
 가자맵에서는 앱 실행마다 서버로 요청을 보내서 로그인이 된 회원인지 확인 후 사용자가 최근에 참조한 그룹과 클라이언트를 조회 후 응답해서 지도에 보여주고 있다.
가자맵에서는 앱 실행마다 서버로 요청을 보내서 로그인이 된 회원인지 확인 후 사용자가 최근에 참조한 그룹과 클라이언트를 조회 후 응답해서 지도에 보여주고 있다.
이 부분의 속도 향상을 위해 작업한 내용을 기록하려고 한다.
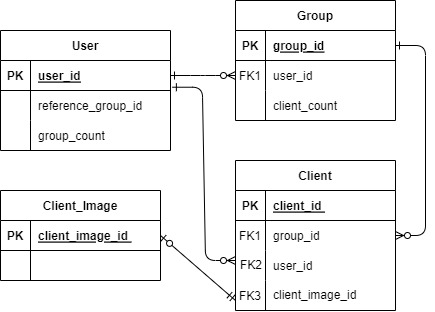 속도를 개선할 DB 스키마이다.
속도를 개선할 DB 스키마이다.
user는 권한에 따라 다르지만 여러 개의 group을 생성할 수 있고 group안에 여러 개의 client를 생성할 수 있다. 그리고 최근에 어떤 group을 참조했는지 user 컬럼에 reference_group_id(최근에 참조한 그룹 아이디)가 있다.
1. 사용자를 조회한다.
2. 사용자의 최근 접속 날짜를 변경한다. (비동기 이벤트)
3. 사용자의 reference_group_id를 가져와서 최근 참조 그룹을 조회한다.
3-1. reference_group_id 이 null이라면 그룹을 조회하지 않는다.
3-2. reference_group_id 이 null이 아니라면 특정 그룹을 조회한다.
4. 최근 참조 그룹에 속한 클라이언트를 조회한다.
4-1. reference_group_id 이 null이라면 클라이언트 전체 LIMIT(최대 1000)를 조회한다.
4-2. reference_group_id 이 null이 아니라면 특정 그룹에 속한 클라이언트를 조회한다.사용자가 앱을 실행할 때마다 크게 4단계로 위 로직으로 실행된다.
위 흐름대로 쿼리를 1차 수정하였고 수정된 로직의 성능을 측정해 보자.
1차 수정 성능 측정
로컬 서버로 측정하였고 HikariPool Connection 수는 50개로 설정하였다.
PostgresSQL DB에 저장된 레코드는 다음과 같다.
- User: 100명
- Group: 1000개
- Client: 1_000_000개
- Client_Image: 1_000_000개
- 각 User 는 10개의 Group을 가지고 있고 각 Group은 1000개의 Client씩 가지고 있다.
그리고 각 Client는 Client_Image 를 하나씩 가지고 있다.
JMeter 도구를 사용해서 사용자가 최근에 참조한 그룹이 전체일 때와 특정 그룹일 때를 나눠서 성능을 측정해보자.
- Number of Threads: 100명
- Ramp-Up Period: 10초
- Loop Count: 무한 반복
으로 진행한 결과는 다음과 같다.
- 전체 그룹: 14015ms
- 특정 그룹: 14358ms
평균 14초가 걸리고 있었다. 말도 안 되게 느린 속도였다.
그렇다면 사용자가 최근에 참조한 그룹이 전체 그룹일 때와 특정 그룹일 때를 개선해 보자.
전체 그룹
전체 그룹일 때 조회하는 쿼리는 다음과 같다.
SELECT * FROM client c
JOIN group_set g ON c.group_id = g.group_id
LEFT JOIN client_image ci ON c.client_image_id = ci.client_image_id
WHERE c.user_id = 30 AND g.user_id = 30
ORDER BY c.client_id DESC
LIMIT 1000;EXPLAIN ANALYZE 로 쿼리를 분석해보자.
Nested Loop Left Join (cost=23.05..20927.43 rows=45 width=194) (actual time=102.717..193.627 rows=3333 loops=3)
-> Hash Join (cost=22.63..20627.78 rows=45 width=155) (actual time=102.701..166.185 rows=3333 loops=3)
Hash Cond: (c.group_id = g.group_id)
-> Parallel Seq Scan on client c (cost=0.00..20593.33 rows=4486 width=113) (actual time=102.554..162.353 rows=3333 loops=3)
Filter: (user_id = 50)
Rows Removed by Filter: 330000
-> Hash (cost=22.50..22.50 rows=10 width=42) (actual time=0.427..0.429 rows=10 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on group_set g (cost=0.00..22.50 rows=10 width=42) (actual time=0.214..0.414 rows=10 loops=1)
Filter: (user_id = 50)
Rows Removed by Filter: 990
-> Index Scan using client_image_pkey on client_image ci (cost=0.42..6.66 rows=1 width=39) (actual time=0.006..0.006 rows=1 loops=10000)
Index Cond: (client_image_id = c.client_image_id)
Planning Time: 1.006 ms
Execution Time: 380.795 msLIMIT과 ORDER BY 도 포함시키면 내용이 굉장히 길기 때문에 그것은 임의로 제외한 실행 계획이고 시간이 380ms 걸리는 것을 알 수 있다.
그렇다면 어떤 식으로 동작하고 있는 것일까?
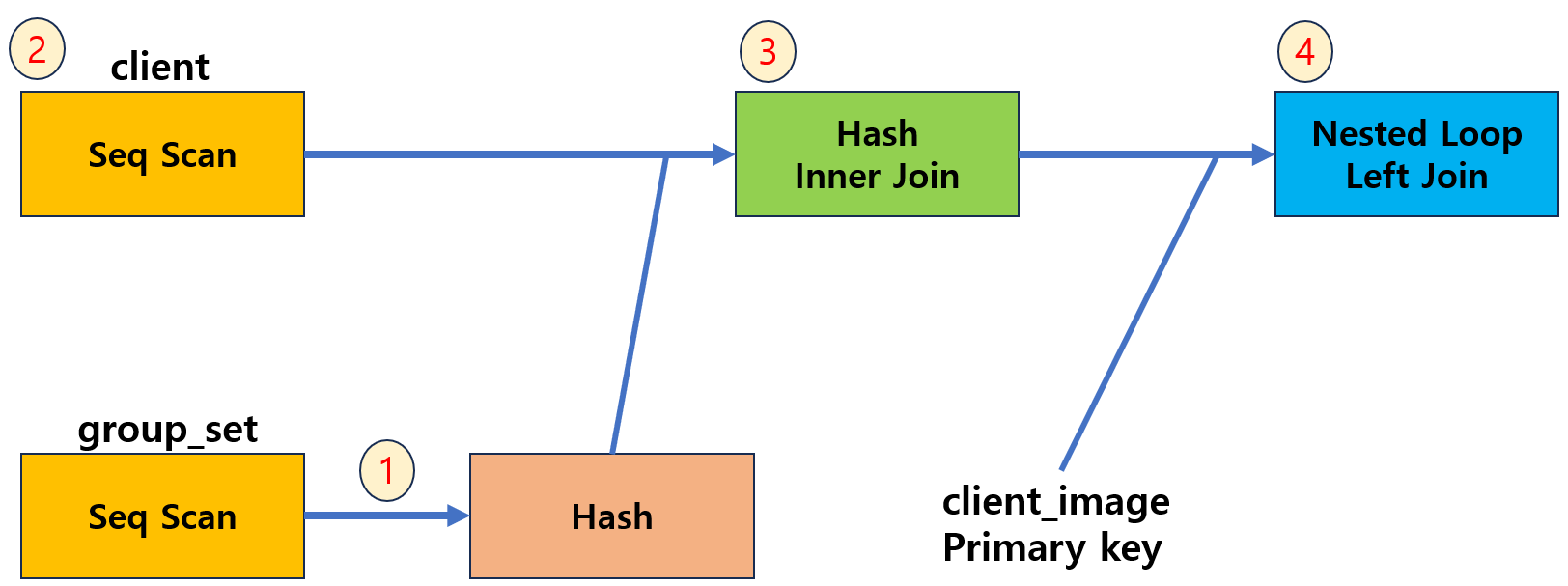
1. group_set을 Seq Scan하는데 결과가 Hash로 들어간다. (1000개 중 990개는 필터링 되었다.)
2. client를 Seq Scan한다. (100만개 중 33만 개가 필터링 되었다.)
3. 1, 2 번 결과를 Hash Inner Join 한다.
4. 3번에 나온 결과를 구동 테이블로 두고 client_image를 Index Scan해서 Left Join 한다.
2번 결과에서 user는 client를 총 10000개를 가지고 있고 Seq Scan인데 99만개가 필터링 되는 것이 아닌 왜 33만 개만 필터링 되는지 의문이다.. 나중에 더 알아봐야 겠다.
WHERE c.user_id = 50 AND g.user_id = 50
위 조건절에서 Seq Scan 타는 것이 속도의 원인인 것 같다.
당연히 외래키로 했으면 인덱스가 생성되는 줄 알았지만 PostgresSQL은 아니었다.
MySQL InnoDB에서는 외래키를 자동으로 인덱스를 생성하지만 PostgresSQL은 그렇지 않다고 한다.
그래서 직접 client 테이블에 user_id를 인덱스 걸고, group_set 테이블에도 user_id를 인덱스를 걸어서 시간을 측정해보자.
결과
그 결과 Seq Scan부분이 Index Scan으로 변경되면서 대략 42ms 속도가 나왔다. (380ms -> 42ms 로 속도가 개선되었다.)
JMeter로 측정한 결과는 약 2.4초이다.
특정 그룹
SELECT * FROM client c
JOIN group_set g ON c.group_id=g.group_id
LEFT JOIN client_image ci ON c.client_image_id = ci.client_image_id
WHERE c.group_id = 500 AND g.group_id = 500
ORDER BY c.client_id DESCEXPLAIN ANALYZE 로 쿼리를 분석해보자.
Nested Loop (cost=25006.86..25143.08 rows=994 width=194) (actual time=287.309..314.876 rows=1000 loops=1)
-> Gather Merge (cost=25006.59..25143.08 rows=994 width=152) (actual time=287.250..313.126 rows=1000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Nested Loop Left Join (cost=0.42..23988.57 rows=414 width=152) (actual time=83.154..157.490 rows=333 loops=3)
-> Parallel Seq Scan on client c (cost=0.00..20593.33 rows=414 width=113) (actual time=83.813..155.524 rows=333 loops=3)
Filter: (group_id = 500)
Rows Removed by Filter: 333000
-> Index Scan using client_image_pkey on client_image ci (cost=0.42..8.20 rows=1 width=39) (actual time=0.005..0.005 rows=1 loops=1000)
Index Cond: (client_image_id = c.client_image_id)
-> Materialize (cost=0.28..8.30 rows=1 width=42) (actual time=0.000..0.000 rows=1 loops=1000)
-> Index Scan using group_set_pkey on group_set g (cost=0.28..8.29 rows=1 width=42) (actual time=0.039..0.040 rows=1 loops=1)
Index Cond: (group_id = 500)
Planning Time: 0.652 ms
Execution Time: 315.445 msORDER BY는 임의로 제외한 실행 계획이고 시간이 315ms 걸린 것을 알 수 있다.
동작 과정을 쉽게 알아보자.
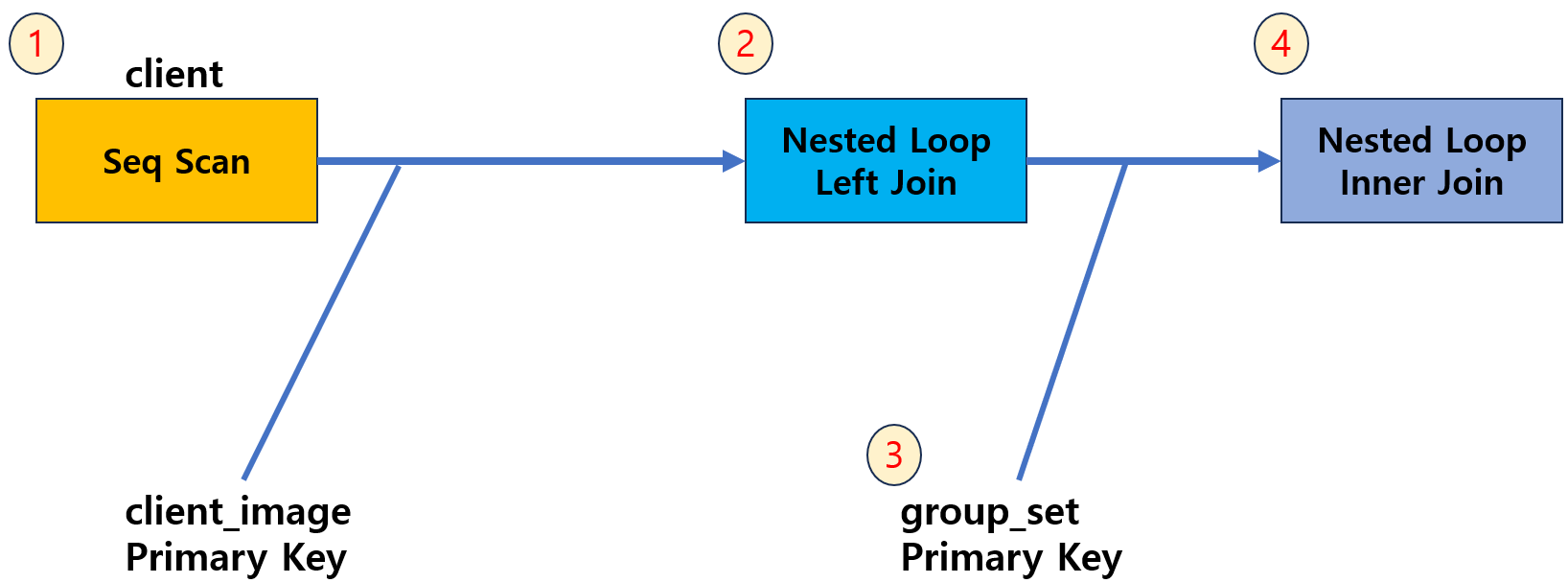
1. client를 Seq Scan 한다.
2. 1번에 나온 결과를 구동 테이블로 두고 client_image를 Index Scan해서 Left Join 한다.
3. group_set을 Index Scan 한다.
4. 2번과 3번에 나온 결과를 Nested Loop Inner Join 한다.
client 테이블에 group_id를 인덱스 걸고 시간을 측정해보자.
결과
대략 5ms 속도가 나왔다.(315ms -> 5ms)
JMeter로 측정한 결과는 약 0.9초이다.
그런데 WHERE c.group_id = 500 AND g.group_id = 500 에서 양쪽 다 조건을 걸어 줄 필요 없이 한 쪽만 걸어도 옵티마이저가 실행 속도가 빠른 쪽으로 고려해서 둘 다 Index Scan을 할 때도 있다는 것을 알게 되었다. 왜냐하면 레코드 수가 적을 때 Index Scan보다 Seq Scan이 빠른 이유는 인덱스 트리에서 루트 노드부터 리프 노드까지 탐색할 때 여러 번의 랜덤I/O로 오버헤드가 발생할 수 있지만 Seq Scan로 할 경우 순차I/O로 진행하기 때문에 레코드 수가 적을 경우 속도가 더 빠를 수 있다.
지금은 group_set 테이블 레코드의 수가 1000개밖에 안돼서 Seq Scan으로 하고 있지만 레코드 수가 많아지면 Index Scan으로 할 것이다. 그래서 WHERE c.group_id = 500 로 변경하였다.
ORDER BY 정렬 성능 문제
전체 그룹과 특정 그룹의 조회 쿼리 속도가 45ms, 5ms로 큰 차이가 난다.
그 이유는 ORDER BY c.client_id DESC에 있는데 최종 결과를 정렬하기 때문에 레코드 수에 따라 속도가 달라진다.
위 예시 같은 경우 전체 그룹은 10000개의 데이터를 heap sort를 진행하고, 특정 그룹은 1000개의 데이터를 quick sort를 진행한다. 따라서 레코드의 수가 많아질수록 성능은 저하될 것이다.
그래서 sort를 하지 않도록 인덱스를 잘 설정해야 한다.
복합 인덱스
문제가 되는 ORDER BY c.client_id DESC 를
Index Scan 과정에서 client_id를 정렬된 상태로 가져온다면 해결될 것이라고 판단하였다.
그래서 WHERE 조건에 있는 c.user_id와 c.group_id를 기준으로 각각 client_id를 복합 인덱스로 묶어주기로 하였다.
- Client 테이블의 user_id, group_id 단일 인덱스
- Group 테이블의 user_id 단일 인덱스
위 처럼 테이블에 걸린 단일 인덱스를 아래와 같이 복합 인덱스로 생성하였다.
- CREATE INDEX client_group ON client(group_id, client_id)
- CREATE INDEX client_user ON client(user_id, client_id)
결과를 EXPLAIN ANALYZE를 해서 가장 핵심적인 부분을 보자.
전체 그룹
Index Scan Backward using_client_group on client c
Index Cond: (user_id = 50)전체 그룹은 WHERE c.user_id = 50 가 있는데 예상한대로 역순으로 Index Scan을 진행하여 client_id를 내림차순으로 가져왔고 sort 과정은 사라졌다.
특정 그룹
Index Scan Backward using client_user on client c
Index Cond: (group_id = 500) 특정 그룹은 WHERE c.group_id = 500 가 있는데 이것도 역순으로 Index Scan하여 client_id를 내림차순으로 가져온 것을 볼 수 있다. 마찬가지로 sort 과정은 사라졌다.
최종
개선한 쿼리를 최종적으로 이전과 이후를 분석한 표이다.
참조
https://seunghyunson.tistory.com/20
https://yurimkoo.github.io/db/2020/03/14/db-index.html
https://pganalyze.com/docs/explain
https://stackoverflow.com/questions/38846199/in-a-postgresql-query-plan-what-is-the-difference-between-materialize-and-hash?rq=3
https://www.postgresql.org/docs/9.4/indexes-ordering.html
https://burning-dba.tistory.com/79
