순차 탐색
- 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법
- 보통 정렬되지 않은 리스트에서 데이터를 찾아야 할 때 사용
- 리스트 내에 데이터가 아무리 많아도 시간만 충분하다면 항상 원하는 원소( 데이터 )를 찾을 수 있다는 장점이 있다
- 데이터 정렬 여부와 상관없이 가장 앞에 있는 원소부터 하나씩 확인해야 한다는 점이 특징
📍 리스트에서 순차 탐색으로 C를 찾는 과정

- 가장 먼저 첫 번째 데이터를 확인

- 찾고자 하는 데이터와 다르기 때문에 다음으로 넘어간다

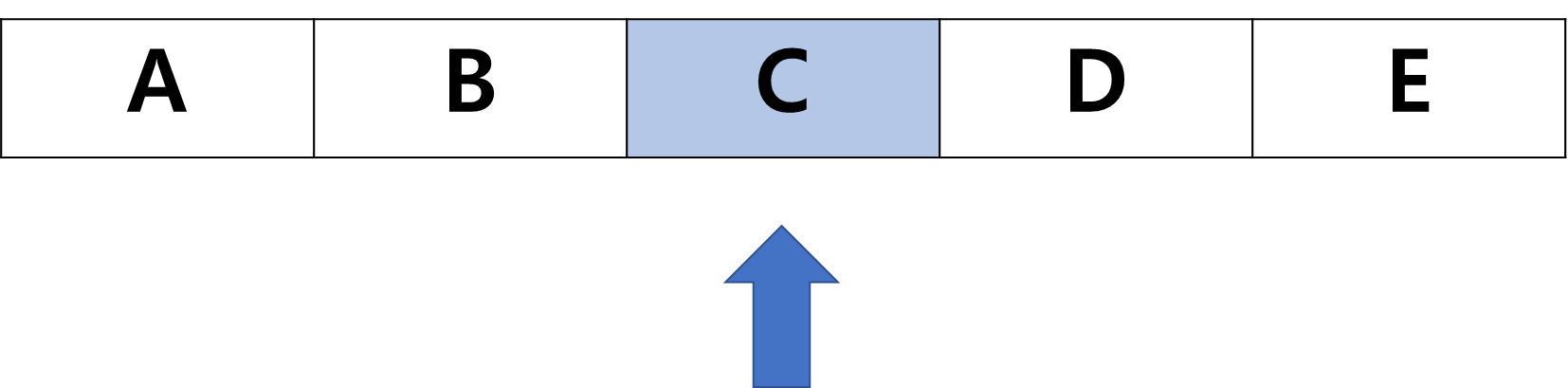
- 찾고자 하는 데이터와 일치하므로 탐색을 마친다
def sequential_search(n, target, array):
# 각 원소를 하나씩 확인
for i in range(n):
# 찾고자 하는 원소와 동일한 경우
if array[i] == target:
return i + 1 # 현재의 위치 반환( 인덱스는 0부터 시작하므로 1 더하기 )
print('생성할 원소 개수를 입력한 다음 한 칸 띄고 찾을 문자열을 입력하세요. ')
input_data = input().split()
n = int(input_data[0])
target = input_data[1]
print('앞서 적은 원소 개수만큼 문자열을 입력하세요. 구분은 띄어쓰기 한칸으로 합니다. ')
array = input().split()
print(sequential_search(n, target, array))
~~>
생성할 원소 개수를 입력한 다음 한 칸 띄고 찾을 문자열을 입력하세요.
5 Dongbin
앞서 적은 원소 개수만큼 문자열을 입력하세요. 구분은 띄어쓰기 한 칸으로 합니다.
Hanul Jonggu Dongbin Taeil Sangwook
3- 데이터의 개수가 개일 때 최대 번의 비교 연산이 필요하므로 최악의 경우 시간 복잡도는 이다.
이진 탐색: 반으로 쪼개면서 탐색하기
- 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘
- 데이터가 무작위일 때는 사용할 수 없지만, 이미 정렬되어 있으면 매우 빠르게 데이터를 찾을 수 있다는 특징이 있다
- 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 특징이 있다
- 시작점, 끝점, 중간점을 이용해 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해나가며 데이터를 찾는 탐색 과정
- 한 번 확인할 때마다 확인하는 원소의 개수가 절반씩 줄어든다는 점에서 퀵 정렬과 공통점이 있다
- 의 시간 복잡도를 가진다
📍 리스트에서 원소 값 4를 찾는 과정
- 시작점과 끝점을 확인한 다음 둘 사이에 중간점을 정한다
- 중간점이 실수일 때는 소수점 이하를 버린다

- 중간점의 데이터
8이 찾으려는 값 보다 크기 때문에 중간점 이후의 값은 확인 할 필요가 없다 - 끝점을 중간점의 앞 위치로 재설정 후 반복
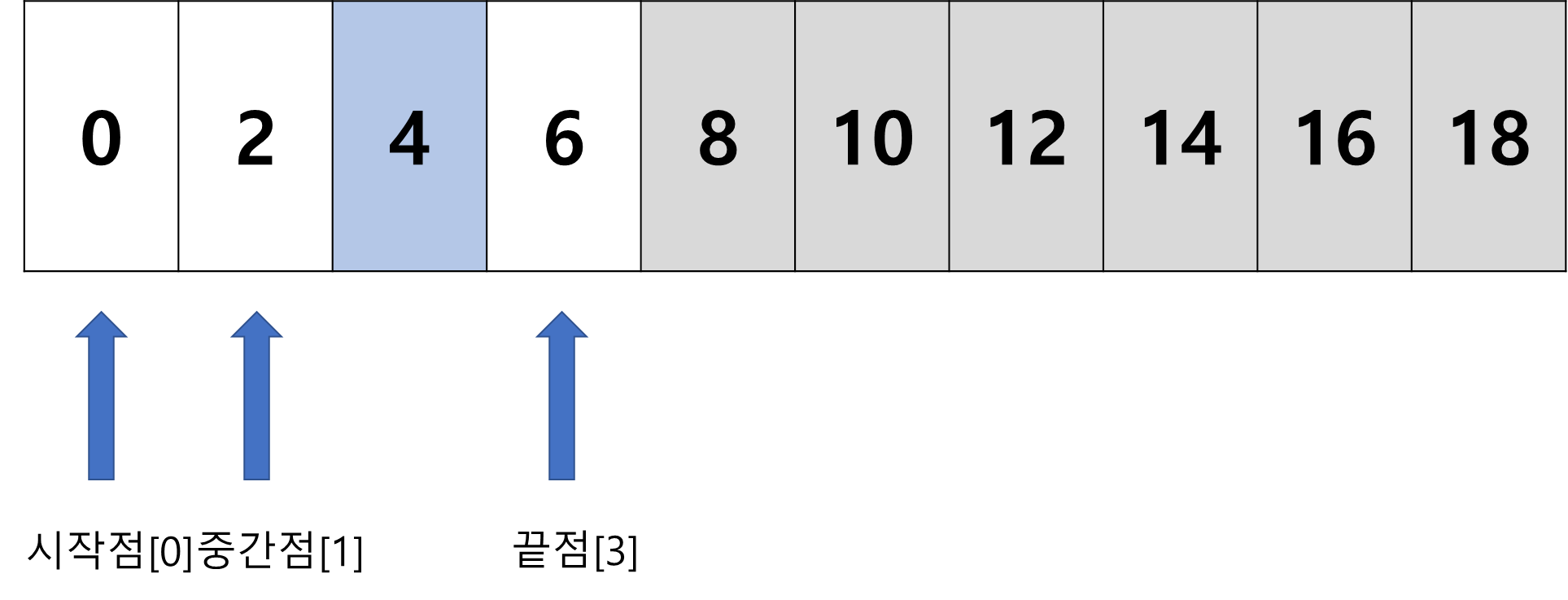
- 중간점에 위치한 데이터
2가 찾으려는 값 보다 작기 때문에 시작점을 중간점 앞 위치로 재설정 후 반복
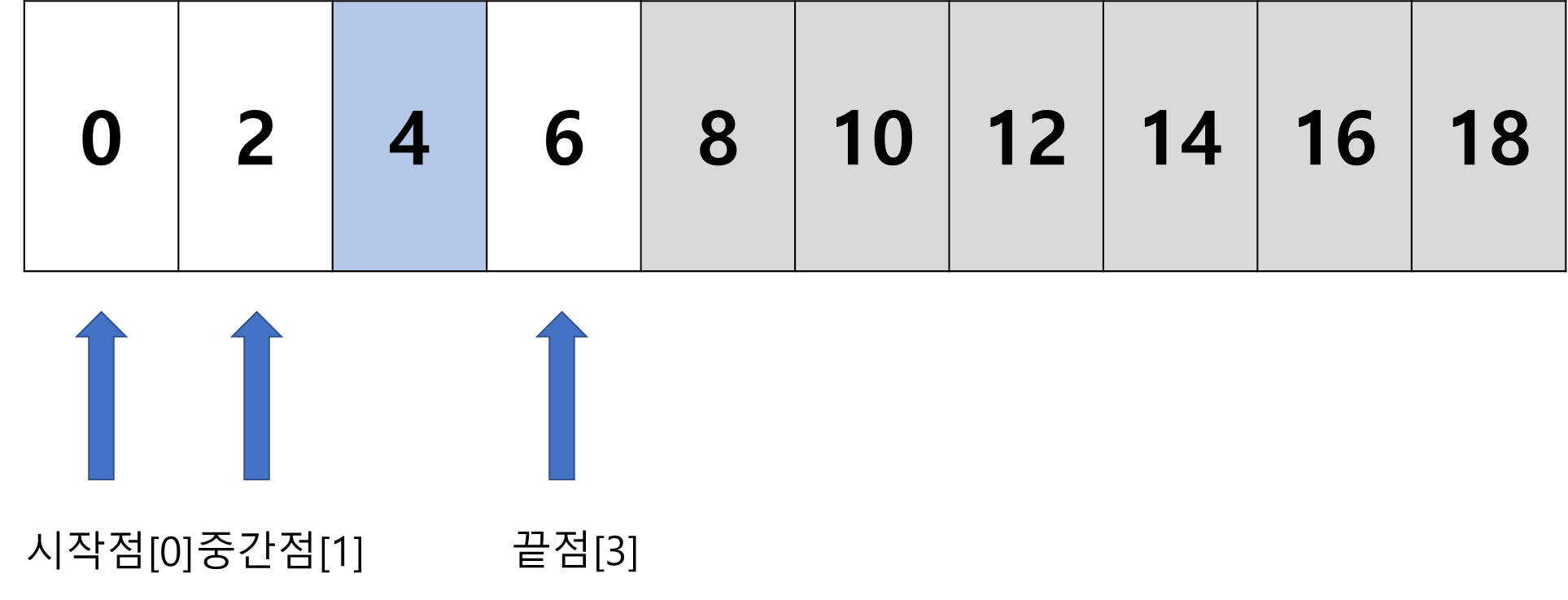
- 중간점에 위치한 값이 찾으려는 값
4와 일치하므로 탐색을 종료
📍 재귀 함수로 구현한 이진 탐색 소스코드
def binary_search(array, target, start, end):
if start > end:
return None
mid = (start + end) //2
if array[mid] == target:
return mid
elif array[mid] > target:
return binary_search(array, target, start, mid-1)
else:
return binary_search(array, target, mid+1, end)
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
print(result + 1)
~~>
# 1
10 7
1 3 5 7 9 11 13 15 17 19
4
# 2
10 7
1 3 5 6 9 11 13 15 17 19
원소가 존재하지 않습니다.
~~>📍 반복문으로 구현한 이진 탐색 소스코드
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
if array[mid] == target:
return mid
elif array[mid] > target:
end = mid - 1
else:
start = mid + 1
return None
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n-1)
if result == None:
print('원소가 존재하지 않습니다.')
else:
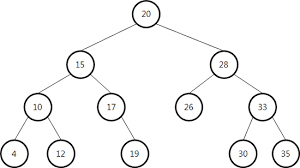
print(result + 1)트리 자료구조
- 트리는 부모 노드와 자식 노드의 관계로 표현
- 트리의 최상단 노드를 루트 노드라고 한다
- 트리의 최하단 노드를 단말 노드라고 한다
- 트리에서 일부를 떼어내도 트리 구조이며 이를 서브 트리라 한다
- 트리는 파일 시스템과 같이 계층적이고 정렬된 데이터를 다루기에 적합하다
이진 탐색 트리
- 트리 자료구조 중에서 가장 간단한 형태가 이진 탐색 트리이다
- 이진 탐색 트리의 특징
- 부모 노드보다 왼쪽 자식 노드가 작다
- 부모 노드보다 오른쪽 자식 노드가 크다
👉 왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드
📍 찾는 원소가 37일 때 동작하는 과정
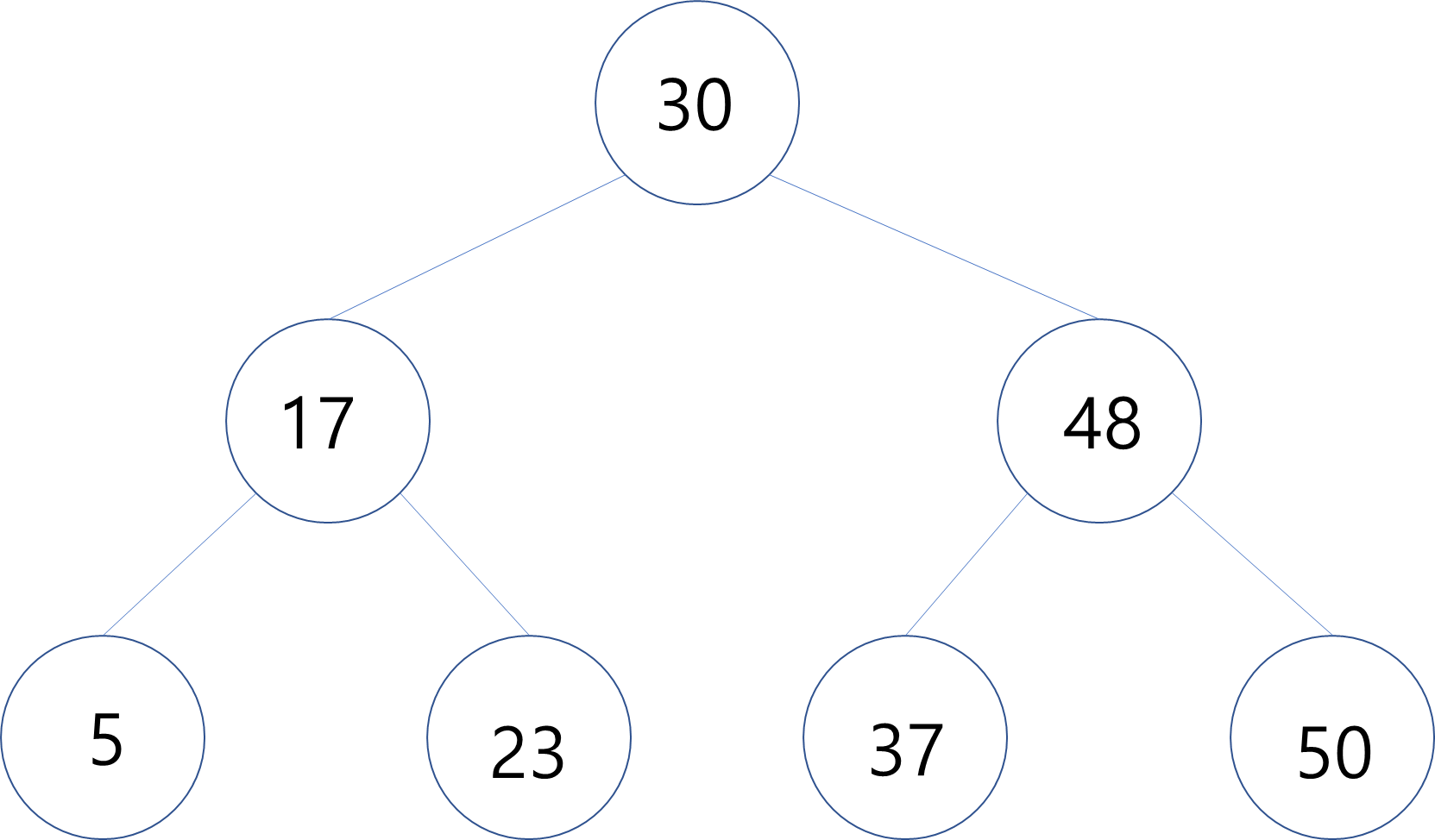
- 루트 노드가
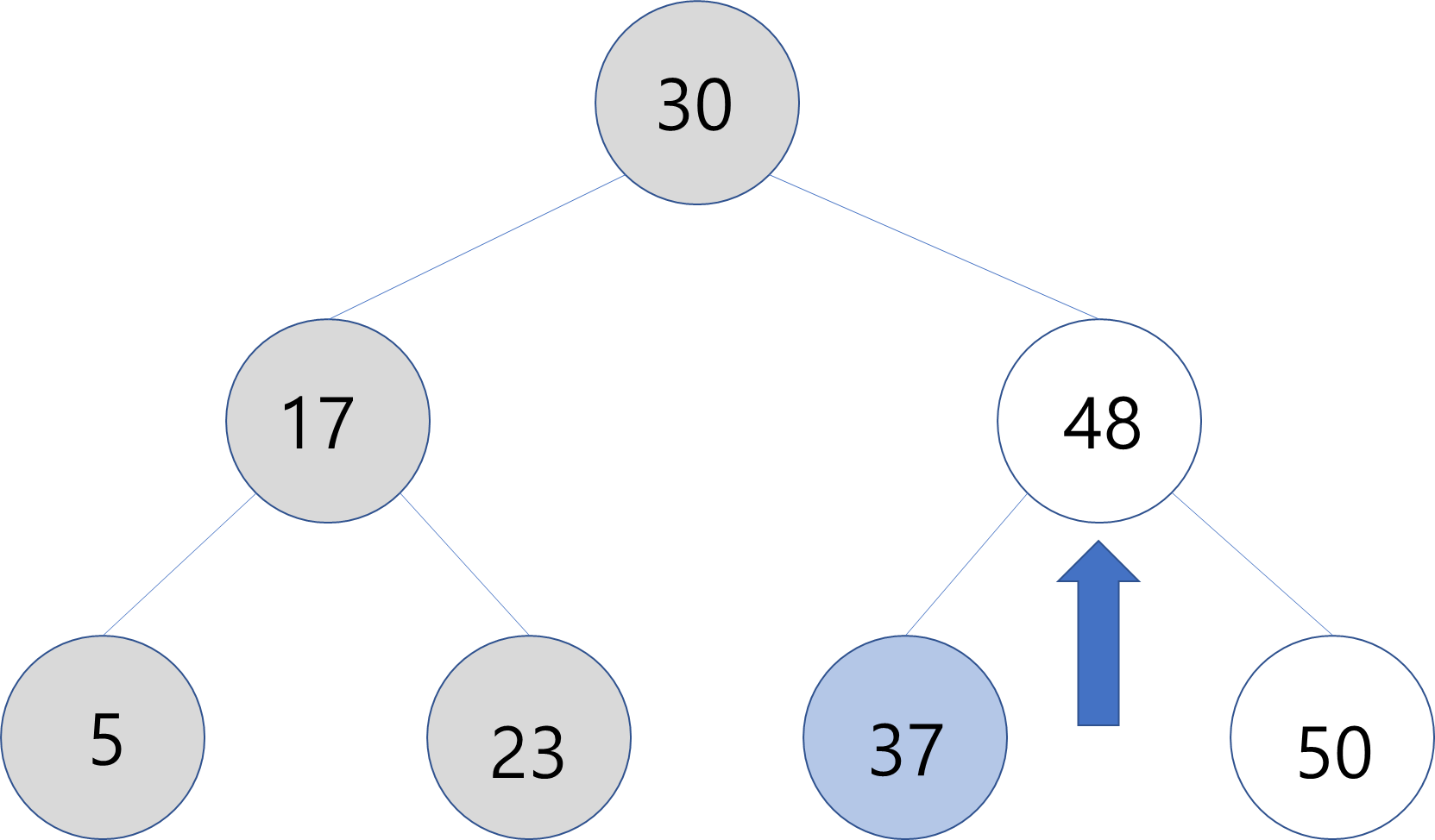
30이고 찾는 원소값이37이기 때문에 왼쪽 노드는 확인할 필요가 없다 - 오른쪽 자식 노드인
48이 부모 노드가 되었을 때 찾는 원소값37은 부모노드 보다 작기 때문에 왼쪽노드를 확인한다
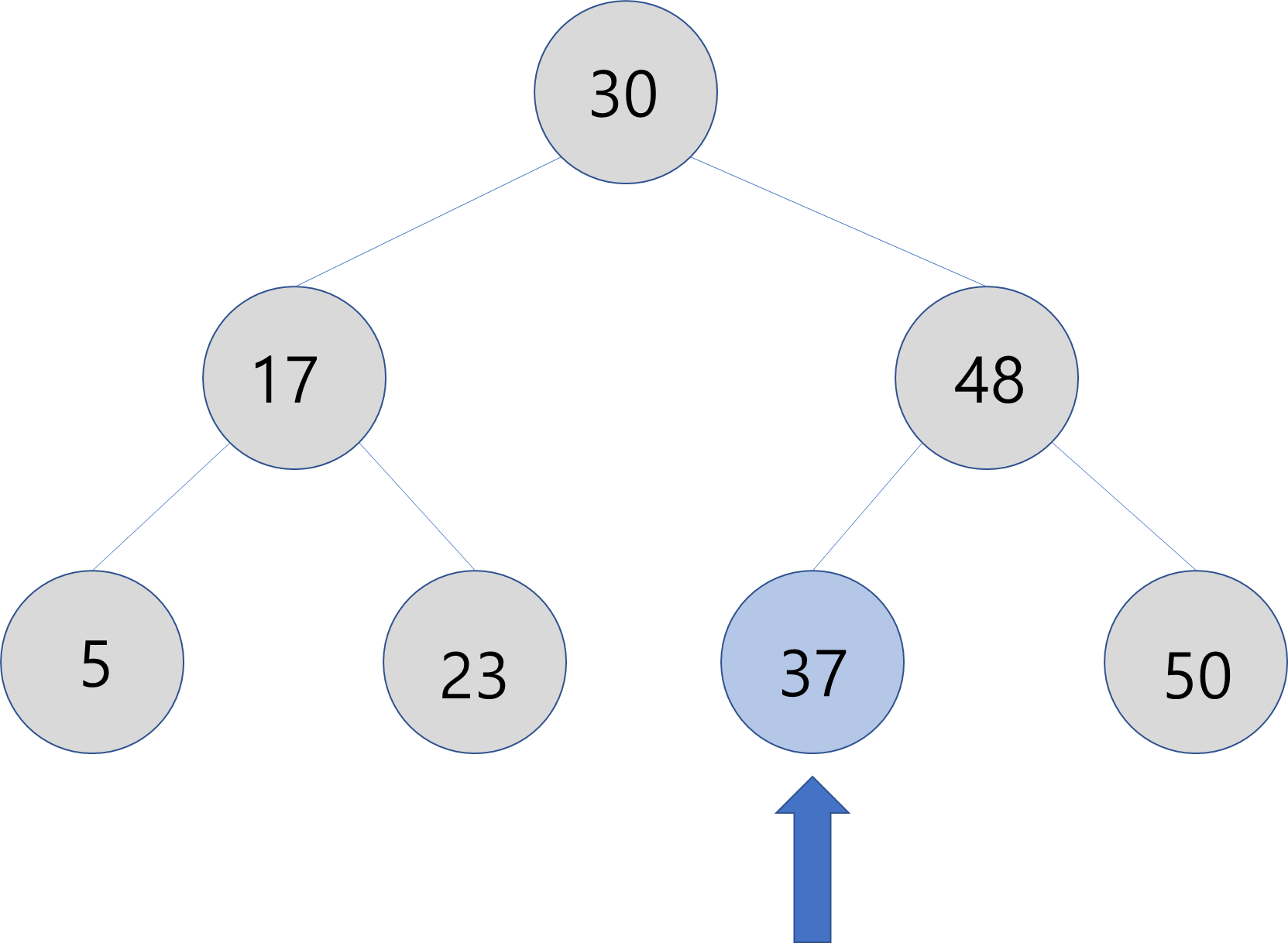
- 현재 방문한 노드의 값이
37과 일치하기 때문에 탐색을 마친다

data science!!, data analyst!! ///// hello world