RDBMS
RDBMS는 Related DataBase Management System 의 약자로서 관계형 데이터베이스 관리 시스템을 의미한다.
DB2, Sybase, Oracle, Mysql, MariaDB, PostgreSQL 등의 DB가 RDBMS에 속하며, 현재는 Mysql, MariaDB, PostgreSQL 세가지가 범용적으로 제일 많이 사용되는 추세이다.
(SQL 구문 표준을 가장 잘지키고 있는 DB는 Postgre라고 알려져있다.)
RDBMS는 엑셀과 매우 유사하다. 모든 데이터는 고정된 주소(Address)를 가진다. 엑셀에서는 데이터의 주소를 A4, B3, F5 등으로 표현한다. RDBMS에서는 데이터의 종류를 나타내는 Column (행)과 Row(열)번호로 주소를 표현한다.
엑셀에는 Sheet기능이 있는 것을 알것이다. Sheet 마다 새로운 엑셀 필드를 제공해준다. RDBMS에서는 이 시트지 하나를 Table(테이블) 이라고 부르며, 이러한 시트지를 모아둔 하나의 엑셀파일(.xlsx)를 RDBMS에서는 Database(데이터베이스) 라고 부른다. 여러 엑셀파일들을 읽고, 수정하고, 삭제하고, 데이터를 삽입하는 프로그램은 Microsoft Excel 프로그램이나, Polaris Office의 Excel, MacOS의 Numbers 등이 대표적이다. 이와 같은 프로그램이 RDBMS가 되는 것이다.
Table(테이블)
테이블은 하나의 데이터베이스의 자료집합의 단위이다. 테이블은 다음과 같은 구성을 가진다.
| - | Column1 | Column2 |
|---|---|---|
| Row1 | Data1-1 | Data1-2 |
| Row2 | Data2-1 | Data2-2 |
엑셀과 똑같지 않은가? 하나의 Row를 RDBMS에서는 Record(레코드) 라고 얘기한다. 엑셀과 매우 유사하지만, 엑셀과 명확한 차이를 보이는 부분이 존재한다. 엑셀에서 데이터의 타입을 정하는 부분은 존재한다. 가령 서식..?(숫자를 화폐단위로 바꿔줌, 숫자를 날짜 데이터로 바꿔줌) 하지만, 이를 어긴다고해서 엑셀에 데이터 삽입을 못하진 않는다. 하지만, RDBMS는 정해진 데이터 타입 외에는 삽입 자체가 불가능하다. 또한, 엑셀처럼 데이터의 크기에 제한이 없는것이 아니라 데이터 크기에 제한이 존재한다.
위의 설명과 같은 특징을 가지는 테이블의 속성을 바로 Schema(스키마) 라고 얘기한다. 정확히 얘기하자면 다음과 같은 정의를 가진다.
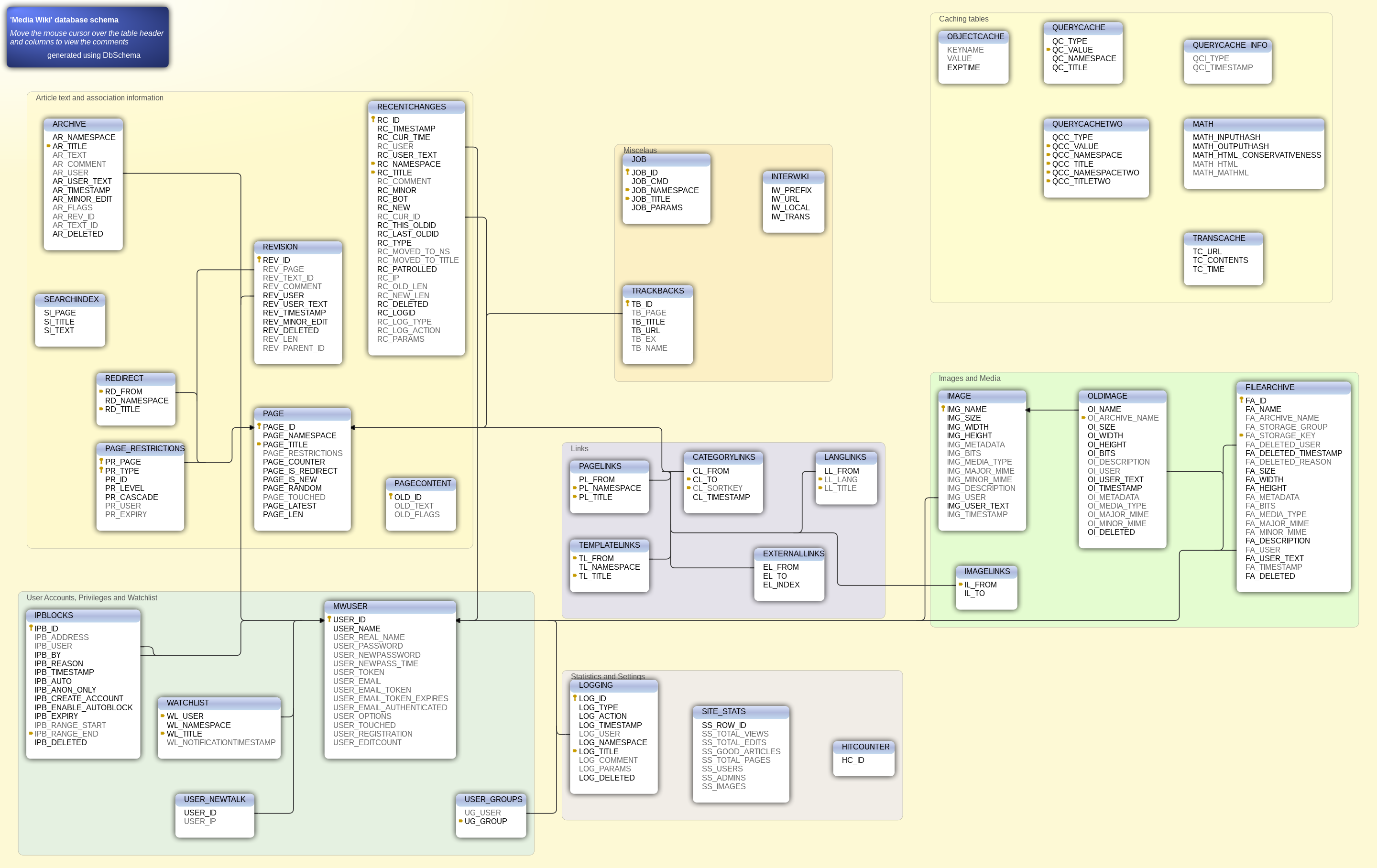
[컴퓨터 과학에서 데이터베이스 스키마(database schema)는 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조이다. 데이터베이스 관리 시스템(DBMS)이 주어진 설정에 따라 데이터베이스 스키마를 생성하며, 데이터베이스 사용자가 자료를 저장, 조회, 삭제, 변경할 때 DBMS는 자신이 생성한 데이터베이스 스키마를 참조하여 명령을 수행한다.] - 출처 https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4_%EC%8A%A4%ED%82%A4%EB%A7%88
이 Schema에도 종류가 존재한다. 종류는 총 세가지
-
외부 스키마(External Schema)
외부 스키마는 프로그래머나 사용자의 입장에서 데이터베이스의 모습으로 일부분을 조직의 일부분을 정의한 것을 의미한다. 가령, 위 사진에서 뒷 배경의 색이 다른것을 볼 수 있는데, 이 와 같이 큰 부분으로 나눈 것을 외부 스키마를 정의한다고 한다.
-
내부 스키마(Internal Schema)
내부 스키마는 모든 응용 시스템과 사용자들이 필요로하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의한 것을 의미한다. 예를들어, 위 ERD에서 표같이 생긴(정확히는 엔티티(Entity)라고 한다.)것을 내부 스키마라고 한다. -
개념 스키마(Conceptual Schema)
개념 스키마란, '모든 응용 시스템과 사용자들이 필요로하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의한 것' 이다. 예를들어, 위 ERD에서 각각의 내부 스키마가 선으로 이어진것을 개념 스키마라고 부른다.
테이블은 스키마에 의해 생성되고, 스키마에 의해서 데이터를 삽입 및 삭제 할 수있다. 만약 스키마와 일치하지 않는 쿼리문을 데이터베이스에 요청한다면, 곧바로 데이터베이스는 접근할 수 없음을 나타낼 것이다.
View(뷰)
뷰는 쉽게 말하면 쿼리문을 실행하여 반환된 결과창을 의미한다. 엑셀에서는 필터 기능을 예로 들수 있겠다.
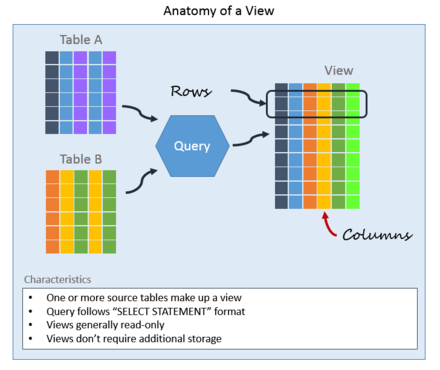
정확히 얘기하면,
[뷰(view)는 관계 데이터베이스의 데이터베이스 언어 SQL에서 하나 이상의 테이블 (또는 다른 뷰)에서 원하는 모든 데이터를 선택하여, 그들을 사용자 정의하여 나타낸 것이다. 관계 데이터베이스의 관계 모델의 관계의 일종인 도출 관계에 해당한다.] - https://ko.wikipedia.org/wiki/VIEW_(SQL)
이다. 보통 SELECT 문을 실행할 때, 이 View를 얻어낼 수 있다. 또는, 사용자가 직접 뷰를 만들어 낼 수도 있다.
CREATE VIEW 뷰이름 AS SELECT 구문;Sequence(시퀀스)
시퀀스는 자동으로 일련번호를 생성해주는 오브젝트이다. 테이블에 데이터를 삽입할 때, 보통의 데이터들은 서로간의 고유한 Primary Key(PK)를 가지게 되는데, 일반적으로 이 PK를 미리 DBMS에 내장된 시퀀스를 이용하여, 자동 순차적으로 숫자를 부여해준다.
특정한 규칙의 시퀀스를 생성하고 싶다면, 다음의 구문을 통해 시퀀스를 생성할 수 있다.
## 존재하는 시퀀스 조회
SELECT * FROM user_sequence;
## 간단 시퀀스 생성(1부터 순차적으로 증가하는 시퀀스 생성)
CREATE SEQUENCE id_seq;
## 구체적인 시퀀스 생성
CREATE SEQUENCE id_seq
INCREMENT BY 1 ---> 1씩 증가
START WITH 1 ---> 초기값 1
MAXVALUE 100 ---> 최대값 100
NOCACHE ---> CACHE 일시는 시퀀스를 캐쉬하여 미리 만들어두고 가져다 쓴다.
NOCYCLE ---> 반복하지 않는다.생성한 시퀀스를 사용하기 위해서는, 새로운 테이블을 생성하거나 기존의 테이블 스키마를 수정할 때, 다음과 같이 시퀀스를 참조하도록 구문을 적어준다.
insert into emp_seq(id, name, day)
values(id_seq.nextval, user, default); >> id_seq.nextval여기서 nextval은 다음 사용가능한 시퀀스부터 부여하겠다는 의미가 된다.
Synonym(동의어)
테이블의 또 다른 별명을 정하는 오브젝트이다. Synonym을 생성하게 되면, 기존의 테이블 명말고도 동의어를 통해 테이블에 접근 할 수 있게 된다.
## 동의어 생성
CREATE SYNONYM 동의어 FOR 테이블 명;
## 또는 동의어 변경
REPLACE SYNONYM 동의어 FOR 테이블 명;Index(인덱스)
인덱스는 DB의 검색 및 조회 속도를 위하여 존재하는 오브젝트이다. 책의 페이지를 Index라고 보면 편하다. Primary Key가 이 Index 오브젝트에 속한다.
상세하게는 네가지 종류의 인덱스가 존재한다.
-
비트맵 인덱스(Bitmap Index)
비트맵 인덱스는 데이터 뭉치를 비트 열(bit array)로 저장하여 이러한 비트맵에 비트 연산을 수행함으로써, 대부분의 질의어에 응답하는 특별한 종류의 인덱스다. -
조밀 인덱스(Dense Index)
데이터베이스에서 조밀 인덱스는 데이터 파일 내의 모든 레코드에 대한 키와 포인터의 쌍을 가진 파일이다. 중복 키를 가진 클러스터드 인덱스에서, 조밀 인덱스는 그러한 키를 가진 첫 번째 레코드를 가리키고 있다. -
희소 인덱스(Sparse Index)
데이터베이스에서 희소 인덱스는 데이터 파일 내의 모든 블록에 대한 키와 포인터의 쌍을 가진 파일이다. 이 파일 내의 모든 키는 정렬된 데이터 파일 내의 블록에 연결된 특정 포인터들과 연계되어 있다. 중복된 키를 가진 클러스터드 인덱스에서 희소 인덱스는 각 블록 내의 가장 빈도가 낮은 검색 키를 지시한다. -
역방향 인덱스(Inverse Index)
역방향 키는 인덱스 내에 들어가기 전에 인덱스는 키 값을 뒤집는다. 예를 들어, 24538 값은 83542값으로 인덱스 내에 저장된다. 키 값을 뒤집는 것은 특히 단일 값으로 새롭게 증가되는 번호순으로 된 인덱스 데이터에 유용하다.
이제, 지루한 기초 RDBMS의 구조는 끝났다.(기초만 끝난 것이다... ㅠㅠ) 다음 글 부터는 DDL, DML, DCL, TCL을 다채롭게 다뤄보도록 하자.
