
프로젝트를 개발하던 중 사용자가 데이터를 삭제할 때 어떻게 처리할까 고민이 되었다.
예를 들어 사용자가 회원 탈퇴를 하면 DB에 저장된 사용자와 연관된 레코드는 전부 삭제를 해줘야 되고 뿐만 아니라 S3에 올라간 이미지들도 전부 삭제를 해줘야 돼서
이런 모든 작업이 끝나고 응답받기까지 사용자는 상당히 많은 시간을 기다려야 하는 것이 문제였다.
삭제되었다고 마킹하기
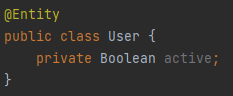
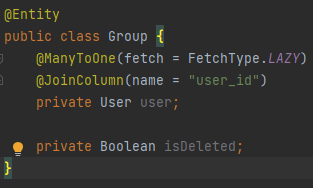
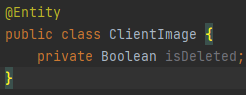
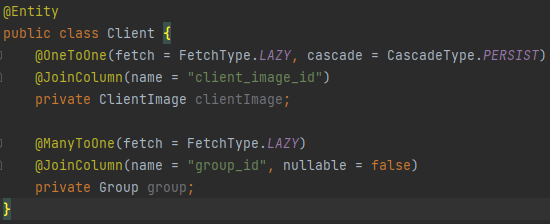
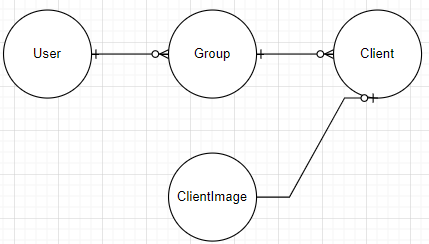
삭제를 관리해야 될 테이블은 User, Group, Client, ClientImage 총 4개이다.
erd로 나타내면 아래와 같다.
 삭제했다는 것을 마킹하기 위해서 아래와 같이 테이블에 필드를 추가하였다.
삭제했다는 것을 마킹하기 위해서 아래와 같이 테이블에 필드를 추가하였다.
- User 테이블에서 회원 탈퇴를 판별하는 active 필드
- Group를 삭제했다는 isDeleted 필드
- CLientImage를 삭제했다는 isDeleted 필드
이렇게 사용자가 삭제 요청을 할 경우 추가된 필드를 1로 update시키고 정해진 시간에
한꺼번에 모아서 삭제한다면 사용자는 삭제 응답을 빨리 받을 수 있을 수 있을 거라고 생각했다.
문제는 삭제된 것을 언제 어떻게 한꺼번에 처리할 것인가?
삭제 로직과 스케줄링이 필요했다!
삭제 로직
스케줄링을 알아보기 전 한꺼번에 삭제를 어떻게 처리할건지 고민을 많이 했었다.
현재 프로젝트 흐름을 보면 회원탈퇴를 할 때 사용자와 연관된 모든 테이블의 isDeleted 필드를 1로 update하는 것이 아닌 User 테이블의 active만 0으로 update해서 응답하고
사용자가 Group을 삭제할 때는 Group에 속한 ClientImage들은 제외하고 Group의 isDeleted필드만 1로 update해서 응답해주고 있었다.
왜 이렇게 했냐면 삭제된 테이블과 연관된 테이블들을 update해주면 간단하고 삭제 작업을 한꺼번에 처리하기 수월하겠지만 사용자에게 빠른 시간에 응답해주고 싶어 연관된 테이블은 update하지 않았다.
아래 코드는 전체적인 삭제 로직으로 회원 탈퇴 기준으로 설명하겠다.
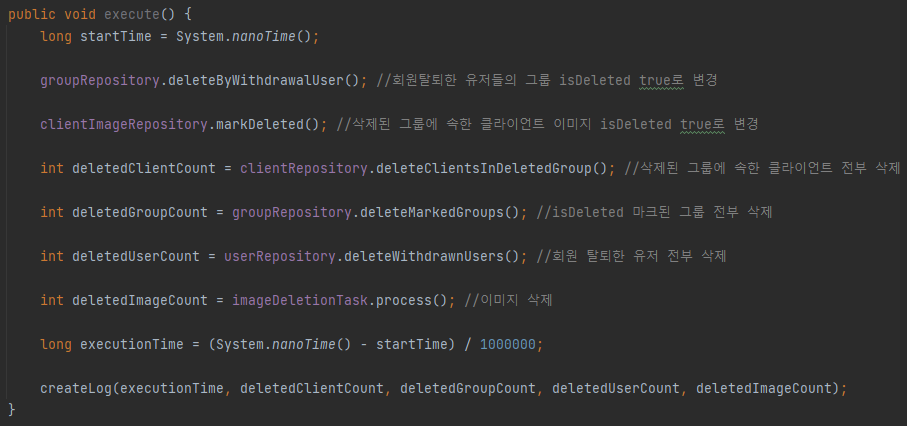 주석으로 써져있지만 단계별로 설명하자면
주석으로 써져있지만 단계별로 설명하자면
- 회원 탈퇴한 유저들이 가진 Group 테이블의 isDeleted 필드를 1로 변경한다.
- isDeleted 필드가 1인 Group 테이블과 연관된 ClientImage 테이블의 레코드 isDeleted 필드를 1로 변경한다.
- isDeleted 필드가 1인 Group 테이블과 관련된 Client 테이블의 레코드를 전부 삭제한다.
- isDeleted 필드가 1인 Group 테이블 레코드도 전부 삭제한다.
- 회원 탈퇴한 active 필드가 0인 User 테이블 레코드도 전부 삭제한다.
- isDeleted 필드가 1인 ClientImage 테이블의 이미지 경로를 조회해서 S3에 이미지를 삭제하고 ClientImage 테이블의 레코드도 삭제한다.
총 6단계로 회원 탈퇴, Group삭제, Client삭제, ClientImage삭제, S3에서 이미지삭제 모두 처리할 수 있게 된다.
다음으로 마지막 단계에 해당하는 이미지 삭제 로직을 알아보자.
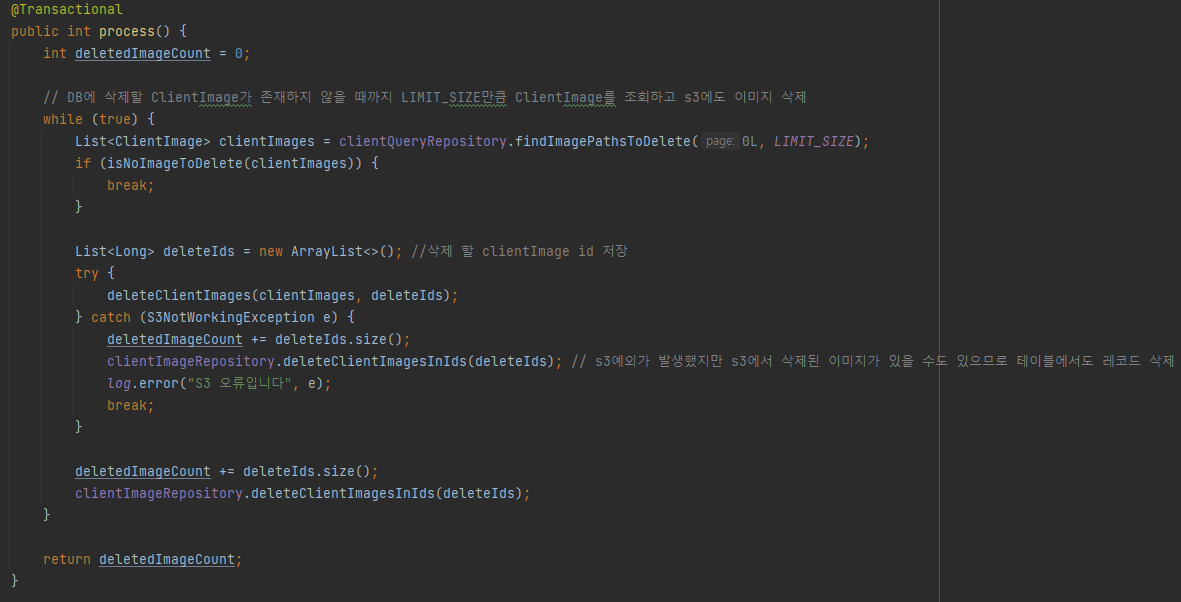 S3에 저장된 이미지를 삭제하려면 ClientImage테이블에서 이미지 경로를 조회해야 된다.
S3에 저장된 이미지를 삭제하려면 ClientImage테이블에서 이미지 경로를 조회해야 된다.
- 삭제할 ClientImage 레코드의 수가 엄청 많다면 조회할 때 OutOfMemoryError가 발생할 수 있으므로 1000개씩 조회한다.
- 해당하는 이미지 경로를 가지고 S3에서 이미지 파일을 삭제한다.
- S3에서 이미지를 무사히 삭제했다면 ClientImage의 id값을 List에 저장한다.
- 만약 S3에서 예외가 발생했다면 S3에 성공적으로 삭제된 이미지에 해당하는 ClientImage들만 DB에서 삭제한다. (S3에 삭제한 id값을 저장했기 때문에 가능하다.)
- 조회한 ClientImage들을 S3에서 모두 삭제했다면 ClientImage들을 DB에서 삭제한다.
- 삭제할 ClientImage가 더 존재한다면 1번으로 돌아가 반복해서 실행한다.
더이상 존재하지 않는다면 종료
간략하게 총 4단계로 처리할 수 있다.
이제 이 삭제 로직을 원하는 시간에 자동으로 실행할 수 있도록 해보자.
스케줄링
일정한 시간간격 또는 일정한 시각에 특정 로직을 돌리기 위해서
Spring Scheduler와 Quartz라는 2가지 방식을 많이 사용하는 것 같다.
Quartz는 장애 복구, 분산 스케줄링 등 정교한 스케줄링 작업할 때 유용한 것 같고
Spring Scheduler는 Spring Framework에 내장되어 있고 간단하게 @Scheduled 어노테이션을 사용하여 스케줄링이 가능한 것을 알게 되었다.
그래서 프로젝트가 큰 규모도 아니기도 하고 쉽고 빠르게 작업이 가능한 Spring Scheduler를 도입하기로 했다.
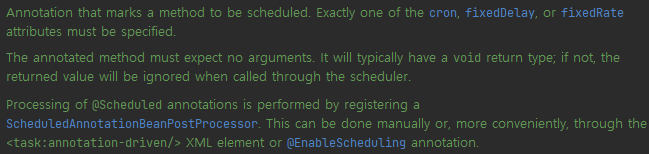 @Scheduled 어노테이션 설명을 보면 이것을 사용하기 위해선 @EnableScheduling 어노테이션을 등록하고 @Scheduled에 cron, fixedDelay 또는 fixedRate 특성 중 하나를 정확히 지정해야 한다고 한다. 그리고 void 반환 형식을 사용해야 되는데 그렇지 않으면 반환된 값은 스케줄러를 통해 호출될 때 무시되니깐 주의하자!
@Scheduled 어노테이션 설명을 보면 이것을 사용하기 위해선 @EnableScheduling 어노테이션을 등록하고 @Scheduled에 cron, fixedDelay 또는 fixedRate 특성 중 하나를 정확히 지정해야 한다고 한다. 그리고 void 반환 형식을 사용해야 되는데 그렇지 않으면 반환된 값은 스케줄러를 통해 호출될 때 무시되니깐 주의하자!
- cron: 정한 시간대에 주기적으로 실행 (알람 시계를 생각하면 된다.)
- fixedDelay: 마지막 호출이 종료될 때부터 다음 호출이 시작될 때까지 기간을 정해서 실행
- fixedRate: 호출 사이에 일정 기간을 두고 실행
내가 필요한 것은 사용자가 많이 사용하지 않은 시간대에 주기적으로 실행하는 것이므로 cron을 선택했다.
이제 실행시킬 메소드 위에 @Scheduled 어노테이션을 붙이면 스케줄링이 가능하다.
cron 표현식
 한국 시간으로 매일 3시에 실행시키고 싶으면
한국 시간으로 매일 3시에 실행시키고 싶으면
@Scheduled(cron = "0 0 3 * * *", zone = "Asia/Seoul")으로 설정하면 되는데 zone의 default는 서버 시간대라고 한다.
더 많은 내용을 알고 싶으면 아래 사이트를 참고하자.
https://docs.spring.io/spring-framework/docs/5.3.x/reference/html/integration.html#scheduling-cron-expression
@Scheduled 동작 원리
코드 분석은 아래 블로그에서 쉽게 설명되어 있어서 참고하면 된다.
내가 궁금한 것은 @Scheduled가 어떻게 정해진 시간에 작업을 실행하는지 알고 싶었다.
하지만 구글링 해도 잘 안 나오고 공식 문서를 봐도 사용법에 대한 내용뿐이라서 직접 내부 코드를 분석하려고 했지만 이해가 잘되지 않았다.
그래서 stackoverflow에서 찾던 도중 좋은 키워드를 찾게 되었다.
저 글에서 Condition.awaitNanos()가 시간 지연을 담당한다고 한다.
실제로 디버깅을 해보면 저 코드에서 시간 지연이 발생한다.
awaitNanos()에 구현된 코드를 보면 LockSupport.parkNanos()를 호출하고 있는데
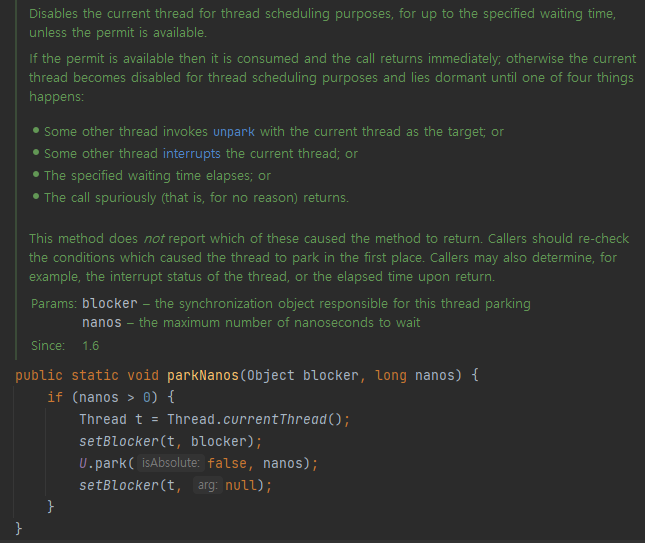 메소드에 대한 설명을 보면 현재 스레드를 대기 상태로 만들어 스레드 스케줄링을 조절하며, 특정 시간 동안 대기 한다.
메소드에 대한 설명을 보면 현재 스레드를 대기 상태로 만들어 스레드 스케줄링을 조절하며, 특정 시간 동안 대기 한다.
이때 4가지 상황 중 하나가 발생할 때까지 대기한다.
- 다른 스레드가 현재 스레드를 대상으로 unpark 메소드를 호출할 경우
- 다른 스레드가 현재 스레드를 인터럽트하는 경우
- 지정된 대기 시간이 경과하는 경우
- 호출이 무작위로 반환되는 경우
내가 궁금한 건 3번 지정된 대기 시간이 경과하는 경우이다.
위의 코드에서 가장 핵심은 U.park(false, nanos) 인데 저게 지정한 시간 동안 지연시켜준다.
즉, 알람 역할을 해준다고 생각하면 이해하기 쉽다.
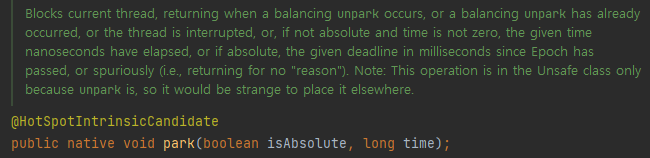 Unsafe클래스에 있는 park()메소드에 대한 설명이다.
Unsafe클래스에 있는 park()메소드에 대한 설명이다.
Unsafe 클래스는 자바에서 낮은 수준의 메모리 조작 및 스레드 동기화 기능을 제공한다.
메모리를 조작하다 보니 park()메소드가 native로 되어있다.
설명을 보면 스레드를 대기 상태로 만들어 주어진 나노초 시간만큼 대기한다고만 나와있어서
시간 지연은 컴퓨터 내부적으로 해결하고 있구나라고 생각하게 되었다.
그렇다면 컴퓨터 내부적으로 어떻게 동작할까?
Timer (뇌피셜 주의)
시스템 구조도를 보고 여러 글을 봤지만 명확한 해답이 없어서 정리한 내 생각이니 틀릴 수도 있다.
틀렸다면 따끔하고 날카로운 지적 부탁드립니다.
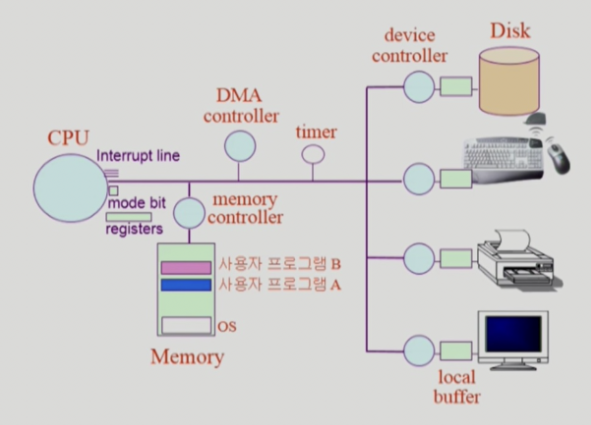 시스템 구조도를 보면 timer가 있다는 것을 볼 수 있다.
시스템 구조도를 보면 timer가 있다는 것을 볼 수 있다.
컴퓨터 안에는 timer라는 하드웨어가 존재하는데 일정 시간 단위를 측정하고 그 단위 마다 timer가 CPU에게 timer interrupt를 보내서 다른 작업을 수행하거나 스케줄링하는데 사용한다.
timer가 알람 역할을 해줄 거라는 생각은
위 포스팅을 보고 짐작하게 되었다.
그래서
Unsafe.park()메소드를 호출하면 아래와 같은 단계로 실행될 것이라고 생각된다.
1. 현재 스레드가 시간 지연 요청 (인터럽트 발생)
2. CPU 제어권이 커널로 넘어감
3. 커널이 인터럽트가 발생한 스레드를 대기 상태로 변경
4. 커널이 타이머에게 지정한 시간이 지나면 타이머 인터럽트를 발생시켜달라고 요청
5. 지정한 시간이 지나면 타이머 인터럽트가 발생
6. 다시 CPU 제어권이 커널로 넘어가고 대기 상태인 스레드를 실행 상태로 변경
7. CPU 제어권이 대기했던 스레드로 넘어가서 작업 수행스레드가 대기 상태로 요청할 때 컨텍스트 스위칭이 발생해서 조금 오버헤드가 있지만
시간 지연은 CPU가 아닌 타이머가 해주기 때문에 더 효율적이다.
만약 타이머가 없었다면 시간 지연하려고 컨텍스트 스위칭이 자주 일어났을 것이다.
문제점
@Scheduled 를 매일 정각으로 설정했다면 타이머에게 현재 시간에서 지정한 시간 차이만큼 한 번만 요청할 거라고 생각했지만 그게 아닌 것 같았다.
예를 들어 12시에 스케줄링 해놓고 현재 시간이 6시라면 타이머에게 딱 한 번 6시간 동안 지연 요청하는 것이 아닌 지연 시간을 잘게 여러 번 나눠서 스케줄링을 하는 것을 확인하였다.
왜 저렇게 생각했냐면
디버깅을 하다가 다음 스케줄링 작업까지 6시간이 남았는데 4~50초 간격으로 나눠서 지속적으로 시간 지연 요청을 하는 것을 알게 되었다.
왜 이렇게 하는지 정확한 이유는 잘 모르겠다. (nano 단위라서 지연 시간을 크게 요청하면 timer의 측정 최댓값을 넘을 수도 있어서 그런가?)
이렇게 잘게 나눠서 시간 지연 요청을 하면 사용자가 자주 사용하는 시간대에 컨텍스트 스위칭이 자주 발생해 오버헤드가 좀 클 것 같았다.
해결 방법은 이런 오버헤드까지 생각한다면 스케줄링 서버를 따로 두는 방법밖에 없는 것 같다.
참고
https://sabarada.tistory.com/113
https://docs.spring.io/spring-framework/docs/5.3.x/reference/html/integration.html#scheduling
https://docs.spring.io/spring-framework/reference/integration/scheduling.html
https://bbangya16.tistory.com/137
http://www.kocw.net/home/cview.do?cid=3646706b4347ef09
