
[목차]
- Java의 특징
- JVM의 역할
- Java의 컴파일 과정
- Java에서 제공하는 원시 타입들에 무엇이 있고, 각각 몇 비트를 차지하나
- 오버라이딩(Overriding)과 오버로딩(Overloading)에 대해 설명
- 객체지향 프로그래밍(OOP)에 대해 설명
- try-with-resources에 대해 설명
- 불변 객체가 무엇인지 설명하고 대표적인 Java의 예시를 설명
- 참조 타입일 경우 추가적인 작업은 어떤게 있는지 설명
- 불변 객체나 final을 굳이 사용해야 하는 이유가 있을까
- 추상 클래스와 인터페이스를 설명해주시고, 차이에 대해 설명
- 싱글톤 패턴에 대해 설명
- 싱글톤 패턴의 대표적인 예시를 간단하게 설명
- 가비지 컬렉션(Garbage Collection)에 대해 설명
- 가비지 컬렉션 과정에 대해 설명
- 객체지향의 설계원칙에 대해 설명
- 자바의 메모리 영역에 대해 설명
- 각 메모리 영역이 할당되는 시점은 언제인가
- 클래스와 객체에 대해 설명해
- 생성자(Constructor)에 대해 설명
- Wrapper Class란 무엇이며, Boxing과 UnBoxing은 무엇인지 설명
- Synchronized에 대해 아는 대로
- new String()과 리터럴("")의 차이에 대해 설명
- String, StringBuffer, StringBuilder의 차이를 설명
- String 객체가 불변인 이유에 대해 아는대로 설명
- 접근 제한자(Access Modifier)에 대해 설명
- 클래스 멤버 변수 초기화 순서에 대해 설명
- static에 대해 설명
- static을 사용하는 이유에 대해 설명
- Inner Class(내부 클래스)의 장점에 대해 설명
- 리플렉션(Reflection)이란 무엇인지 설명
- 리플렉션은 어떤 경우에 사용되는지 설명
- Error와 Exception의 차이를 설명
- CheckedException과 UnCheckedException의 차이를 설명
- Optional API에 대해 설명
- 컬렉션 프레임워크에 대해 설명
- List, Set, Map, Stack, Queue의 특징에 대해 설명
- Set과 Map의 타입이 Wrapper Class가 아닌 Object를 받을 때 중복 검사는 어떻게 할건지 설명
- Vector와 List의 차이를 설명
- 제네릭에 대해 설명해주시고, 왜 쓰는지
- final / finally / finalize 의 차이를 설명
- 직렬화(Serialize)에 대해 설명
- SerialVersionUID를 선언해야 하는 이유에 대해 설명
JVM의 특징
Java는 객체지향 프로그래밍 언어이다.
기본 자료형을 제외한 모든 요소들이 객체로 표현되고, 객체 지향 개념의 특징인 캡슐화, 상속, 다형성이 잘 적용된 언어이다.
장점
JVM(자바가상머신) 위에서 동작하기 때문에 운영체제에 독립적이다.
GabageCollector를 통한 자동적인 메모리 관리가 가능하다.
단점
JVM 위에서 동작하기 때문에 실행 속도가 상대적으로 느리다.
다중 상속이나 타입에 엄격하며, 제약이 많다.
Java의 역할
JVM은 스택 기반으로 동작하며, Java Byte Code를 OS에 맞게 해석 해주는 역할을 하고 가비지컬렉션을 통해 자동적인 메모리 관리를 해준다.
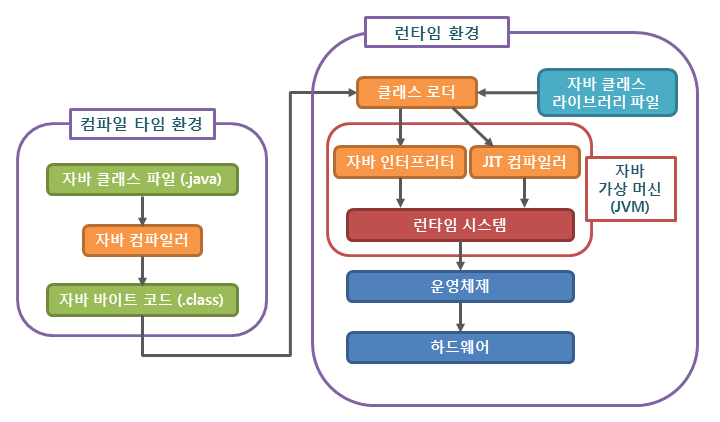
Java의 컴파일 과정
- 개발자가 .java 파일을 생성한다.
- build를 한다.
- java compiler의 javac의 명령어를 통해 바이트코드(.class)를 생성한다.
- Class Loader를 통해 JVM 메모리 내로 로드한다.
- 실행엔진을 통해 컴퓨터가 읽을 수 있는 기계어로 해석된다.(각 운영체제에 맞는 기계어)
Java에서 제공하는 원시 타입들에 무엇이 있고, 각각 몇 비트를 차지하나
- 정수형 byte, short, int, long (1, 2, 4, 8 Byte)
- 실수형 float, double (4, 8 Byte)
- 문자형 char (2 Byte)
- 논리형 boolean이 (1 Byte)
오버라이딩(Overriding)과 오버로딩(Overloading)에 대해 설명
- 오버라이딩(Overriding)은 상위 클래스에 있는 메소드를 하위 클래스에서 재정의 하는 것
- 오버로딩(Overloading)은 매개변수의 개수나 타입을 다르게 하여 같은 이름의 메소드를 여러 개 정의하는 것
객체지향 프로그래밍(OOP)에 대해 설명
우리가 실생활에서 쓰는 모든 것을 객체라 하며, 객체 지향 프로그래밍은 프로그램 구현에 필요한 객체를 파악하고 상태와 행위를 가진 객체를 만들고 각각의 객체들의 역할이 무엇인지를 정의하여 객체들 간의 상호작용을 통해 프로그램을 만드는 것을 말합니다.
즉, 기능이 아닌 객체가 중심이며 "누가 어떤 일을 할 것인가?"가 핵심
특징으로는 캡슐화, 상속, 다형성, 추상화 등이 있고, 모듈 재사용으로 확장 및 유지보수가 용이합니다.
try-with-resources에 대해 설명
- try-with-resources는 try-catch-finally의 문제점을 보완하기 위해 나온 개념입니다.
- try( ... ) 안에 자원 객체를 전달하면, try블록이 끝나고 자동으로 자원 해제 해주는 기능을 말합니다.
- 따로 finally 구문이나 모든 catch 구문에 종료 처리를 하지 않아도 되는 장점이 있습니다.
- try-with-resources 알아보기
불변 객체가 무엇인지 설명하고 대표적인 Java의 예시를 설명
- 불변 객체는 객체 생성 이후 내부의 상태가 변하지 않는 객체를 말합니다.
- Java에서는 필드가 원시 타입인 경우 final 키워드를 사용해 불변 객체를 만들 수 있고,
- 참조 타입일 경우엔 추가적인 작업이 필요합니다.
1. 참조 타입일 경우 추가적인 작업은 어떤게 있는지 설명
참조 타입은 대표적으로
1.객체를 참조할 수도 있고, 2.배열이나 3.List 등을 참조할 수 있습니다.
-
참조 변수가 일반 객체인 경우 객체를 사용하는 필드의 참조 변수도 불변 객체로 변경해야 합니다.
-
배열일 경우 배열을 받아 copy해서 저장하고, getter를 clone으로 반환하도록 하면 됩니다. (배열을 그대로 참조하거나, 반환할 경우 외부에서 내부 값을 변경할 수 있음. 때문에 clone을 반환해 외부에서 값 변경하지 못하게 함)
-
리스트인 경우에도 배열과 마찬가지로 생성시 새로운 List를 만들어 값을 복사하도록 해야 합니다.
배열과 리스트는 내부를 복사하여 전달하는데, 이를 방어적 복사(defensive-copy)라고 합니다.
2. 불변 객체나 final을 굳이 사용해야 하는 이유가 있을까
불변 객체나 final 키워드를 사용해 얻는 이점은 다음과 같습니다.
-
Thread-Safe하여 병렬 프로그래밍에 유용하며, 동기화를 고려하지 않아도 된다. (공유 자원이 불변이기 때문에 항상 동일한 값을 반환하기 때문)
-
실패 원자적인 메소드를 만들 수 있다.
(어떠한 예외가 발생되더라도 메소드 호출 전의 상태를 유지할 수 있어 예외 발생 전과 똑같은 상태로 다음 로직 처리 가능) -
부수효과를 피해 오류를 최소화 할 수 있다.
※ 부수효과 : 변수의 값이 바뀌거나 객체의 필드 값을 설정하거나 예외나 오류가 발생하여 실행이 중단되는 현상 -
메소드 호출 시 파라미터 값이 변하지 않는다는 것을 보장할 수 있다.
-
가비지 컬렉션 성능을 높일 수 있다.
(가비지 컬렉터가 스캔하는 객체의 수가 줄기 때문에 Gc 수행 시 지연시간도 줄어든다.)
추상 클래스와 인터페이스를 설명해주시고, 차이에 대해 설명
-
추상 클래스는 클래스 내 추상 메소드가 하나 이상 포함되거나 abstract로 정의된 경우를 말하고,
-
인터페이스는 모든 메소드가 추상 메소드로만 이루어져 있는 것을 말합니다.
-
공통점
- new 연산자로 인스턴스 생성 불가능
- 사용하기 위해서는 하위 클래스에서 확장/구현 해야 한다.
-
차이점
- 인터페이스는 그 인터페이스를 구현하는 모든 클래스에 대해 특정한 메소드가 반드시 존재하도록 강제함에 있고,
- 추상클래스는 상속받는 클래스들의 공통적인 로직을 추상화 시키고, 기능 확장을 위해 사용한다.
- 추상클래스는 다중상속이 불가능하지만, 인터페이스는 다중상속이 가능하다.
싱글톤 패턴에 대해 설명
- 싱글톤 패턴은 단 하나의 인스턴스를 생성해 사용하는 디자인 패턴입니다.
- 인스턴스가 1개만 존재해야 한다는 것을 보장하고 싶은 경우와
- 동일한 인스턴스를 자주 생성해야 하는 경우에 주로 사용합니다. (메모리 낭비 방지)
- 싱글톤 패턴(Singleton Pattern)알아보기
싱글톤 패턴의 대표적인 예시를 간단하게 설명
싱글톤 패턴의 대표적인 예시는 Spring Bean 입니다.
스프링의 빈 등록 방식은 기본적으로 싱글톤 스코프이고, 스프링 컨테이너는 모든 빈들을 싱글톤으로 관리합니다.
스프링은 요청할 때마다 새로운 객체를 생성해서 반환하는 기능도 제공한다.
(프로토타입 빈, @Scope("prototype"))
가비지 컬렉션(Garbage Collection)에 대해 설명
- 가비지 컬렉션은 JVM의 메모리 관리 기법 중 하나로 시스템에서 동적으로 할당됐던 메모리 영역 중에서 필요없어진 메모리 영역을 회수하여 메모리를 관리해주는 기법입니다.
가비지 컬렉션 과정에 대해 설명
GC의 작업을 수행하기 위해 JVM이 어플리케이션의 실행을 잠시 멈추고, GC를 실행하는 쓰레드를 제외한 모든 쓰레드들의 작업을 중단 후 (Stop The World 과정) 사용하지 않는 메모리를 제거(Mark and Sweep 과정)하고 작업이 재개됩니다.
++ GC의 작업은 Young 영역에 대한 Minor GC와 Old 영역에 대한 Major GC로 구분됩니다.
객체지향의 설계원칙에 대해 설명
-
SRP - 단일 책임 원칙
한 클래스는 하나의 책임만 가져야 한다. -
OCP - 개방-폐쇄 원칙
확장에는 열려있고, 수정에는 닫혀있어야 한다. -
LSP - 리스코프 치환 원칙
상위 타입은 항상 하위 타입으로 대체할 수 있어야 한다. -
ISP - 인터페이스 분리 원칙
인터페이스 내에 메소드는 최소한 일수록 좋다.
(하나의 일반적인 인터페이스보다 여러 개의 구체적인 인터페이스가 낫다.) SRP와 같은 문제에 대한 두 가지 다른 해결책이다. -
DIP - 의존관계 역전 원칙
구체적인 클래스보다 상위 클래스, 인터페이스, 추상클래스와 같이 변하지 않을 가능성이 높은 클래스와 관계를 맺어라. DIP 원칙을 따르는 가장 인기 있는 방법은 의존성 주입(DI)이다.
자바의 메모리 영역에 대해 설명
-
자바의 메모리 공간은 크게 Method 영역, Stack 영역, Heap 영역으로 구분되고, 데이터 타입에 따라 할당됩니다.
-
메소드(Method) 영역
전역변수와 static변수를 저장하며, Method영역은 프로그램의 시작부터 종료까지 메모리에 남아있다. -
스택(Stack) 영역
지역변수와 매개변수 데이터 값이 저장되는 공간이며, 메소드가 호출될 때 메모리에 할당되고 종료되면 메모리가 해제된다. LIFO(Last In First Out) 구조를 갖고 변수에 새로운 데이터가 할당되면 이전 데이터는 지워진다. -
힙 (Heap) 영역
new 키워드로 생성되는 객체(인스턴스), 배열 등이 Heap 영역에 저장되며, 가비지 컬렉션에 의해 메모리가 관리되어 진다.
각 메모리 영역이 할당되는 시점은 언제인가
- Method 영역 : JVM이 동작해서 클래스가 로딩될 때 생성
- Stack 영역 : 컴파일 타임 시 할당
- Heap 영역 : 런타임시 할당
※ 컴파일 타임 : 소스코드가 기계어로 변환되어 실행가능한 프로그램이 되는 과정
※ 런타임 : 컴파일 타임 이후 프로그램이 실행되는 때
클래스와 객체에 대해 설명해
클래스는 객체를 만들어내기 위한 설계도 혹은 틀 이라고 할 수 있고, 객체를 생성하는데 사용합니다.
- 객체는 설계도(클래스)를 기반으로 생성되며, 자신의 고유 이름과 상태, 행동을 갖습니다.
- 여기서 상태는 필드(fields), 행동은 메소드(Method)라고 표현합니다.
- 객체에 메모리가 할당되어 실제로 활용되는 실체는 '인스턴스'라고 부릅니다.
생성자(Constructor)에 대해 설명
생성자는 클래스와 같은 이름의 메소드로, 객체가 생성될 때 호출되는 메소드입니다.
- 명시적으로 생성자를 만들지 않아도 default로 만들어지며, 생성자는 파라미터를 다르게하여 오버로딩할 수 있습니다.
Wrapper Class란 무엇이며, Boxing과 UnBoxing은 무엇인지 설명
- 기본 자료형(Primitive data type)에 대한 객체 표현을 Wrapper class라고 합니다.
- 기본 자료형 → Wrapper class로 변환하는 것을 Boxing이라 하며,
- Wrapper class → 기본 자료형으로 변환하는 것을 UnBoxing이라 합니다.
- Wrapper클래스란?
Synchronized에 대해 아는 대로
-
여러 개의 쓰레드가 한 개의 자원을 사용하고자 할 때, 현재 데이터를 사용하고 있는 쓰레드를 제외하고 나머지 쓰레드들은 데이터에 접근할 수 없게 막는 개념입니다.
-
데이터의 thread-safe를 하기 위해 자바에서 Synchronized 키워드를 제공해 멀티 쓰레드 환경에서 쓰레드간 동기화를 시켜 데이터의 thread-safe를 보장합니다.
-
Synchronized는 변수와 메소드에 사용해서 동기화 할 수 있으며, Synchronized 키워드를 남발하게 되면 오히려 프로그램의 성능저하를 일으킬 수 있습니다.
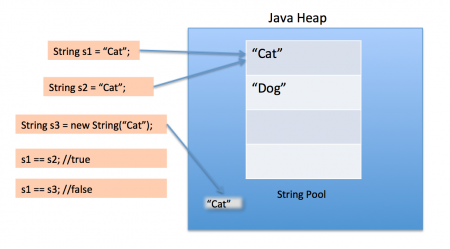
new String()과 리터럴("")의 차이에 대해 설명
- new String()은 new 키워드로 새로운 객체를 생성하기 때문에 Heap 메모리 영역에 저장되고,
- ""는 Heap 안에 있는 String Constant Pool 영역에 저장됩니다.
String, StringBuffer, StringBuilder의 차이를 설명
- String은 불변의 속성을 가지며, StringBuffer와 StringBuilder는 가변의 속성을 가집니다.
- StringBuffer는 동기화를 지원하여 멀티 쓰레드 환경에서 주로 사용하며,
- StringBuilder는 동기화를 지원하지 않아 싱글 쓰레드 환경에서 주로 사용합니다.
- String, StringBuffer, StringBuilder의 차이와 장단점
String 객체가 불변인 이유에 대해 아는대로 설명
1. 캐싱 기능에 의한 메모리 절약과 속도 향상
- Java에서 String 객체들은 Heap의 String Pool 이라는 공간에 저장되는데, 참조하려는 문자열이 String Pool에 존재하는 경우 새로 생성하지 않고 Pool에 있는 객체를 사용하기 때문에 특정 문자열 값을 재사용하는 빈도가 높을 수록 상당한 성능 향상을 기대할 수 있다.
2. thread-safe
- String 객체는 불변이기 때문에 여러 쓰레드에서 동시에 특정 String 객체를 참조하더라도 안전하다.
3. 보안기능
- 중요한 데이터를 문자열로 다루는 경우 강제로 해당 참조에 대한 문자열 값을 바꾸는 것이 불가능하기 때문에 보안에 유리하다.
접근 제한자(Access Modifier)에 대해 설명
- 변수 또는 메소드의 접근 범위를 설정해주기 위해서 사용하는 Java의 예약어를 의미하며, 총 4 가지 종류가 있습니다.
- public - 접근 제한이 없다. (같은 프로젝트 내 어디서든 사용 가능)
- protected - 해당 패키지 내, 다른 패키지에서 상속받아 자손 클래스에서 접근 가능하다.
- (default) - 해당 패키지 내에서만 접근 가능
- private - 해당 클래스에서만 접근 가능
클래스 멤버 변수 초기화 순서에 대해 설명
- static 변수 선언부 : 클래스가 로드 될 때 변수가 제일 먼저 초기화 된다.
- 필드 변수 선언부 : 객체가 생성될 때 생성자 block 보다 앞서 초기화 된다.
- 생성자 block : 객체가 생성될 때 JVM이 내부적으로 locking( thread-safe 영역 )
static에 대해 설명
-
static 키워드를 사용한 변수나 메소드는 클래스가 메모리에 올라갈 때 자동으로 생성되며 클래스 로딩이 끝나면 바로 사용할 수 있습니다. 즉, 인스턴스(객체) 생성 없이 바로 사용 가능합니다.
-
모든 객체가 메모리를 공유한다는 특징이 있고, GC 관리 영역 밖에 있기 때문에 프로그램이 종료될 때까지 메모리에 값이 유지된 채로 존재하게 됩니다.
static을 사용하는 이유에 대해 설명
-
static은 자주 변하지 않는 값이나 공통으로 사용되는 값 같은 공용자원에 대한 접근에 있어서 매번 메모리에 로딩하거나 값을 읽어들이는 것보다 일종의 '전역변수'와 같은 개념을 통해 접근하는 것이 비용도 줄이고 효율을 높일 수 있습니다.
-
인스턴스 생성 없이 바로 사용 가능하기 때문에 프로그램 내에서 공통으로 사용되는 데이터들을 관리할 때 이용합니다.
Inner Class(내부 클래스)의 장점에 대해 설명
- 내부 클래스에서 외부 클래스의 멤버에 손쉽게 접근할 수 있다.
- 서로 관련 있는 클래스를 논리적으로 묶어서 표현함으로써, 캡슐화를 증가시키고, 코드의 복잡성을 낮출 수 있다.
- 외부에서는 내부 클래스에 접근할 수 없으므로, 코드의 보안성을 높일 수 있다.
리플렉션(Reflection)이란 무엇인지 설명
리플렉션이란 구체적인 클래스 타입을 알지 못해도 그 클래스의 메소드, 타입, 변수들에 접근할 수 있도록 해주는 자바 API
리플렉션은 어떤 경우에 사용되는지 설명
코드를 작성할 시점에는 어떤 타입의 클래스를 사용할지 모르지만, 런타임 시점에 지금 실행되고 있는 클래스를 가져와서 실행해야 하는 경우 사용됩니다.
프레임워크나 IDE에서 이런 동적인 바인딩을 이용한 기능을 제공합니다. intelliJ의 자동완성 기능, 스프링의 어노테이션이 리플렉션을 이용한 기능이라 할 수 있습니다.
Error와 Exception의 차이를 설명
-
Error는 실행 중 일어날 수 있는 치명적 오류를 말합니다. 컴파일 시점에 체크할 수 없고, 오류가 발생하면 프로그램은 비정상 종료되며 예측 불가능한 UncheckedException에 속합니다.
-
반면, Exception은 Error보다 비교적 경미한 오류이며, try-catch를 이용해 프로그램의 비정상 종료를 막을 수 있습니다.
CheckedException과 UnCheckedException의 차이를 설명
- CheckedException은 실행하기 전에 예측 가능한 예외를 말하고, 반드시 예외 처리를 해야 합니다.
- 대표적인 Exception - IOException, ClassNotFoundException 등
- 대표적인 Exception - IOException, ClassNotFoundException 등
- UncheckedException은 실행하고 난 후에 알 수 있는 예외를 말하고, 따로 예외처리를 하지 않아도 됩니다.
- 대표적인 Exception - NullPointerException, ArrayIndexOutOfBoundException 등
- 대표적인 Exception - NullPointerException, ArrayIndexOutOfBoundException 등
- RuntimeException은 UncheckedException을 상속한 클래스이고, RuntimeException이 아닌 것은 CheckedException을 상속한 클래스 입니다.
- CheckedException, UnCheckedException
Optional API에 대해 설명
개발할때 가장 많이 발생하는 예외 중 하나가 NPE(NullPointerException)입니다.
NPE를 피하려면 null 여부 검사를 필연적으로 하게 되는데 만약 null 검사를 해야하는 변수가 많은 경우 코드가 복잡해지고 번거롭습니다. 하지만 Java8 부터 Optional을 제공하여 null로 인한 예외가 발생하지 않도록 도와주고, Optional 클래스의 메소드를 통해 null을 컨트롤 할 수 있습니다.
컬렉션 프레임워크에 대해 설명
-
다수의 데이터를 쉽고 효과적으로 관리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미합니다.
-
자바 컬렉션에는 List, Set, Map 인터페이스를 기준으로 여러 구현체가 존재하고, 이에 더해 Stack, Queue 인터페이스도 존재합니다.
List, Set, Map, Stack, Queue의 특징에 대해 설명
- List는 순서가 있는 데이터의 집합이며, 데이터의 중복을 허용합니다.
대표적인 구현체로는 ArrayList가 있고, 이는 Vector를 개선한 것입니다. 이외에도 LinkedList 등의 구현체가 있습니다.- Vector, ArrayList, LinkedList, Stack, Queue
- Vector, ArrayList, LinkedList, Stack, Queue
- Set은 순서가 없는 데이터의 집합이며, 데이터의 중복을 허용하지 않습니다. 대표적인 구현체로는 HashSet이 있고, 순서를 보장하기 위해서는 LinkedHashSet을 사용합니다. (Map의 key-value 구조에서 key 대신 value가 들어가 value를 key로 하는 자료구조)
- HashSet, LinkedHashSet, TreeSet
- HashSet, LinkedHashSet, TreeSet
- Map은 키와 값이 한 쌍으로 이뤄져 있고, 키를 기준으로 중복을 허용하지 않으며, 순서가 없습니다. key의 순서를 보장하기 위해서는 LinkedHashMap을 사용합니다.
- HashMap, TreeMap, HashTable, Properties
- HashMap, TreeMap, HashTable, Properties
- Stack 객체는 직접 new 키워드로 사용할 수 있으며, Queue 인터페이스는 LinkedList에 new 키워드를 적용해 사용할 수 있습니다.
Set과 Map의 타입이 Wrapper Class가 아닌 Object를 받을 때 중복 검사는 어떻게 할건지 설명
hashCode() 메소드를 오버라이딩하여 리턴된 해시코드 값이 같은지를 보고 해시코드 값이 다르다면 다른 객체로 판단하고, 해시코드 값이 같으면 equals() 메소드를 오버라이딩하여 다시 비교합니다. 이 두 개가 모두 맞으면 중복 객체입니다.
Vector와 List의 차이를 설명
-
벡터는 데이터 삽입시 원소를 밀어내지만 리스트는 노드를 연결만 하기 때문에, 삽입 삭제 부분에서 리스트가 시간복잡도의 우위를 가집니다.
-
벡터는 랜덤부분접근이 가능하지만 리스트는 더블링크드리스트(노드가 양쪽으로 연결)로 되어있기 때문에 랜덤 접근이 되지 않습니다. 검색적인 측면에서는 벡터가 우위에 있습니다.
-
벡터는 리스트와 달리 항상 동기화되는 장점이자 단점을 가지고 있습니다. 멀티 쓰레드 환경에서 안전하게 객체를 추가하고 삭제할 수 있지만, 단일쓰레드 환경 일때도 동기화를 하기 때문에 List보다 성능이 떨어집니다.
제네릭에 대해 설명해주시고, 왜 쓰는지
-
제네릭은 데이터의 타입을 하나로 지정하지 않고 사용할 때마다 범용적이고 포괄적으로 지정한다는 의미입니다.
-
제네릭 타입을 사용함으로써 잘못된 타입이 사용될 수 있는 문제를 컴파일 과정에서 제거할 수 있어 에러를 사전에 방지할 수 있습니다.
final / finally / finalize 의 차이를 설명
- final은 클래스, 메소드, 변수, 인자를 선언할 때 사용할 수 있으며, 한 번만 할당하고 싶을 때 사용합니다.
- final 변수는 한 번 초기화되면 그 이후에 변경할 수 없습니다.
- final 메소드는 다른 클래스가 이 클래스를 상속할 때 메소드 오버라이딩을 금지합니다.
- final 클래스는 다른 클래스에서 이 클래스를 상속할 수 없습니다.
-
finally는 try-catch와 함께 사용되며, try-catch가 종료될 때 finally block이 항상 수행되기 때문에 마무리 해줘야 하는 작업이 존재하는 경우에 해당하는 코드를 작성해주는 코드 블록입니다.
-
finalize는 Object 클래스에 정의되어 있는 메소드이며, GC에 의해 호출되는 메소드로 절대 호출해서는 안되는 메소드입니다. GC가 발생하는 시점이 불분명하기 때문에 해당 메소드가 실행된다는 보장이 없고, finalize() 메소드가 오버라이딩 되어 있으면 GC가 이루어질 때 바로 Garbage Collectiong 되지 않습니다. GC가 지연되면서 OOME(Out of Memory Exception)이 발생할 수 있기 때문에 finalize() 메소드를 오버라이딩하여 구현하는 것을 권장하지 않고 있습니다.
직렬화(Serialize)에 대해 설명
-
시스템 내부에서 사용되는 객체 또는 데이터를 외부의 시스템에서도 사용할 수 있도록 바이트(byte) 형태로 데이터 변환하는 기술이며, 반대로 직렬화된 바이트 형태의 데이터를 다시 객체로 변환하는 과정을 '역직렬화'라고 합니다.
-
(간단히) JVM의 메모리에 상주(힙 or 스택)되어 있는 객체 데이터를 바이트 형태로 변환하는 기술
SerialVersionUID를 선언해야 하는 이유에 대해 설명
-
JVM은 직렬화와 역직렬화를 하는 시점의 클래스에 대한 버전 번호를 부여하는데, 만약 그 시점에 클래스의 정의가 바뀌어 있다면 새로운 버전 번호를 할당하게 됩니다. 그래서 직렬화할 때의 버전 번호와 역직렬화를 할 때의 버전 번호가 다르면 역직렬화가 불가능하게 될 수 있기 때문에 이런 문제를 해결하기 위해 SerialVersionUID를 사용합니다.
-
만약 직렬화할 때 사용한 SerialVersionUID의 값과 역직렬화 하기 위해 사용했던 SVUID가 다르다면 InvalidClassException이 발생할 수 있다.
출처 : https://dev-coco.tistory.com/153