
개요
자바의 Object 클래스에는 equals() 메서드와 hashCode() 메서드가 정의되어 있습니다.
이 두 메서드는 자바의 컬렉션 프레임워크 구현체 중 하나인 HashMap에서 핵심적으로 사용되는데요.
저는 이 두 메서드가 HashMap에서 어떻게 사용되는지 조금 자세하게 알고 싶어졌습니다.
이번 글은 HashMap의 내부 코드를 분석하며 두 메서드가 어떻게 사용되는지 알아보겠습니다.
equals()와 hashCode()
HashMap은 먼저 hashCode() 메서드를 사용해 해시 코드를 생성한 다음, equals() 메서드로 키의 동등성을 판단합니다.
따라서 키 객체에 대한 equals()와 hashCode() 메서드를 적절하고 일관성 있게 구현하는 것이 중요합니다.
이에 대한 몇 가지 예시를 살펴보겠습니다.
public class Person {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}위의 Person 클래스는 equals()와 hashCode() 메서드를 재정의 하고 있지 않습니다.
이 클래스를 HashMap의 키로 사용해 보겠습니다.
public class Main {
public static void main(String[] args) {
Map<Person, String> map = new HashMap<>();
Person person1 = new Person("MinSsi", 29);
Person person2 = new Person("MinSsi", 29);
map.put(person1, "민씨");
map.get(person2); // null
}
}person1, person2는 필드 값이 같지만 map.get(person2)는 null을 반환합니다.
이유는 두 객체의 해시 코드가 다르기 때문입니다.
person1.hashCode(); // 312116338
person2.hashCode(); // 453211571그렇다면 Objects.hash() 메서드를 이용하여 hashCode() 메서드를 재정의 한 뒤
동일한 해시 코드를 반환하도록 변경해 보겠습니다.
@Override
public int hashCode() {
return Objects.hash(name, age);
}person1.hashCode(); // -1566425017
person2.hashCode(); // -1566425017변경된 코드는 person1, person2의 hashCode() 메서드 호출 시, 동일한 해시 코드를 반환합니다.
이제는 원하는 결과를 얻을 수 있을까요?
map.get(person2); // null아쉽게도 여전히 null을 반환합니다. 이유는 HashMap은 키의 해시 코드가 같다고 할지라도 equals() 메서드를 이용하여 객체의 동등성을 추가로 검사하기 때문입니다.
따라서 equals() 메서드도 적절하게 재정의 해줘야 합니다.
@Override
public boolean equals(Object object) {
if (this == object) return true;
if (object == null || getClass() != object.getClass()) return false;
Person person = (Person) object;
return age == person.age && Objects.equals(name, person.name);
}map.get(person2); // "민씨"equals()와 hashCode() 메서드를 적절하게 재정의하고 나서야 원하는 결과를 얻을 수 있게 되었습니다.
정리
- HashMap은 키의 hashCode() 메서드와 eqauls() 메서드를 사용한다.
- 따라서, 키에 대한 equals()와 hasCode() 메서드를 적절하게 정의해야 한다.
HashMap의 초기화와 버킷 생성
자바의 HashMap에서는 키-값 쌍을 저장하는 데 사용되는 구조를 버킷(Bucket) 또는 슬롯(Slot)이라고 합니다.
이번 섹션에서는 HashMap이 내부적으로 버킷을 어떻게 생성하고 관리하는지에 대해 자세히 살펴보겠습니다.
먼저 HashMap은 객체가 생성될 때, 버킷이 즉시 생성되지 않습니다.
Map<Person, String> map = new HashMap<>();public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}HashMap 클래스의 기본 생성자를 살펴보겠습니다.
버킷과 관련된 코드는 전무하며 단순히 loadFactor 변수에 상수인 DEFAULT_LOAD_FACTOR을 할당하고 있습니다.
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;로드 팩터(Load Factor)는 버킷의 로드 비율을 나타내는 변수입니다.
- "얼마나 가득 차 있을 때 크기를 조정해야 하는가?"를 결정하는 역할을 하는데요.
- 0.75f는 "버킷이 75% 찼을 때 크기를 조정해야 한다"를 의미합니다.
그렇다면 버킷은 언제 생성될까요?
바로 HashMap에 실제로 데이터가 추가될 때, put() 메서드가 호출될 때 비로소 생성됩니다.
Person person1 = new Person("MinSsi", 29);
map.put(person1, "민씨");public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}put() 메서드는 내부적으로 hash() 메서드를 호출한 후 putVal() 메서드를 호출합니다.
먼저 hash() 메서드를 살펴보겠습니다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}hash() 메서드는 키의 hashCode() 메서드와 비트 연산을 이용하여 키에 대한 새로운 해시 코드를 생성합니다.
-
키의 hashCode() 메서드를 이용하여 키의 해시 코드 계산
h = key.hashCode() -
키의 해시코드를 부호를 무시한 채 우측으로 16번 시프트
h >>> 16 -
위 두 값을 이용하여 XOR 연산 수행
(h = key.hashCode()) ^ (h >>> 16)
이 과정을 시각적으로 이해하기 위해 아래의 예시를 살펴보겠습니다.
Person person = new Person("MinSsi", 29);
int h = person.hashCode();
System.out.println(h); // -1566425017
int shiftH = h >>> 16;
System.out.println(shiftH); // 41634
int xor = h ^ shiftH;
System.out.println(xor); // -156638338710100010101000100100000001000111 // h
00000000000000001010001010100010 // shiftH
10100010101000101110001011100101 // xor최종적으로 h와 shiftH의 XOR값인 -1566383387가 hash() 메서드의 반환값으로 사용됩니다.
HashMap은 키에서 재정의한 hashCode() 메서드의 반환 값을 해시 코드로 사용하는 것이 아닌, 내부적으로 추가적인 처리 과정(비트 연산)을 한번 더 거친 뒤 해시 코드로 사용하는데요.
그 이유는 해시 코드의 분포를 개선하고 해시 충돌을 최소화 함에 있습니다.
(이에 대한 자세한 설명은 버킷의 인덱스를 결정하는 과정에서 알아보겠습니다.)
다음으로 putVal() 메서드를 살펴보기 전에, Node 클래스에 대한 지식이 필요합니다.
Node는 무엇일까요?
Node 클래스는 HashMap의 버킷을 나타내는 데 사용되는 클래스이며 이너 클래스로 아래와 같이 정의되어 있습니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}- hash : 키의 해시 코드 (
hash()메서드의 결과 저장) - key : 버킷에 저장된 키
- value : 키에 매핑된 값
- next : 해시 충돌과 연관된 필드
HashMap은 필드로 Node 클래스의 배열을 가지고 있습니다.
transient Node<K,V>[] table;즉, HashMap의 버킷은 Node 클래스의 배열로 구현되어 있습니다.
이제 putVal() 메서드를 살펴보겠습니다.
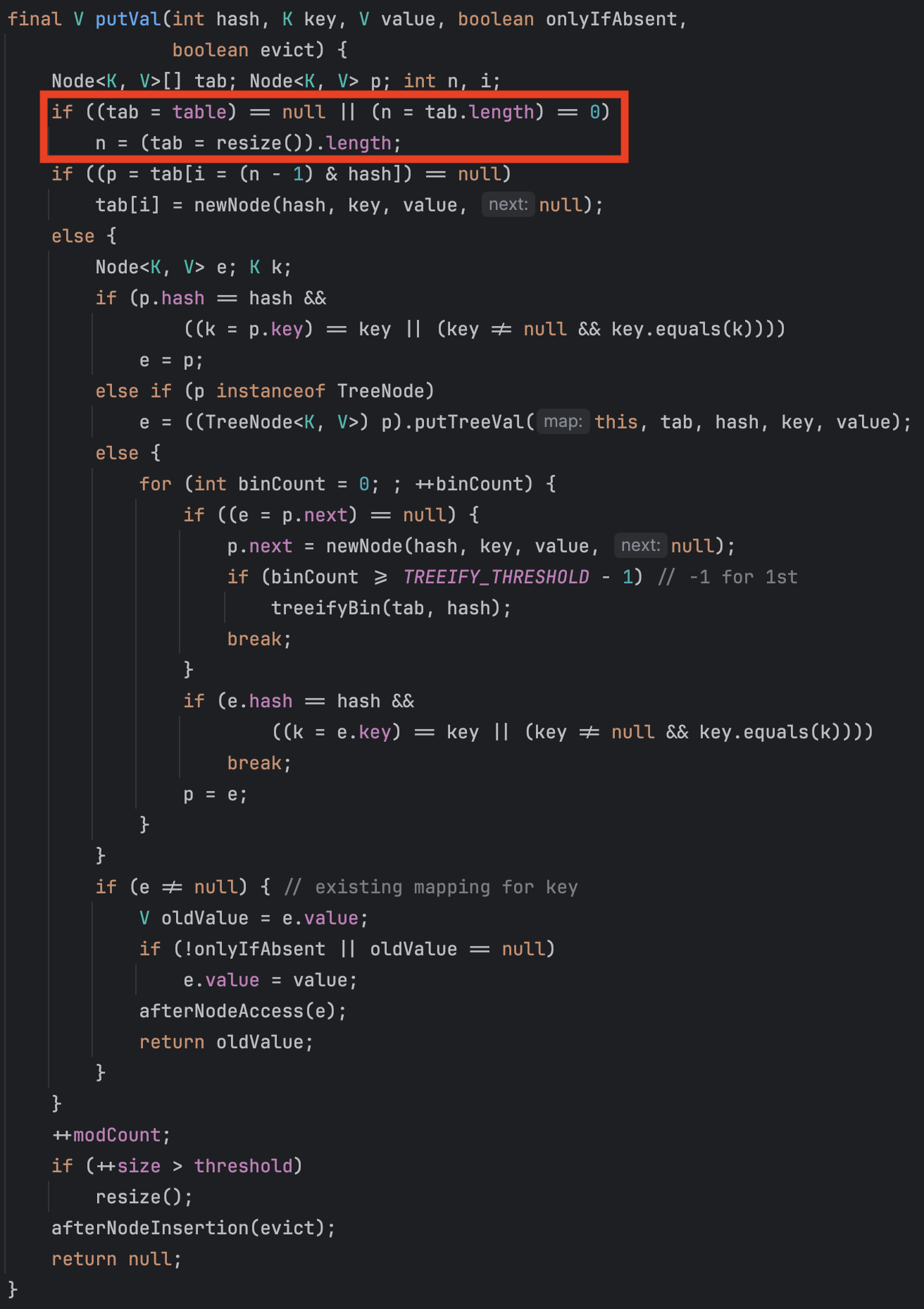
알아보기 힘든 복잡한 코드지만 우리는 빨강색 박스의 코드만 확인하면 됩니다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;(tab = table) == null 는 table 배열이 초기화 되지 않은 상태를 체크합니다.
- HashMap 클래스의 필드인 table은 객체가 생성될 때 초기값이 null이므로 참입니다.
n = (tab = resize()).length; // 16이 후 tab에 resize() 메서드의 결과를 할당한 뒤, n에 tab의 길이를 할당합니다.
결론부터 말하면 n은 16이 할당됩니다.
resize() 메서드를 분석하며 16이 할당되는 과정을 살펴보겠습니다.
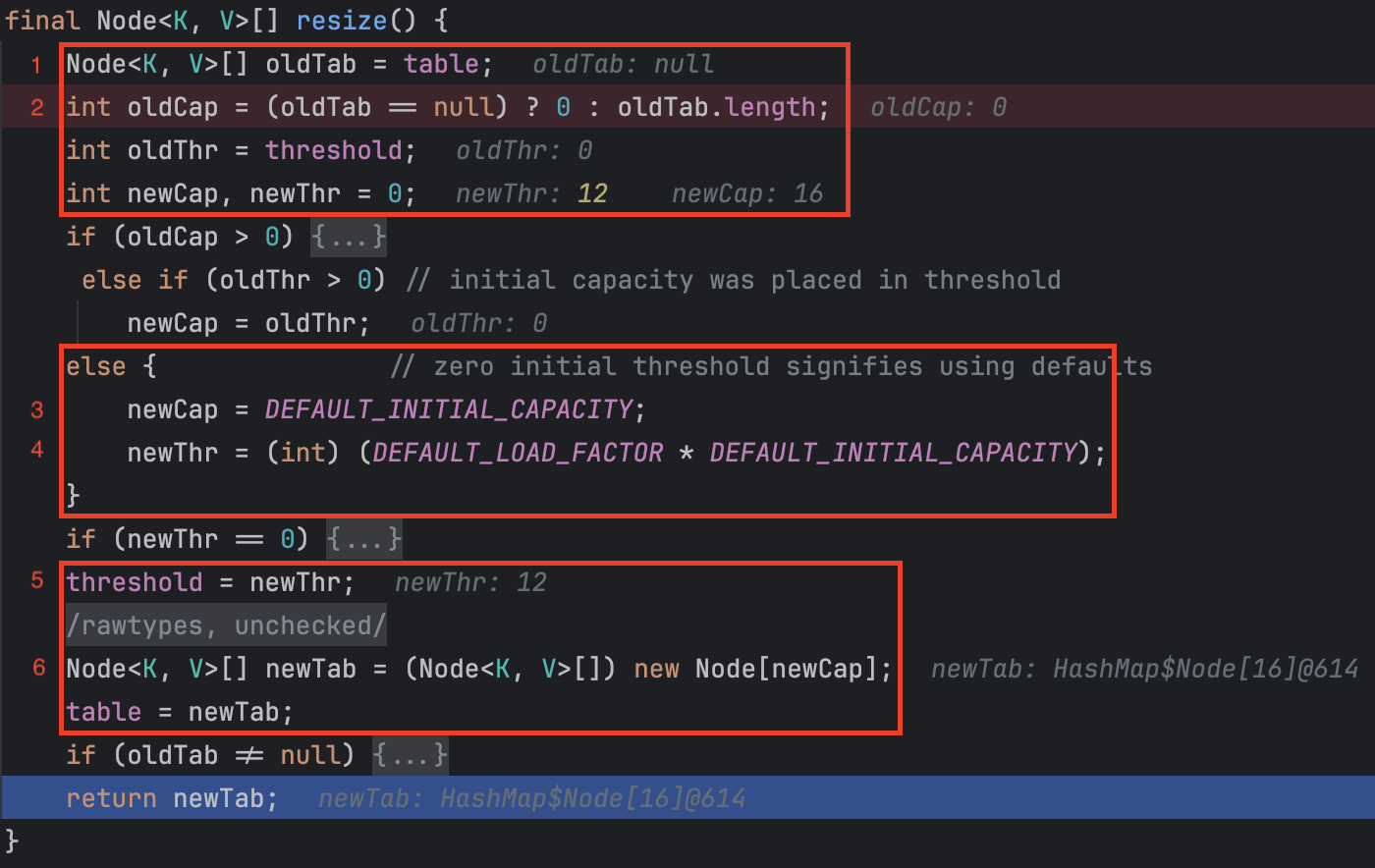
메서드가 길어 일부만을 발췌했습니다.
-
oldTab에 table을 할당합니다.
- 사진은 디버그 모드의 결과를 찍어온 것이라 보이시겠지만 null이 할당되어 있습니다.
- table은 HashMap의 필드로써 초기값 null로 할당 됐기에 당연히 null 입니다.
-
oldCap은 oldTab이 null이므로 0이 할당되고, 아래의 else 문이 실행됩니다.
-
newCap에는 상수값 DEFAULT_INITIAL_CAPACITY(16)가 할당됩니다.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 -
newThr에는 로드 팩터와 용량을 곱한 값(12)이 할당 됩니다.
- 16의 75%인 12가 할당됩니다. (16 * 0.75f)
-
HashMap의 필드인 threshold에 newThr(12)이 할당됩니다.
// (The javadoc description is true upon serialization. // Additionally, if the table array has not been allocated, this // field holds the initial array capacity, or zero signifying // DEFAULT_INITIAL_CAPACITY.) int threshold; -
table에 newCap 크기(16)의 배열이 생성되고 할당됩니다.
드디어 버킷이 생성되었습니다.
정리
- 기본 생성자를 이용하여 해시 맵을 생성하면 버킷의 용량이 결정되지 않음
- 키의 hashCode() 메서드는 HashMap의 hash() 메서드에서 추가 처리를 위해 사용 됨
- put() 메서드를 호출했는데 버킷이 없다면, resize() 메서드를 호출하여 용량이 16인 버킷 생성
HashMap에 데이터 저장하기
마침내 용량이 16인 버킷이 생성되었습니다.
그렇다면 데이터가 버킷에 저장되기 위해서는 어떠한 과정을 거칠까요?
바로 putVal() 메서드의 아래 코드에서 실행됩니다.
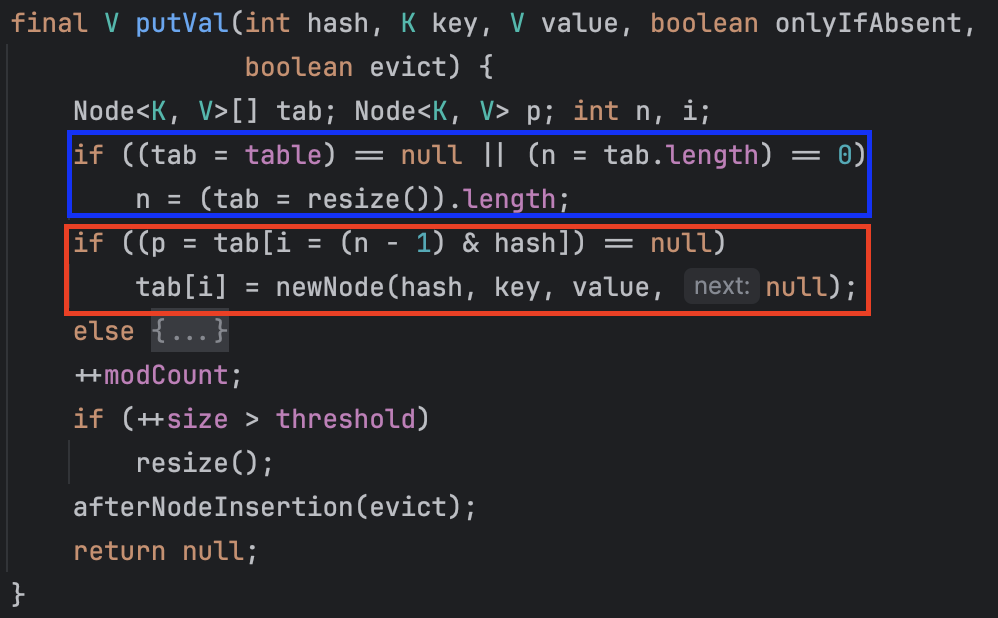
파랑색 박스는 앞서 살펴본 버킷 생성 코드를 나타내며, 이번 섹션에서는 빨강색 박스에 표시된 버킷에 값을 삽입하는 과정을 살펴보겠습니다.
HashMap의 table 변수는 크기가 16인 Node 배열로 초기화 되었습니다.
배열에 값을 삽입하기 위해서는 인덱스를 결정해야 하는데요.
변수 i가 인덱스의 역할을 하게 됩니다.
if ((p = tab[i = (n - 1) & hash]) == null)i = (n - 1) & hash인덱스는 버킷의 용량 - 1(n -1)과 키의 해시 코드(hash)의 AND 연산으로 생성되는데요.
이 과정을 시각적으로 이해하기 위해 아래의 예시를 살펴보겠습니다.
int hash = h ^ shiftH;
System.out.println(hash); // -1566383387 (이 값이 도출되는 과정은 위에서 확인 하세요)
int n = 16;
System.out.println(n - 1); // 15
int index = (n - 1) & hash;
System.out.println(index); // 510100010101000101110001011100101 // hash
00000000000000000000000000001111 // n - 1
00000000000000000000000000000101 // index계산 결과 인덱스가 5로 결정됩니다.
if ((p = tab[i = (n - 1) & hash]) == null)if ((p = tab[5]) == null)if ((p = null) == null)if (null == null)if (true)위와 같은 과정을 거쳐 버킷에 값을 삽입하는 코드가 실행됩니다.
tab[i] = newNode(hash, key, value, null);tab[5] = newNode(-1566383387, person1, "민씨", null);이를 그림으로 표현하면 아래와 같습니다.
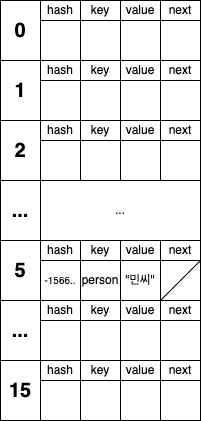
크기가 16인 Node 배열의 5번 인덱스에 새로운 노드가 할당되었습니다.
인덱스를 결정하는 코드를 조금 더 자세히 살펴보겠습니다.
그전에 버킷의 용량이 어떻게 늘어나는지 알아할 필요가 있는데요.
resize() 메서드를 잠시 확인해 보겠습니다.
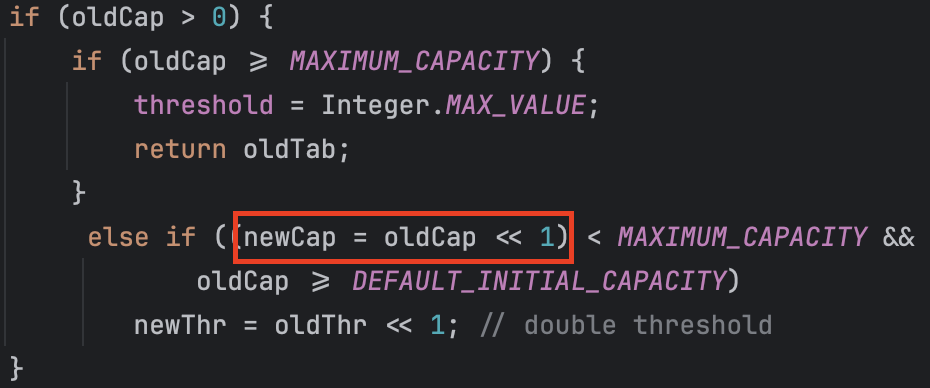
버킷의 용량은 왼쪽으로 1번 시프트한 값으로 결정됩니다.
따라서 초기값이 16 즉, 2^4 이므로 2^5, 2^6 .. 2^n 으로 용량이 확장되는데요.
용량은 2의 거듭제곱이 되고 이를 이진수로 표현하면 아래와 같습니다.
00000000000000000000000000010000 // 2^4
00000000000000000000000000100000 // 2^5
00000000000000000000000001000000 // 2^6
...
00000000000100000000000000000000 // 2^20n에서 1을 뺀 n-1을 이진수로 나타내면 아래와 같습니다.
00000000000000000000000000001111 // 2^4 - 1
00000000000000000000000000011111 // 2^5 - 1
00000000000000000000000000111111 // 2^6 - 1
..
00000000000011111111111111111111 // 2^20 - 1모든 하위 비트가 1로 변하게 되죠.
이를 이용해 AND 연산을 수행하면 어떠한 수가 와도 0 ~ 2^n - 1 사이의 값으로 결정됩니다.
[1010001010100010111000101110]0101 // hash
&
[0000000000000000000000000000]1111 // n - 1
--------------------------------
[0000000000000000000000000000]0101 // 괄호 안은 0으로 다 지워짐 즉, 어떠한 해시 코드가 주어져도 0 ~ 2^n - 1 사이의 범위 내에 있는 인덱스 값이 도출됩니다.
인덱스를 계산하는 방법을 알았으니 버킷 생성 섹션에서 언급한 "해시 코드 분포 개선과 해시 충돌 최소화"에 대해 알아보겠습니다.
public class HashMethodExample {
public static void main(String[] args) {
int n = 16;
// 다양한 해시 코드를 생성하기 위한 키 객체
String[] keys = {"Key1", "Key2", "Key3", "Key4", "Key5", "Key6", "Key7", "Key8", "Key9"};
for (String key : keys) {
// 원래 hashCode
int originalHashCode = key.hashCode();
// hash() 메서드에서 수행하는 비트 연산 적용
int newHashCode = hash(originalHashCode);
System.out.println("Key: " + key + ", Original HashCode: " + originalHashCode + ", Original Index: [" + ((n - 1 ) & originalHashCode) + "], Hash: " + newHashCode + ", New Index: [" + ((n - 1) & newHashCode) + "]");
}
}
private static int hash(int hashCode) {
return hashCode ^ (hashCode >>> 16);
}
}위 코드는 9개의 키 객체를 이용하여 hashCode() 메서드 만을 사용했을 때의 인덱스와 hash() 메서드를 이용했을 때의 인덱스를 비교하는 코드입니다.
실행 결과는 아래와 같습니다.
Key: Key1, Original HashCode: 2335186, Original Index: [2], Hash: 2335217, New Index: [1]
Key: Key2, Original HashCode: 2335187, Original Index: [3], Hash: 2335216, New Index: [0]
Key: Key3, Original HashCode: 2335188, Original Index: [4], Hash: 2335223, New Index: [7]
Key: Key4, Original HashCode: 2335189, Original Index: [5], Hash: 2335222, New Index: [6]
Key: Key5, Original HashCode: 2335190, Original Index: [6], Hash: 2335221, New Index: [5]
Key: Key6, Original HashCode: 2335191, Original Index: [7], Hash: 2335220, New Index: [4]
Key: Key7, Original HashCode: 2335192, Original Index: [8], Hash: 2335227, New Index: [11]
Key: Key8, Original HashCode: 2335193, Original Index: [9], Hash: 2335226, New Index: [10]
Key: Key9, Original HashCode: 2335194, Original Index: [10], Hash: 2335225, New Index: [9]주목할 점은 Original Index와 New Index입니다.
키 객체의 hashCode() 메서드만을 이용하여 생성된 Original Index는 인덱스의 분포가 한정적인 반면 hash() 메서드를 이용한 New Index는 인덱스의 분포가 더 넓어집니다.
이로인해 버킷 내에 데이터를 균등하게 분포시켜주며 해시 충돌의 가능성을 줄여줍니다.
정리
- 버킷의 용량은 2의 거듭제곱으로 늘어난다.
- 인덱스는 버킷의 용량에서 1을 뺀 값과 키의 해시 코드와의 AND 연산으로 계산한다.
HashMap에서 데이터 조회하기
지금까지 put() 메서드를 이용하여 버킷을 생성하고, 버킷에 데이터를 삽입하는 과정을 살펴보았습니다.
public class Main {
public static void main(String[] args) {
HashMap<Person, String> map = new HashMap<>();
Person person1 = new Person("MinSsi", 29);
map.put(person1, "민씨");
Person person2 = new Person("MinSsi", 29);
map.get(person2); // 여기
}
}이번 섹션에서는 person2 객체를 이용하여 HashMap을 조회했을 때 발생하는 과정에 대해 알아보겠습니다.
먼저 get() 메서드에 대하여 살펴봅시다.
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}get() 메서드는 내부적으로 getNode() 메서드를 호출하며, 이 때 해시 코드와 키를 매개 변수로 사용합니다.
- person2는 person1과 동등한 객체이므로 hash(key)는 -1566383387 입니다.
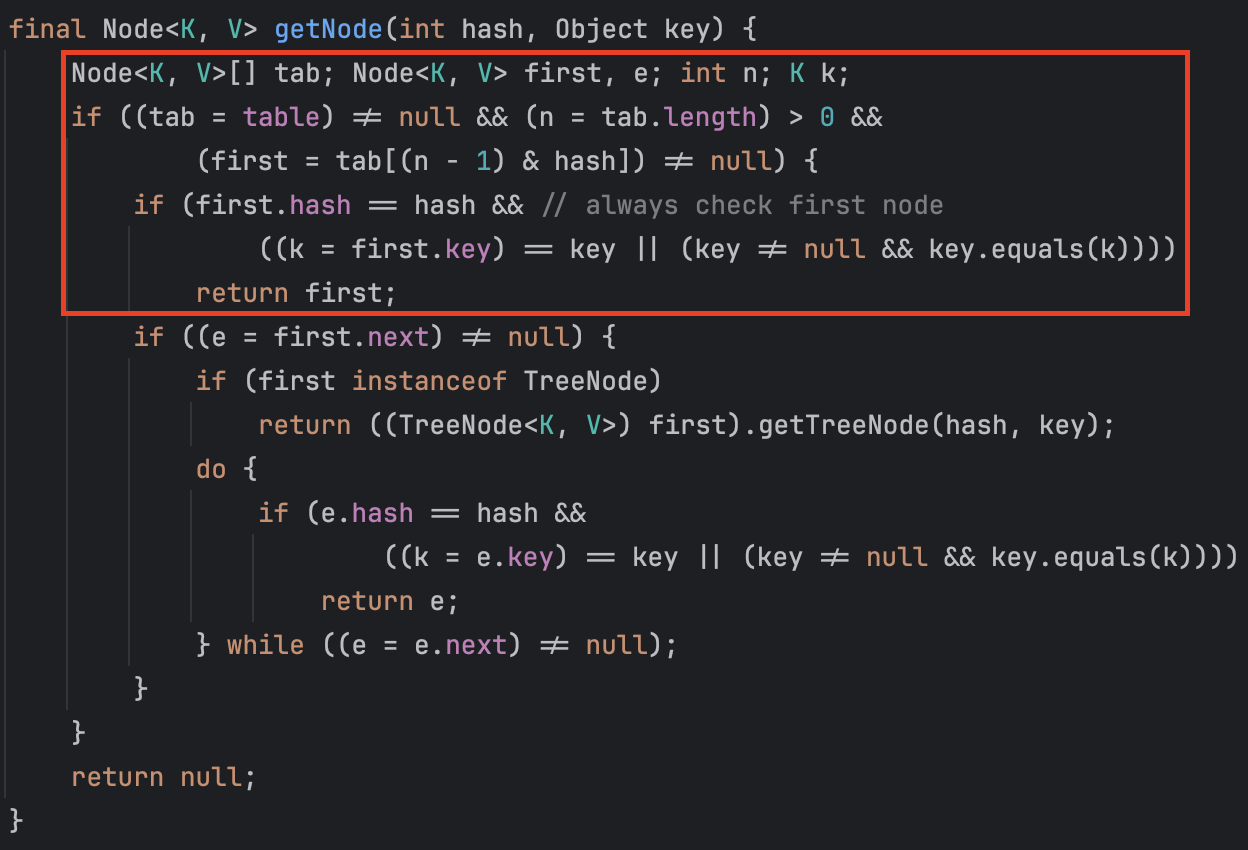
이번에도 빨강색 박스만 확인하면 됩니다.
첫 번째 조건문을 확인해 보겠습니다.
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null)-
(tab = table) != null: true- tab에 table 할당
- table의 크기는 16이고 5번 인덱스에 Node 객체가 할당되어 있습니다.
- table은 null이 아닙니다. true
-
(n = tab.length) > 0: true- n에 tab의 크기 할당
- tab의 크기는 16이므로 0보다 큽니다. true
-
(first = tab[(n-1) & hash]) != null: true- (n -1) & hash 는 5를 반환합니다.
- first에 tab[5] 할당
- first는 null이 아닙니다. true
위 조건문은 참이므로 두 번째 조건문을 확인해 보겠습니다.
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))-
first.hash == hash: true- first의 해시와 매개 변수의 해시가 일치하는지 확인
- first에 저장된 해시 코드는 person1의 해시 코드 이므로 person2의 해시 코드와 같습니다. true
-
(k = first.key) == key: false- k에 first의 키 할당, 이후 매개 변수 key와 동일한 지 확인
- first의 키인 person1이 k에 할당됩니다.
- k(person1)와 key(person2)는 동등한 객체이나 같은 메모리를 참조하고 있진 않습니다. false
-
key != null && key.equals(k): true- key(person2)는 null이 아닙니다. true
- key(person2)와 k(person1)는 동등합니다. : true
이 전 섹션에서 논의한 바와 같이, hashCode()만 재정의 하고 equals()를 재정의하지 않으면 위 조건문에 의하여 동등하지 않은 객체로 인식되어 null을 반환하게 됩니다.
이후 first(tab[5])를 반환합니다.
return first;getNode() 메서드의 호출이 종료되었습니다.
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}public V get(Object key) {
Node<K,V> e;
return (e = new Node<Person, String>(-1566383387, person1, "민씨", null)) == null ? null : e.value;
}public V get(Object key) {
Node<K,V> e;
return e == null ? null : e.value;
}public V get(Object key) {
Node<K,V> e;
return e.value;
}다시 get() 메서드로 돌아와서 위 과정을 거친 뒤, e의 값(value)이 반환됩니다.
정리
- HashMap은 키의 해시 코드를 비교하고 equals() 메서드로 동등한지 이중으로 검사한다.
HashMap의 해시 충돌
해시 충돌(Hash Collision)이 일어나는 경우는 무엇이 있을까요?
제 생각으로는 두 가지의 경우가 있을 것 같습니다.
- 잘못 정의된 hashCode() 메서드
- 배열의 크기 한계
1번, 잘못 정의된 hashCode() 메서드
public class Person {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object object) {
if (this == object) return true;
if (object == null || getClass() != object.getClass()) return false;
Person person = (Person) object;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return -1;
}
}위 Person 클래스는 hashCode() 메서드를 -1로 고정해서 리턴하고 있습니다.
Person person1 = new Person("MinSsi", 29);
Person person2 = new Person("KimSsi", 30);
Person person3 = new Person("LeeSsi", 23);
System.out.println(person1.hashCode()); // -1
System.out.println(person2.hashCode()); // -1
System.out.println(person3.hashCode()); // -1따라서 person1, person2, person3 객체는 필드가 다르지만 똑같은 해시 코드를 반환합니다.
2번, 배열의 크기 한계
이 전 섹션에서 살펴본 것처럼, HashMap은 내부적으로 배열을 사용합니다.
transient Node<K,V>[] table;자바에서 배열의 최대 크기는 Integer.MAX_VALUE, 즉 2^31-1개입니다.
만약 HashMap에 2^31개의 데이터가 삽입되면 필연적으로 해시 충돌이 일어나게 됩니다.
(현실적으로는 메모리 문제가 먼저 발생하겠지만 이는 무시합니다.)
즉 해시 충돌은 이론상 반드시 일어납니다.
이러한 해시 충돌을 해결하기 위한 방법은 대표적으로 두 가지가 있습니다.
- 개방 주소법(Open Addressing)
- 체이닝(Separate Chaining)
자바의 HashMap은 두 번째 체이닝을 이용하여 해결합니다. 이를 그림으로 나타내면 아래와 같습니다.
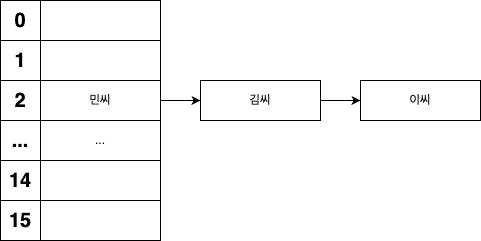
이 전 섹션에서 언급했지만 체이닝을 구현하기 위해 HashMap의 Node 클래스에는 next 필드가 존재합니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}이번 섹션에는 1번 방법을 이용하여 강제로 해시 충돌을 일으킨 뒤, HashMap이 체이닝으로 해시 충돌을 해결하는 방법을 알아보겠습니다.
public class Main {
public static void main(String[] args) {
HashMap<Person, String> map = new HashMap<>();
Person person1 = new Person("MinSsi", 29);
Person person2 = new Person("KimSsi", 30);
Person person3 = new Person("LeeSsi", 23);
map.put(person1, "민씨");
map.put(person2, "김씨");
map.put(person3, "이씨");
System.out.println(map); // {Person@ffffffff=민씨, Person@ffffffff=김씨, Person@ffffffff=이씨}
}
}위 코드의 person1, person2, person3 객체는 똑같은 해시 코드인 -1을 반환합니다.
해시 코드가 똑같으므로 버킷에 값이 덮어쓰여 "이씨"만 저장될 것 같지만, "민씨", "김씨", "이씨" 전부 저장됩니다.
map.put(person1, "민씨");우선 "민씨"까지는 위에서 알아본 것 처럼 똑같이 저장됩니다. 그림으로 나타내면 아래와 같습니다.
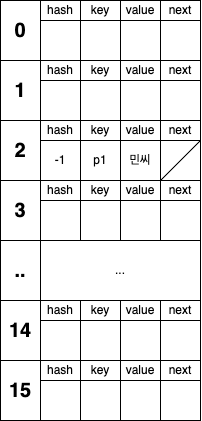
map.put(person2, "김씨");두 번째 put() 메서드 부터는 HashMap의 내부 코드를 살펴봐야합니다.
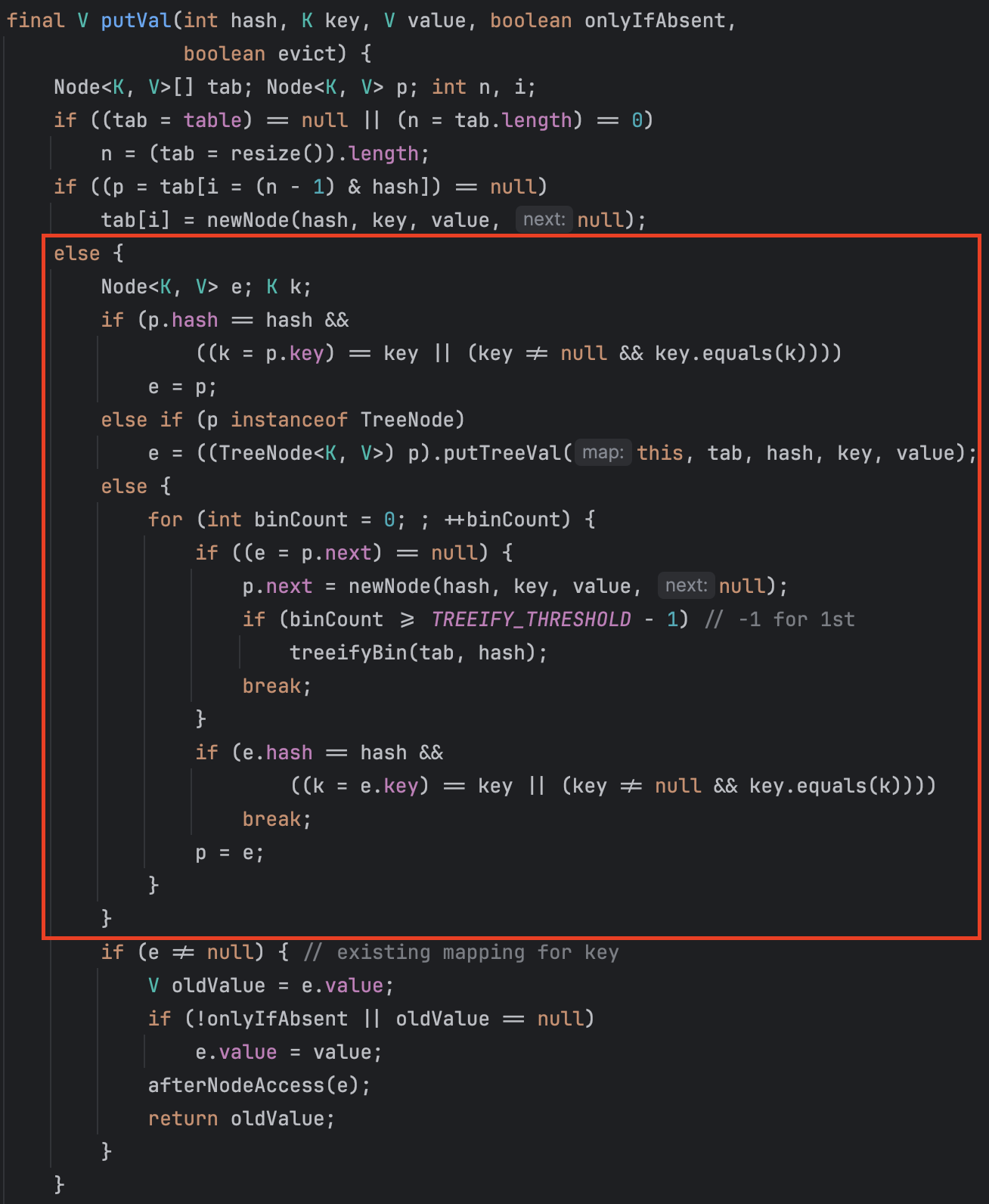
putVal() 메서드의 else 구문을 살펴보겠습니다.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))-
p.hash == hash: true-
p는 2번 인덱스에 저장된 값입니다.

-
"김씨"의 hash값(-1)과 "민씨"의 hash값(-1)은 동일합니다. true
-
-
(k = p.key) == key: false- k는 p의 키인 p1입니다. 반면에 key는 "김씨"의 키 p2입니다. false
-
(key != null && key.equals(k)): false- key는 null이 아닙니다. true
- key인 p1과 k인 p2는 동등한 객체가 아니므로 거짓입니다. false
else if (p instanceof TreeNode)p는 Node 클래스의 객체이므로 false 입니다. else 구문으로 이동합니다.
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
e에 p.next를 할당합니다. 위 그림을 보면 알 수 있듯이 null입니다. 따라서 조건문은 참입니다.
p.next = newNode(hash, key, value, null);
p.next에 새로운 노드를 생성한 뒤 할당합니다.
위 코드는 반복문으로써 next가 null일 때 까지 연결 리스트를 탐색한 뒤 next에 새로운 Node 객체를 연결합니다.
따라서, "이씨"에 대한 put() 메서드가 호출되면 "이씨"도 동일한 방법으로 연결됩니다.

궁극적으로 체이닝 방법으로 해시 충돌을 해결한 버킷은 아래와 같은 형태를 가집니다.
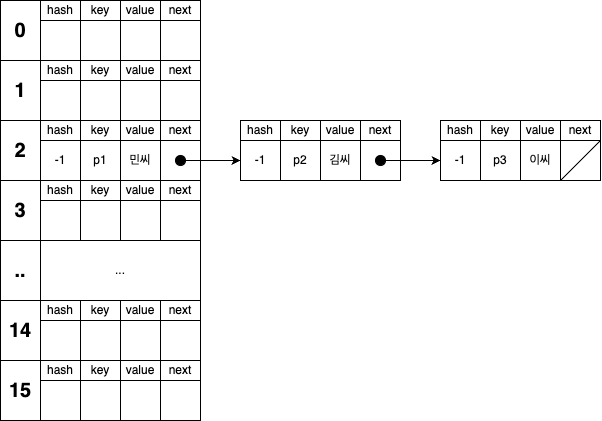
마지막으로 해시 충돌이 빈번하게 발생한 상황에 대해 알아보겠습니다.
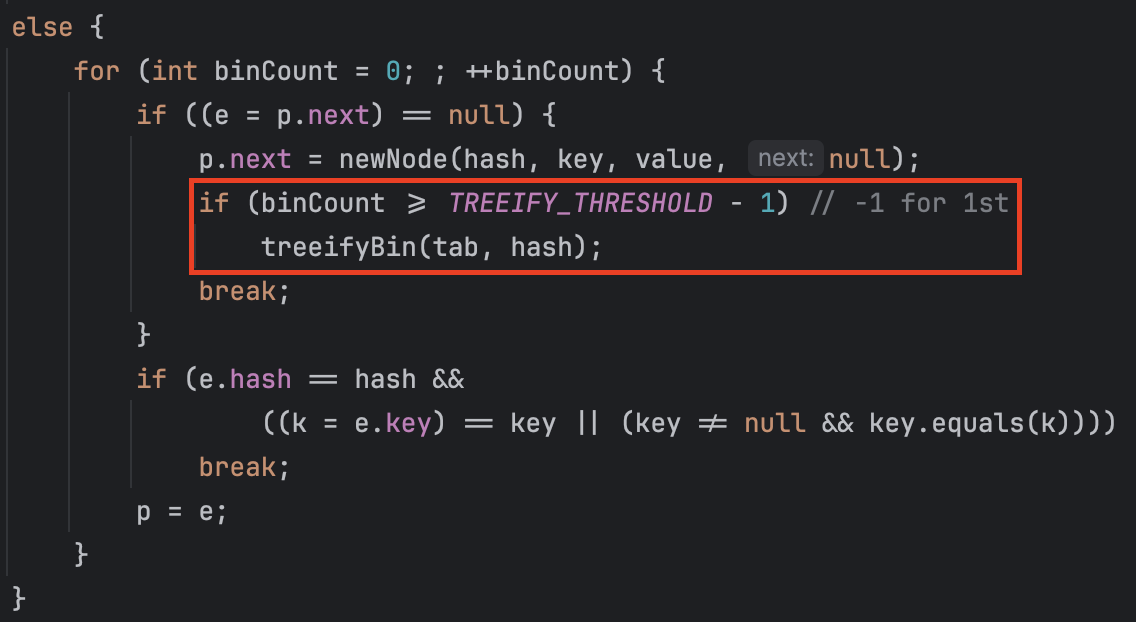
위 코드는 연결 리스트의 개수가 8개 이상이 되면 연결 리스트를 트리로 변경하는 코드입니다.
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;TREEIFY_THRESHOLD는 임계값을 나타내는 상수로 8로 초기화 되어 있습니다.
해시 충돌이 자주 발생하여 연결 리스트가 늘어날 경우 조회, 삽입, 삭제에 많은 시간이 소요됩니다.
이유는 일반적인 버킷 조회의 시간 복잡도가 O(1)인 반면, 연결 리스트는 O(n)이기 때문인데요.
따라서 HashMap은 연결 리스트가 일정 임계값(8)을 초과하면 검색 시간을 O(log n)으로 개선하기 위하여 트리로 구조를 전환합니다.
정리
- 해시 충돌은 불가피한 문제이다.
- HashMap은 체이닝 방법을 이용하여 해시 충돌을 해결한다.
- 연결 리스트의 개수가 8개 이상이 되면 성능 개선을 위해 트리로 전환한다.
마치며
HashMap의 버킷에 값을 삽입하고 조회하는 과정 및 해시 충돌에 대해 조금 자세히 알아봤습니다.
처음에는 단순히 equals()와 hashCode()가 어떻게 HashMap에서 사용되는 지가 궁금하여 코드를 들여다 보는 것이 시작이였는데, 이렇게 자세한 글이 될 지 몰랐는데요.
평소에 막연하게 "HashMap에는 equals()와 hashCode()가 쓰인다" 정도에서 벗어나 왜 그런지를 알 수 있게 된 재미있는 시간이였습니다.
이 글을 읽는 분들이 조금이나마 HashMap을 이해하는 데 도움이 되었으면 좋겠습니다.
감사합니다.
