1. 다음 중 데이터베이스에 대한 설명으로 적합하지 않은 것은?
① 프로그램에서 데이터를 저장하고 관리하면 데이터를 유지하기에 불편하다
② 중복된 데이터의 발생을 최소화 할 수 있다
③ 최적화된 자료구조에 의해서 데이터를 효율적으로 관리할 수 있다
④ 서로 다른 운영체제 및 프로그램에서 요청해도 일괄적인 방법으로 접근가능하다
⑤ 프로그램과 데이터는 물리적으로 같은 컴퓨터에서 관리하는 것이 좋다
해설 :
프로그램과 데이터를 같은 컴퓨터에서 관리하는 것은 데이터베이스에서 권장되지 않는다. 이유는 다음과 같다.
-
보안 문제: 프로그램과 데이터를 같은 컴퓨터에서 관리하면 보안 위험이 증가
-
확장성 문제: 프로그램과 데이터를 같은 컴퓨터에서 관리하면 확장성 문제가 발생할 수 있다. 데이터베이스가 커질 경우, 성능 저하와 같은 문제가 발생할 수 있다.
-
유지보수 문제: 프로그램과 데이터를 같은 컴퓨터에서 관리하면 유지보수에 어려움이 있다. 프로그램이 업그레이드되거나 변경될 경우, 데이터에 영향을 주는 위험이 있기 때문이다.
따라서, 데이터베이스에서는 보안, 확장성, 유지보수 등을 고려하여 프로그램과 데이터를 분리하여 관리하는 것이 권장된다.
2. 다음 중 oracle 데이터베이스의 자료형에 대한 설명으로 적합하지 않은 것은?
① NUMBER - 정수 및 실수 자료형을 처리한다
② VARCHAR2 - 가변 길이 문자열 자료형을 처리한다
③ CHAR - 단일 글자 자료형을 처리한다
④ DATE - 기본적인 날짜를 처리한다
⑤ BLOB - Binary Large Object, 바이너리 대용량 객체를 처리한다
해설 :
CHAR 자료형은 고정 길이 문자열 자료형을 처리한다
3. 다음 오라클 제약조건 중 옳지 않은 것은?
① NOT NULL - NULL을 허용하지 않는다. 값 입력이 필수이다
② UNIQUE - 중복된 값을 허용하지 않는다
③ PRIMARY KEY - NULL을 허용하지 않고, 중복된 값을 허용한다
④ FOREIGN KEY - 다른 테이블의 PRIMARY KEY 혹은 UNIQUE 컬럼을 참조한다
⑤ DEFAULT - 데이터 입력이 없을 경우 기본값을 지정한다
해설 :
PRIMARY KEY 제약조건은 NULL 값을 허용하지 않으며, 중복된 값을 허용하지 않는다.
PRIMARY KEY는 테이블에서 각 레코드를 고유하게 식별하는데 사용된다.
4. 다음 명령어 중 DML에 해당하지 않는 것을 고르세요
① INSERT
② SELECT
③ CREATE
④ UPDATE
⑤ DELETE
해설 :
DML(Data Manipulation Language)은 데이터를 검색, 삽입, 수정, 삭제 등을 포함한 데이터 조작 작업을 수행하는 언어를 말한다. INSERT, SELECT, UPDATE, DELETE 등이 대표적인 DML 명령어이다.
CREATE은 DDL (Date Manipulation Language)에 해당된다. DDL은 데이터베이스의 스키마, 테이블, 인덱스 등의 개체를 정의하거나 조작하는 명령어를 말한다. CREATE은 새로운 테이블, 뷰, 인덱스 등을 생성할 때 사용된다.
5. 아래와 같은 관계형 데이터베이스의 테이블에서, 20세 이상 남성의 데이터만 불러오기 위한 SQL 문을 작성하세요
TABLE : MEMBER
| MEMBERID | NAME | AGE | GENDER |
|---|---|---|---|
| 20201215-0001 | 이지은 | 30 | 여성 |
| 20201215-0002 | 홍진호 | 41 | 남성 |
| 20201215-0003 | 이수현 | 24 | 여성 |
| 20201216-0001 | 고은아 | 33 | 여성 |
| 20201216-0002 | 이찬혁 | 27 | 남성 |
| 20201215-0003 | 윤후 | 15 | 남성 |
| 20201216-0003 | 김강훈 | 12 | 남성 |
SELECT * FROM MEMBER
WHERE age >= 20 AND gender = '남성';
6. 다음 집계함수에 대한 설명으로 옳지 않은 것은?
① AVG – 평균을 구한다
② COUNT – 순번을 구한다
③ MAX – 최대값을 구한다
④ MIN – 최소값을 구한다
⑤ SUM – 합계를 구한다
해설 :
COUNT 함수는 특정 컬럼에 포함된 데이터의 개수를 반환하는 집계함수. 순번을 반환하는 기능은 ROW_NUMBER() 함수와 같은 윈도우 함수를 사용해야 한다.
7. 다음은 오라클 시퀀스를 작성하는 구문이다. 빈칸에 알맞은 내용으로 짝지어진 것은?
create sequence member_seq
start with 10000
㉠____ 999999999
㉡_ by 1
nocache
nocycle
① ㉠ maxvalue, ㉡ increment
② ㉠ foreign key, ㉡ increments
③ ㉠ maxvalue, ㉡ minvalue
④ ㉠ foreign key, ㉡ connect
⑤ ㉠ end with, ㉡ connect
8. 다음은 서로 다른 두 개의 테이블을 조인하는 구문이다. 빈 칸에 들어갈 내용으로 알맞은 것은?
select
city as 도시,
count(department_name) as 부서
from departments D
join locations L
____ D.location_id = L.location_id
group by city;
① where
② case
③ having
④ on
⑤ then
해설 :
JOIN 구문에서 두 테이블을 연결할 때는 일치하는 행을 찾기 위해 조인 조건을 명시해야 한다. 이때, ON 절을 사용하여 두 테이블 간의 공통된 컬럼을 기준으로 조인한다.
※ 다음은 어떤 개발 동아리의 회원 정보를 저장하는 테이블이다.
테이블의 이름은 STUDENT2 이며, 각 컬럼은 이름, 나이, 성별, 노트북의 브랜드 입니다
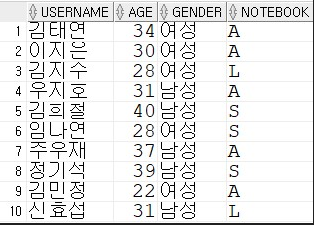
-
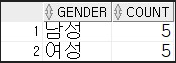
아래의 테이블의 정보를 바탕으로 성별에 따른 인원수를 출력하는 SQL을 작성하세요
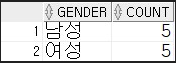
SELECT gender, conut(*) as count FROM student2
GROUP BY gender
ORDER BY gender; -
아래 테이블의 정보를 바탕으로, 성별에 따른 각 브랜드별 노트북 수량을 출력하는 SQL을 작성하세요
(단, 나이가 20살 ~ 39살인 사람만 대상으로 하며, 각 브랜드의 수량은 APPLE, SAMSUNG으로 출력합니다)
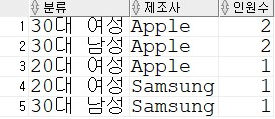
select
case
when age between 20 and 29 and gender = '여성' then '20대 여성'
when age between 30 and 39 and gender = '여성' then '30대 여성'
when age between 30 and 39 and gender = '남성' then '30대 남성'
end as 분류,
case
when notebook like '%A%' then 'Apple'
when notebook like '%S%' then 'Samsung'
end as 제조사,
count(*) as 인원수
from student2
where age between 20 and 39 and (gender = '여성' OR gender = '남성')
and (notebook like '%A%' or notebook like '%S%')
group by
case
when age between 20 and 29 and gender = '여성' then '20대 여성'
when age between 30 and 39 and gender = '여성' then '30대 여성'
when age between 30 and 39 and gender = '남성' then '30대 남성'
end,
case
when notebook like '%A%' then 'Apple'
when notebook like '%S%' then 'Samsung'
end
order by 인원수 desc, 제조사 ;
