Intro
원본 링크: Attention Is All You Need (NIPS 2017)
학부연구생을 진행하면서 vision Transformer(ViT)를 이용한 논문을 접한 적이 있었는데 이해하지 못하고 넘겼던 경험이 있습니다.
언젠가 한번 Transformer부터 차근차근 공부해야지 하던게 많이 미뤄졌네요.
Attention, Positional encoding, ViT 도 전반적으로 공부해볼 예정입니다.
transformer는 기존 sequencial 모델에 사용됐던 RNN, CNN을 attention 메커니즘으로 대체한 모델입니다.
이때 sequential 모델에서 다루는 중요한 관점 2가지가 있는데 첫번째는 연산량, 두번째는 long-term dependency 입니다.
- hidden state 를 이용하기때문에 병렬화를 할 수 없다.
→ sequence의 길이가 길수록 연산량이 증가한다.- long-term dependency를 학습할 수 있어야 한다.
→위치상으로 멀리 떨어진 데이터의 관계를 표현할 수 있어야 한다.
논문에서 저자는 multihead attention과 self-attention 를 이용하여 위 두 문제를 효과적으로 해결했음을 보이고 있습니다.
Main
RNN, LSTM, GRNN 같은 Transformer 이전의 모델들은 hidden state 를 과 에서의 input으로 표현하는 방법을 사용합니다. 이는 곧 순서에 따라 계산돼야 해서 병렬화가 불가능함을 의미합니다.
factorization 트릭, conditional constraint으로 이러한 문제들을 어느정도 우회했지만. 한계점 존재한다고 지적하고 있습니다.
Transformer구조는 attention 메커니즘을 이용하여 병렬화가 가능하고 global dependency도 학습할 수 있습니다.
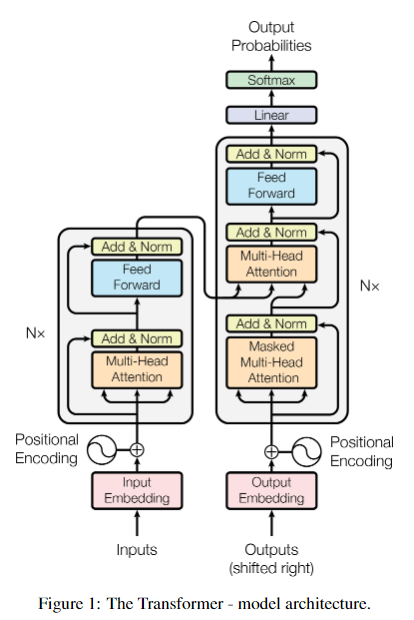
모델의 구조는 encoder, decoder 부분으로 나눌수 있고 두 구조는 비슷하지만 디코더에는 Masked Multi-Head Attention layer가 존재한다는 것이 차이점입니다. 이는 디코더에서 학습시에 현재 출력되고 있는 step 이후의 정보를 참조하지 않게 하기 위해 절댓값이 큰 음수를 에 넣어 masking 되도록 합니다.
Encoder
인코더는 input sequence of symbol 을 연속적인값의 representation 로 매핑하는 역할을 수행합니다. 여기서 의 차원이 같은 이유는 skip connection을 이용하기에 차원의 개수가 같게 됩니다. (으로 같은 차원이면 skip connection을 이용하는 것이 거의 한 쌍이라고 봐도 될 정도로 일반적인것 같습니다.)
sub layer는 크게 multi-head attention과 feed-forward layer 두가지로 이루어져 있는데, 각각을 살펴보면 다음과 같습니다.
multi-head attention:
= 512 차원의 K,Q,V를 한번 어텐션을 수행하는 것 보다 K,Q,V를 프로젝션 시켜서 각각 차원으로 h번 어텐션을 수행한 후 concat하는 것이 더 효과적이라 설명하고 있습니다. 연산량은 concat을 제외하면 동일합니다.
여기서 로 scaling을 해주는 이유는 forwarding시에 분산이 발산하지 않도록 하는 역할을 해줍니다.
position-wise Feed-Forward Networks:
쉽게 이해하면 Affine → relu →Affine 구조입니다.
input과 output의 크기는 512로 동일하고 inner layer = 의 크기는 2048 입니다. (512 → 2048 →512 로 크기 변환이 이루어집니다.)
본논문대로라면 해당 layer를 6번 반복하여 에 대한 continuous representation 를 얻을 수 있게 됩니다.
인코더를 통해 source data에 대한 attention을 수행하여 source data간의 연관성, 추상적인 관계를 학습하고 이 정보를 decoder에 전달해줄 수 있습니다.
Decoder
디코더는 인코더와 비슷하지만 output에 대해 Masked Multihead self-attention을 수행하는 sub layer가 추가됩니다.
이는 학습시에 이후 출력에 대한 정보를 masking 해줘서 옳바른 학습이 이루어질 수 있도록 합니다.
디코더는 인코더로부터 를 전달받아 로 사용하게 됩니다. 예를들면
한국어→영어 번역task에서
"나는 학교에 간다."→"I go to school"
각각의 단어 "나는", "학교에", "간다." 의 인코딩된 정보가 출력된 output들과 어떠한 연관성이 있는지("학교에"와 "go"의 연관성이 높아?를 물어봄)를 파악할 수 있게 인코더가 정보를 제공한다고 이해할 수 있습니다.
디코더는 차원의 output으로부터 선형변환, softmax를 이용하여 next-token probability를 계산하고, eos token이 출력될 때까지 위 과정을 반복합니다.
Additional Considerations
-
path length dependency에 영향을 미치는 중요한 요인이 propagation시의 path의 길이다 라는 내용이 있었는데, 추가적인 공부가 필요할 것 같습니다. 직관적으로 생각하면 거리가 멀면 gradient가 약하게 흐르기 때문이지 않을까 생각합니다.
-
: 단어의 개수
: Embeding 벡터의 크기
라고 한다면 인경우와 인 경우의 시간 복잡도를 비교해보기.
인 경우 반경 에 해당하는 포지션으로 dependency 학습이 제한되어 maximum path가 늘어난다라고 하는 내용이 본문에 있는데, 정량적인 분석이 필요할 것 같습니다. -
positional encoding
- input 에서 continuous representation , output
→→로 매핑하는 각각의 step이 AR(Auto-Regressive) 하다는 것의 의미.
