서론
Q. age = 20인 행을 찾을려면?
| first_name | age |
|---|---|
| 김씨 | 15 |
| 이씨 | 30 |
| 박씨 | 25 |
| 김씨 | 20 |
| 이씨 | 10 |
관계형 데이터베이스에서는 age가 20인 행을 찾으려면 모든 행을 다 탐색한다. 만약 데이터가 1억개라면 age가 20인 것을 찾기위해 1억개를 다 찾아볼 것이며 속도가 현저히 느려질 것이다.
Index
만약 데이터가 정렬되지 않았다면 age가 20인 것을 찾기 어렵지만, 데이터가 정렬되었다면 age가 15보다 크고 25보다 작다는 것을 통해 행을 반이상씩 잘라가며 빠르게 찾기가 가능하다.
따라서 정렬해야지 절반씩 소거하며 찾기가 가능하다. 밑의 형태로 말이다.
Index(정렬해놓은 컬럼 사본)
| age |
|---|
| 10 |
| 15 |
| 20 |
| 25 |
| 30 |
구현 방법
Index를 만들고 싶다면 컬럼에 데이터베이스 자료들을 복사하여 정렬해두면 된다.
ex) Array, Linked List
Index는 보통 Tree를 이용하여 데이터를 배치하고 정렬한다.
Binary Search Tree
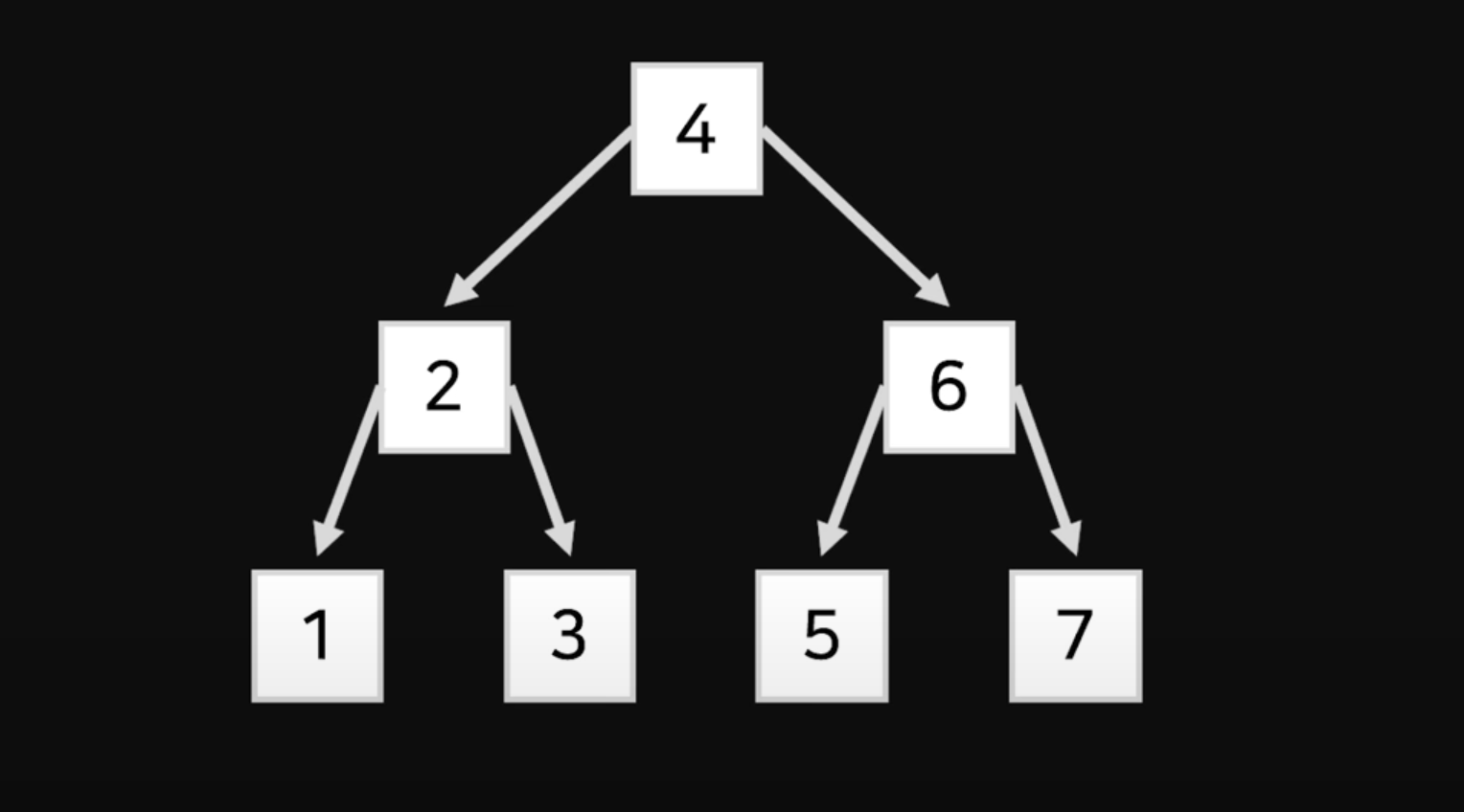
5가 어디 저장되어있는지 찾으려면 Q가 4보다 큰지 Q가 6보다 작은지 단 두번만에 5를 찾을 수 있다.
B-tree
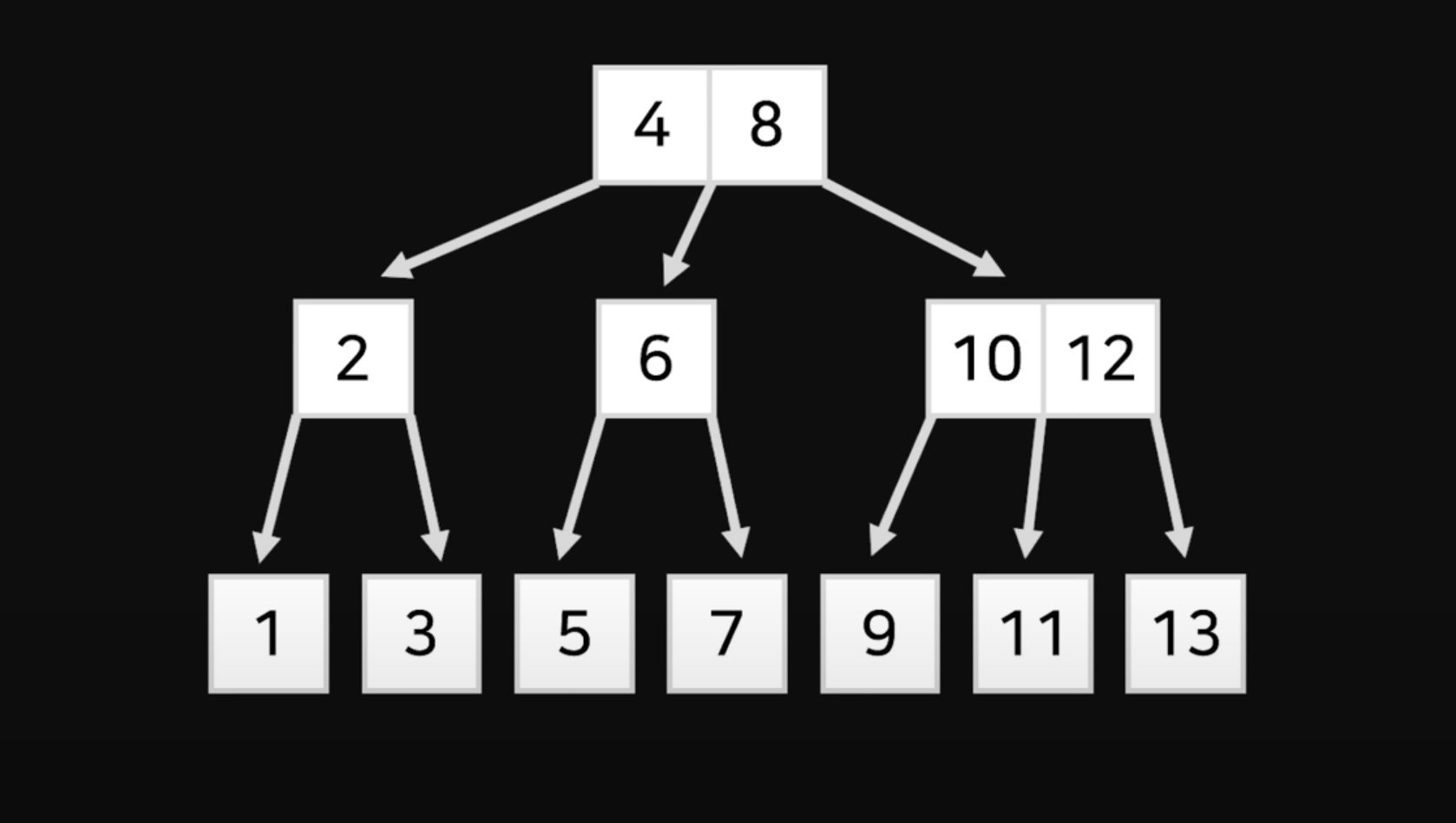
B-tree는 Binary Search Tree의 성능을 강화한 것이다. 한 개의 노드에 여러 숫자를 넣어 한번에 3분의 2씩 소거할 수 있다.
B+tree
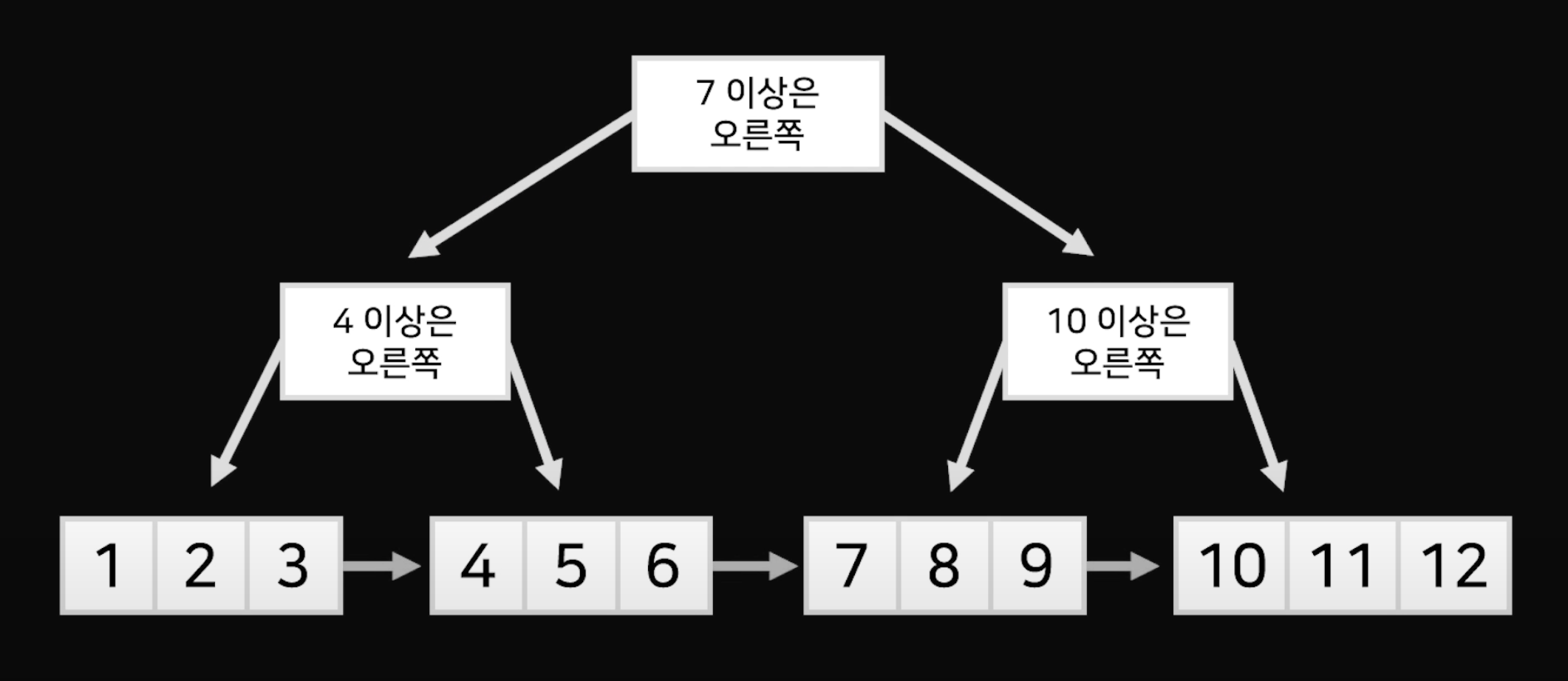
데이터를 노드에다 보관하는 것이 아닌 맨 밑에만 데이터를 보관한다. 위의 노드들엔 데이터가 아닌 가이드만 제공한다. B+tree의 차이점은 밑의 노드끼리도 연결되어 있다. 따라서 범위 검색이 매우 쉬워진다.
한줄 정리
Index가 없는 경우
1. 모든 행을 다 뒤진다.
Index가 있는 경우
1. index에서 age = 20을 빠르게 찾는다.
2. index와 연결된 원래 테이블 행을 가져온다.
하지만 Index는 컬럼을 복사하여 정렬해놓기 때문에 매번 데이터베이스 용량이 증가된다. 검색 작업이 없는 컬럼들은 굳이 Index를 만들 필요가 없다.
또한 기존에 있던 테이블의 데이터를 삽입, 수정, 삭제 해버리면 index에도 변경 사항을 반영하여야 한다. 데이터 생성, 추가 작업을 해야하기 때문에 성능이 하락될 수 있지만 크게 신경 쓸 필요는 없다.
Primary키는 자동 정렬이 되어있기 때문에 Index 생성이 필요없다.
