이번 프로젝트를 하면서, 쿼리를 어떻게 짜야 성능이 좋아질 수 있을까에 대해 고민을 해보았습니다. jpa에서 제공해주는 쿼리 메서드는 분명 편하지만, 과연 직접 짜는 것과 비교해 봤을 때 속도가 빠를까에 대한 의문이 있었습니다.
그래서, 기존 JPA 메서드와 QueryDSL 기반 접근 방식이 어떤 성능 차이를 보이는지 확인하고자 했으며, 시각적인 분석을 위해 nGrinder를 사용했습니다.
테스트 조건 및 예상 결과
테스트 조건
- QueryDSL Fetch Join: 데이터를 조인하여 필요한 정보를 메모리에 캐싱 처리로 가져옵니다.
- QueryDSL로 필요한 컬럼만 가져오기: 필요한 데이터만 찾아서 받아옵니다.
- JPA 메서드 (FetchType.LAZY): Lazy Loading 방식으로 데이터를 가져옵니다.
- JPA 메서드 (FetchType.EAGER): Eager Loading 방식으로 데이터를 즉시 로드합니다.
예상 결과
Fetch Join이나 fetchtype.EAGER은 캐싱 처리이지만, 모든 엔티티를 가져와야 하기 때문에 성능이 저하될 것이라고 생각하였습니다.
QueryDSL의 특정 컬럼만 가져오는 방식이 가장 성능이 좋을 것으로 예상하였으며, LAZY 방식이 가장 느릴 것으로 예측했습니다.
FetchType.EAGER 방식은 성능이 Fetch Join과 비슷할 것으로 기대했으나, 불필요한 데이터를 로드하기 때문에 메모리 사용량이 많아질 가능성을 고려했습니다.
예상 성능 순위:
QueryDSL 특정 컬럼 >= QueryDSL Fetch Join = fetchType.EAGER > fetchType.LAZY
테스트 환경 및 코드
테스트 환경
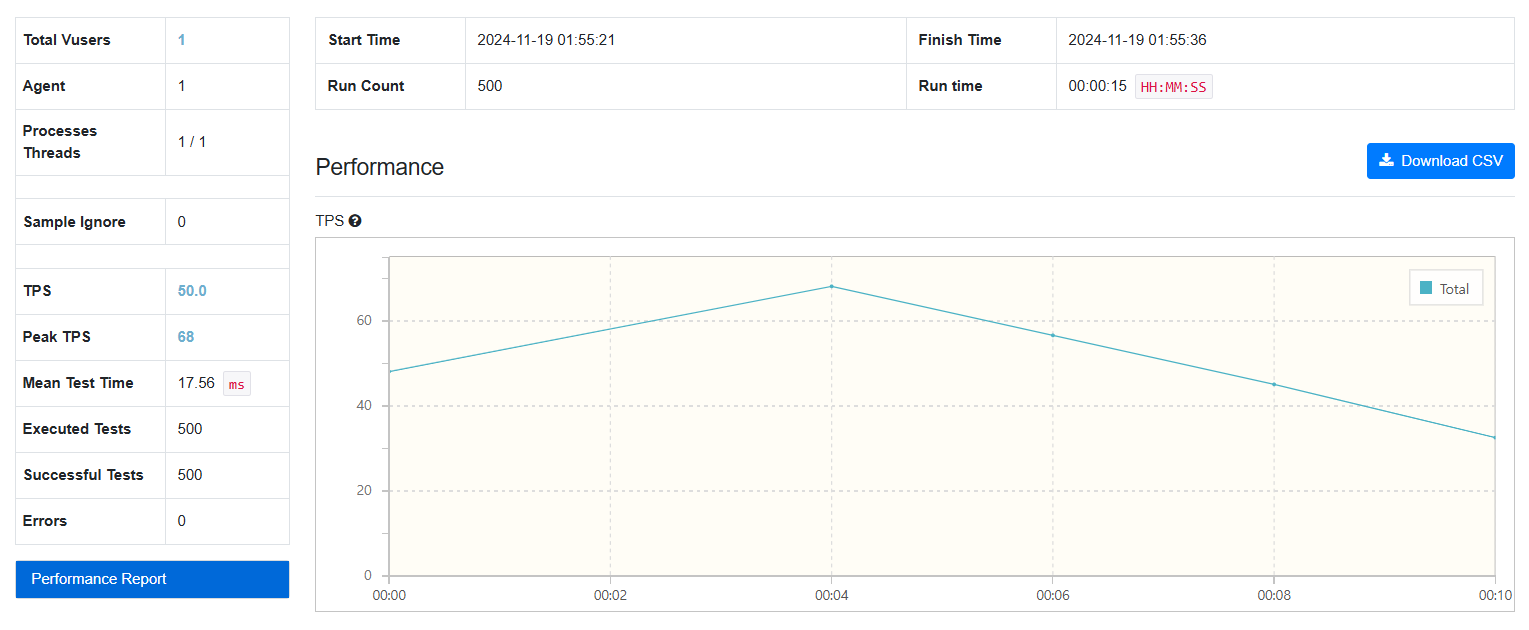
- 데이터를 1만 건 기준으로 테스트하였습니다.
- 동시성 문제를 배제하기 위해 사용자 수는 1명으로 제한하였습니다.
- 결과 데이터는 OrderResponseDto 형태로 반환되며, JSON 예시는 다음과 같습니다.
{
"orderItems": {
"간장치킨": {
"quantity": 1,
"price": 24000
},
"양념치킨": {
"quantity": 1,
"price": 24000
}
},
"restaurantName": "또래오래",
"userName": "김성호",
"totalPrice": 48000,
"orderDate": "2024-11-18T12:05:10.769+00:00",
"orderType": "온라인",
"deliveryAddress": "서울특별시 노원구",
"deliveryRequest": "문앞에 놓아주세요",
"status": "주문 조회 중"
}- 서비스 및 컨트롤러 코드 (테스트 용도)
@Override
public List<Tuple> findOrderDetailsTuples(UUID orderId) {
QOrder o = QOrder.order;
QUser u = QUser.user;
QRestaurant r = QRestaurant.restaurant;
QOrderItem oi = QOrderItem.orderItem;
QMenu m = QMenu.menu;
return queryFactory
.select(
u.username,
r.name,
o.orderType,
o.status,
o.createdAt,
o.totalPrice,
o.deliveryAddress,
o.deliveryRequest,
oi.quantity,
m.name,
m.price
)
.from(oi)
.join(oi.order, o)
.join(o.user, u)
.join(o.restaurant, r)
.join(oi.menu, m)
.where(o.id.eq(orderId))
.fetch();
}@Override
public OrderResponseDto findOrderDetailsFetchJoin(UUID orderId) {
QOrder o = QOrder.order;
QUser u = QUser.user;
QRestaurant r = QRestaurant.restaurant;
QOrderItem oi = QOrderItem.orderItem;
QMenu m = QMenu.menu;
List<Tuple> result = queryFactory
.select(
o,
u,
r,
oi,
m
)
.from(oi)
.join(oi.order, o).fetchJoin()
.join(o.user, u).fetchJoin()
.join(o.restaurant, r).fetchJoin()
.join(oi.menu, m).fetchJoin()
.where(o.id.eq(orderId))
.fetch();
return mapToOrderResponseDto(result);
}@RestController
@RequiredArgsConstructor
@RequestMapping("/api/test")
public class TestController {
private final OrderService orderService;
private final OrderRepository orderRepository;
@GetMapping("/querydsl/neededItems/{orderId}")
public OrderResponseDto testQueryDslFetch(@PathVariable UUID orderId) {
return orderService.findOrderDetails(orderId);
}
@GetMapping("/querydsl/fetch/{orderId}")
public OrderResponseDto testJpqlFetch(@PathVariable UUID orderId) {
return orderRepository.findOrderDetailsFetchJoin(orderId);
}
@GetMapping("jpa/lazyAndEager/{orderId}")
public OrderResponseDto testLazyFetch(@PathVariable UUID orderId) {
Order order = orderRepository.findById(orderId).get();
Map<String, MenuDetails> MenuDetails = new HashMap<>();
order.getOrderItems().stream().map(orderItem ->
MenuDetails.put(
orderItem.getMenu().getName(),
new MenuDetails(orderItem.getQuantity(),
orderItem.getMenu().getPrice())));
OrderResponseDto orderResponseDto = new OrderResponseDto();
orderResponseDto.setOrderDate(Timestamp.valueOf(order.getCreatedAt()));
orderResponseDto.setOrderItems(MenuDetails);
orderResponseDto.setDeliveryAddress(order.getDeliveryAddress());
orderResponseDto.setDeliveryRequest(order.getDeliveryRequest());
orderResponseDto.setOrderType(order.getOrderType());
orderResponseDto.setStatus(order.getStatus());
orderResponseDto.setTotalPrice(order.getTotalPrice());
orderResponseDto.setRestaurantName(order.getRestaurant().getName());
orderResponseDto.setUserName(order.getUser().getUsername());
return orderResponseDto;
}
}테스트 결과: 1만 건 기준
1. QueryDSL Fetch Join
QueryDSL을 활용하여 Fetch Join으로 데이터를 가져온 결과, 초당 약 100~120회 요청 처리가 가능했습니다.
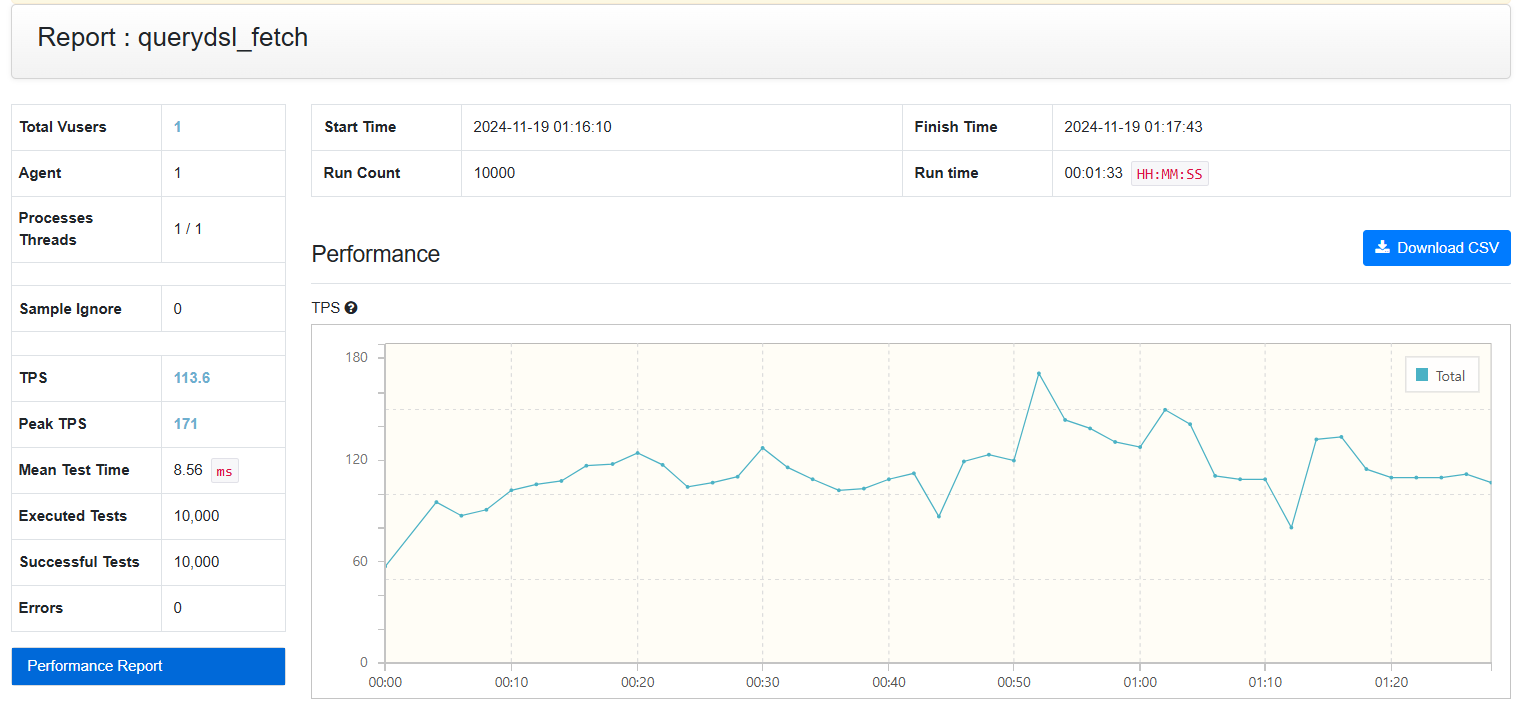
2. QueryDSL로 필요한 컬럼만 추출
QueryDSL로 필요한 컬럼만 가져온 결과, 초당 약 80~110회 요청 처리가 가능했습니다.
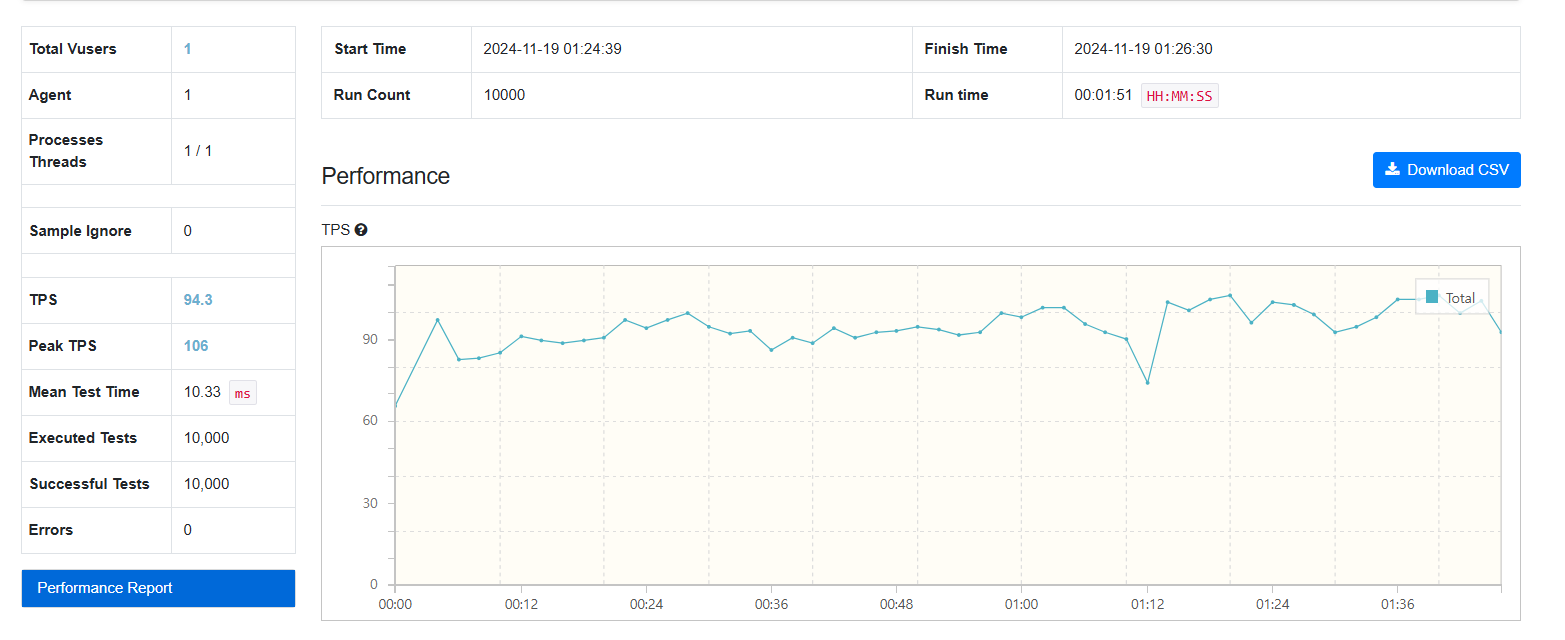
3. FetchType.LAZY
JPA 메서드를 사용하여 FetchType.LAZY로 데이터를 가져온 결과, 초당 약 70~90회 요청 처리가 가능했습니다.
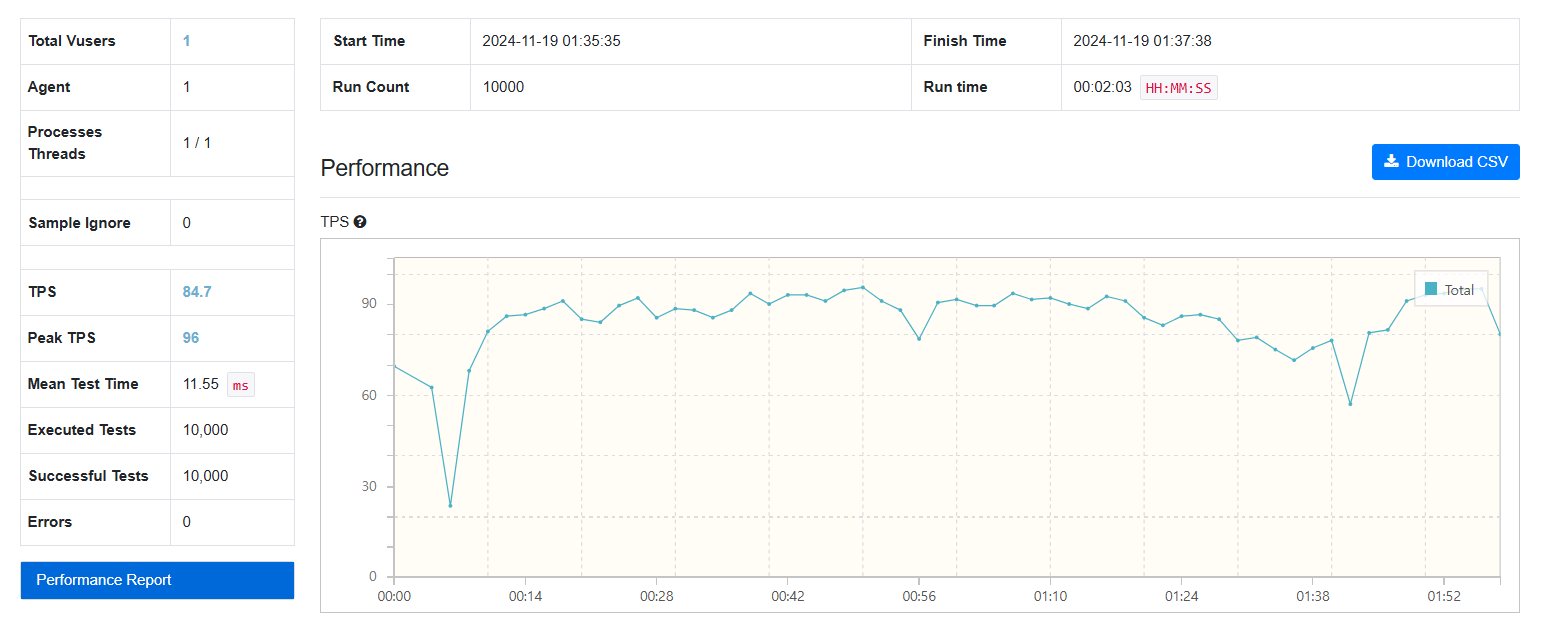
4. FetchType.EAGER
JPA 메서드를 사용하여 FetchType.EAGER로 데이터를 가져온 결과, 초당 약 50~60회 요청 처리가 가능했습니다.
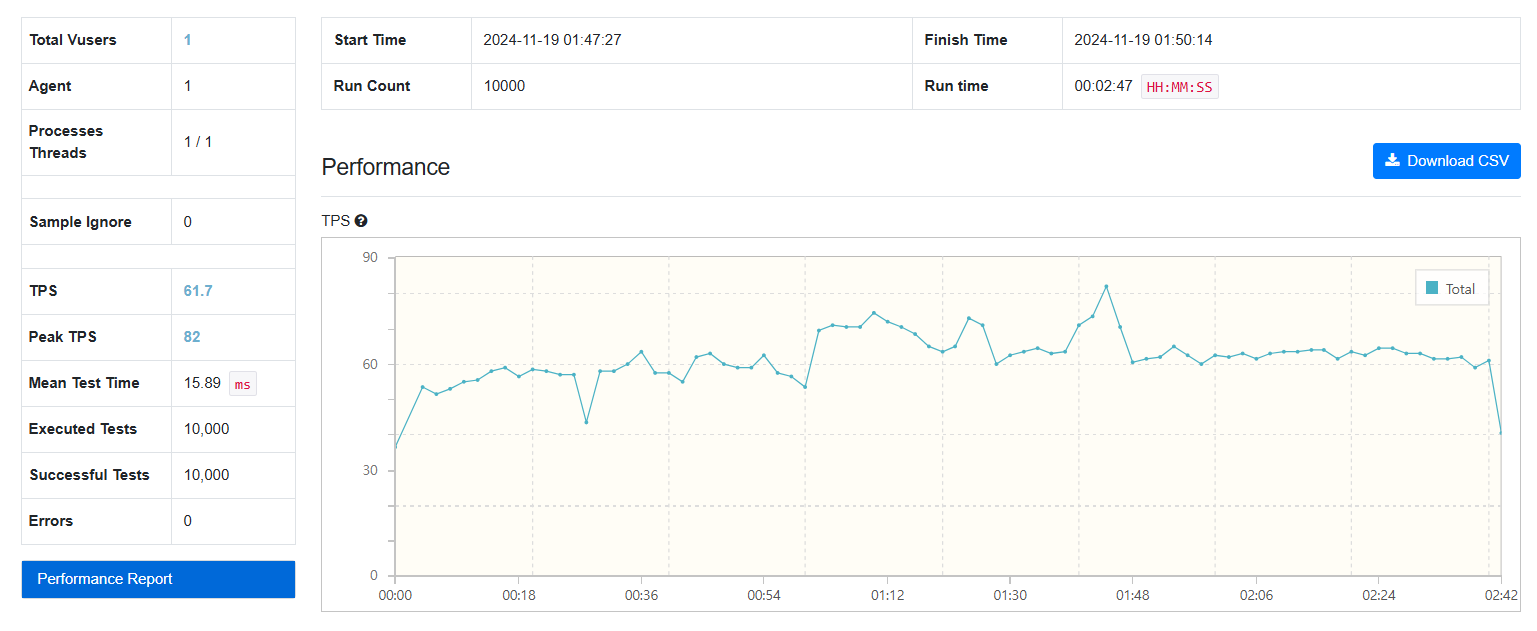
결과 분석
성능 비교
QueryDSL Fetch Join > QueryDSL로 필요한 컬럼 추출 > FetchType.LAZY > FetchType.EAGER
-
QueryDSL Fetch Join 방식이 가장 빠르게 나타났으며, EAGER 방식이 가장 느렸습니다.
-
QueryDSL로 필요한 컬럼만 가져오는 방식은 Fetch Join보다는 느렸으나, 메모리 사용량을 줄이는 데 유리할 것이라 예상합니다.
-
Fetch Join은 필요한 데이터를 한 번에 가져와 메모리에 캐싱하여 조회 속도가 빨랐습니다.
-
EAGER는 영속성 컨텍스트 1차 캐싱으로 모든 연관 데이터를 즉시 로드하며, 불필요한 데이터까지 가져오게 되어 성능이 저하된 것으로 보입니다.
-
LAZY는 가장 느릴 것으로 예상했으나, EAGER이 다른 엔티티의 정보까지 탐색하는 시간 동안에 데이터를 처리하여 시간 소모가 적었던 것으로 보입니다.
개선 방향
-
메모리 관리
Fetch Join은 성능이 좋지만, 동시 사용자가 증가하면 메모리 사용량이 급격히 늘어날 수 있습니다. 이를 줄이기 위해 Redis와 같은 캐싱 기술을 병행하거나, 적절한 로직에서는 QueryDSL을 사용해 필요한 컬럼만 조회하는 방식으로 메모리 부담을 덜어내는 것도 하나의 방법이라고 생각합니다. -
동시성 문제
동시 사용자가 많아질수록 데이터베이스 연결이 포화 상태에 이르거나 서버 자원이 부족해질 가능성이 높아집니다. 이를 예방하기 위해 동시성 테스트를 추가로 진행하고 병렬 처리가 가능하도록 구조를 최적화해야 합니다.
결론
이번 테스트를 통해 Fetch Join 방식이 빠르고 효율적인 방법임을 확인했습니다. 하지만 동시 사용자가 많아지면 메모리나 데이터베이스 부하로 인해 성능이 저하될 가능성이 큽니다.
실제 운영 환경에서는 단순 조회 속도뿐만 아니라, 동시성 처리, 메모리 관리, 데이터베이스 부하 등 여러 요인을 종합적으로 고려해야 합니다. 캐싱 기술과 최소 데이터 조회 방식을 병행하는 전략이 중요하며, 테스트 환경을 실제 환경과 최대한 비슷하게 설정해 지속적으로 점검하는 것이 필요합니다.
최대한 실제 환경과 비슷하게 만들어서 테스트하는 방법을 찾아보고 싶어졌으며, querydsl과 fetch join의 작동 원리와 fetchType을 더 잘 설계하는 방법에 대해서 생각해 보게 되었습니다.
상세 데이터
7000건
-
Fetch Join:
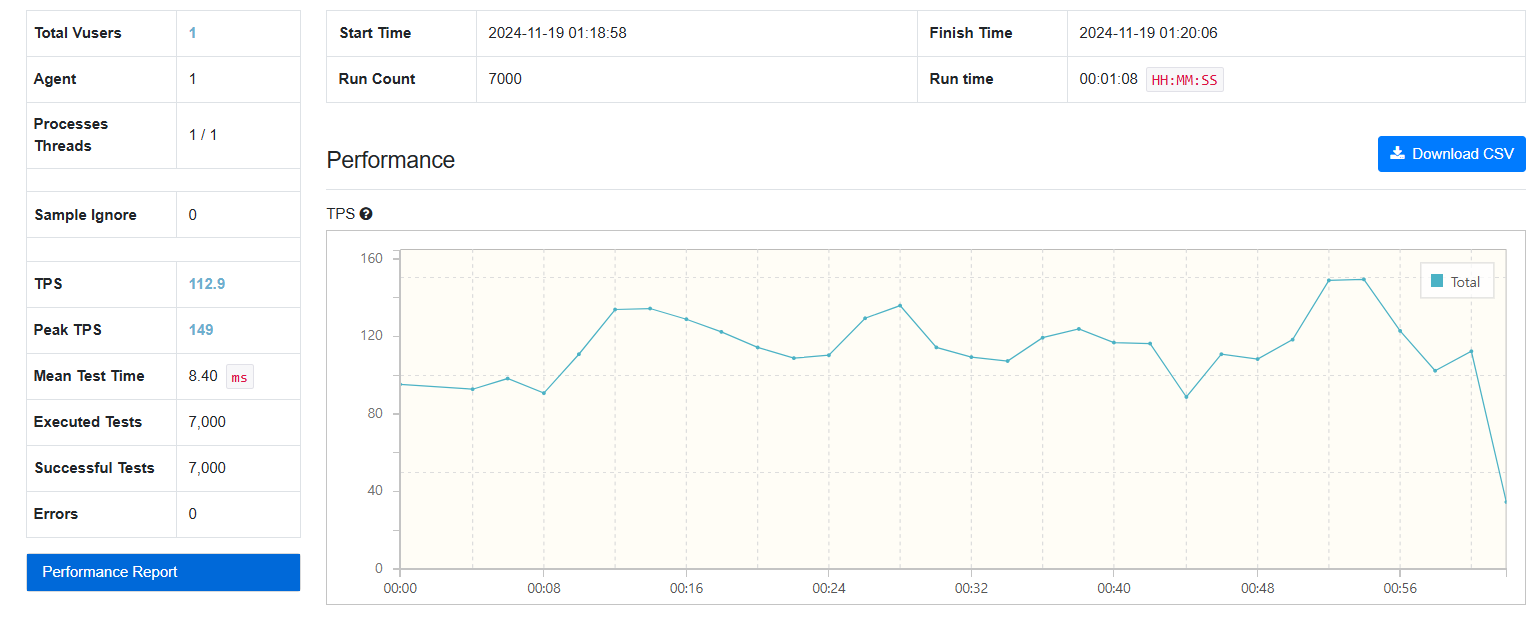
-
컬럼 추출:
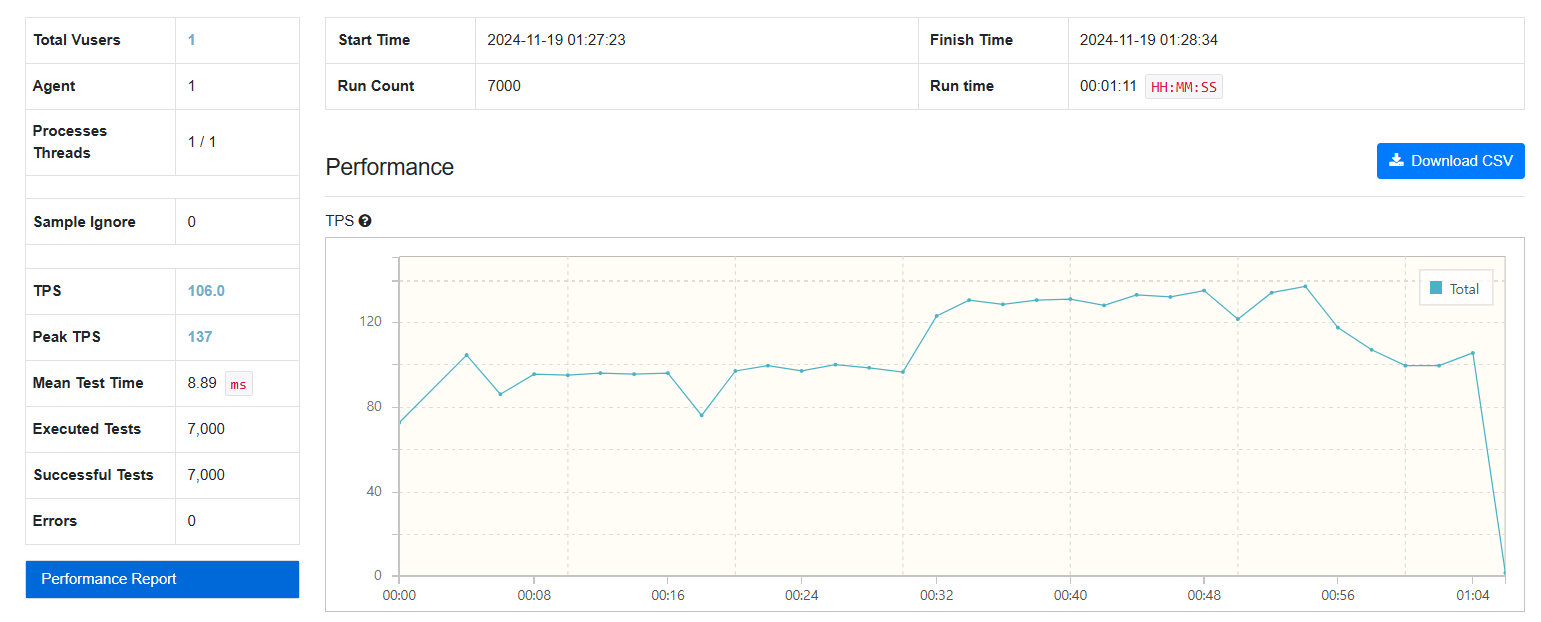
-
FetchType.LAZY:
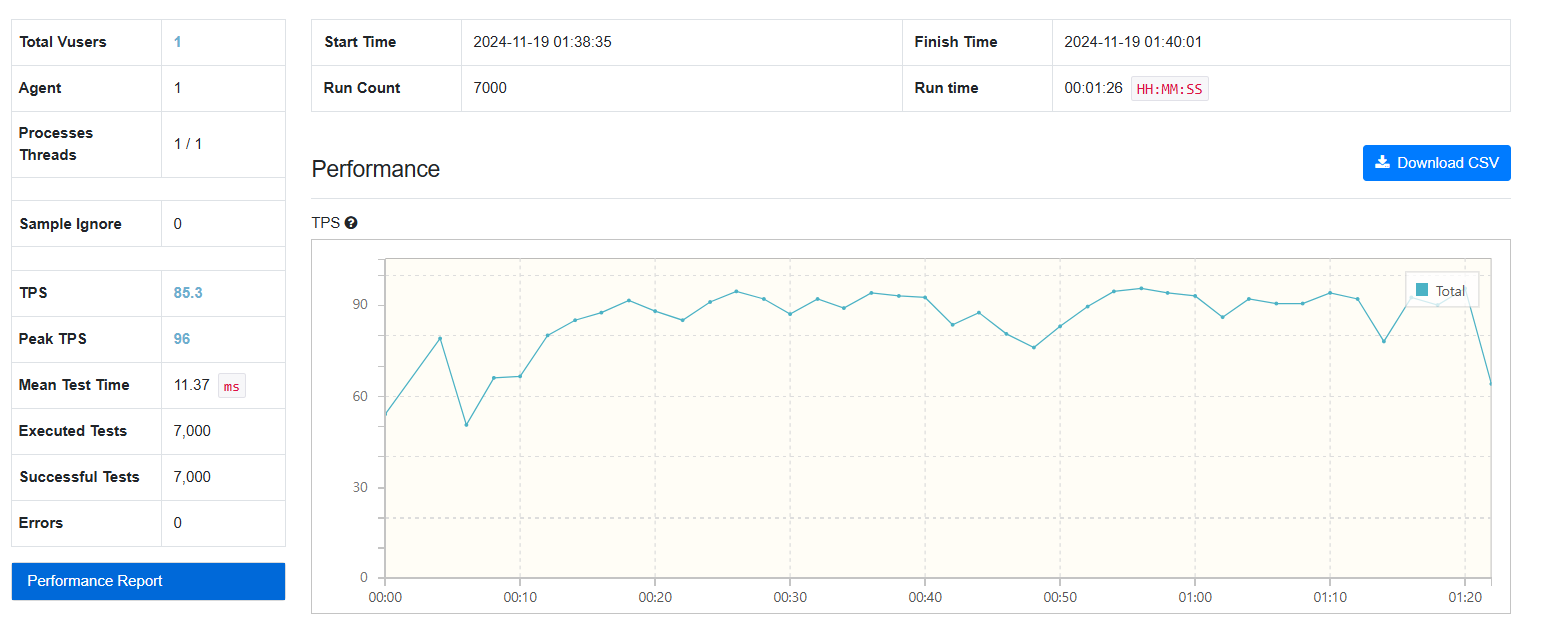
-
FetchType.EAGER:
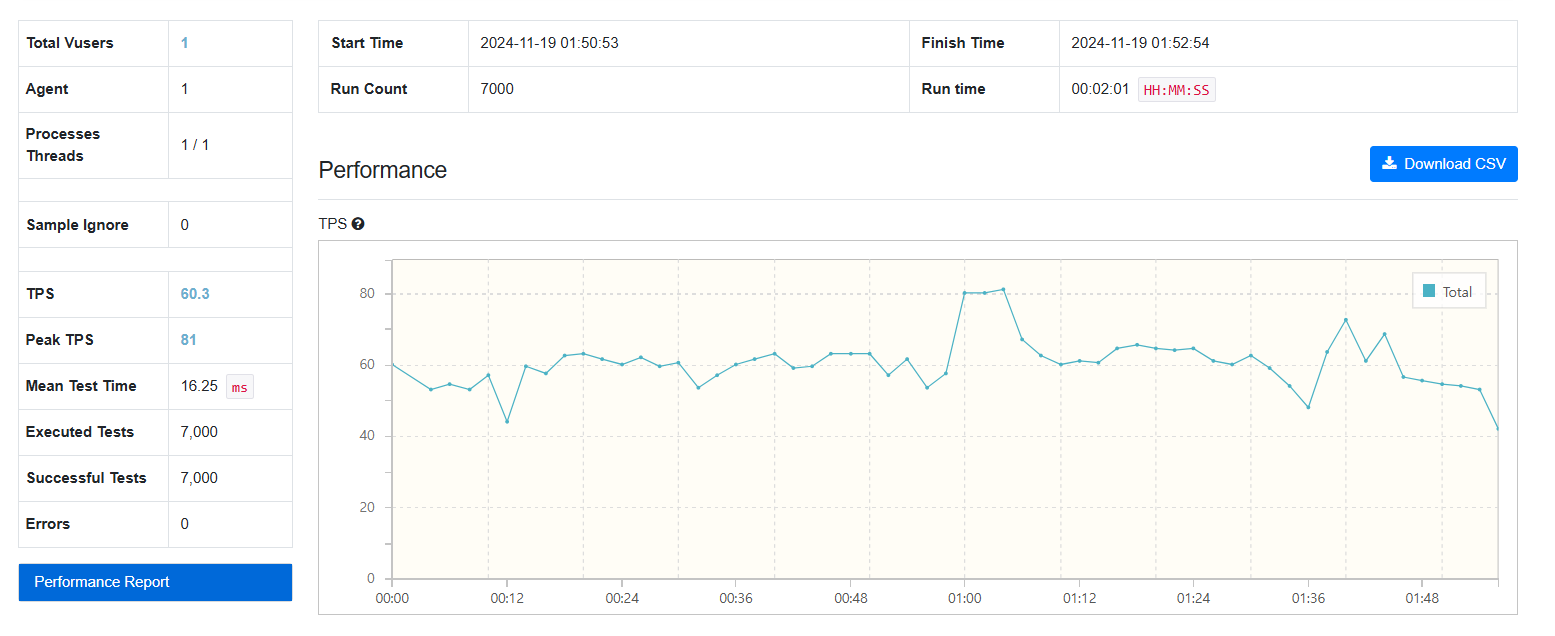
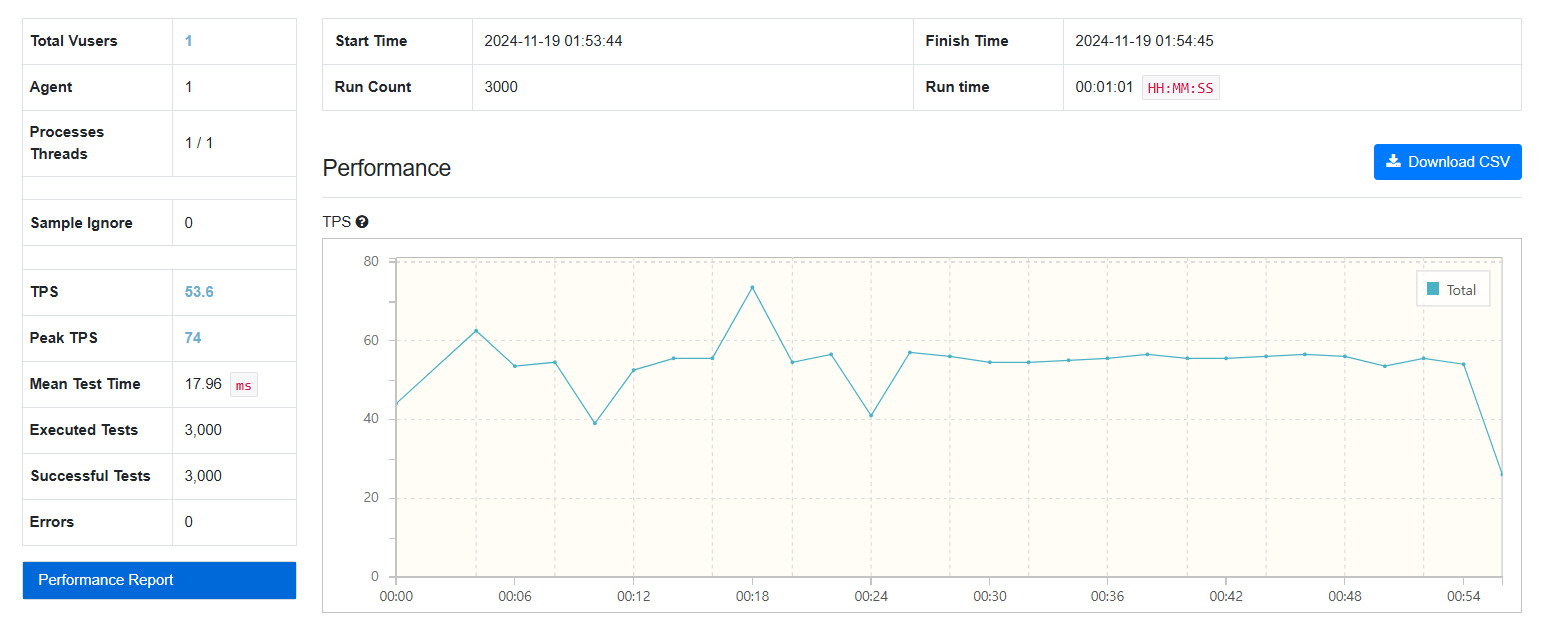
3000건
-
Fetch Join:
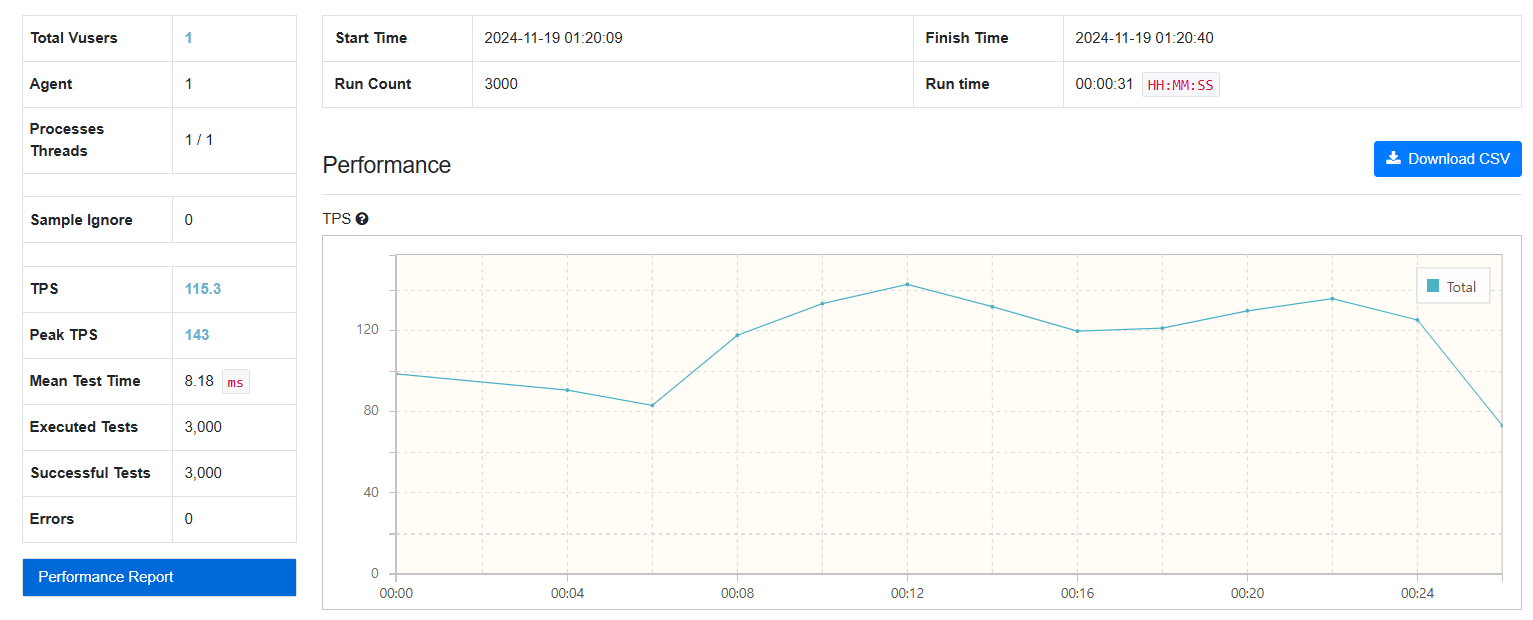
-
컬럼 추출:
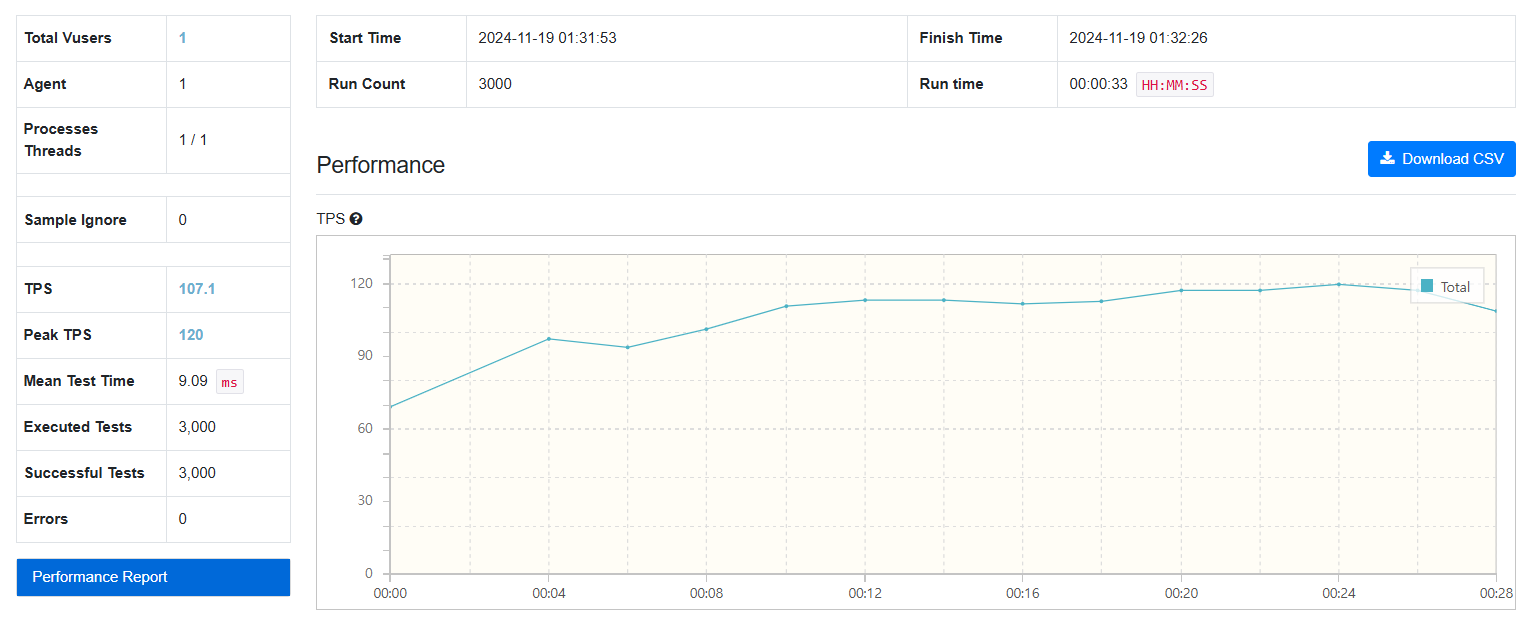
-
FetchType.LAZY:
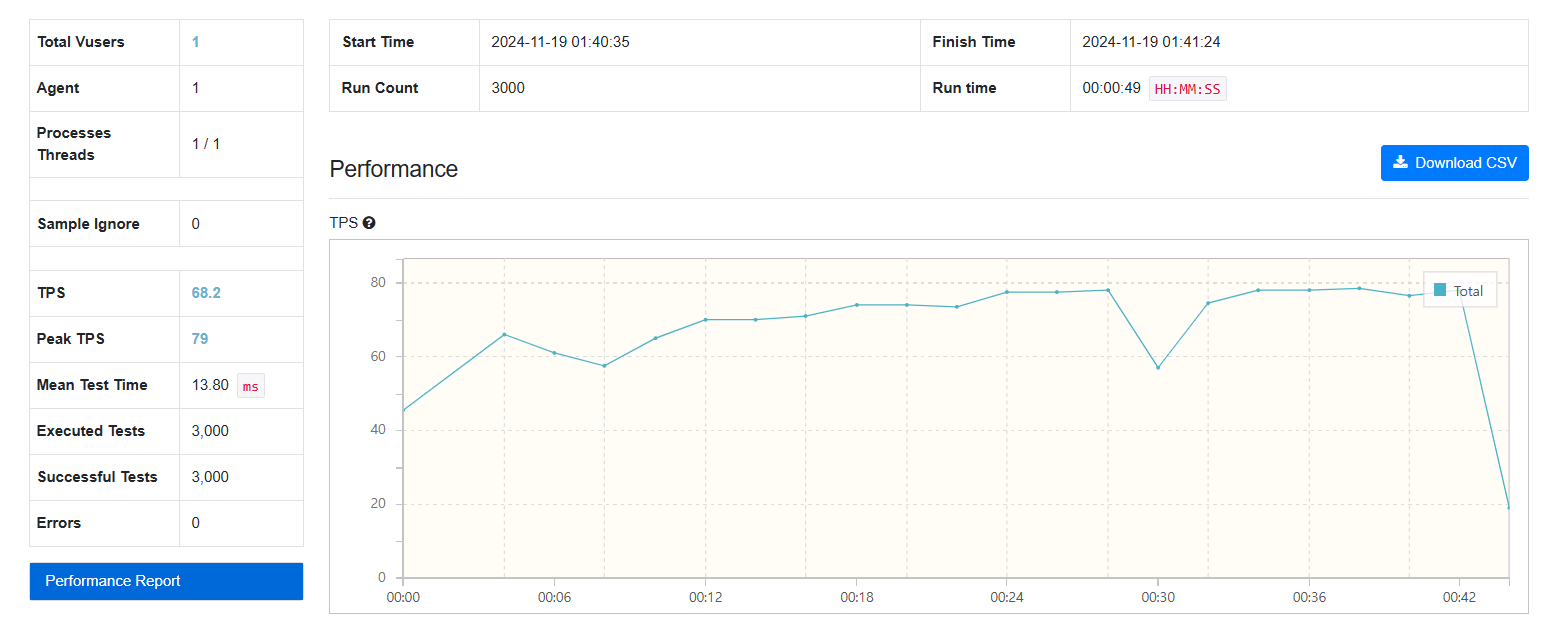
-
FetchType.EAGER:
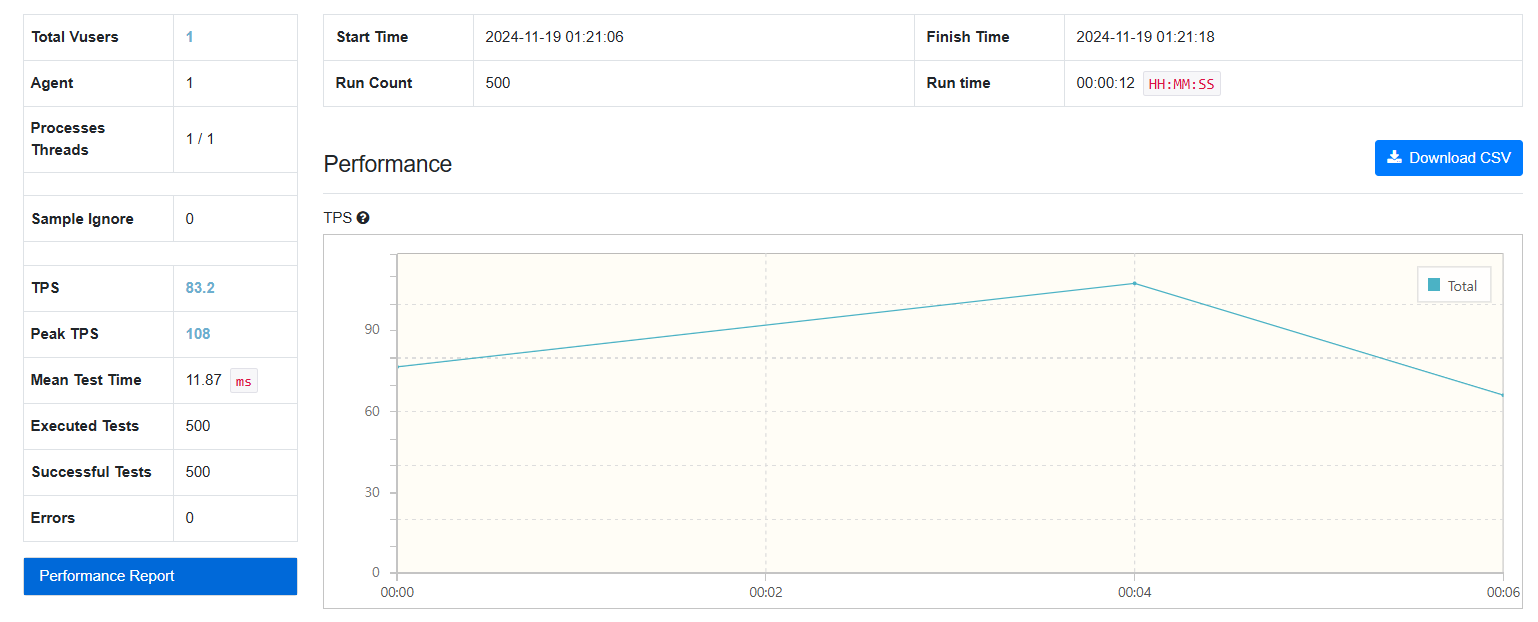
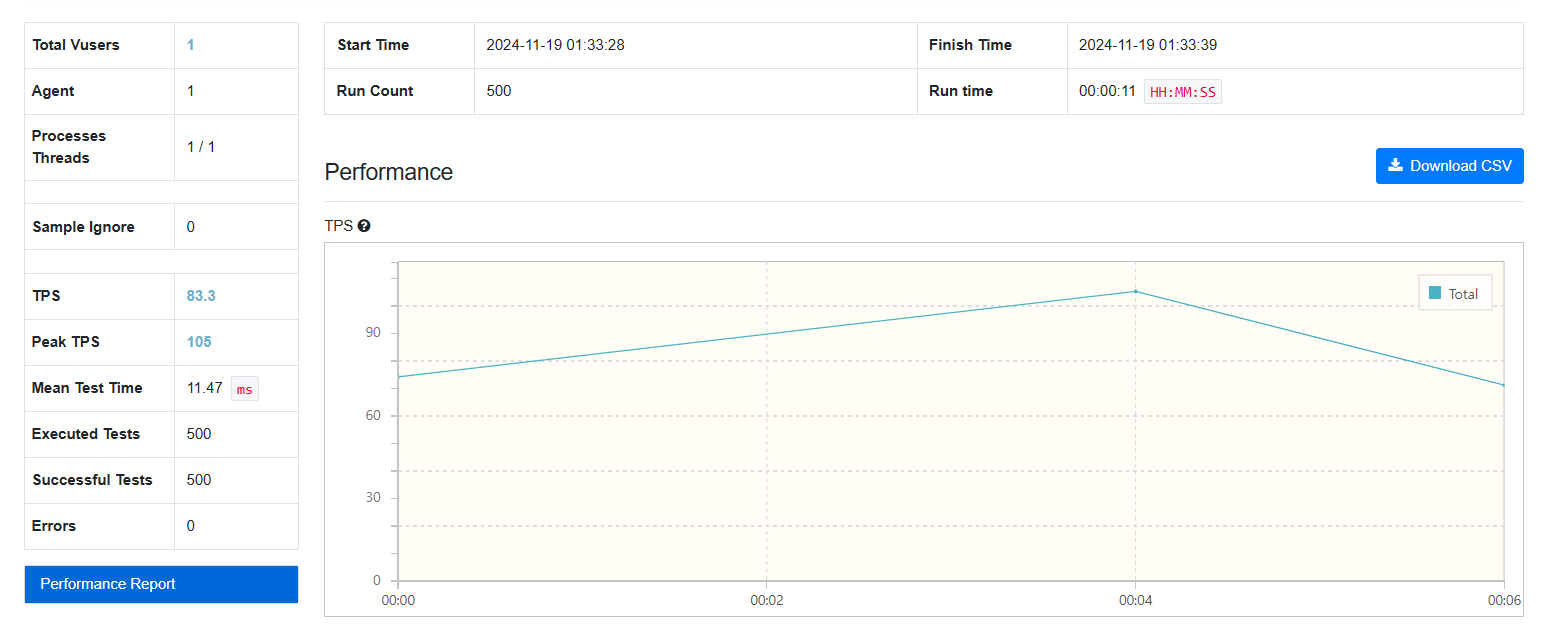
500건
-
Fetch Join:
-
컬럼 추출:
-
FetchType.LAZY:
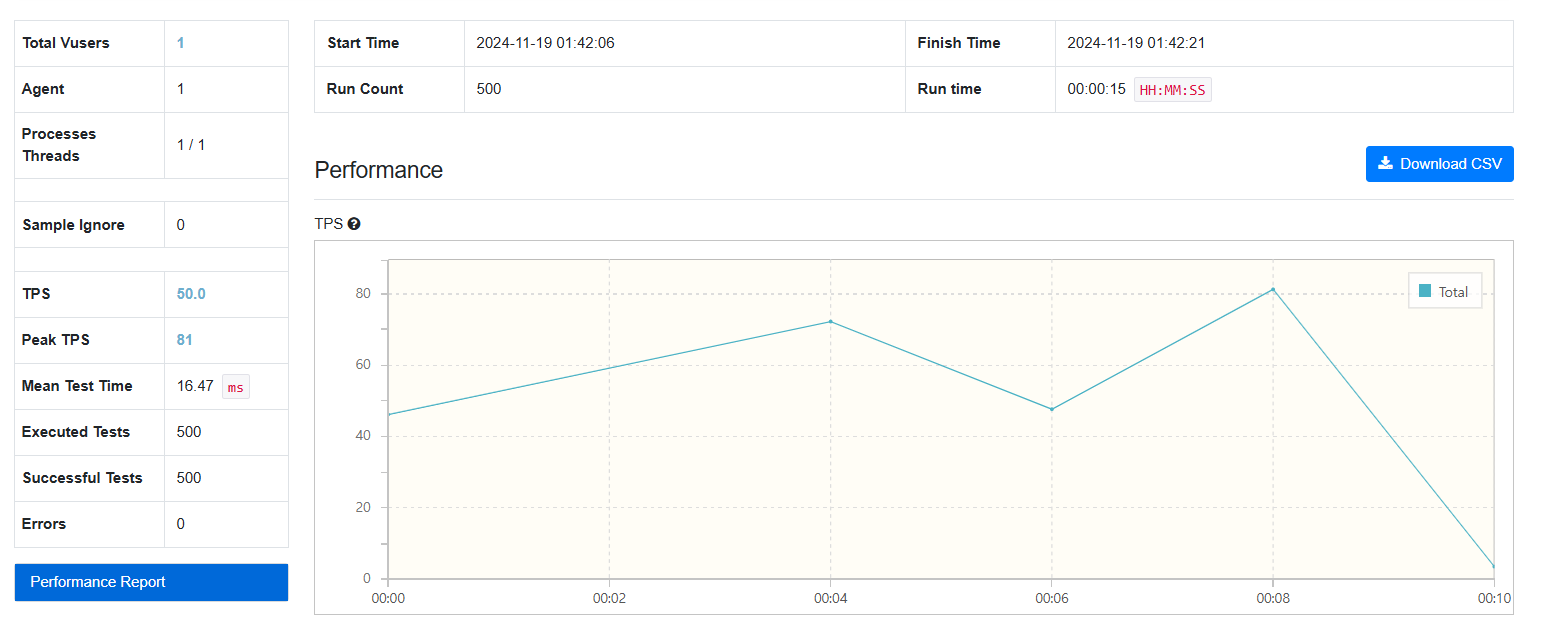
-
FetchType.EAGER: