1. DB
ORM
object relation matching
자료 독립 어떤 프로그램으로도 자료를 조회할 수 있음
장점
데이터의 논리적 독립성
데이터의 물리적 독립성
데이터의 무결성 유지
데이터 중복성 최소화(아예 엇진 않음)
관계형 데이터 베이스를 가장 많이씀(관계 있는 애들만 데이터를 불러옴)
2. DBMS
my sql 만든 회사가 나가섯 mari.db를 만듬
mysql
정의
조작기능 데이터를 검색.갱신, 삽입, 삭제 등을 지원
제어기능 : 데이터의 정확성과 안정성을 유지하는 기능
우리는 주로 조작어를 배우를거임
3. dm,

이부분이 암호화를 해도 털릴때 있음
객체는 변수와 기능(속성만 남고) 이것들 끼리 관계를 맺음
DB를 만들때는
계획 분석 설계 구현 시험 유지 보수 의 과정을 거치는게 좋음
1. 데이터 모델링
현실세계의 있는걸 컴퓨터로 옮기는 과정
개념적 구조 > 논리적 구조 > (물리적 구조) 일단 논리적까지만 생각
DB설계
개념적 설계
데이터를 구조화 정형화 시키기 위해 추상적인 개념으로 표현하는 과정
E - R다이어그램이라는 그림을 그림
논리적 설계
그림을 토대로 만듬
릴레이션 스키마 ( 표)
name age
sjb 12
lsth 123데이터 타입 ,:숫자나 글자 길이도 잇음
제약조건등을 걸어줌
2. 관계 데이터 모델
릴레이션 : 정보 저장의 형태가 2차원 구조의 테이블
속성 : 테이블의 각 열을 의미
튜플 : 테이블의 한 행을 구서하는 속성들의 집합
도메인 : 속성이 취할 수 있는 값들의 집합
기수 : 튜플의 수 cardinality
차수 : 속성의 수 degree
3. 릴레이션의 특징
특정 릴레이션은 오직 하나의 레코드 타입만 저장
하나의 속성내의 값들은 같은 유형
속성들의 순서는 중요하지 않음
각 속성의 이름은 한 릴레이션 내에서만 고유함
한 릴레이션에 동일한 이름의 애트리뷰트가 두개이상 존재할 수 없음
다른 릴레이션에서는 존재 가능
릴레이션에서 동일한 튜플이 두개 이상 존재하지 않음
한 튜플의 각 속성은 원자값을 가짐
값에 리스트나 집합 등은 허용되지 않음
원자값이란?
ex) 속성은 list 안됨
kim 20 movie,song,soccer 이런식으로 여러개 x
kim 20 movie
kim 20 song 이렇게 따로 저장해야함
여러값을 가지면 여러번 저장해야함
4. 키의 종류
개체끼리 관계를 만들때 키로 관계를 맺어줌
1 슈퍼키 : 유일성은갖지만, 최소성을만족시키지 못하는 속성의 집합
2 후보키 : 기본키의 후보
3 기본키 : 개체식별자,
4 대체키 : 기본키를 제외한 후보키
5 외래키 : 다른테이블을 참조하는데 사용되는 속성
참조했기 때문에 다른테이블에서 값이 바뀌면 알아서 수정됨
최소성은 유일성을 만족시켜줘야하기 때문에
이때 필요한 최소 속성의 수
하나로 안되면 두개를 묶어서
5. 관계 데이터 제약
개체 무결성 : 기본릴레이션의 기본키를 구성하는 어떤 속성도 null과 중복을 허용 x
참조무결성 : 외래키 값은 null이거나 참조하는 릴레이션에 있는 기본키이다.
도메인 무결성 : 특정 속성의 값은 그 속성에 정의된 대로의 값만 허용한다.
6. 사상
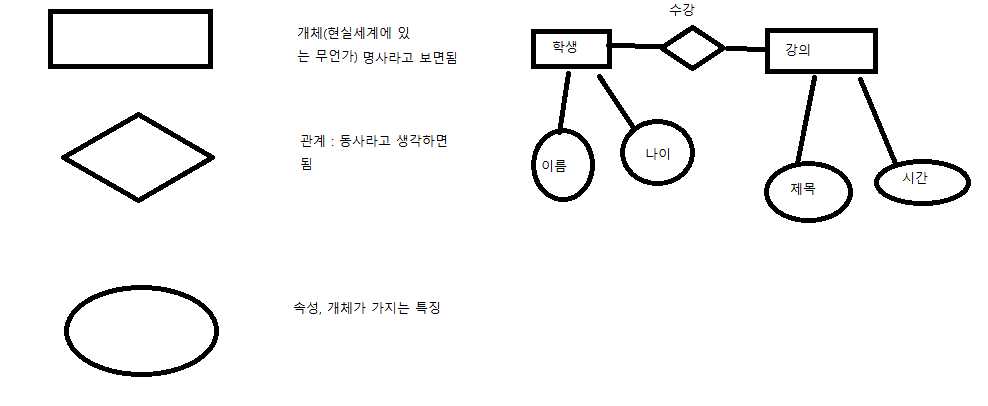
개체(네모)는 하나의 릴레이션(표)로 변환
다대다 관계 : 하나의 릴레이션으로 표현
ex)
학생 과목을 여러개 수강할 수 있다.
과목은 여러학생이 수강할 수 있다.
다대다 새로운 릴레이션 형성
이름 나이 학생 과목 강사 과목
aa 20 aa 파이썬 김 파이썬
bb 21 bb 파이썬 최 DB
일대다 관계 : 다쪽에다가 외래키 속성으로 표현
ex)
학생은 여러 휴대폰을 수 있다.
핸드폰은 하나의 주인 가질 수 있다.
핸드폰 번호 핸드폰 번호 소유자
삼성 1234 삼성 1234 aa
삼성 1234 --> 삼성 1234 aa
애플 1123 애플 1123 aa
애플 1331 애플 1331 bb
소유자라는 외래키를 추가
일대일 관계 : 외래키 속성으로 표현
ex)
남편은 한 명의 부인만 있다.
부인은 한 명의 남편만 있다.
외래키가 어디있어도 상관 없음
다중값 속성은 다른 릴레이션으로 변환
이름 나이 취미 이름 나이 취미 이름
김 20 영화 김 20 영화 김
김 20 노래 --> 김 20 & 노래 김
이 20 축구 이 20 축구 이
이렇게 하면 한번에 데이터를 추가할때 기존에는 이름 나이 취미 3개를 썼어야 했지만 취미 이름 2개만 추가하면 됨
7. 정규화
이상 문제를 해결하기 위해 테이블을 쪼개는것
이상의 종류
삽입 : 데이터를 저장할때 원하지 않는 정보가 함께 저장된 경우
삭제 : 튜플을 삭제함으로써 유지되어야 하는 정보까지도 삭제됨
갱신 : 중복된 튜플 중 일부의 속성만 갱신시킴으로써 정보의 모순성 발생
정규화 과정을 하려면 함수적 종속을 알아야함
함수적 종속 : x로 인해 y값이 정해져 버림 어떤 송석이 다른 속성을 정해버림
ex)
나이는 주민등록번호에 종속되어있음
97년생은 26
98년생은 25
정규화 과정
제 1 정규형 : 도메인이 원자값(값이 하나만 있는것)이 아닌 것을 원자값으로 변환
제 2 정규형 : 부분 함수 종속 제거
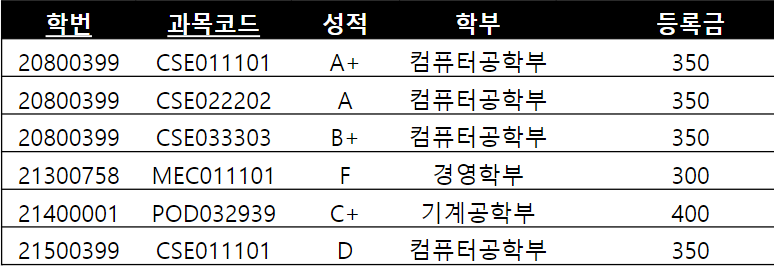
에서 학번과 과목코드는 성적을 결정하고
학번은 학부를 정한다 즉 두개가 겹치기 때문에 이를 나눠줘야 한다.
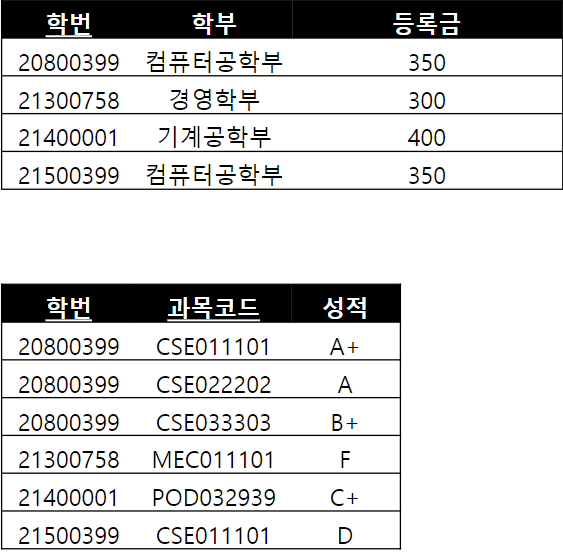
제 3 정규형 : 이행 함수 종속 제거
a가 b를 결정하는데 b가 c를 결정하는 것을 의미
학번이 학부를 결정하고 학부가 등록금을 결정
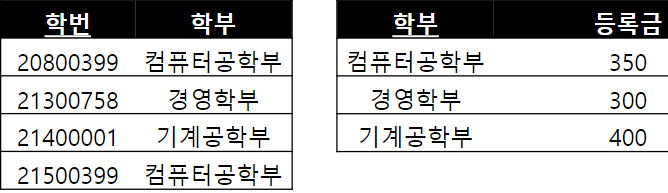
웬만하면 123 과정에서 다 됨
이거 안되면
BCNF : 결정자 중 후보키가 아닌 것들은 제거
제 4 정규형 : 다치 종속 제거
제 5 정규형 : 조인 종속성 제거 해야함
8. SQL
데이터를 어떻게 저장할지 형식이나 값 변경등이 해당
데이터 정의언어(DDL)
create alter drop(표를 아예 지우기)
데이터 조작언어(DML)
sql은 끝날때 ; 세미콜론이 필수
mysql 워크 벤치 사용법
create DATABASE ex01; 데이터 베이스 ex01을 생성
use ex01; 앞으로 ex01을 사용하겠다.
create table student ( table student를 생성
sname varchar(10) primary key,
age integer
);
create table lecture (
idx integer auto_increment,
lname varchar(50),
ltime int,
primary key (idx)
);
create table lecture_student (
idx integer,
sname varchar(15),
foreign key(idx) references lecture(idx),
foreign key(sname) references student(sname)
);
create table phonenumber (
phonenumber integer,
pname varchar(15),
foreign key (pname) references student(sname)
);
create table phonenumber_student (
sname varchar(15),
phonenumber integer,
foreign key(sname) references student(sname)
);
insert into student values (
'student01', 10
);
insert into student (sname) values ('student02');
insert into lecture (lname, ltime) values ('파이썬', 10);
insert into lecture (lname, ltime) values ('DB', 8);
select * from lecture;
select sname from student;
update student set sage = 20 where sname = 'student01';
delete from student where sname = 'student01';
alter table student add gender varchar(1);
alter table student drop gender;
alter table student rename column age to sage;
alter table student modify sname varchar(15);
DROP table phonenumber;
drop database ex01;다른 데이터 import하기
sql워크벤치 server탭에서 data import
import from self contained file import하고싶은 파일
use employees;
select * from employees where emp_no < 10011 and ;
select * from employees
where gender = 'M';
select * from employees
where last_name = 'Butner' and gender = 'M';
select * from employees
where birth_date > '1955-01-01';
select *, count(last_name) from employees
where last_name = 'Butner' group by last_name;
group by 는 뒤의 변수로 묶어서 하겠다라는 의미
여기서는 count를 하기위해 묶음join을 통해 다른테이블에 있는 변수를 한번에 보여주기
join의 종류
join : 두 테이블중 겹치는것을 출력
left join : 두 테이블중 왼쪽은 다 출력하고 두 테이블중 일치하는 값만 추가해서 출력
right join : 두 테이블 중 오른쪽은 다 출력하고 일치하는 값만 추가해서 출력
select last_name, salary From employees
inner join salaries
on employees.emp_no = salaries.emp_no ; ORM 객체 관계 매핑
