APM 도입 삽질 일기(Spring Boot Actuator + Prometheus + Grafana)
개요
애플리케이션 성능 모니터링(APM)은 실시간으로 애플리케이션의 성능을 파악하고, 잠재적인 문제를 신속하게 해결하여 전반적인 성능을 향상시키는 데 중요한 역할을 합니다. 비록 트래픽이 거의 없는 토이 프로젝트에서 큰 문제가 발생할 확률은 낮지만, 조만간 부하 테스트를 계획하고 있어 이번 기회에 APM 환경을 구축하기로 결정했습니다.
APM 도구 선택에 있어 고려한 후보는 다음과 같습니다.
- Scouter
- VisualVM
- Grafana
- Pinpoint
최종적으로는 'Spring Boot Actuator + Prometheus + Grafana'의 조합을 선택하였습니다.
이유는 김영한님의 스프링 부트 강의에서 해당 조합이 소개되었기 때문에, 다른 툴들에 비해 상대적으로 참고할 자료가 많았고, Grafana를 개인적으로 사용해 본 경험이 있어 친숙했기 때문입니다.
이번 포스팅은 AWS EC2 인스턴스에 APM 툴을 도입하며 얻은 삽질경험을 기록해 보았습니다.
액추에이터 테스트 진행
우선, Spring Boot Actuator의 의존성을 프로젝트에 추가했습니다.
implementation 'org.springframework.boot:spring-boot-starter-actuator'의존성을 추가하면 설정파일을 통하여 다양한 엔드포인트에 접근할 수 있습니다.
보안상의 이유로 env와 beans 엔드포인트를 사용하지 않도록 설정하였습니다.
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.exclude=env,beans이후 헬스 체크 엔드포인트(/actuator/health)를 통해 정상적으로 작동하는 것을 확인할 수 있습니다.
다음으로, Prometheus에서 Spring Boot Actuator가 제공하는 메트릭을 활용할 수 있도록 하는 의존성을 추가하고 그 기능을 테스트해 보았습니다.
runtimeOnly 'io.micrometer:micrometer-registry-prometheus'엔드포인트(/actuator/prometheus)를 통해 문제 없이 작동하는 것을 확인했습니다.
이제 Prometheus 설치와 설정을 진행해 보겠습니다.
프로메테우스 테스트 진행
Prometheus 서버를 띄울 때는 prometheus.yml 설정 파일이 필요합니다.
기본형은 아래와 같이 생겼습니다.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]scrape_configs 섹션에 Prometheus가 데이터를 수집할 대상을 지정해 주어야 하는데요.
Spring Boot Actuator의 /actuator/prometheus 엔드포인트에서 메트릭을 수집할 것이기 때문에 다음과 같이 설정 파일을 작성하였습니다.
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 추가한 내용
- job_name: "actuator"
metrics_path: '/actuator/prometheus' # 액추에이터의 프로메테우스 메트릭 엔드포인트
scrape_interval: 15s # 15초마다 지표 수집
static_configs:
- targets: ["localhost:8080"] # Spring Boot 애플리케이션의 호스트와 포트이제 이 설정파일을 이용하여 EC2 인스턴스에서 Docker를 통해 Prometheus 서버를 띄워보겠습니다.
검색결과 Prometheus 공식 문서에서 Using Docker 섹션을 찾을 수 있었습니다.
기본형이 아래와 같으므로,
docker run \
-p 9090:9090 \
-v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus위 설정 파일을 /home/ec2-user/ 아래에 복사한 다음 아래와 같이 실행해 주었습니다.
docker run \
-p 9090:9090 \
-v /home/ec2-user/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus서버가 성공적으로 실행되었습니다.
9090 포트에 대한 인바운드 규칙을 보안 그룹에 추가한 후, 프로메테우스 서버 접속 테스트를 진행했습니다. 서버 접속은 정상적으로 이루어졌습니다.
하지만 Spring Boot Actuator의 /actuator/prometheus 엔드포인트에 대한 헬스 체크는 실패하였습니다.
이 문제를 해결하기 위해 많은 고민을 하였는데, 독립적인 컨테이너 환경을 고려하지 않았던게 문제였습니다.
Grafana 서버 까지 띄웠다고 가정하고 현재 상황을 그림으로 표현하면 아래와 같습니다.
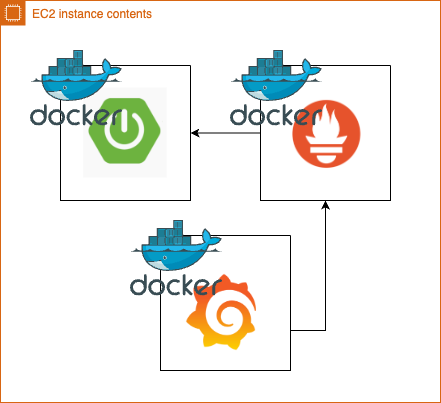
EC2 인스턴스 내에서는 Grafana, Prometheus, 그리고 Spring Boot 애플리케이션이 각각 독립적인 컨테이너로 구동되고 있습니다.
이러한 설정에서는 Spring Boot 애플리케이션의 로컬호스트와 Prometheus 컨테이너의 로컬호스트가 서로 독립적인 환경에 위치해 있기 때문에, Prometheus가 Spring Boot 애플리케이션의 메트릭에 접근하는 것이 불가능 했던 것입니다.
따라서, 아래와 같은 구성이 되도록 만들어줘야 했습니다.
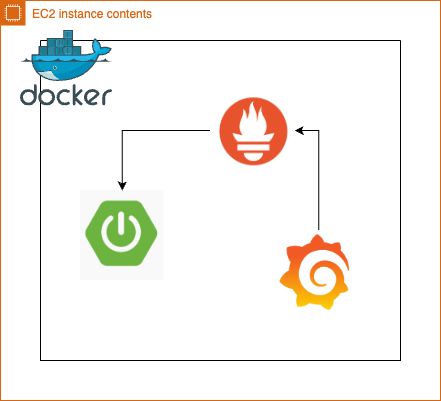
도커 컴포즈를 이용한 컨테이너간 통신문제 해결
Spring Boot 애플리케이션과 Prometheus 서버의 컨테이너간 통신을 위하여 Docker Compose를 작성하였습니다.
version: '3.8'
services:
app:
image: ghcr.io/ber01/lo-gak-gye:latest
ports:
- "80:8080"
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- /home/ec2-user/prometheus.yml:/etc/prometheus/prometheus.ymlDocker Compose를 통해 서비스를 실행한 후, 헬스 체크를 시도했지만 실패했습니다.
$ docker-compose up -d초기에는 Docker Compose 내의 서비스(Spring Boot 애플리케이션, Prometheus 서버)들이 동일한 네트워크 환경에 있어 로컬 호스트를 통한 접근이 가능할 것으로 기대했지만, 이는 도커 컨테이너의 네트워크 동작 방식을 잘 몰랐던 저의 착각이였습니다.
각 서비스는 독립된 컨테이너 내에서 실행 되며, 도커의 브릿지 네트워크를 통해 서로 연결됩니다.
이 때문에 컨테이너 내에서 'localhost'를 사용하면, 해당 컨테이너의 로컬 환경을 가리케 되어 외부 서비스에 접근할 수 없습니다.
이 문제를 해결하기 위해 container_name 속성을 사용하여 서비스에 명확한 이름을 부여했습니다.
version: '3.8'
services:
app:
image: ghcr.io/ber01/lo-gak-gye:latest
container_name: lo-gak-gye
ports:
- "80:8080"
prometheus:
image: prom/prometheus
container_name: prometheus
ports:
- "9090:9090"
volumes:
- /home/ec2-user/prometheus.yml:/etc/prometheus/prometheus.yml그리고 Prometheus 설정 파일에서는 targets를 Docker Compose에서 정의된 컨테이너 이름으로 변경하였습니다.
- job_name: "actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
static_configs:
- targets: ["lo-gak-gye:8080"]다시 Docker Compose를 이용하여 서비스를 실행한 결과 헬스체크에 성공했습니다.
마지막으로 Grafana를 실행할 차례입니다.
그라파나 테스트 진행
Docker Compose를 이용해 Grafana 서버를 구축하고 Prometheus와의 연결을 설정하였습니다.
Grafana도 container_name 속성을 이용하여 서비스의 이름을 부여해 주었습니다.
version: '3.8'
services:
app:
image: ghcr.io/ber01/lo-gak-gye:latest
container_name: lo-gak-gye
ports:
- "80:8080"
prometheus:
image: prom/prometheus
container_name: prometheus
ports:
- "9090:9090"
volumes:
- /home/ec2-user/prometheus.yml:/etc/prometheus/prometheus.yml
grafana:
image: grafana/grafana
container_name: grafana
ports:
- "3000:3000"이후, 3000 포트에 대한 인바운드 규칙을 보안 그룹에 추가한 뒤 admin/admin으로 Grafana 서버에 접속 테스트를 시도하면 성공합니다.
그다음은 Prometheus와 Grafana를 연결해 주어야 하는데요.
아래의 단계를 차근차근 진행하면 됩니다.
여기서도 Docker Compose에서 정의한 container_name 속성을 사용합니다.
하지만 이렇게 Prometheus 설정을 마친 뒤, 컨테이너를 재시작 할 경우 한가지 문제가 발생합니다. 바로 볼륨 설정이 되지 않아 설정이 초기화 된다는 점입니다.
공식 문서를 찾아보니 Use Docker volumes (recommended) 섹션이 있습니다.
docker run -d -p 3000:3000 --name=grafana \
--volume grafana-storage:/var/lib/grafana \
grafana/grafana-enterprise참고하여 아래와 같이 Docker Compose를 변경해 주었습니다.
version: '3'
services:
grafana:
image: grafana/grafana
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana-storage:/var/lib/grafana
volumes:
grafana-storage:다시 한 번, 재실행 한 뒤 Prometheus 설정을 진행하면 이제 컨테이너를 재실행 하더라도 설정 파일이 초기화 되지 않습니다.
이제 마지막으로 대시보드를 설정할 차례입니다.
Grafana는 이미 잘 만들어진 공유 대시보드가 존재하는데요.
저는 Spring Boot 2.1 System Monitor 대시보드를 사용해 보겠습니다.
링크로 들어가서 Copy ID to clipboard를 클릭하여 복사합니다.
+ 버튼을 누른 뒤, Import dashboard 버튼을 눌러 복사한 ID를 붙여넣습니다.
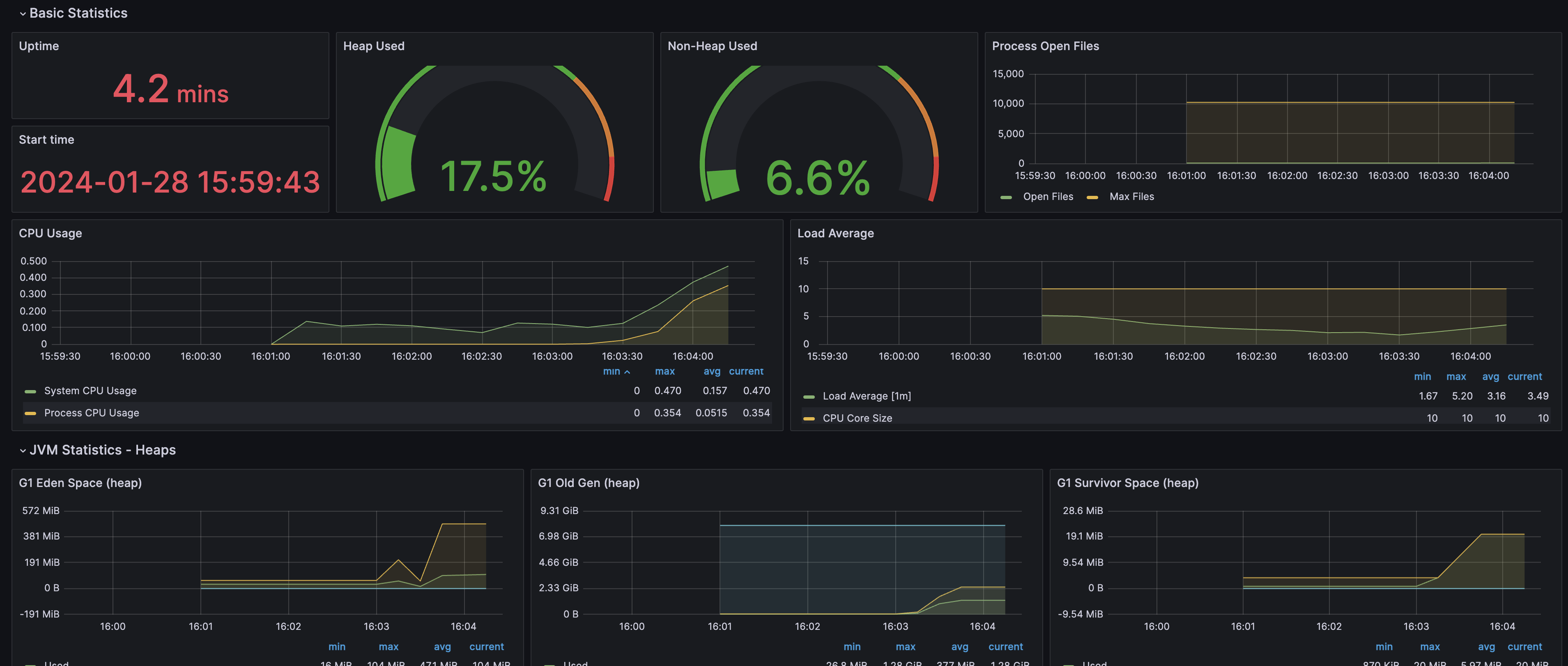
원래라면 아래와 같은 정상적인 대시보드 화면이 출력이 됩니다.
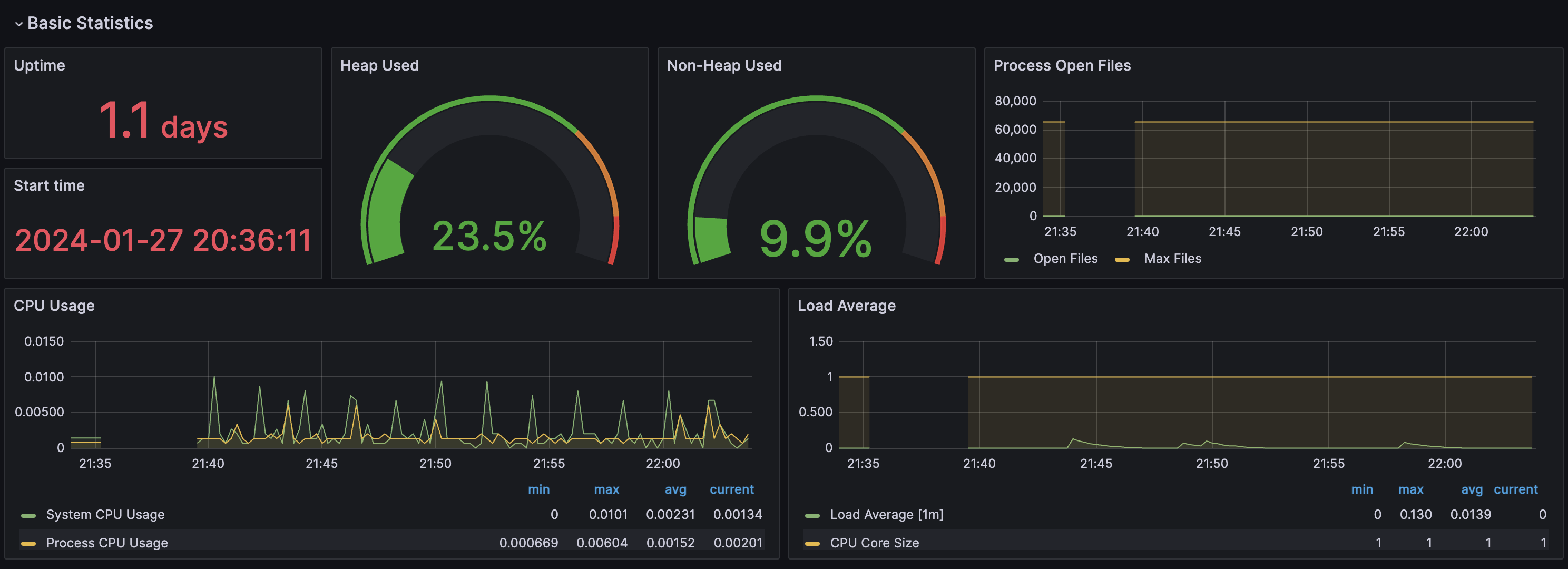
그런데, 대시보드를 추가한 뒤 EC2 인스턴스의 CPU 사용량이 급격히 증가하는 현상을 목격했습니다.
CPU 사용률 100%가 보이시나요?
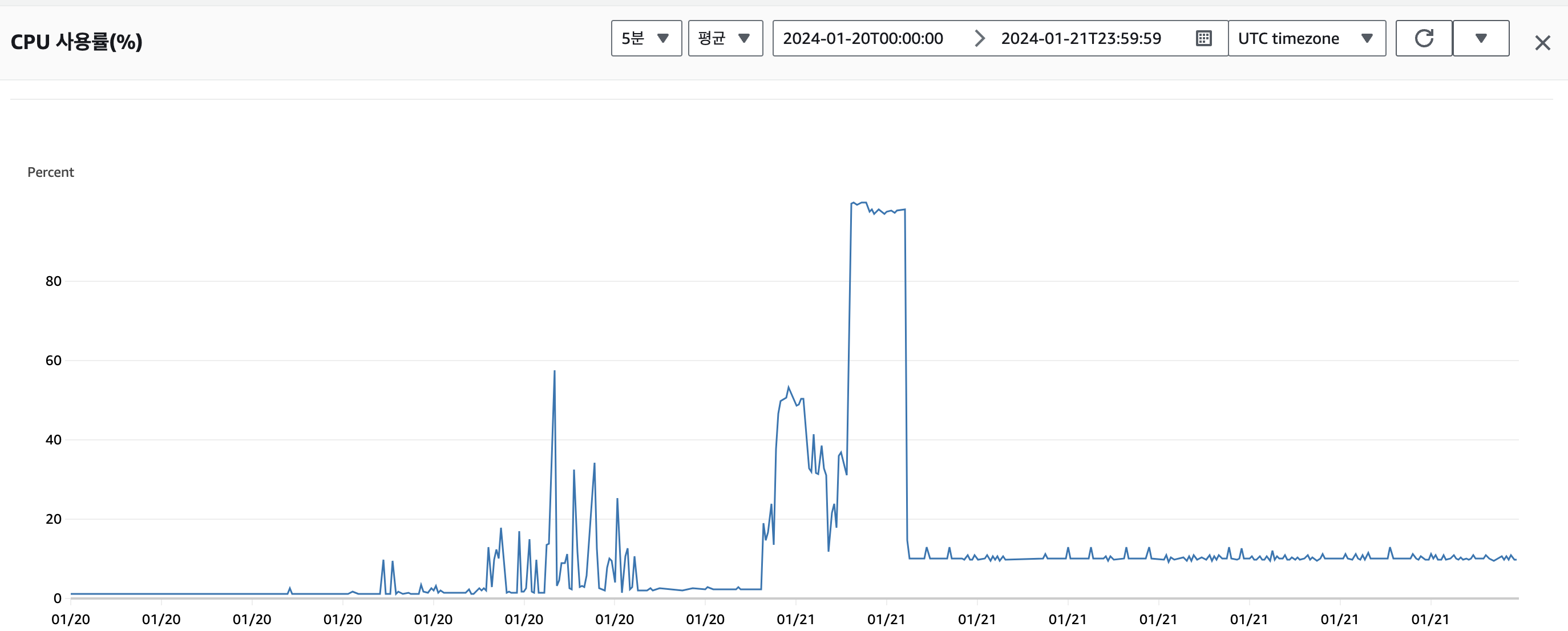
평소 CPU 사용량이 2%를 넘지 않았던 인스턴스가 지속적인 부하를 받으며 성능 저하를 일으키더니 이내 명령어 조차 쳐지지 않아 인스턴스를 재부팅 하여 문제를 임시로 해결하였습니다.
위와 같은 상황이 벌어지는 이유는 모니터링 환경을 구성함에 따라 시스템 리소스에 영향을 많이 끼쳤기 때문인데요.
프리티어 t2.mciro의 성능은 메모리 1GiB의 아름다운 성능으로 메모리 스왑을 하더라도 2GiB로 한정적입니다.
GPT한테 물어보고 다른 개발자 분들과 이야기를 해 본 결과 그라파나를 사용할 거면 최소 2GB 정도의 메모리 양이 필요하다는 결론이 나왔는데, 메모리 스왑도 하지 않은 1GiB의 서버에 너무 가혹한 짓을 하고 있었습니다. (여담으로 핀포인트는 16GB가 필요하다고 합니다.)
아무래도 모니터링 환경 때문에 실제 운영 서버가 영향을 받는 일이 없어야 할 터이니 서로 다른 환경에 격리 시키는 것이 맞을 것 같습니다.
마치며
최종적으로, 모니터링 환경은 로컬에서 운영하기로 결정했습니다.

다만, 걱정이 좀 되는 것은 로컬에서 진행할 경우 15초 마다 Prometheus가 데이터를 수집하면 AWS Data Transfer 과금 정책이 프리티어의 경우 한 달에 100GB가 최대인데 어느정도 소모 될 지가 궁금하네요. 아직 1월이 가지 않았으니 테스트 해봐야겠습니다.

이틀동안의 모니터링 결과, 처음에는 0.75% 정도였는데 현재는 0.86% 입니다. 즉 1%도 소모하지 않았습니다. 데이터의 양이 매우 적어서 별 걱정 안하고 사용해도 될 것 같네요.
초반에는 단순히 부하 테스트를 해보기 전에 모니터링 환경을 구축해서 "이런것이 있구나" 정도의 경험을 쌓으려 했습니다.
하지만 이 과정에서 예상치 못한 시간을 투자하게 되었고, 기억 저편으로 사라졌던 Docker Compose, 도커 네트워크에 관련된 새로운 지식, 모니터링 환경이 서비스 리소스에 미치는 영향에 대해 생각해 볼 수 있었습니다.
감사합니다!
