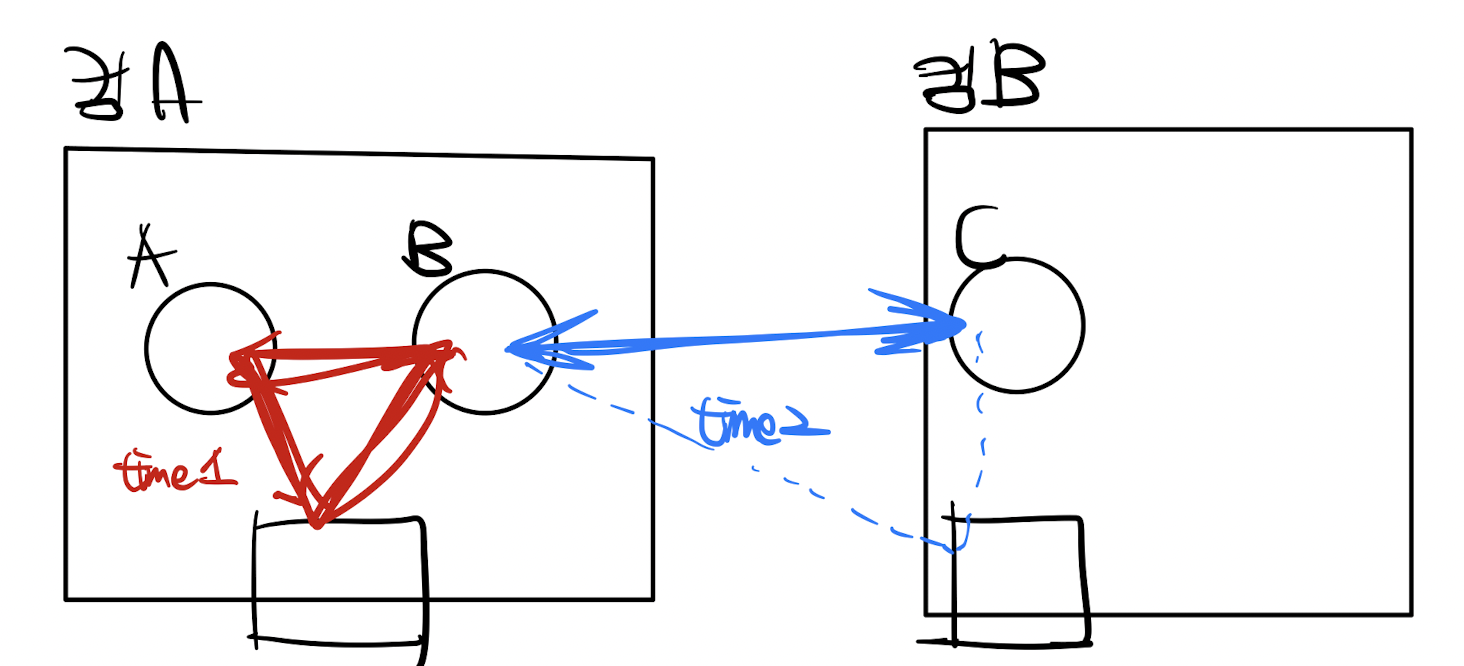
time 1 은 Single 컴퓨터 내에서 자원을 참조하는 시간이다. 아래 사각형은 스택영역, 혹은 JVM이다.
time 2 는 두 컴퓨터가 자원을 공유하는 시간이다. 자원공유 방식은 message push 방식일 수도 있고, 소켓 통신일수도 있고, 혹은 RMI와 같은 미들웨어가 처리해주는 가상 공유자원을 이용할 수도 있다.
이때 time 1 과 time 2 시간이 비슷할 수록 tightly coupling 관계라고 할 수 있다.
이러한 결합이 강하면 강할수록, 단일 컴퓨터 처럼 사용할 수 있다.
그리고 이 개념은 슈퍼컴퓨터의 원리이기도 하다.
내 단일 컴퓨터의 자원을 참조하는 시간과 분산처리된 다른 컴퓨터의 자원을 참조하는 시간이 비슷하다면 사실상 하나의 컴퓨터처럼 쓰고있다고 간주할 수 있겠다. 이 것은 슈퍼 컴퓨터의 원리를 단적으로 보여준다.
