Intro
원본 링크: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
3D rendering에 관하여 흥미가 생겨 처음 접한 논문입니다. 아무래도 3D rendering 의 background가 없으니 classical volume rendering 등등 중간 내용에 대해 충분히 이해하지 못하고 넘어간 부분이 있는 것 같습니다. 해당 부분의 수식을 정확히 이해하려면 추가적인 공부가 필요할 것 같습니다.
먼저 논문에 대해 간략히 요약해보면 3D렌더링을 수행하는 과정을 volume rendering + 5D(위치 + 각도)를 이용한 radiance field를 이용하여 모든 위치, 모든 각도에서 새로운 view를 합성할 수 있으면 해당 scene을 렌더링 했다고 보는 관점입니다. ray상의 sample들에서 RGB + density를 통해 얻고 이를 적절히(classical volume rendering) accumulate하여 해당하는 camera pose의 이미지를 얻어낼 수 있습니다.
읽는 중에 view와 scene을 나름대로 재정의하니 읽는데에 도움이 됐습니다.
1. scene: 장면 그 자체(보는 각도와 위치에 따라 물체는 움직이지 않음, 정적인 표현)이고
2. view: 위치와 보는 각도에 따라 달라지는 (반사되는 빛등을 표현할 수 있는, 동적인 표현) 요소들의 의미를 특히 강조하여 내포하고 있는 개념.
제가 생각한 논문의 핵심 idea를 생각해보자면,
1.MLP를 이용하여 implicit한 scene에 대한 연속, 미분가능한 표현 제공.
2.positional encoding을 이용한 저차원에서 고차원으로의 매핑 트릭.
3.5D를 이용하여 모든 위치, 모든 각도에서의 view를 합성하는 방법을 찾자 라는 접근법.
Main
Neural Radiance Field Scene Representation
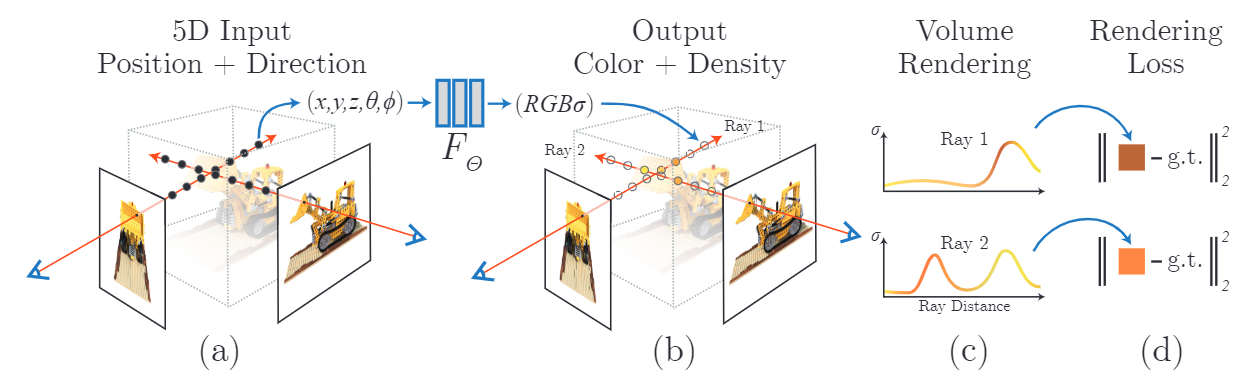
NeRF의 scene representation과 미분 가능한 rendering 절차를 설명하는 그림입니다.
a→b→c→d
순서대로 설명해보면
(a) 먼저 input으로 camera pose와 5D(3D: 위치 + 2D: direction)정보가 들어갑니다.
(b) 이를 MLP를 이용하여 각 sample들에 대한 RGB와를 구합니다.
(c) classical volume rendering 을 이용하여 ray에 따른 관찰자가 보는 color를 구합니다.
(d) 이를 g.t와 비교하여 학습의 loss로 이용합니다.
이때, 3D 위치정보만 이용하여 density 먼저 추정하고 모델 도중에 각도를 concate하여 RGB를 추정합니다.
Volume Rendering with Radiance Fields
, where = exp
위 식은 classical volume rendering에 관한 식입니다(??).
기존의 voxel grid를 이용하면 continuous한 view를 합성할 수 없습니다. 대신에 stratified sampling appoach 를 적용했는데, 이는 ray를 개로 uniform하게 sampling합니다. 이럴경우 sample들이 존재하는 영역은 continuous한 domain이 되므로 continuous한 novel view를 합성할 수 있게 됩니다.
sampling 과정은 위 수식과 같고,
위 수식을 이용하여 ray를 sampling하고 해당 ray에 해당하는 color를 예측하게 됩니다.
Optimizing A Neural Radiance Field
Neural Radiance Field를 optimizing하는 과정에서 핵심 idea는 두가지가 있습니다.
- Positional Encoding
MLP가 Low frequency에 집중되도록 학습되는 경향이 있다고 합니다. input을 higher dimension으로 매핑하므로 low frequency에 바이어싱 되는 현상을 어느정도 해결하는 트릭을 사용하였습니다.
위 수식을 이용하면 를 로 매핑할 수 있습니다.
transformer의 positional encoding과 차이점은 transformer에서는 input token의 위치 정보를 부여하기 위하여 positional encoding을 사용했다면, NeRF에서는 저차원에서 고차원으로 매핑하기위한 수단으로 이용했다는 목적성에서 차이가 있습니다.
- Hierarchical volume sampling
가려진 부분과 자유공간은 렌더링에 거의 영향이 없습니다. 따라서 evenly sampling하는 과정은 충분히 유의미한 sample의 개수를 확보하는데에 비효율적입니다.
따라서 volume 과 관련된 부분에 바이어스 되도록 를 추가적으로 sampling한 후 + (fine network)으로 학습을 진행합니다.
Aditional Considerations
궁금한 점은 density가 각 sample에 대해서 하나의 스칼라 값으로 예측되는데,파란색 유리를 통해 뒤의 물체를 관찰하는 경우를 생각해보면, RGB별로 density가 다를것이라 생각했습니다. 따라서 RGB에 일대일 대응되도록 density도 세개의 값이 예측될 것이라 생각했는데, 이러한 부분들이 고려된 것인지 실험 결과를 통해 확인해볼 예정입니다.
